

GLM 4.1V 9B Thinking es un modelo de IA innovador porque puede ver imágenes y explicar su razonamiento paso a paso. Esto se denomina razonamiento de cadena de pensamiento (CoT), y GLM lo hace mejor que cualquier otro modelo de lenguaje-visión de su tamaño. Verás cómo se compara con modelos más grandes y cómo puedes probarlo tú mismo, incluso si no tienes una GPU costosa.
¿Qué cambios introdujo GLM 4.1V 9B Thinking en los modelos VLM?
Como el primer modelo VLM del mundo con razonamiento de cadena de pensamiento (CoT), GLM no solo ha impresionado con sus potentes capacidades, sino que también ha logrado reconocimiento por alcanzar un rendimiento comparable al de Qwen 2.5 72B, a pesar de ser un modelo mucho más pequeño de 9B. A continuación, analicemos más de cerca las especificaciones detalladas de GLM y los resultados de evaluación comparativa.
Atributos de GLM 4.1V 9B Thinking

¡Puedes iniciar una prueba gratuita directamente en Hugging Face!
¿Cómo logra GLM 4.1V 9B Thinking estas mejoras?
- Refuerzo de SFT (Supervised Fine-Tuning):
Las muestras de entrenamiento incluyen anotaciones explícitas de Cadena de Pensamiento (CoT), por lo que el modelo aprende a “pensar primero, luego responder”. Esto difiere de los modelos tradicionales que solo generan una respuesta sin mostrar los pasos de razonamiento. - Refuerzo con RLCS (Reinforcement Learning from Chain-of-Thought Supervision):
La recompensa del modelo no se basa únicamente en la corrección, sino que también evalúa la calidad del proceso de razonamiento y las explicaciones, fomentando un pensamiento interno más coherente y completo. - Soporte arquitectónico:
Un codificador de visión ViT se alimenta a un proyector MLP y luego al decodificador LLM, lo que permite al modelo generar sin problemas rutas de razonamiento explícitas a partir de la entrada visual, en lugar de una mera recuperación o coincidencia de patrones. - Base de razonamiento sólida:
Y otro factor clave: el modelo base (GLM‑4‑9B 0414) ya posee habilidades de razonamiento robustas. Por ejemplo:- Demuestra un excelente razonamiento matemático y rendimiento en tareas generales, ubicándose en los primeros lugares entre los modelos de código abierto de su tamaño.
- Arquitectónicamente y en su entrenamiento, GLM‑4‑9B se beneficia de un preentrenamiento autoregresivo de relleno de espacios en blanco y un ajuste fino posterior que fortalecen las habilidades de razonamiento lógico y de múltiples pasos.
Puedes obtener más detalles en el artículo: GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning.
GLM 4.1V 9B Thinking vs Qwen 2.5 VL 72B
| Benchmark | GLM 4.1V 9B Thinking | Qwen 2.5 VL 72B | Ganador |
|---|---|---|---|
| MMMU (imagen) | 68.0 | 70.2 | Qwen 2.5 VL |
| MMMU‑Pro | 57.1 | 51.1 | GLM |
| VideoMMMU | 61.0 | 60.2 | GLM |
| mvBench (video) | 70.4 | 64.6 | GLM |
| AITZ_EM (agente) | 83.2 | 35.3* | GLM |
| Agente (OSWorld) | 14.9 | 8.8 | GLM |
| Agente (AndroidWorld) | 41.7 | 35.0 | GLM |
| Agente (WebVoyageSom) | 69.0 | 40.4 | GLM |
| Agente (Webquest‑SingleQA) | 72.1 | 60.5 | GLM |
| Agente (Webquest‑MultiQA) | 54.7 | 52.1 | GLM |
| Codificación (Design2Code) | 64.7 | 41.9 | GLM |
| Codificación (Flame‑VLM‑Code) | 72.5 | 46.3 | GLM |
| OCRBench | 84.2 | 85.1 | Qwen 2.5 VL |
| VideoMME (sin texto) | 68.2 | 73.3 | Qwen 2.5 VL |
| VideoMME (con texto) | 73.6 | 79.1 | Qwen 2.5 VL |
| MMVU | 59.4 | 62.9 | Qwen 2.5 VL |
Elige GLM 4.1V 9B Thinking si tu prioridad es el razonamiento multimodal, capacidades de agente, resolución de problemas STEM o codificación.
Elige Qwen 2.5 VL 72B si te centras en la comprensión de documentos, imágenes o video, especialmente OCR, extracción estructurada y percepción visual.
Si deseas conocer más detalles, consulta este artículo: GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: ¿Cuál se adapta a cada escenario?
También incluye una comparación con otros modelos líderes.
De THUDM
Cómo acceder a GLM 4.1V 9B Thinking?
1. Acceso Local
Aún más impresionante, GLM 4.1V 9B Thinking tiene solo 9 mil millones de parámetros, lo que permite ejecutarlo en GPUs como la RTX 4090 o incluso la 3090. En comparación con otros modelos con varias veces más parámetros, GLM logra un rendimiento excepcional con un tamaño mucho más pequeño, un logro que sin duda destaca el poder del aprendizaje por refuerzo.
De THUDM
Guía de Instalación
Instalación:
pip install git+https://github.com/huggingface/transformers.git
Uso básico:
from transformers import AutoProcessor, Glm4vForConditionalGeneration
import torch
MODEL_PATH = "THUDM/GLM-4.1V-9B-Thinking"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://upload.wikimedia.org/wikipedia/commons/f/fa/Grayscale_8bits_palette_sample_image.png"
},
{
"type": "text",
"text": "describe this image"
}
],
}
]
processor = AutoProcessor.from_pretrained(MODEL_PATH, use_fast=True)
model = Glm4vForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
Si comprar una GPU resulta demasiado costoso, puedes aprovechar las GPUs en la nube rentables y confiables de Novita AI, como la RTX 4090 por solo $0.69 la hora o la RTX 3090 por solo $0.21 la hora.
2. Integración Directa con API
Paso 1: Inicia Sesión y Accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de Modelos.

Paso 2: Elige tu Modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
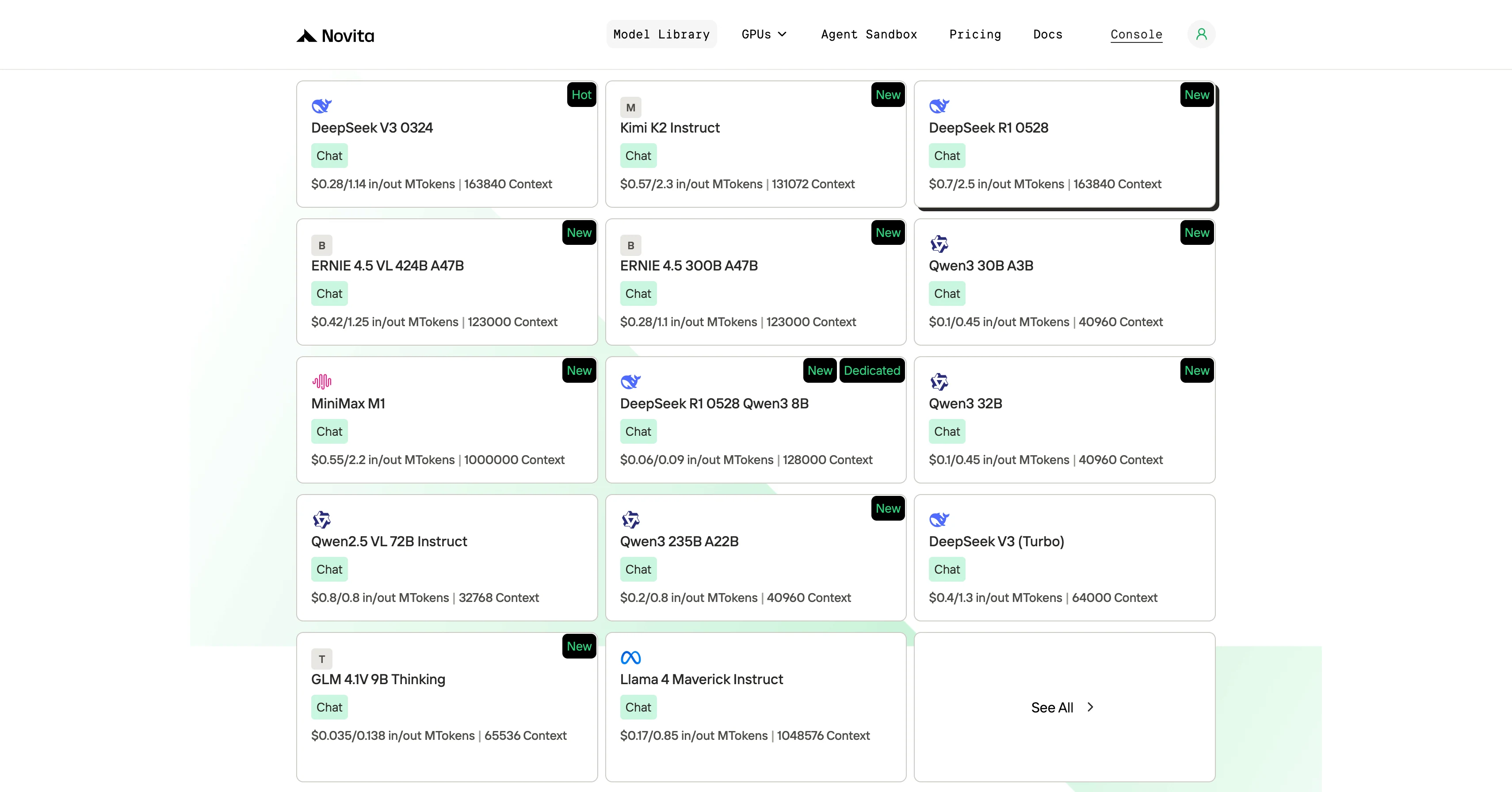
Paso 3: Comienza tu Prueba Gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
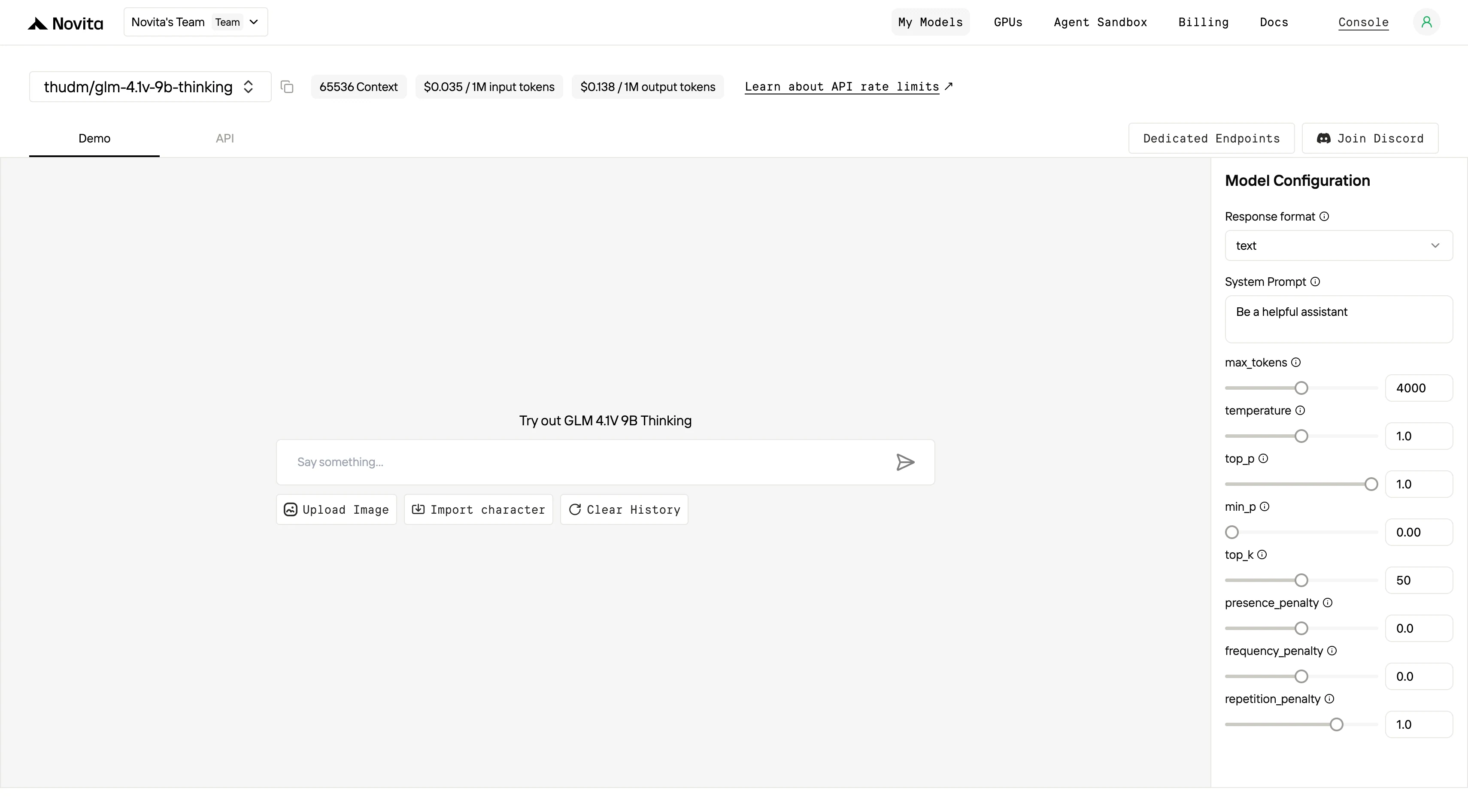
Paso 4: Obtén tu Clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página de “Configuración” y copia la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el administrador de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_kgNdXtDPt2zYc95i-nDWPaW4Zl_e7nf4VDpukuIVBKpko1-LE8xCasG4YK7c-3c1xnPzGYRuocFk_DhkPUUQyQ==",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # or False
max_tokens = 4000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Construye una Herramienta Simple de Reconocimiento de Imágenes usando MCP y GLM.
Si deseas aprovechar las capacidades de GLM (por ejemplo, construir una herramienta simple de reconocimiento de imágenes para demostrar su integración de reconocimiento visual y razonamiento), puedes usar la funcionalidad MCP compatible con Novita AI. A continuación se muestra el código de ejemplo:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
Si deseas obtener más detalles, puedes consultar este artículo: Cómo construir tu primer servidor MCP con Novita AI
GLM 4.1V 9B Thinking es fácil de usar, súper inteligente y no necesita hardware sofisticado. Puedes probar sus capacidades de reconocimiento de imágenes y razonamiento con solo unas pocas líneas de código, ya sea en tu propia máquina o en la nube. Si quieres ver hasta dónde ha llegado la IA multimodal, ¡prueba GLM!
¿Qué tiene de especial GLM 4.1V 9B Thinking?
Es el primer modelo que puede “ver” y mostrar sus pasos de razonamiento, no solo dar respuestas.
¿Puedo probar GLM 4.1V 9B si no tengo una GPU potente?
¡Sí! Puedes usar GPUs en la nube asequibles o probarlo gratis en Novita AI Playground.
¿Cómo puedo integrar GLM 4.1V 9B Thinking en mis propios proyectos?
Puedes ejecutarlo localmente usando Python y Hugging Face, acceder a él a través de la API de Novita AI, o incluso construir tus propias herramientas de reconocimiento de imágenes usando MCP como se muestra en los ejemplos de código proporcionados.
Novita AI es la plataforma en la nube integral que impulsa tus ambiciones de IA. APIs integradas, sin servidor, instancias GPU: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



