

النقاط الرئيسية
DeepSeek-V3 هو نموذج مفتوح المصدر ثوري يتفوق في المجالات التقنية مثل البرمجة والرياضيات.
بينما يوفر النشر المحلي مرونة، فإنه يتطلب أجهزة متطورة وخبرة متقدمة.
للسهولة، توفر حلول API مثل Novita AI بدائل قابلة للتوسع.
DeepSeek V3 هو نموذج ذكاء اصطناعي متقدم حظي باهتمام كبير لقدراته المذهلة، خاصة في المجالات التقنية والرياضية. كبديل مفتوح المصدر لنماذج مثل ChatGPT، فإنه يمثل خيارًا جذابًا للمطورين والباحثين. تقدم هذه المقالة دليلاً مفصلاً حول كيفية الوصول إلى DeepSeek V3 محليًا، مع تغطية طرق النشر المختلفة، متطلبات الأجهزة، التحديات، واستراتيجيات التحسين.
الوصول إلى DeepSeek V3 محليًا
1. GitHub (DeepSeek-Infer Demo)
الدليل
- المستودع: نموذج DeepSeek-V3 متاح على GitHub، حيث يمكنك العثور على مستودع الكود.
- الاستنساخ: استنساخ المستودع مع دعم LFS باستخدام:
git clone https://github.com/deepseek-ai/DeepSeek-V3.git
cd DeepSeek-V3/inference
- البيئة المنعزلة (موصى به): إنشاء بيئة منعزلة باستخدام conda:
conda create -n deepseek-v3 python=3.10 -y
conda activate deepseek-v3
- التبعيات: تثبيت التبعيات مع تثبيت الإصدارات:
pip install torch==2.4.1 triton==3.0.0 transformers==4.46.3 safetensors==0.4.5
- أوزان النموذج: تنزيل أوزان النموذج من Hugging Face ووضعها في الدليل المحدد.
- التحويل المتقدم: تحويل أوزان النموذج إلى تنسيق معين، مما يتيح تكميم FP8:
python convert.py \
--hf-ckpt-path ./DeepSeek-V3 \
--save-path ./DeepSeek-V3-Demo \
--n-experts 256 \
--model-parallel 16 \
--quant-mode fp8
-
أوضاع التنفيذ:
- الدردشة التفاعلية (متعددة العقد):
torchrun --nnodes 2 --nproc-per-node 8 \
generate.py \
--ckpt-path ./DeepSeek-V3-Demo \
--config configs/config_671B.json \
--temperature 0.7 \
--top-p 0.95 \
--max-new-tokens 2048
- المعالجة الجماعية:
torchrun --nproc-per-node 8 \
generate.py \
--input-file batch_queries.jsonl \
--output-file responses.jsonl
المزايا
- النمذجة السريعة: إعداد أقل من 5 دقائق للاستدلال الأساسي
- كفاءة الذاكرة: استخدام VRAM أقل بنسبة 40% مقارنة بخط الأساس BF16
- سهولة البحث: وصول مباشر إلى الطبقات الوسيطة
العيوب
- قابلية التوسع المحدودة: بحد أقصى 16 عقدة في التوازي النموذجي
- لا يدعم التجميع: معالجة تسلسل واحد عند استخدام الوضع التفاعلي
- التكميم اليدوي: يتطلب تحويل FP8 صريح
2. SGLang
الوصف
- الإطار: SGLang هو إطار يدعم DeepSeek V3، ويقدم أداءً محسنًا لكل من وحدات معالجة الرسومات NVIDIA و AMD.
- أوضاع الاستدلال: يدعم بشكل كامل DeepSeek-V3 في وضعي الاستدلال BF16 و FP8.
- التوازي: يدعم التوازي الموتر متعدد العقد، مما يسمح بتشغيل النموذج على عدة أجهزة متصلة.
- التحسين:
from sglang import runtime
# تمكين التوازي الهجين
runtime.configure(
tensor_parallel=8,
pipeline_parallel=4,
expert_parallel=2
)
# ملف تعريف استدلال FP8
runtime.set_precision(
weight=8,
activation=8,
kv_cache=8
)
المزايا
- جاهز للإنتاج: دعم SLA لتوفر 99.9%
- غير مرتبط بالأجهزة: دعم ROCm/HIP لـ AMD Instinct
- التكميم المتقدم: تحجيم FP8 تلقائي
- التجميع الديناميكي: إنتاجية أعلى 5 مرات من خط الأساس
- فك الترميز التخميني: تسريع 2.3x باستخدام MTP
- دعم عبر المنصات: واجهة برمجة تطبيقات موحدة لوحدات معالجة الرسومات NVIDIA/AMD
العيوب
- النشر المعقد: يتطلب خبرة في Kubernetes
- زيادة الذاكرة: أعلى بنسبة 15% من التنفيذ الأصلي
- التخصيص المحدود: توجيه الخبراء غير شفاف
3. LMDeploy
الوصف
- الإطار: LMDeploy هو إطار آخر يدعم DeepSeek V3، مصمم للاستدلال الفعال وخدمة نماذج اللغة الكبيرة.
- خيارات النشر: يقدم إمكانيات النشر دون اتصال وعبر الإنترنت.
- التكامل: يتكامل مع سير العمل المعتمدة على PyTorch.
- تكامل TurboMind:
from lmdeploy import pipeline, GenerationConfig
# تهيئة التوازي الموتر رباعي الاتجاهات
pipe = pipeline(
"DeepSeek-V3",
tp=4,
max_batch_size=32,
cache_max_entry_count=0.5
)
# تكوين معلمات التوليد
gen_config = GenerationConfig(
temperature=0.8,
top_k=50,
repetition_penalty=1.1,
stop_phrases=["<|EOT|>"]
)
المزايا
- ميزات المؤسسات: RBAC، تحديد المعدل
- النوى المحسنة: 1536 رمز في الثانية لكل H100
- سحابي أصلي: تكامل مراقبة Prometheus
- التجميع المستمر: تجميع الطلبات الديناميكي
- تصحيح الرموز: تصحيح تلقائي للإكمال
- دعم Multi-LoRA: التبديل السريع للمحولات
العيوب
- منحنى تعلم حاد: بناء جملة تكوين معقد
- كثيف الموارد: يتطلب 8x H100 على الأقل للميزات الكاملة
- الارتباط بالمورد: يتطلب وحدات معالجة رسومات NVIDIA
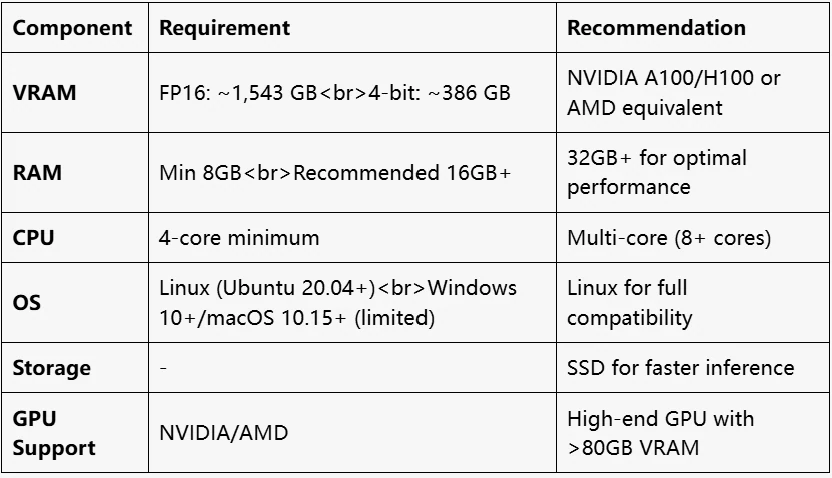
متطلبات الأجهزة
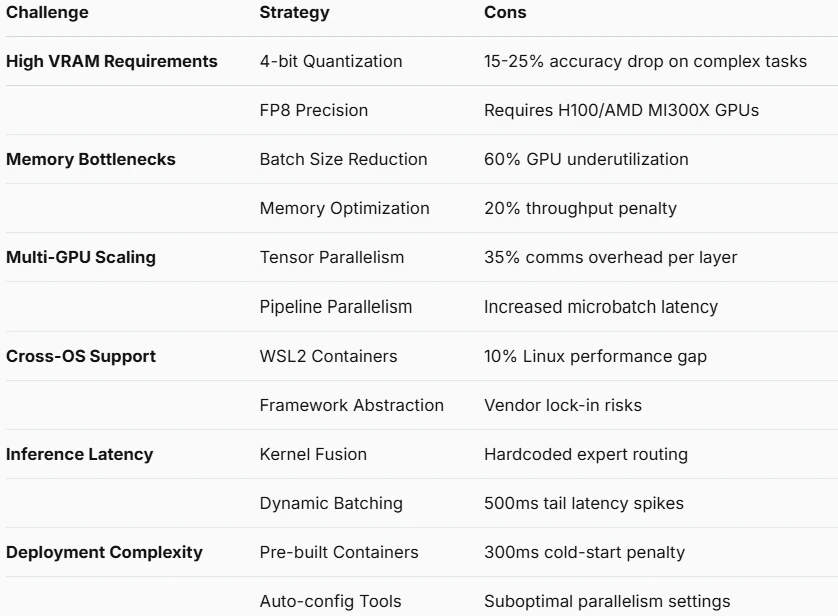
التحديات والتحسين
الخيار البديل - API
ما المشاكل التي يحلها API؟
متطلبات VRAM العالية
- حل API: دقة كاملة
- التنفيذ التقني: تجميع موارد الكتلة من جانب الخادم
اختناقات الذاكرة
- حل API: إزالة كاملة
- التنفيذ التقني: تخصيص الذاكرة الديناميكي على عقد الخادم
تعقيد توسيع نطاق وحدات معالجة الرسومات المتعددة
- حل API: معالجة تلقائية
- التنفيذ التقني: توسيع أفقي أصلي للسحابة
مشكلات التوافق عبر أنظمة التشغيل
- حل API: دعم أصلي
- التنفيذ التقني: واجهات HTTP/WebSocket موحدة
زمن استجابة الاستدلال
- حل API: تحسين جزئي
- التنفيذ التقني: عقد حوسبة طرفية + تسريع عالمي
تعقيد النشر
- حل API: إزالة كاملة
- التنفيذ التقني: SDK معد مسبقًا مع تكامل بسطر واحد
فقدان دقة التكميم
- حل API: تجاوز اختياري
- التنفيذ التقني: الحفاظ على دقة FP16 من جانب الخادم
توجيه الخبراء غير الشفاف
- حل API: شفافية كاملة
- التنفيذ التقني: API تشخيص التوجيه في الوقت الحقيقي
حل رائع - Novita AI
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API بسيط، مع توفير سحابة GPU موثوقة وبأسعار معقولة للبناء والتوسع.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر نموذجك
تصفح الخيارات المتاحة وحدد النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ النسخة التجريبية المجانية
ابدأ نسختك التجريبية المجانية لاستكشاف قدرات النموذج المحدد.

الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنقدم لك مفتاح API جديد. بالدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة الخاصة بك.

بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام API لإكمال الدردشة لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_v3"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
عند التسجيل، توفر Novita AI رصيدًا بقيمة $0.5 لتبدأ!
إذا تم استنفاد الرصيد المجاني، يمكنك الدفع لمواصلة الاستخدام.
يمثل DeepSeek V3 تقدمًا كبيرًا في الذكاء الاصطناعي مفتوح المصدر، حيث يقدم أداءً متطورًا في مهام متنوعة. بينما يوفر النشر المحلي تحكمًا أكبر وخصوصية، فإنه يتطلب موارد أجهزة كبيرة وخبرة تقنية. بالنسبة لأولئك الذين لا يستطيعون تلبية هذه المتطلبات، توفر البدائل القائمة على API مثل Novita AI حلاً يمكن الوصول إليه وقابل للتوسع. يعتمد الاختيار بين النشر المحلي واستخدام API على الاحتياجات والموارد المحددة.
الأسئلة الشائعة
ما هي بنية الخبراء المختلطين (MoE) ولماذا هي مهمة؟
تستخدم MoE العديد من “الخبراء” لمعالجة رموز إدخال محددة، مما يحسن الكفاءة والأداء للمهام المعقدة. إنها أكثر كفاءة من الناحية الحسابية من النماذج الكثيفة ولكنها لا تزال تتطلب أجهزة كثيفة.
كيف يقارن DeepSeek V3 و Llama 3.3 70B من حيث المعايير وحالات الاستخدام؟
يتفوق DeepSeek V3 في مهام البرمجة والرياضيات، بينما يتألق Llama 3.3 70B في التطبيقات اللغوية العامة ومتعددة اللغات.
ما هي متطلبات VRAM لـ DeepSeek V3؟
تختلف متطلبات VRAM لـ DeepSeek V3 بناءً على الدقة. بالنسبة لـ FP16، يتطلب نموذج 671B حوالي 1,543 جيجابايت من VRAM، بينما مع تكميم 4 بت، يتطلب حوالي 386 جيجابايت من VRAM. المعلمات النشطة هي 37B.
Novita AI هي المنصة السحابية الشاملة التي تمكن طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، بدون خادم، مثيلات GPU — الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجانًا، وحول رؤيتك للذكاء الاصطناعي إلى واقع.



