

主なハイライト
DeepSeek-V3 は、コーディングや数学などの技術分野で優れた性能を発揮する革新的なオープンソースモデルです。
ローカルデプロイは柔軟性を提供しますが、高度なハードウェアと専門知識が必要です。
より簡単にアクセスするには、Novita AI のような API ソリューションがスケーラブルな代替手段を提供します。
DeepSeek V3 は、特に技術分野や数学領域での優れた能力で大きな注目を集めている高度な AI モデルです。ChatGPT のようなモデルのオープンソース代替として、開発者や研究者にとって魅力的な選択肢です。この記事では、DeepSeek V3 をローカルで利用するための詳細なガイドを提供し、さまざまなデプロイ方法、ハードウェア要件、課題、最適化戦略を網羅します。
DeepSeek V3 をローカルで利用する
1. GitHub (DeepSeek-Infer Demo)
ガイド
- リポジトリ: DeepSeek-V3 モデルは GitHub で入手可能で、コードリポジトリを見つけることができます。
- クローン: LFS サポート付きで リポジトリをクローンします。
git clone https://github.com/deepseek-ai/DeepSeek-V3.git
cd DeepSeek-V3/inference
- 分離環境(推奨): Conda を使用して分離環境を作成します。
conda create -n deepseek-v3 python=3.10 -y
conda activate deepseek-v3
- 依存関係: バージョンを固定して 依存関係をインストールします。
pip install torch==2.4.1 triton==3.0.0 transformers==4.46.3 safetensors==0.4.5
- モデル重み: Hugging Face からモデル重みをダウンロードし、指定のディレクトリに配置します。
- 高度な変換: モデル重みを特定の形式に変換し、FP8 量子化を有効にします。
python convert.py \
--hf-ckpt-path ./DeepSeek-V3 \
--save-path ./DeepSeek-V3-Demo \
--n-experts 256 \
--model-parallel 16 \
--quant-mode fp8
-
実行モード:
- インタラクティブチャット(マルチノード):
torchrun --nnodes 2 --nproc-per-node 8 \
generate.py \
--ckpt-path ./DeepSeek-V3-Demo \
--config configs/config_671B.json \
--temperature 0.7 \
--top-p 0.95 \
--max-new-tokens 2048
- バッチ処理:
torchrun --nproc-per-node 8 \
generate.py \
--input-file batch_queries.jsonl \
--output-file responses.jsonl
利点
- 迅速なプロトタイピング: 基本的な推論のセットアップは5分未満
- メモリ効率: BF16 ベースライン比で VRAM 使用量 40% 削減
- 研究に好都合: 中間層への直接アクセス
欠点
- スケーラビリティの制限: モデル並列化で最大16ノード
- バッチ非対応: インタラクティブモード使用時 は単一シーケンス処理
- 手動量子化: 明示的な FP8 変換が必要
2. SGLang
説明
- フレームワーク: SGLang は DeepSeek V3 をサポートするフレームワークで、NVIDIA および AMD GPU の両方で最適化されたパフォーマンスを提供します。
- 推論モード: BF16 および FP8 の両方の推論モードで DeepSeek-V3 を完全サポート。
- 並列化: マルチノードテンソル並列化をサポートし、複数の接続されたマシンでモデルを実行可能。
- 最適化:
from sglang import runtime
# ハイブリッド並列化を有効化
runtime.configure(
tensor_parallel=8,
pipeline_parallel=4,
expert_parallel=2
)
# FP8 推論プロファイル
runtime.set_precision(
weight=8,
activation=8,
kv_cache=8
)
利点
- プロダクション対応: 99.9% の稼働時間 SLA サポート
- ハードウェア非依存: AMD Instinct 向け ROCm/HIP サポート
- 高度な量子化: 自動 FP8 スケーリング
- 動的バッチ処理: ベースライン比で 5 倍のスループット
- 投機的デコード: MTP 使用で 2.3 倍の高速化
- クロスプラットフォーム対応: NVIDIA/AMD GPU 向け統一 API
欠点
- 複雑なデプロイ: Kubernetes の専門知識が必要
- メモリオーバーヘッド: ネイティブ実装より 15% 高い
- カスタマイズの制限: エキスパートルーティングが不透明
3. LMDeploy
説明
- フレームワーク: LMDeploy は DeepSeek V3 をサポートする別のフレームワークで、大規模言語モデルの効率的な推論とサービング向けに設計されています。
- デプロイオプション: オフラインおよびオンラインの両方のデプロイ機能を提供。
- 統合: PyTorch ベースのワークフローと統合。
- TurboMind 統合:
from lmdeploy import pipeline, GenerationConfig
# 4-way テンソル並列を初期化
pipe = pipeline(
"DeepSeek-V3",
tp=4,
max_batch_size=32,
cache_max_entry_count=0.5
)
# 生成パラメータを設定
gen_config = GenerationConfig(
temperature=0.8,
top_k=50,
repetition_penalty=1.1,
stop_phrases=["<|EOT|>"]
)
利点
- エンタープライズ機能: RBAC、レート制限
- 最適化カーネル: H100 あたり毎秒1536トークン
- クラウドネイティブ: Prometheus モニタリング統合
- 継続的バッチ処理: 動的リクエストグループ化
- トークンヒーリング: 自動補完修正
- マルチ LoRA サポート: アダプターのホットスワップ
欠点
- 急な学習曲線: 複雑な設定構文
- リソース集約型: 全機能には最低 8x H100 が必要
- ベンダーロックイン: NVIDIA GPU が必要
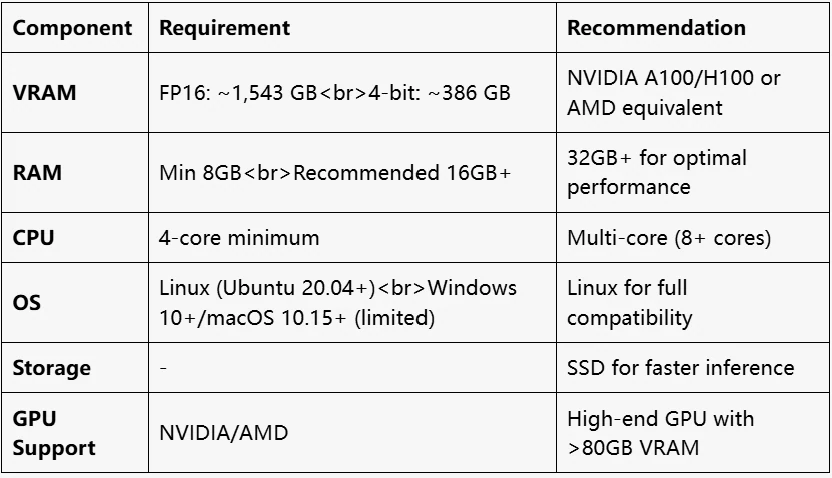
ハードウェア要件
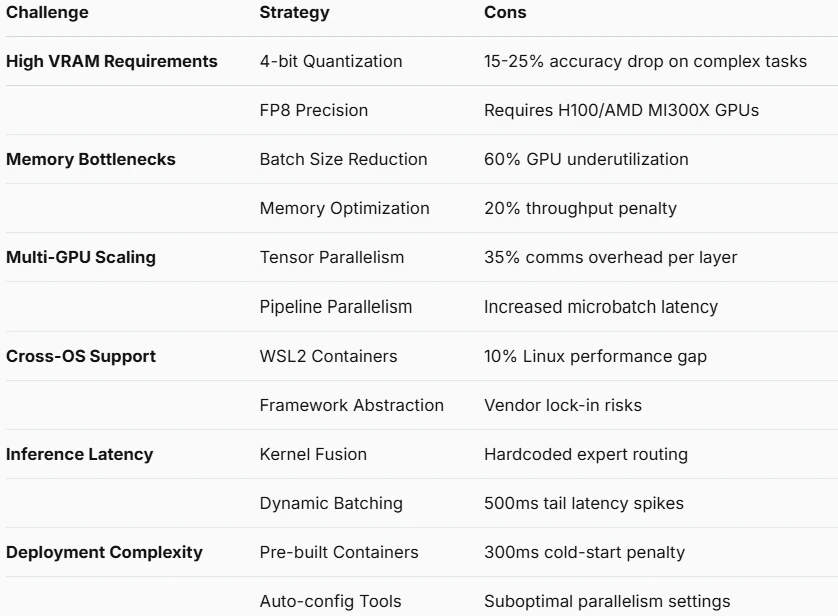
課題と最適化
代替オプション - API
API はどのような問題を解決するか?
高い VRAM 要件
- API ソリューション: 完全解決
- 技術的実装: サーバー側クラスタリソースプーリング
メモリボトルネック
- API ソリューション: 完全排除
- 技術的実装: サーバーノードでの動的メモリ割り当て
マルチ GPU スケーリングの複雑さ
- API ソリューション: 自動処理
- 技術的実装: クラウドネイティブ水平オートスケーリング
クロス OS 互換性問題
- API ソリューション: ネイティブサポート
- 技術的実装: 標準化された HTTP/WebSocket インターフェース
推論レイテンシ
- API ソリューション: 部分的な改善
- 技術的実装: エッジコンピューティングノード + グローバルアクセラレーション
デプロイの複雑さ
- API ソリューション: 完全排除
- 技術的実装: ワンライン統合のプリビルト SDK
量子化精度の低下
- API ソリューション: オプションで回避可能
- 技術的実装: サーバー側 FP16 精度維持
不透明なエキスパートルーティング
- API ソリューション: 完全な透明性
- 技術的実装: リアルタイムルーティング診断 API
優れたソリューション - Novita AI
Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームです。また、手頃な価格で信頼性の高い GPU クラウドを提供し、スケーリングを実現します。
ステップ 1: ログインしてモデルライブラリにアクセス
アカウントにログインし、Model Library ボタンをクリックします。

ステップ 2: モデルを選択
利用可能なオプションから、ニーズに合ったモデルを選択します。

ステップ 3: 無料トライアルを開始
選択したモデルの機能を試すために、無料トライアルを開始します。

ステップ 4: API キーを取得
API で認証するために、新しい API キーを提供します。“Settings” ページに移動し、画像のように API キーをコピーします。

ステップ 5: API をインストール
プログラミング言語に適したパッケージマネージャを使用して API をインストールします。

インストール後、必要なライブラリを開発環境にインポートします。API キーを使用して API を初期化し、Novita AI LLM との対話を開始します。以下は、Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_v3"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
登録時に、Novita AI はスターター用に $0.5 のクレジットを提供します!
無料クレジットを使い切った場合は、支払って継続利用できます。
DeepSeek V3 は、様々なタスクで最先端のパフォーマンスを提供する、オープンソース AI における重要な進歩です。ローカルデプロイはより大きな制御とプライバシーを提供しますが、相当なハードウェアリソースと技術的専門知識が必要です。これらの要件を満たせない方には、Novita AI のような API ベースの代替手段がアクセス可能でスケーラブルなソリューションを提供します。ローカルデプロイと API 利用の選択は、特定のニーズとリソースに依存します。
よくある質問
混合エキスパート (MoE) アーキテクチャとは何か、なぜ重要なのか?
MoE は複数の「エキスパート」を使用して特定の入力トークンを処理し、複雑なタスクの効率とパフォーマンスを向上させます。密なモデルよりも計算効率が高いですが、依然としてハードウェア集約型です。
DeepSeek V3 と Llama 3.3 70B をベンチマークとユースケースの観点から比較するとどうか?
DeepSeek V3 はコーディングや数学のタスクに優れており、Llama 3.3 70B は一般的な言語および多言語アプリケーションで優れています。
DeepSeek V3 の VRAM 要件は?
DeepSeek V3 の VRAM 要件は精度によって異なります。FP16 の場合、671B モデルは約 1,543 GB の VRAM を必要とし、4 ビット量子化では約 386 GB の VRAM を必要とします。アクティブパラメータは 37B です。
Novita AI は、AI の野望を実現するオールインワンのクラウドプラットフォームです。統合 API、サーバーレス、GPU インスタンス — コスト効率の良いツールを提供します。インフラを排除し、無料で始めて、AI ビジョンを現実にしましょう。



