

GLM 4.1V 9B Thinking هو نموذج ذكاء اصطناعي ثوري لأنه يستطيع رؤية الصور وشرح استدلالاته خطوة بخطوة. يُسمى هذا الاستدلال المتسلسل (chain-of-thought - CoT)، ويؤديه GLM بشكل أفضل من أي نموذج رؤية-لغة آخر بنفس حجمه. ستشاهد كيف يقارن بالنماذج الأكبر وكيف يمكنك تجربته بنفسك، حتى لو لم تمتلك وحدة معالجة رسومية (GPU) باهظة الثمن.
ما التغييرات التي أحدثها GLM 4.1V 9B Thinking في نماذج VLM؟
بصفته أول نموذج VLM في العالم مزود باستدلال متسلسل (CoT)، لم يبهرنا GLM بقدراته القوية فحسب، بل حصل أيضًا على تقدير لتحقيقه أداءً مماثلاً لـ Qwen 2.5 72B، على الرغم من كونه نموذجًا أصغر بكثير بحجم 9B. بعد ذلك، دعنا نلقي نظرة أقرب على مواصفات GLM التفصيلية ونتائج الاختبارات القياسية.
خصائص GLM 4.1V 9B Thinking

يمكنك بدء تجربة مجانية على Hugging Face مباشرة!
كيف يحقق GLM 4.1V 9B Thinking هذه التحسينات؟
- تعزيز SFT (Supervised Fine-Tuning):
تحتوي عينات التدريب على تعليقات توضيحية صريحة لـ سلسلة التفكير (Chain‑of‑Thought - CoT)، لذا يتعلم النموذج “التفكير أولاً، ثم الإجابة.” وهذا يختلف عن النماذج التقليدية التي تُخرج إجابة فقط دون إظهار خطوات الاستدلال. - تعزيز RLCS (Reinforcement Learning with Chain-of-Thought Supervision):
لا تعتمد مكافأة النموذج على الصحة فقط، بل تقوم أيضًا بتقييم جودة عملية الاستدلال والتفسيرات، مما يشجع على تفكير داخلي أكثر تماسكًا وعمقًا. - الدعم المعماري:
يقوم مشفر رؤية ViT بتغذية إسقاط MLP ثم إلى مفكك LLM، مما يمكّن النموذج من توليد مسارات استدلال صريحة بسلاسة من المدخلات البصرية، بدلاً من مجرد الاسترجاع أو مطابقة الأنماط. - أساس استدلال قوي:
وعامل رئيسي آخر: النموذج الأساسي - GLM‑4‑9B 0414 - يمتلك بالفعل قدرات استدلالية قوية. على سبيل المثال:- يُظهر أداءً ممتازًا في الاستدلال الرياضي وأداء المهام العامة، ويحتل مرتبة متقدمة بين النماذج مفتوحة المصدر بحجمه.
- من الناحية المعمارية والتدريبية، يستفيد GLM‑4‑9B من التدريب المسبق على تعبئة الفراغات الذاتية الرجعية (autoregressive blank‑infilling) والضبط الدقيق اللاحق الذي يعزز مهارات الاستدلال المنطقي ومتعدد الخطوات.
يمكنك الحصول على المزيد من التفاصيل من الورقة البحثية: GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning.
GLM 4.1V 9B Thinking مقابل Qwen 2.5 VL 72B
| الاختبار القياسي | GLM 4.1V 9B Thinking | Qwen 2.5 VL 72B | الفائز |
|---|---|---|---|
| MMMU (صورة) | 68.0 | 70.2 | Qwen 2.5 VL |
| MMMU‑Pro | 57.1 | 51.1 | GLM |
| VideoMMMU | 61.0 | 60.2 | GLM |
| mvBench (فيديو) | 70.4 | 64.6 | GLM |
| AITZ_EM (وكيل) | 83.2 | 35.3* | GLM |
| وكيل (OSWorld) | 14.9 | 8.8 | GLM |
| وكيل (AndroidWorld) | 41.7 | 35.0 | GLM |
| وكيل (WebVoyageSom) | 69.0 | 40.4 | GLM |
| وكيل (Webquest‑SingleQA) | 72.1 | 60.5 | GLM |
| وكيل (Webquest‑MultiQA) | 54.7 | 52.1 | GLM |
| برمجة (Design2Code) | 64.7 | 41.9 | GLM |
| برمجة (Flame‑VLM‑Code) | 72.5 | 46.3 | GLM |
| OCRBench | 84.2 | 85.1 | Qwen 2.5 VL |
| VideoMME (بدون نص) | 68.2 | 73.3 | Qwen 2.5 VL |
| VideoMME (مع نص) | 73.6 | 79.1 | Qwen 2.5 VL |
| MMVU | 59.4 | 62.9 | Qwen 2.5 VL |
اختر GLM 4.1V 9B Thinking إذا كانت أولوياتك هي الاستدلال متعدد الوسائط، وقدرات الوكيل، وحل مشكلات STEM، أو البرمجة.
اختر Qwen 2.5 VL 72B إذا كنت تركز على فهم المستندات/الصور/الفيديو - خاصة OCR، والاستخراج المنظم، والإدراك البصري.
إذا كنت ترغب في التحقق من المزيد من التفاصيل، يمكنك الاطلاع على هذه المقالة: GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Which Fits What؟
كما توفر مقارنة مع نماذج رائدة أخرى.
من THUDM
كيفية الوصول إلى GLM 4.1V 9B Thinking؟
1. الوصول محلياً
والأكثر إثارة للإعجاب، أن GLM 4.1V 9B Thinking يمتلك 9 مليارات معلمة فقط، مما يسمح بتشغيله على وحدات معالجة رسومية مثل RTX 4090 أو حتى 3090. مقارنة بالنماذج الأخرى التي تحتوي على عدة أضعاف المعلمات، يحقق GLM أداءً متميزًا بحجم أصغر بكثير - وهو إنجاز يسلط الضوء بلا شك على قوة التعلم المعزز.
من THUDM
دليل التثبيت
التثبيت:
pip install git+https://github.com/huggingface/transformers.git
الاستخدام الأساسي:
from transformers import AutoProcessor, Glm4vForConditionalGeneration
import torch
MODEL_PATH = "THUDM/GLM-4.1V-9B-Thinking"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://upload.wikimedia.org/wikipedia/commons/f/fa/Grayscale_8bits_palette_sample_image.png"
},
{
"type": "text",
"text": "describe this image"
}
],
}
]
processor = AutoProcessor.from_pretrained(MODEL_PATH, use_fast=True)
model = Glm4vForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
إذا كان شراء وحدة معالجة رسومية (GPU) مكلفًا للغاية، يمكنك الاستفادة من وحدات معالجة رسومية سحابية فعالة من حيث التكلفة وموثوقة من Novita AI - مثل RTX 4090 بسعر 0.69 دولار فقط في الساعة أو RTX 3090 بسعر 0.21 دولار فقط في الساعة!
2. التكامل المباشر عبر API
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

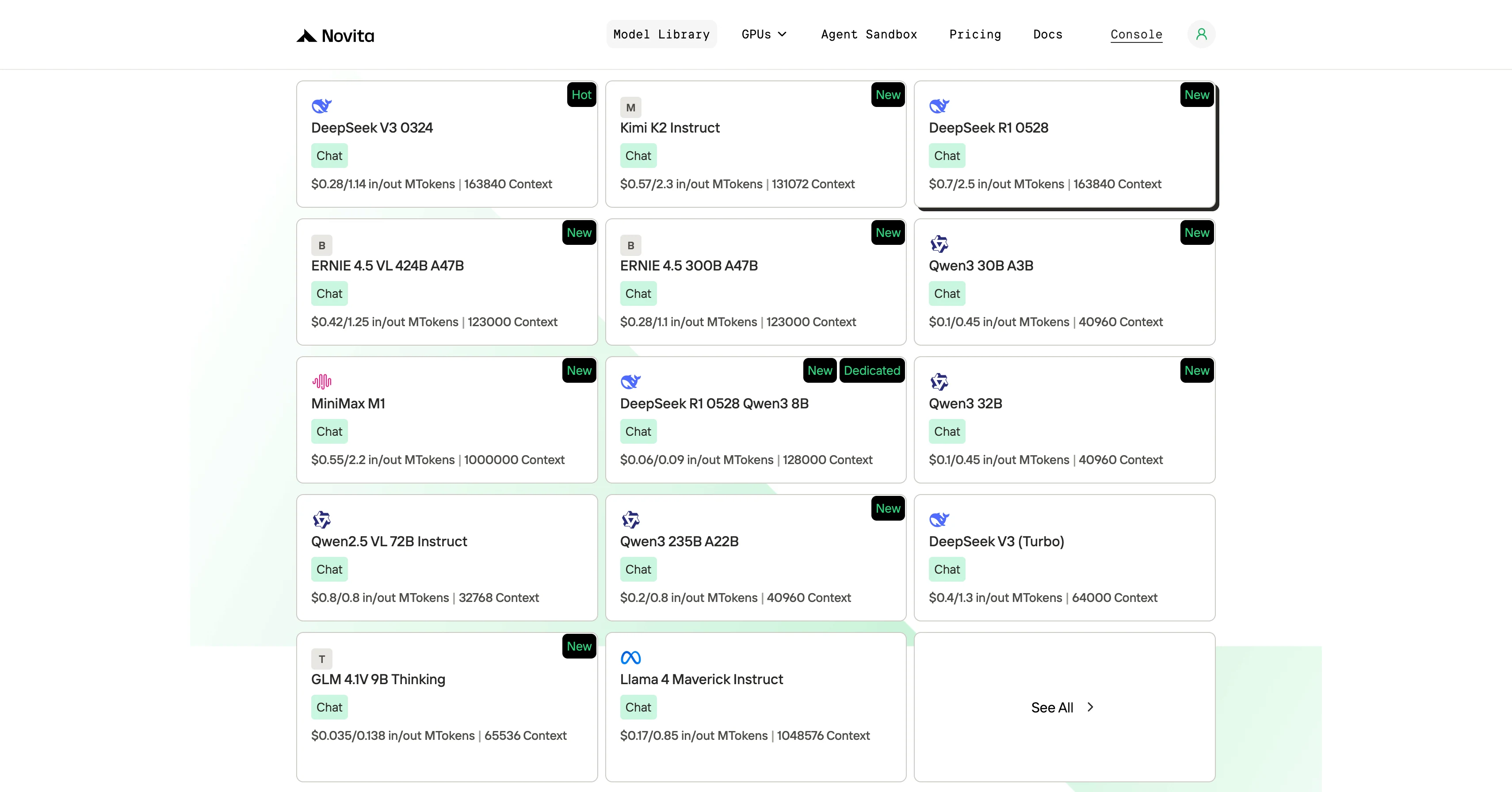
الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.
الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف قدرات النموذج المحدد.
الخطوة 4: احصل على مفتاح API الخاص بك
للتحقق من هويتك مع API، سنوفر لك مفتاح API جديد. بالدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة الخاصة بك.
بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام API لاستكمال الدردشة (chat completions) لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_kgNdXtDPt2zYc95i-nDWPaW4Zl_e7nf4VDpukuIVBKpko1-LE8xCasG4YK7c-3c1xnPzGYRuocFk_DhkPUUQyQ==",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # or False
max_tokens = 4000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
بناء أداة بسيطة للتعرف على الصور باستخدام MCP و GLM
إذا كنت ترغب في الاستفادة من قدرات GLM - مثل بناء أداة بسيطة للتعرف على الصور لتوضيح تكامل التعرف البصري والاستدلال - يمكنك استخدام وظيفة MCP التي تدعمها Novita AI. فيما يلي نموذج الكود:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
إذا كنت ترغب في الحصول على التفاصيل، يمكنك الاطلاع على هذه المقالة: How to Build Your First MCP Server with Novita AI!
GLM 4.1V 9B Thinking سهل الاستخدام، فائق الذكاء، ولا يحتاج إلى أجهزة متطورة. يمكنك اختبار قدراته في التعرف على الصور والاستدلال ببضعة أسطر من الكود فقط، سواء على جهازك الخاص أو في السحابة. إذا كنت تريد معرفة إلى أي مدى وصل الذكاء الاصطناعي متعدد الوسائط، جرب GLM!
ما المميز في GLM 4.1V 9B Thinking؟
إنه أول نموذج يمكنه “الرؤية” وعرض خطوات استدلاله، وليس فقط إعطاء الإجابات.
هل يمكنني تجربة GLM 4.1V 9B إذا لم يكن لدي وحدة معالجة رسومية قوية؟
نعم! يمكنك استخدام وحدات معالجة رسومية سحابية ميسورة التكلفة أو تجربته مجانًا على Novita AI Playground.
كيف يمكنني دمج GLM 4.1V 9B Thinking في مشاريعي الخاصة؟
يمكنك تشغيله محليًا باستخدام Python و Hugging Face، أو الوصول إليه عبر واجهة برمجة التطبيقات Novita AI’s، أو حتى بناء أدوات التعرف على الصور الخاصة بك باستخدام MCP كما هو موضح في أمثلة الكود المقدمة.
Novita AI هي المنصة السحابية الشاملة التي تمكّن طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، خوادم بدون خادم (serverless)، مثيلات GPU - الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، وابدأ مجانًا، وحوّل رؤيتك للذكاء الاصطناعي إلى واقع.



