

Эта статья дает обзор настроек конфигурации больших языковых моделей (LLM), углубляясь в преимущества и недостатки больших контекстных окон. Она также предлагает практические примеры, иллюстрирующие, как изменение этих настроек влияет на вывод LLM при различных задачах.
Введение
Большие языковые модели полагаются на вероятности, чтобы определить наиболее вероятный следующий токен или слово на основе своих обучающих данных, подсказок и настроек. Предыдущие обсуждения подчеркивали, как методы подсказок могут привить LLM человеческое рассуждение, в то время как такие техники, как Retrieval Augmented Generation, расширяют их возможности, предоставляя доступ к внешним источникам знаний.
Тем не менее, настройка параметров LLM может существенно повлиять на конечный вывод независимо от предоставленного контекста и подсказок. Овладение этими настройками имеет решающее значение для эффективного использования больших языковых моделей и направления их к желаемому поведению. В этой статье мы исследуем фундаментальные параметры LLM, такие как температура, Top P, максимальное количество токенов и контекстное окно, объясняя, как они влияют на вывод модели.
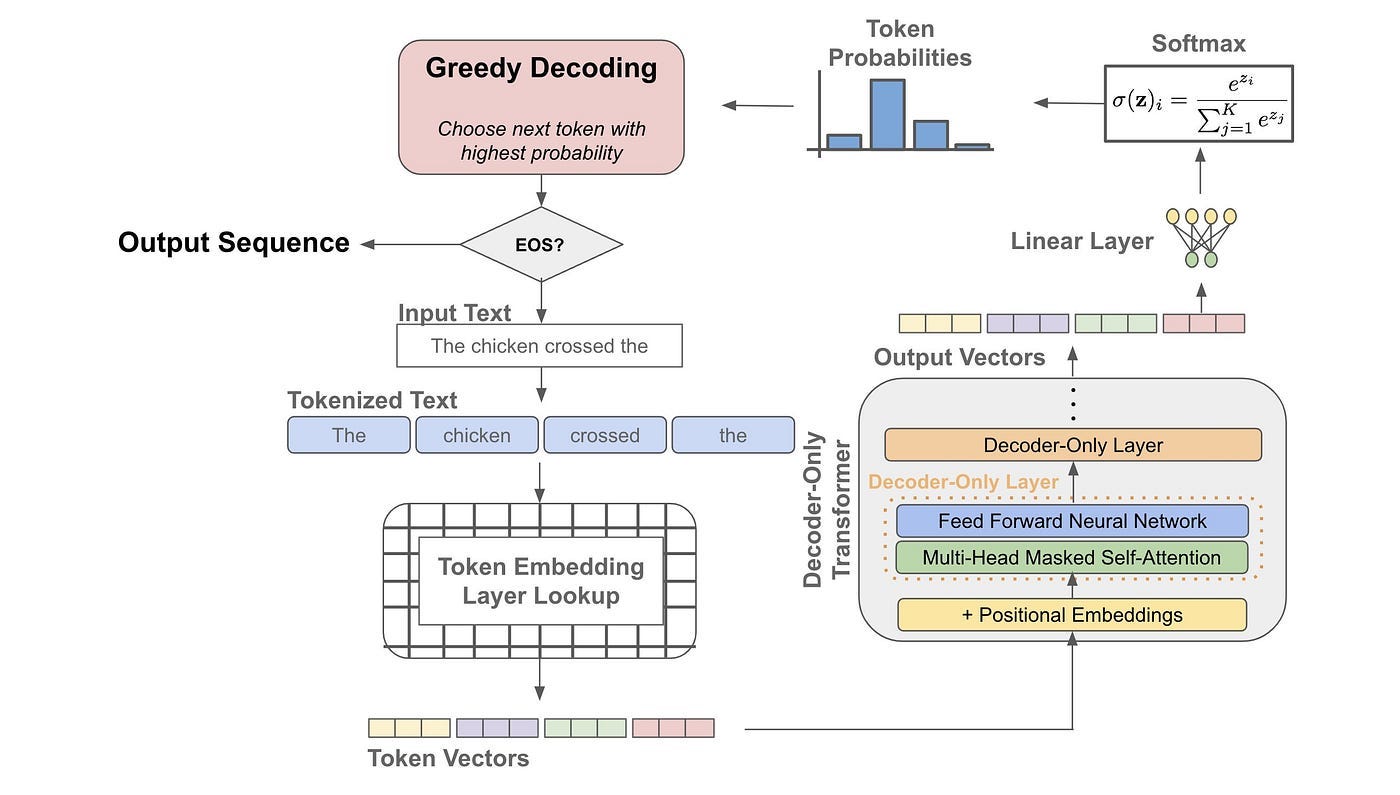
Что такое температура LLM?

Проще говоря, температура — это параметр, который варьируется от 0 до 1, определяющий уровень случайности в ответах, генерируемых большой языковой моделью (LLM). Более высокие температуры приводят к более разнообразным и творческим результатам, в то время как более низкие температуры дают более консервативные и предсказуемые ответы.
Когда температура установлена на ноль, LLM будет последовательно выдавать одинаковый вывод при одном и том же запросе. Повышение температуры увеличивает креативность модели, обеспечивая более широкий спектр результатов. Однако чрезмерно высокие температуры могут привести к выводу, лишенному связности или смысла.
Настройки температуры по умолчанию различаются у разных LLM, в зависимости от таких факторов, как тип модели и доступ к ней через API или веб-интерфейс. Например, в обсуждениях ChatGPT-3.5 и 4 часто упоминаются настройки температуры по умолчанию около 0,7–0,8, хотя точные значения часто не раскрываются.
Настройки температуры
Параметр температуры — это числовое значение, обычно находящееся в диапазоне от 0 до 1 (хотя иногда может выходить за эти пределы), которое влияет на степень склонности модели к риску или консерватизму при выборе слов. Он корректирует распределение вероятностей следующего слова.
Вот разбивка различных параметров температуры для больших языковых моделей:

Низкая температура (<1,0) — при значении ниже 1 вывод модели становится более детерминированным и повторяющимся. Более низкие температуры отдают предпочтение выбору наиболее вероятного следующего слова, уменьшая вариативность вывода. Это может быть полезно для получения предсказуемых и консервативных ответов, но также может давать менее творческий или разнообразный текст, придавая модели более роботизированный тон.
Высокая температура (>1,0) — установка температуры выше 1 увеличивает случайность в генерируемом тексте. Модель более склонна выбирать менее вероятные слова в качестве следующего слова в последовательности, что приводит к более разнообразным, а иногда и более творческим результатам. Однако эта повышенная случайность может привести к ошибкам или бессмысленным ответам, поскольку модель меньше связана распределением вероятностей своих обучающих данных.
Температура 1,0 — часто это настройка по умолчанию, направленная на достижение баланса между случайностью и детерминизмом. Модель генерирует текст, который не является ни чрезмерно предсказуемым, ни слишком случайным, опираясь на распределение вероятностей, полученное в ходе обучения.
Варианты использования моделирования температуры LLM
Тонкая настройка параметра температуры в моделировании включает поиск правильного баланса между случайностью и детерминизмом, что является критическим аспектом в приложениях, где качество генерируемого текста глубоко влияет на пользовательский опыт или процессы принятия решений.
В практических сценариях выбор настройки температуры зависит от желаемого результата. Задачи, требующие творчества или разнообразия ответов, могут выиграть от более высоких температур, в то время как задачи, требующие точности или фактической правильности, обычно предпочитают более низкие температуры.
Вот несколько распространенных вариантов использования и рекомендуемые настройки температуры для моделей LLM:
Творческое письмо — использование более высоких температур может стимулировать креативность и давать разнообразные результаты, что полезно для преодоления творческого кризиса или генерации инновационных идей для контента.
Техническая документация — предпочтительны более низкие температуры для обеспечения точности и надежности контента, что важно в технической документации, где точность и согласованность имеют первостепенное значение.
Взаимодействие с клиентами — регулировка температуры позволяет адаптировать ответы в чат-ботах или виртуальных помощниках в соответствии с брендом и тоном организации, а также с предпочтениями целевой аудитории.
Что такое Top P
Top P, также известный как nucleus sampling (выборка ядра), — это еще один параметр, влияющий на случайность вывода LLM. Этот параметр определяет пороговую вероятность для включения токенов в набор кандидатов, используемый LLM для генерации вывода. Более низкие значения этого параметра приводят к более точным и основанным на фактах ответам LLM, в то время как более высокие значения увеличивают случайность и разнообразие генерируемого вывода.
Например, установка параметра Top P на 0,1 приводит к детерминированному и сфокусированному выводу LLM. С другой стороны, увеличение Top P до 0,8 позволяет получать менее ограниченные и более творческие ответы.
Что такое Max Tokens
В то время как температура и Top P регулируют случайность ответов LLM, они не устанавливают никаких ограничений на размер принимаемого ввода или генерируемого моделью вывода. Напротив, два других параметра — контекстное окно и максимальное количество токенов — напрямую влияют на производительность LLM и возможности обработки данных.
Контекстное окно, измеряемое в токенах (которые могут быть целыми словами, частями слов или символами), определяет количество слов, которое LLM может обработать за один раз. С другой стороны, параметр максимального количества токенов устанавливает верхний предел общего количества токенов, включая как ввод, предоставленный LLM в качестве подсказки, так и выходные токены, сгенерированные LLM в ответ на эту подсказку.

Понимание контекстного окна
В целом, размер контекстного окна в больших языковых моделях (LLM) определяет объем информации, который модель может сохранить и использовать при генерации вывода. Большее контекстное окно позволяет LLM запоминать больше контекста, что приводит к более связным и точным ответам. Однако, если ввод превышает контекстное окно, модель начинает «забывать» более раннюю информацию, что потенциально приводит к менее релевантному и более низкокачественному выводу.
Кроме того, размер контекстного окна накладывает ограничения на методы разработки подсказок. Такие методы, как Tree-of-Thoughts (дерево мыслей) или Retrieval Augmented Generation (RAG), требуют больших контекстных окон для эффективности, поскольку они полагаются на подачу модели достаточного количества информации для генерации качественных ответов.
По мере развития LLM их контекстные окна также расширяются, позволяя обрабатывать больше токенов за раз. Например, в то время как GPT-4 имеет ограничение контекста в 8 192 токена, более новые модели, такие как GPT-4 Turbo, поддерживают контекстное окно до 128K токенов. Аналогично, Anthropic увеличила ограничение контекста в инструменте Claude с 9 000 токенов до 200K токенов в версии Claude 2.1.
Когда большое контекстное окно не приводит к лучшему результату?
Хотя большее контекстное окно позволяет LLM обрабатывать более длинные вводы, что приводит к потенциально более релевантным ответам, расширение контекстных лимитов не является универсально выгодным. Следует учитывать несколько недостатков.
Во-первых, большие наборы входных данных требуют больше времени для генерации ответов LLM. Повышенная вычислительная сложность обработки больших контекстных окон еще больше усугубляет эту проблему.
Во-вторых, вычислительные затраты, связанные с большими контекстными окнами, возрастают пропорционально.
Более того, исследование Liu et al. (2023) выявило еще одну проблему: большие языковые модели часто с трудом эффективно получают доступ к информации в длинных входных контекстах. Их исследование показало, что LLM достигают оптимальной производительности, когда релевантная информация находится либо в начале, либо в конце ввода. И наоборот, использование информации из середины длинного контекста приводит к снижению производительности модели.
Другие настройки LLM
Несколько других настроек могут влиять на вывод языковых моделей, включая стоп-последовательности, штрафы за частоту и штрафы за присутствие.
Стоп-последовательности
Стоп-последовательности указывают, когда модель должна прекратить генерацию вывода, позволяя контролировать длину и структуру контента. Например, при подсказке ИИ написать электронное письмо, установка «С уважением» или «Искренне Ваш» в качестве стоп-последовательности гарантирует, что модель остановится перед заключительным приветствием, что приведет к краткому и сфокусированному письму. Стоп-последовательности полезны для генерации вывода, который, как ожидается, будет следовать структурированному формату, такому как электронные письма, нумерованные списки или диалоги.
Штраф за частоту
Штраф за частоту — это настройка, которая препятствует повторению в генерируемом тексте, штрафуя токены на основе частоты их появления. Токены, которые встречаются в тексте чаще, с меньшей вероятностью будут использованы снова ИИ.
Штраф за присутствие
Штраф за присутствие работает аналогично штрафу за частоту, но применяет фиксированный штраф к токенам в зависимости от того, появлялись ли они в тексте или нет, а не штрафует их пропорционально.

Источник: novita.ai
Импорт персонажа (опционально)
Некоторые LLM имеют свои особые настройки, например, импорт персонажа. Импортируя карточки персонажей, вы можете общаться с любимыми персонажами, кем бы они ни были.

LLM novita.ai с функцией импорта персонажа
Как настроить параметры LLM?
Как показано выше, настройка таких параметров, как температура, Top P и максимальное количество токенов, может помочь точно настроить LLM для получения более релевантных и точных результатов. Снижение температуры или Top P до значений 0,1 или 0,2 уменьшает случайность, давая более сфокусированные ответы, подходящие для таких задач, как генерация кода или написание сценариев анализа данных. И наоборот, увеличение параметров температуры или Top P примерно до 0,7 или 0,8 стимулирует более творческий и разнообразный вывод, идеальный для творческого письма или рассказывания историй. Обычно рекомендуется изменять либо температуру, либо Top P, но не оба параметра одновременно.
Между тем, изменение параметра максимального количества токенов позволяет настраивать длину вывода LLM. Эта гибкость оказывается полезной при адаптации LLM для генерации как коротких ответов для чат-ботов, так и более длинного контента для статей. Кроме того, настройка параметра максимального количества токенов может быть полезна в таких сценариях, как генерация кода для разработки программного обеспечения или суммаризация длинных документов.
Заключение
Подводя итог, можно сказать, что овладение такими настройками, как температура, Top P, максимальная длина и другими, имеет решающее значение при использовании языковых моделей. Эти параметры позволяют точно управлять выводом модели, адаптируя его для конкретных задач или приложений. Они управляют такими факторами, как случайность ответов, длина и частота повторений, что в совокупности способствует улучшению взаимодействия с ИИ.
novita.ai — универсальная платформа для безграничного творчества, предоставляющая доступ к 100+ API. От генерации изображений и обработки языка до улучшения аудио и манипуляции видео, дешевая модель оплаты по мере использования, она освобождает вас от хлопот по обслуживанию GPU, позволяя создавать собственные продукты. Попробуйте бесплатно.
Рекомендуемое чтение
Novita AI LLM Inference Engine: самая большая пропускная способность и самый дешевый инференс



