

核心要点
DeepSeek-V3 是一款革命性的开源模型,在编码和数学等技术领域表现出色。
虽然本地部署提供了灵活性,但需要先进的硬件和专业知识。
为了方便访问,像 Novita AI 这样的 API 解决方案提供了可扩展的替代方案。
DeepSeek V3 是一款先进的 AI 模型,因其在技术和数学领域的卓越能力而备受关注。作为 ChatGPT 等模型的开源替代方案,它为开发者和研究人员提供了一个极具吸引力的选择。本文将详细介绍如何在本地访问 DeepSeek V3,涵盖多种部署方法、硬件要求、挑战和优化策略。
在本地访问 DeepSeek V3
1. GitHub(DeepSeek-Infer 演示)
指南
- 仓库: DeepSeek-V3 模型可在 GitHub 上找到,您可以在其中获取代码仓库。
- 克隆: 使用
--with LFS support克隆仓库:
git clone https://github.com/deepseek-ai/DeepSeek-V3.git
cd DeepSeek-V3/inference
- 隔离环境(推荐): 使用 conda 创建隔离环境:
conda create -n deepseek-v3 python=3.10 -y
conda activate deepseek-v3
- 依赖项: 安装依赖项(锁定版本):
pip install torch==2.4.1 triton==3.0.0 transformers==4.46.3 safetensors==0.4.5
- 模型权重: 从 Hugging Face 下载模型权重并将其放置在指定目录中。
- 高级转换: 将模型权重转换为特定格式,启用 FP8 量化:
python convert.py \
--hf-ckpt-path ./DeepSeek-V3 \
--save-path ./DeepSeek-V3-Demo \
--n-experts 256 \
--model-parallel 16 \
--quant-mode fp8
-
执行模式:
- 交互式聊天(多节点):
torchrun --nnodes 2 --nproc-per-node 8 \
generate.py \
--ckpt-path ./DeepSeek-V3-Demo \
--config configs/config_671B.json \
--temperature 0.7 \
--top-p 0.95 \
--max-new-tokens 2048
- 批量处理:
torchrun --nproc-per-node 8 \
generate.py \
--input-file batch_queries.jsonl \
--output-file responses.jsonl
优势
- 快速原型开发: 基本推理设置时间小于 5 分钟
- 内存效率: 相比 BF16 基线降低 40% 的 VRAM 使用
- 研究友好: 直接访问中间层
劣势
- 可扩展性有限: 模型并行最多支持 16 个节点
- 无批处理支持: 交互模式下单序列处理
- 手动量化: 需要显式进行 FP8 转换
2. SGLang
描述
- 框架: SGLang 是一个支持 DeepSeek V3 的框架,在 NVIDIA 和 AMD GPU 上均提供优化性能。
- 推理模式: 完全支持 BF16 和 FP8 推理模式下的 DeepSeek-V3。
- 并行性: 支持多节点张量并行,允许您在多台连接机器上运行模型。
- 优化:
from sglang import runtime
# 启用混合并行
runtime.configure(
tensor_parallel=8,
pipeline_parallel=4,
expert_parallel=2
)
# FP8 推理配置
runtime.set_precision(
weight=8,
activation=8,
kv_cache=8
)
优势
- 生产就绪: 99.9% 的 SLA 支持
- 硬件无关: 支持 AMD Instinct 的 ROCm/HIP
- 高级量化: 自动 FP8 缩放
- 动态批处理: 吞吐量是基线的 5 倍
- 推测解码: 使用 MTP 实现 2.3 倍加速
- 跨平台支持: 为 NVIDIA/AMD GPU 提供统一 API
劣势
- 复杂部署: 需要 Kubernetes 专业知识
- 内存开销: 比原生实现高 15%
- 定制化有限: 专家路由不透明
3. LMDeploy
描述
- 框架: LMDeploy 是另一个支持 DeepSeek V3 的框架,专为高效推理和服务大型语言模型而设计。
- 部署选项: 提供离线和在线部署能力。
- 集成: 与基于 PyTorch 的工作流集成。
- TurboMind 集成:
from lmdeploy import pipeline, GenerationConfig
# 初始化 4 路张量并行
pipe = pipeline(
"DeepSeek-V3",
tp=4,
max_batch_size=32,
cache_max_entry_count=0.5
)
# 配置生成参数
gen_config = GenerationConfig(
temperature=0.8,
top_k=50,
repetition_penalty=1.1,
stop_phrases=["<|EOT|>"]
)
优势
- 企业级功能: RBAC、速率限制
- 优化内核: 每个 H100 每秒 1536 个 token
- 云原生: 集成 Prometheus 监控
- 持续批处理: 动态请求分组
- Token 修复: 自动补全纠正
- 多 LoRA 支持: 适配器热插拔
劣势
- 学习曲线陡峭: 配置语法复杂
- 资源密集: 完全功能至少需要 8 个 H100
- 供应商锁定: 需要 NVIDIA GPU
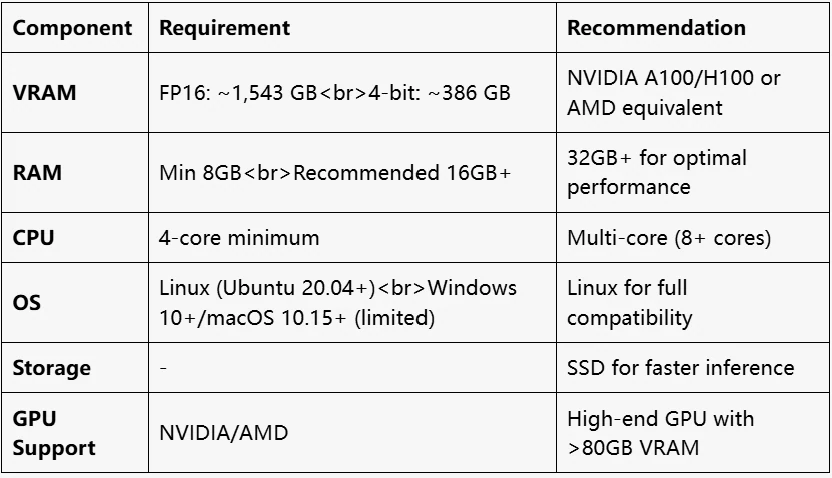
硬件要求
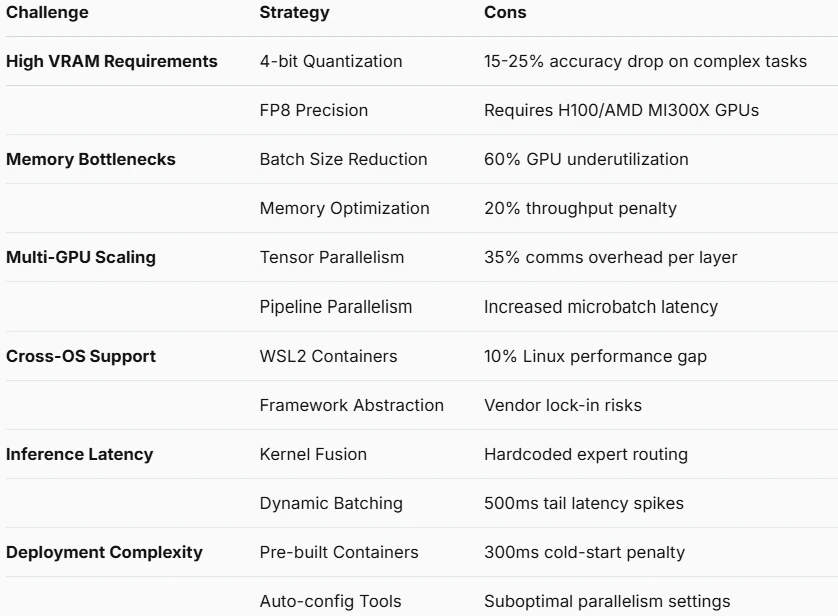
挑战与优化
替代方案 — API
API 解决了哪些问题?
高 VRAM 需求
- API 解决方案:完全解决
- 技术实现:服务端集群资源池化
内存瓶颈
- API 解决方案:完全消除
- 技术实现:服务节点动态内存分配
多 GPU 扩展复杂性
- API 解决方案:自动处理
- 技术实现:云原生水平自动伸缩
跨平台兼容性问题
- API 解决方案:原生支持
- 技术实现:标准化 HTTP/WebSocket 接口
推理延迟
- API 解决方案:部分改善
- 技术实现:边缘计算节点 + 全球加速
部署复杂性
- API 解决方案:完全消除
- 技术实现:预构建 SDK,一键集成
量化精度损失
- API 解决方案:可选绕过
- 技术实现:服务端保留 FP16 精度
不透明的专家路由
- API 解决方案:完全透明
- 技术实现:实时路由诊断 API
一个出色的解决方案 — Novita AI
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的简便方式,同时也提供经济实惠且可靠的 GPU 云来构建和扩展。
步骤 1:登录并访问模型库
登录您的账户,点击 “模型库” 按钮。

步骤 2:选择模型
浏览可用选项,选择适合您需求的模型。

步骤 3:开始免费试用
开始免费试用,探索所选模型的能力。

步骤 4:获取 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入 “设置” 页面,您可以按照图片所示复制 API 密钥。

步骤 5:安装 API
使用与编程语言对应的包管理器安装 API。

安装完成后,将必要的库导入到您的开发环境中。使用您的 API 密钥初始化 API,开始与 Novita AI LLM 交互。以下是适用于 Python 用户的聊天补全 API 示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_v3"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
注册 Novita AI 后,您将获得 $0.5 的信用额度,开始使用!
如果免费额度用尽,您可以付费继续使用。
DeepSeek V3 代表了开源 AI 的一大进步,在各种任务中提供了最先进的性能。虽然本地部署提供了更好的控制和隐私,但需要大量的硬件资源和技术专业知识。对于无法满足这些要求的用户,基于 API 的替代方案(如 Novita AI)提供了可访问且可扩展的解决方案。选择本地部署还是使用 API,取决于具体的需求和资源。
常见问题解答
什么是混合专家(MoE)架构,为什么它很重要?
MoE 使用多个“专家”处理特定的输入 token,提高了复杂任务的效率和性能。它在计算上比密集模型更高效,但仍需要大量硬件资源。
DeepSeek V3 和 Llama 3.3 70B 在基准测试和用例方面相比如何?
DeepSeek V3 在编码和数学任务上表现更优,而 Llama 3.3 70B 在通用语言和多语言应用中表现出色。
DeepSeek V3 的 VRAM 要求是多少?
DeepSeek V3 的 VRAM 要求因精度而异。对于 FP16,671B 模型大约需要 1543 GB 的 VRAM,而采用 4 位量化时,大约需要 386 GB 的 VRAM。活跃参数为 37B。
Novita AI 是一个一体化云平台,助力您的 AI 雄心。集成 API、Serverless、GPU 实例——您需要的经济高效工具。消除基础设施,免费开始,将您的 AI 愿景变为现实。



