

Puntos Clave
DeepSeek-V3 es un modelo revolucionario de código abierto que destaca en áreas técnicas como programación y matemáticas.
Aunque la implementación local ofrece flexibilidad, requiere hardware avanzado y experiencia.
Para un acceso más sencillo, soluciones API como Novita AI ofrecen alternativas escalables.
DeepSeek V3 es un modelo de IA avanzado que ha captado gran atención por sus impresionantes capacidades, especialmente en dominios técnicos y matemáticos. Como alternativa de código abierto a modelos como ChatGPT, representa una opción atractiva para desarrolladores e investigadores. Este artículo proporciona una guía detallada sobre cómo acceder a DeepSeek V3 localmente, cubriendo varios métodos de implementación, requisitos de hardware, desafíos y estrategias de optimización.
Accediendo a DeepSeek V3 Localmente
1. GitHub (Demo de DeepSeek-Infer)
Guía
- Repositorio: El modelo DeepSeek-V3 está disponible en GitHub, donde puedes encontrar el repositorio de código.
- Clonación: Clona el repositorio con soporte LFS usando:
git clone https://github.com/deepseek-ai/DeepSeek-V3.git
cd DeepSeek-V3/inference
- Entorno Aislado (Recomendado): Crea un entorno aislado usando conda:
conda create -n deepseek-v3 python=3.10 -y
conda activate deepseek-v3
- Dependencias: Instala las dependencias con bloqueo de versiones:
pip install torch==2.4.1 triton==3.0.0 transformers==4.46.3 safetensors==0.4.5
- Pesos del Modelo: Descarga los pesos del modelo desde Hugging Face y colócalos en el directorio designado.
- Conversión Avanzada: Convierte los pesos del modelo a un formato específico, habilitando la cuantización FP8:
python convert.py \
--hf-ckpt-path ./DeepSeek-V3 \
--save-path ./DeepSeek-V3-Demo \
--n-experts 256 \
--model-parallel 16 \
--quant-mode fp8
-
Modos de Ejecución:
- Chat Interactivo (Multi-nodo):
torchrun --nnodes 2 --nproc-per-node 8 \
generate.py \
--ckpt-path ./DeepSeek-V3-Demo \
--config configs/config_671B.json \
--temperature 0.7 \
--top-p 0.95 \
--max-new-tokens 2048
- Procesamiento por Lotes:
torchrun --nproc-per-node 8 \
generate.py \
--input-file batch_queries.jsonl \
--output-file responses.jsonl
Ventajas
- Prototipado Rápido: Configuración básica en <5 minutos
- Eficiencia de Memoria: 40% menos uso de VRAM comparado con la línea base BF16
- Amigable para Investigación: Acceso directo a capas intermedias
Desventajas
- Escalabilidad Limitada: Máximo 16 nodos en paralelismo de modelo
- Sin Soporte de Lotes: Procesamiento de una sola secuencia al usar modo interactivo
- Cuantización Manual: Requiere conversión FP8 explícita
2. SGLang
Descripción
- Framework: SGLang es un framework que soporta DeepSeek V3, ofreciendo rendimiento optimizado tanto para GPUs NVIDIA como AMD.
- Modos de Inferencia: Soporta completamente DeepSeek-V3 en modos de inferencia BF16 y FP8.
- Paralelismo: Soporta paralelismo tensorial multi-nodo, permitiendo ejecutar el modelo en varias máquinas conectadas.
- Optimización:
from sglang import runtime
# Habilitar paralelismo híbrido
runtime.configure(
tensor_parallel=8,
pipeline_parallel=4,
expert_parallel=2
)
# Perfil de Inferencia FP8
runtime.set_precision(
weight=8,
activation=8,
kv_cache=8
)
Ventajas
- Listo para Producción: Soporte SLA con 99.9% de disponibilidad
- Independiente del Hardware: Soporte ROCm/HIP para AMD Instinct
- Cuantización Avanzada: Escalado FP8 automático
- Agrupación Dinámica: 5x de rendimiento frente a la línea base
- Decodificación Especulativa: 2.3x de aceleración usando MTP
- Soporte Multiplataforma: API unificada para GPUs NVIDIA/AMD
Desventajas
- Implementación Compleja: Requiere experiencia en Kubernetes
- Sobrecarga de Memoria: 15% más alta que la implementación nativa
- Personalización Limitada: Enrutamiento de expertos opaco
3. LMDeploy
Descripción
- Framework: LMDeploy es otro framework que soporta DeepSeek V3, diseñado para inferencia y servicio eficientes de grandes modelos de lenguaje.
- Opciones de Implementación: Ofrece capacidades de implementación tanto offline como online.
- Integración: Se integra con flujos de trabajo basados en PyTorch.
- Integración con TurboMind:
from lmdeploy import pipeline, GenerationConfig
# Inicializar paralelismo tensorial 4 vías
pipe = pipeline(
"DeepSeek-V3",
tp=4,
max_batch_size=32,
cache_max_entry_count=0.5
)
# Configurar parámetros de generación
gen_config = GenerationConfig(
temperature=0.8,
top_k=50,
repetition_penalty=1.1,
stop_phrases=["<|EOT|>"]
)
Ventajas
- Funcionalidades Empresariales: RBAC, Límite de Tasa
- Kernels Optimizados: 1536 tokens/segundo por H100
- Nativo en la Nube: Integración con monitorización Prometheus
- Agrupación Continua: Agrupación dinámica de solicitudes
- Token Healing: Corrección automática de completado
- Soporte Multi-LoRA: Intercambio en caliente de adaptadores
Desventajas
- Curva de Aprendizaje Pronunciada: Sintaxis de configuración compleja
- Intensivo en Recursos: Mínimo 8x H100 para funciones completas
- Dependencia del Proveedor: Requiere GPUs NVIDIA
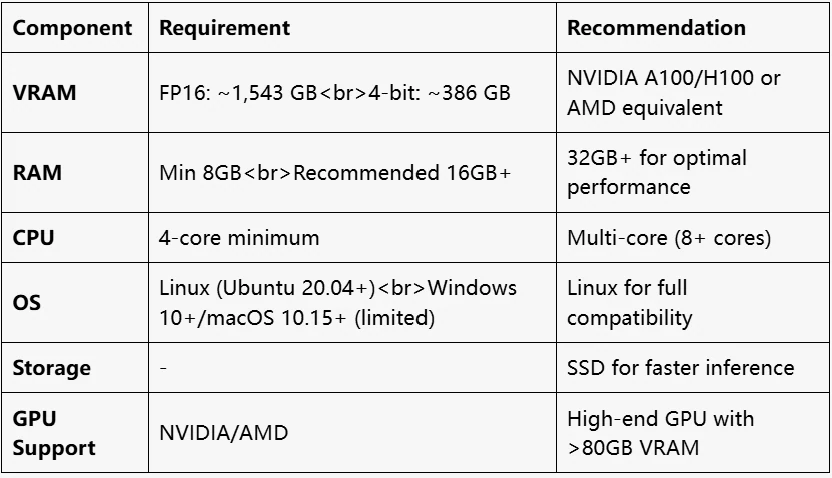
Requisitos de Hardware
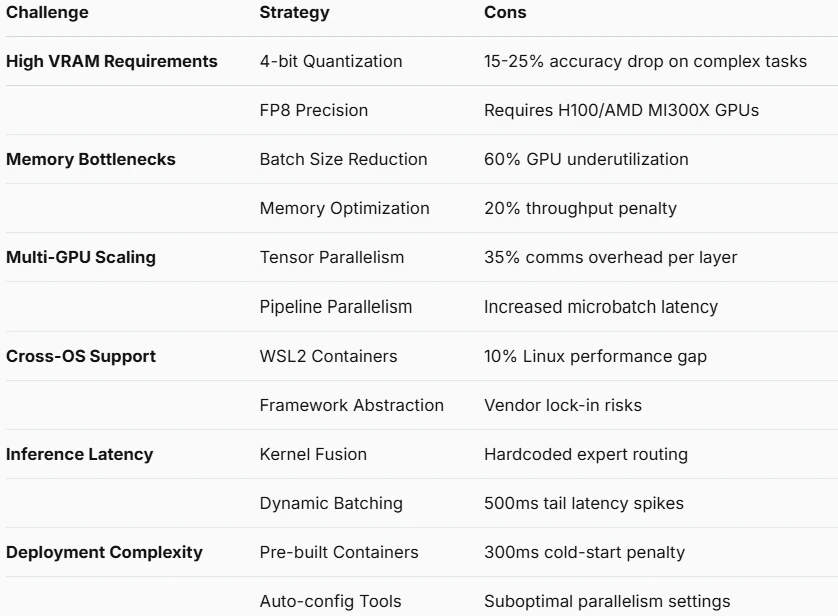
Desafíos y Optimización
Opción Alternativa – API
¿Qué Problemas Resuelve la API?
Altos Requisitos de VRAM
- Solución API: Resolución completa
- Implementación Técnica: Agrupación de recursos en clúster del lado del servidor
Cuellos de Botella de Memoria
- Solución API: Eliminación completa
- Implementación Técnica: Asignación dinámica de memoria en nodos del servidor
Complejidad de Escalado Multi-GPU
- Solución API: Manejo automático
- Implementación Técnica: Autoescalado horizontal nativo en la nube
Problemas de Compatibilidad Multi-SO
- Solución API: Soporte nativo
- Implementación Técnica: Interfaces estandarizadas HTTP/WebSocket
Latencia de Inferencia
- Solución API: Mejora parcial
- Implementación Técnica: Nodos de computación en el borde + aceleración global
Complejidad de Implementación
- Solución API: Eliminación completa
- Implementación Técnica: SDK preconstruido con integración en una línea
Pérdida de Precisión por Cuantización
- Solución API: Omisión opcional
- Implementación Técnica: Preservación de precisión FP16 en el servidor
Enrutamiento de Expertos Opaco
- Solución API: Transparencia total
- Implementación Técnica: API de diagnóstico de enrutamiento en tiempo real
Una Solución Excelente – Novita AI
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA usando nuestra API simple, mientras también proporciona la GPU en la nube asequible y confiable para construir y escalar.
Paso 1: Inicia Sesión y Accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige Tu Modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

¡Prueba DeepSeek V3 Demo Ahora!
Paso 3: Comienza Tu Prueba Gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.

Paso 4: Obtén Tu Clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página “Settings” y copia la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico para tu lenguaje de programación.

Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_v3"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Al registrarte, Novita AI proporciona un crédito de $0.5 para empezar.
Si el crédito gratuito se agota, puedes pagar para seguir usándolo.
DeepSeek V3 representa un avance significativo en la IA de código abierto, ofreciendo rendimiento de última generación en diversas tareas. Si bien la implementación local proporciona mayor control y privacidad, requiere recursos de hardware sustanciales y experiencia técnica. Para aquellos que no pueden cumplir con estos requisitos, alternativas basadas en API como Novita AI ofrecen una solución accesible y escalable. La elección entre implementación local y uso de API depende de las necesidades y recursos específicos.
Preguntas Frecuentes
¿Qué es la arquitectura Mezcla de Expertos (MoE) y por qué es importante?
MoE utiliza múltiples “expertos” para procesar tokens de entrada específicos, mejorando la eficiencia y el rendimiento en tareas complejas. Es más eficiente computacionalmente que los modelos densos, pero sigue siendo intensivo en hardware.
¿Cómo se comparan DeepSeek V3 y Llama 3.3 70B en términos de benchmarks y casos de uso?
DeepSeek V3 es superior para tareas de programación y matemáticas, mientras que Llama 3.3 70B brilla en aplicaciones de lenguaje general y multilingüe.
¿Cuáles son los requisitos de VRAM para DeepSeek V3?
Los requisitos de VRAM para DeepSeek V3 varían según la precisión. Para FP16, el modelo de 671B requiere aproximadamente 1,543 GB de VRAM, mientras que con cuantización de 4 bits, requiere aproximadamente 386 GB de VRAM. Los parámetros activos son 37B.
Novita AI es la plataforma en la nube integral que impulsa tus ambiciones de IA. API integradas, sin servidor, instancias GPU: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



