

Points clés
DeepSeek-V3 est un modèle open-source révolutionnaire qui excelle dans les domaines techniques comme le codage et les mathématiques.
Bien que le déploiement local offre de la flexibilité, il nécessite du matériel avancé et une expertise.
Pour un accès plus facile, des solutions API comme Novita AI offrent des alternatives évolutives.
DeepSeek V3 est un modèle d’IA avancé qui a suscité une attention considérable pour ses capacités impressionnantes, en particulier dans les domaines techniques et mathématiques. En tant qu’alternative open-source à des modèles comme ChatGPT, il constitue une option intéressante pour les développeurs et les chercheurs. Cet article fournit un guide détaillé sur la façon d’accéder à DeepSeek V3 localement, couvrant diverses méthodes de déploiement, les exigences matérielles, les défis et les stratégies d’optimisation.
Accéder à DeepSeek V3 localement
1. GitHub (demo DeepSeek-Infer)
Guide
- Dépôt : Le modèle DeepSeek-V3 est disponible sur GitHub, où vous trouverez le dépôt de code.
- Clonage : Clonez le dépôt avec support LFS en utilisant :
git clone https://github.com/deepseek-ai/DeepSeek-V3.git
cd DeepSeek-V3/inference
- Environnement isolé (recommandé) : Créez un environnement isolé avec conda :
conda create -n deepseek-v3 python=3.10 -y
conda activate deepseek-v3
- Dépendances : Installez les dépendances avec verrouillage de version :
pip install torch==2.4.1 triton==3.0.0 transformers==4.46.3 safetensors==0.4.5
- Poids du modèle : Téléchargez les poids du modèle depuis Hugging Face et placez-les dans le répertoire désigné.
- Conversion avancée : Convertissez les poids du modèle dans un format spécifique, activant la quantification FP8 :
python convert.py \
--hf-ckpt-path ./DeepSeek-V3 \
--save-path ./DeepSeek-V3-Demo \
--n-experts 256 \
--model-parallel 16 \
--quant-mode fp8
-
Modes d’exécution :
- Chat interactif (multi-nœuds) :
torchrun --nnodes 2 --nproc-per-node 8 \
generate.py \
--ckpt-path ./DeepSeek-V3-Demo \
--config configs/config_671B.json \
--temperature 0.7 \
--top-p 0.95 \
--max-new-tokens 2048
- Traitement par lots :
torchrun --nproc-per-node 8 \
generate.py \
--input-file batch_queries.jsonl \
--output-file responses.jsonl
Avantages
- Prototypage rapide : <5 minutes de configuration pour une inférence de base
- Efficacité mémoire : 40 % de mémoire VRAM en moins par rapport à la baseline BF16
- Adapté à la recherche : Accès direct aux couches intermédiaires
Inconvénients
- Évolutivité limitée : Maximum 16 nœuds en parallélisme de modèle
- Pas de support par lots : Traitement de séquence unique en mode interactif
- Quantification manuelle : Nécessite une conversion FP8 explicite
2. SGLang
Description
- Framework : SGLang est un framework qui prend en charge DeepSeek V3, offrant des performances optimisées pour les GPU NVIDIA et AMD.
- Modes d’inférence : Prend en charge DeepSeek-V3 en modes BF16 et FP8.
- Parallélisme : Supporte le parallélisme tensoriel multi-nœuds, permettant d’exécuter le modèle sur plusieurs machines connectées.
- Optimisation :
from sglang import runtime
# Activer le parallélisme hybride
runtime.configure(
tensor_parallel=8,
pipeline_parallel=4,
expert_parallel=2
)
# Profil d'inférence FP8
runtime.set_precision(
weight=8,
activation=8,
kv_cache=8
)
Avantages
- Prêt pour la production : Support SLA avec 99,9 % de disponibilité
- Indépendant du matériel : Support ROCm/HIP pour AMD Instinct
- Quantification avancée : Mise à l’échelle FP8 automatique
- Batching dynamique : Débit 5x supérieur à la baseline
- Décodage spéculatif : Accélération de 2,3x avec MTP
- Support multiplateforme : API unifiée pour GPU NVIDIA/AMD
Inconvénients
- Déploiement complexe : Nécessite une expertise Kubernetes
- Surcharge mémoire : 15 % de plus que l’implémentation native
- Personnalisation limitée : Routage opaque des experts
3. LMDeploy
Description
- Framework : LMDeploy est un autre framework prenant en charge DeepSeek V3, conçu pour l’inférence et le service efficaces des grands modèles de langage.
- Options de déploiement : Propose des capacités de déploiement hors ligne et en ligne.
- Intégration : S’intègre aux workflows basés sur PyTorch.
- Intégration TurboMind :
from lmdeploy import pipeline, GenerationConfig
# Initialiser le parallélisme tensoriel 4 voies
pipe = pipeline(
"DeepSeek-V3",
tp=4,
max_batch_size=32,
cache_max_entry_count=0.5
)
# Configurer les paramètres de génération
gen_config = GenerationConfig(
temperature=0.8,
top_k=50,
repetition_penalty=1.1,
stop_phrases=["<|EOT|>"]
)
Avantages
- Fonctionnalités entreprise : RBAC, limitation de débit
- Noyaux optimisés : 1536 jetons/s par H100
- Cloud natif : Intégration de la surveillance Prometheus
- Batching continu : Regroupement dynamique des requêtes
- Correction de jetons : Correction automatique des complétions
- Support Multi-LoRA : Échange à chaud d’adaptateurs
Inconvénients
- Courbe d’apprentissage abrupte : Syntaxe de configuration complexe
- Gourmand en ressources : Minimum 8x H100 pour toutes les fonctionnalités
- Verrouillage fournisseur : Nécessite des GPU NVIDIA
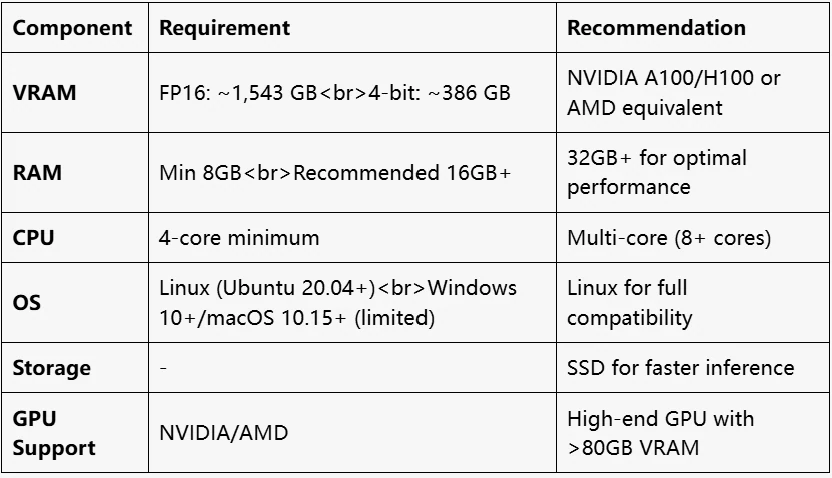
Exigences matérielles
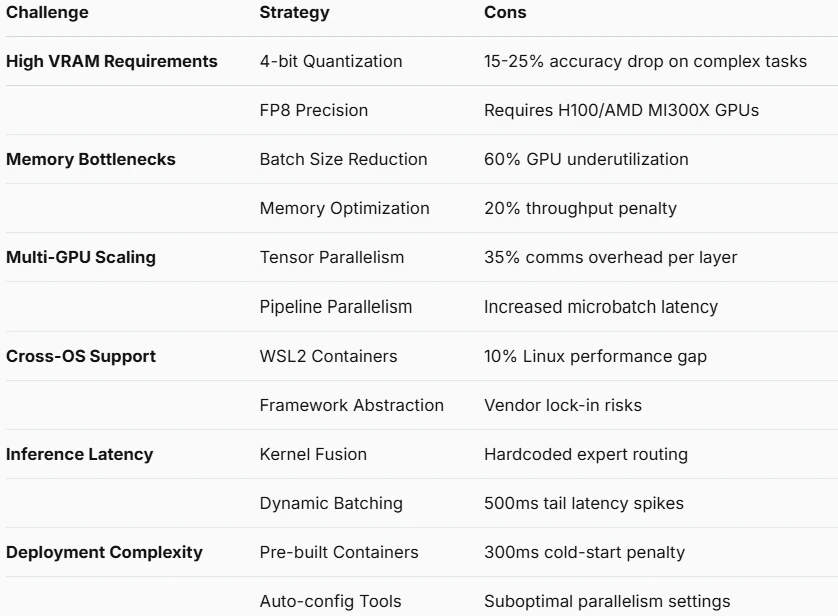
Défis et optimisation
Option alternative : API
Que résout l’API ?
Besoins élevés en VRAM
- Solution API : Pleine résolution
- Implémentation technique : Mutualisation des ressources du cluster côté serveur
Goulots d’étranglement mémoire
- Solution API : Élimination complète
- Implémentation technique : Allocation mémoire dynamique sur les nœuds serveur
Complexité de mise à l’échelle multi-GPU
- Solution API : Gestion automatique
- Implémentation technique : Mise à l’échelle horizontale automatique cloud-native
Problèmes de compatibilité inter-OS
- Solution API : Support natif
- Implémentation technique : Interfaces HTTP/WebSocket standardisées
Latence d’inférence
- Solution API : Amélioration partielle
- Implémentation technique : Nœuds de calcul en périphérie + accélération globale
Complexité de déploiement
- Solution API : Élimination complète
- Implémentation technique : SDK pré-construit avec intégration en une ligne
Perte de précision due à la quantification
- Solution API : Contournement optionnel
- Implémentation technique : Préservation de la précision FP16 côté serveur
Routage opaque des experts
- Solution API : Transparence totale
- Implémentation technique : API de diagnostic de routage en temps réel
Une solution géniale : Novita AI
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API, tout en fournissant un cloud GPU fiable et abordable pour construire et passer à l’échelle.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Essayez la démo DeepSeek V3 maintenant !
Étape 3 : Commencez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.

Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Dans la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_v3"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Lors de l’inscription, Novita AI offre un crédit de 0,5 $ pour vous lancer !
Si les crédits gratuits sont épuisés, vous pouvez payer pour continuer à utiliser le service.
DeepSeek V3 représente une avancée significative dans l’IA open-source, offrant des performances de pointe dans diverses tâches. Bien que le déploiement local offre plus de contrôle et de confidentialité, il nécessite des ressources matérielles substantielles et une expertise technique. Pour ceux qui ne peuvent pas répondre à ces exigences, des alternatives basées sur API comme Novita AI offrent une solution accessible et évolutive. Le choix entre le déploiement local et l’utilisation de l’API dépend des besoins et des ressources spécifiques.
Foire aux questions
Qu’est-ce que l’architecture Mixture-of-Experts (MoE) et pourquoi est-elle importante ?
MoE utilise plusieurs « experts » pour traiter des jetons d’entrée spécifiques, améliorant ainsi l’efficacité et les performances pour les tâches complexes. Elle est plus efficace sur le plan computationnel que les modèles denses, mais reste gourmande en matériel.
Comment DeepSeek V3 et Llama 3.3 70B se comparent-ils en termes de benchmarks et de cas d’utilisation ?
DeepSeek V3 est supérieur pour les tâches de codage et de mathématiques, tandis que Llama 3.3 70B excelle dans les applications linguistiques générales et multilingues.
Quelles sont les exigences VRAM pour DeepSeek V3 ?
Les exigences VRAM pour DeepSeek V3 varient selon la précision. Pour FP16, le modèle 671B nécessite environ 1 543 Go de VRAM, tandis qu’avec une quantification 4 bits, il nécessite environ 386 Go de VRAM. Les paramètres actifs sont de 37B.
Novita AI est la plateforme cloud tout-en-un qui donne vie à vos ambitions IA. API intégrées, serverless, GPU Instance — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et faites de votre vision IA une réalité.



