

Выпуск MiniMax-M2.1 знаменует собой значительный шаг в эволюции открытых ИИ-моделей, особенно для разработчиков, работающих над агентными функциями и задачами программной инженерии. Обладая 228,7 миллиардами параметров, эта модель показывает впечатляющую производительность на многоязычных бенчмарках кодирования, при этом будучи полностью прозрачной и пригодной для локального развертывания. Однако ключевой вопрос для разработчиков, планирующих локальный запуск: сколько VRAM на самом деле требуется MiniMax-M2.1?
Краткий ответ: требования к VRAM для MiniMax M2.1
Для разработчиков, планирующих запускать MiniMax-M2.1 локально, ограничения по VRAM напрямую влияют на:
- Возможность развертывания: можно ли вообще запустить модель на доступном оборудовании
- Скорость инференса: память GPU обеспечивает параллельную обработку; выгрузка части вычислений на CPU значительно замедляет генерацию
- Использование окна контекста: более длинные контексты требуют дополнительной памяти для KV-кэша
- Размер пакета: одновременная обработка нескольких запросов умножает потребности в памяти
- Планирование затрат: решения об аренде GPU или покупке оборудования зависят от точных оценок объема VRAM

Ключевые конфигурации развертывания:
- Полная точность для продакшена: точный объем VRAM не публично disclosed; по оценкам 400–500 ГБ на основе количества параметров
- 4-битное квантование: 200 ГБ VRAM (2x RTX 6000 Pro с контекстом 400k токенов)
- Гибридная выгрузка на CPU: 32 ГБ VRAM (эквивалент RTX 5090) с использованием оперативной памяти CPU
Требования к VRAM для MiniMax M2.1 в зависимости от конфигурации развертывания
Развертывание с полной точностью
| Компонент | Требуемая память | Основание расчета |
|---|---|---|
| Веса модели (FP16) | 458 ГБ | 228,7 млрд параметров × 2 байта |
| Накладные расходы фреймворка | 20–40 ГБ | Типичные накладные расходы PyTorch/vLLM |
| Общая оценка | 480–500 ГБ | Минимум для инференса (короткий контекст) |
Варианты развертывания с квантованием
4-битное квантование
Согласно обсуждению на Hacker News, MiniMax-M2.1 может работать на 2x GPU RTX 6000 Pro (общий объем VRAM 200 ГБ) при 4-битном квантовании с поддержкой окна контекста около 400k токенов. Это представляет собой значительное сокращение требований по сравнению с развертыванием в полной точности.
С M2 да, я использовал его в Claude Code (например, нативный вызов инструментов), Roo/Cline (например, парсинг пользовательских инструментов) и т.д. Он довольно хорош и на протяжении некоторого времени был лучшей моделью для самостоятельного размещения. При 4-битном квантовании он помещается на 2x RTX 6000 Pro (например, ~200 ГБ VRAM) с контекстом около 400k токенов при KV-кэше fp8. Он очень быстрый за счет низкого количества активных параметров, стабильный при длинном контексте, довольно производительный в любой агентной обвязке (это его специализация при обучении). M2.1 должен быть заметным улучшением по сравнению с M2, который был недообучен даже относительно гораздо более мелких моделей.
Из Hacker News
4-битное квантование обычно сокращает размер модели примерно на 75% по сравнению с FP16, что согласуется с этими наблюдениями при развертывании:
- Веса модели: 115 ГБ (228,7 млрд параметров × 0,5 байта)
- Фреймворк + KV-кэш: дополнительно 85 ГБ
- Итого: 200 ГБ VRAM
Гибридная выгрузка вычислений на CPU и GPU
Для разработчиков с потребительскими GPU фреймворк ktransformers демонстрирует, что M2.1 может работать с 32 ГБ VRAM (эквивалент RTX 5090) за счет выгрузки части модели в оперативную память CPU.
Этот гибридный подход жертвует скоростью инференса в пользу доступности:
- VRAM GPU: 32 ГБ (критические слои и активные вычисления)
- Оперативная память системы: требуется значительный дополнительный объем RAM (точный объем не указан)
- Компромисс производительности: выгрузка на CPU вносит задержку по сравнению с полным развертыванием на GPU
Рекомендации по оборудованию для развертывания MiniMax-M2.1
Для разработки и экспериментов
Если вы создаете прототипы или тестируете возможности M2.1, гибридный подход с выгрузкой на CPU предлагает наиболее доступную точку входа:
| Компонент | Минимальные характеристики | Рекомендуемые характеристики |
|---|---|---|
| GPU | 32 ГБ VRAM (RTX 5090) | 48 ГБ VRAM (RTX 6000 Ada) |
| Оперативная память системы | 128 ГБ DDR4/DDR5 | 256 ГБ DDR5 |
| Накопитель | 1 ТБ NVMe SSD | 2 ТБ NVMe SSD |
| Фреймворк | ktransformers с выгрузкой на CPU |
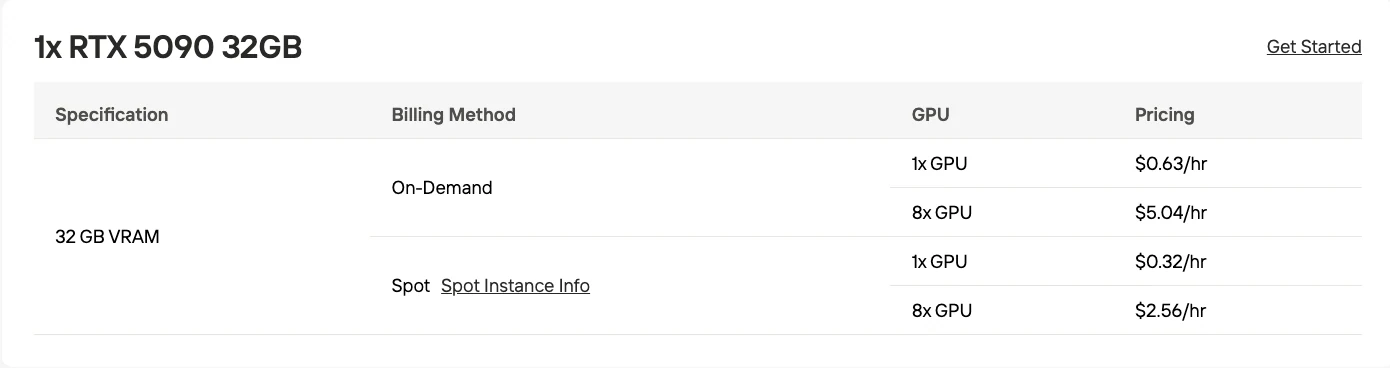
Ожидаемая производительность: подходит для экспериментов и разработки одним пользователем. Скорость инференса будет ниже, чем при полном развертывании на GPU, но достаточная для тестирования агентных рабочих процессов и задач генерации кода.
Для продакшен-развертывания
Продакшен-среды, обслуживающие нескольких пользователей или требующие ответов с низкой задержкой, нуждаются в полном выделении памяти GPU:
| Тип развертывания | Конфигурация GPU | Общий объем VRAM | Сценарий использования |
|---|---|---|---|
| Многопроцессорный (4-битное квантование) | 2x RTX 6000 Pro (по 96 ГБ) | ~192 ГБ | Продакшен среднего масштаба |
| GPU для дата-центров | 4x H100 (по 80 ГБ) | 320 ГБ | Высокопроизводительный продакшен |
| Облачная альтернатива | API | управляемый сервис | Продакшен без собственной инфраструктуры |
Соображения по стоимости: Конфигурация 2x RTX 6000 Pro представляет собой практический баланс для организаций, нуждающихся в локальном развертывании без инфраструктуры дата-центрового масштаба. Для многих сценариев использования API может предложить лучшую экономическую эффективность, чем поддержка собственной GPU-инфраструктуры.
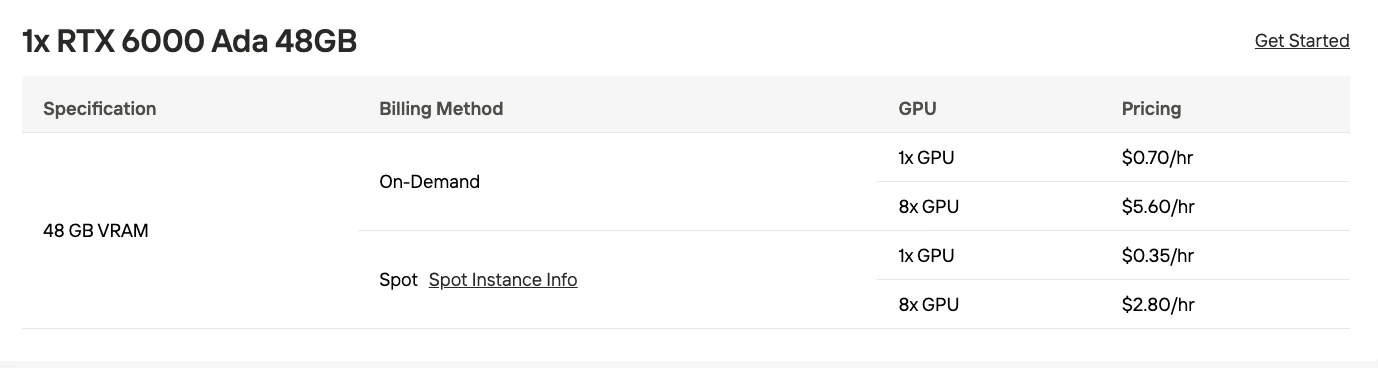
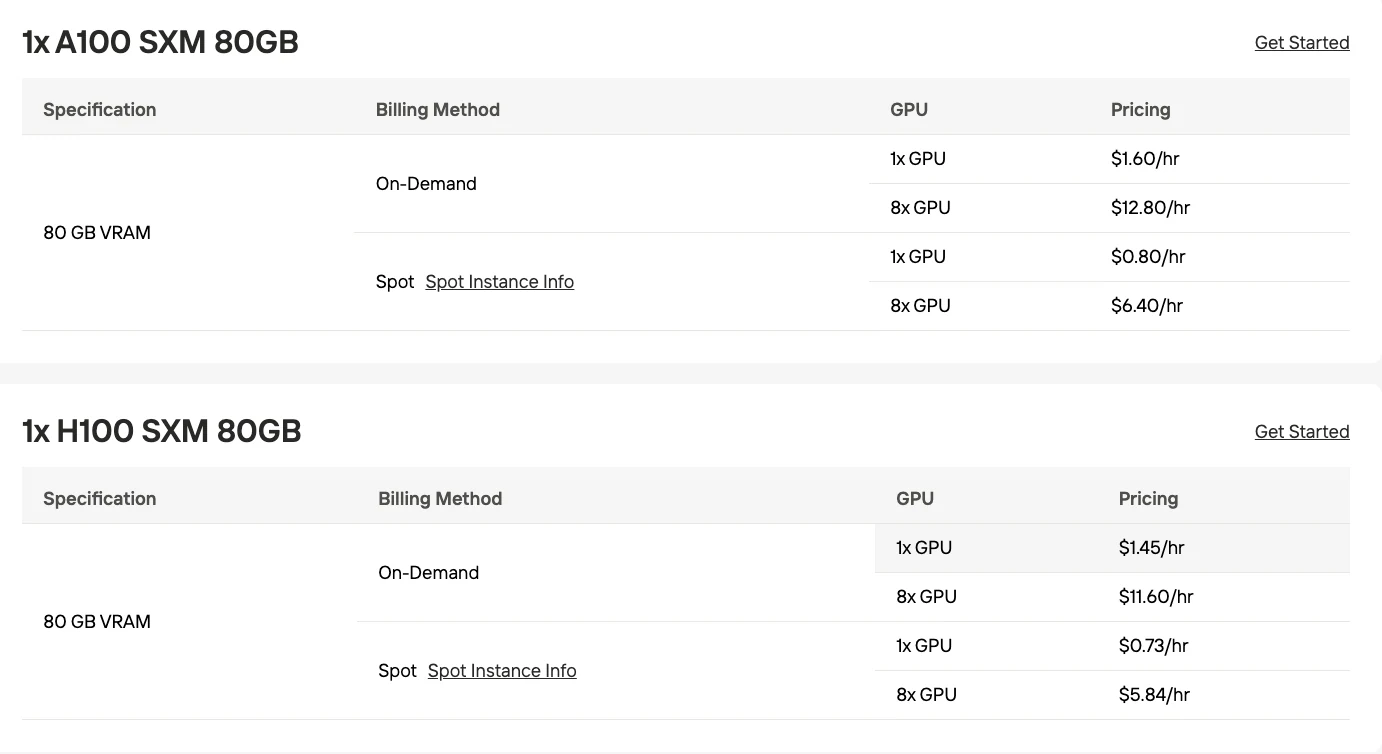
Практические стратегии развертывания
Стратегия 1: Гибридная выгрузка на CPU и GPU (потребительское оборудование)
Фреймворк ktransformers позволяет развертывать модель на потребительских GPU за счет интеллектуального распределения модели между памятью GPU и CPU:
# Пример подхода к развертыванию (точные команды смотрите в документации ktransformers)
# Требования: GPU с 32+ ГБ VRAM, 128+ ГБ оперативной памяти системы
# Фреймворк автоматически распределяет слои
# между памятью GPU и CPU в зависимости от доступных ресурсов
Преимущества:
- Доступно с использованием высококлассных потребительских GPU (RTX 5090, RTX 6000 Ada)
- Меньшие первоначальные инвестиции в оборудование
- Подходит для разработки и продакшена с низким объемом запросов
Недостатки:
- Более низкая скорость инференса из-за передачи данных между CPU и GPU
- Требуется значительный объем оперативной памяти системы (от 128 ГБ)
- Не подходит для продакшен-рабочих нагрузок с высокой степенью параллелизма
Стратегия 2: Многопроцессорное развертывание с квантованием
Шаг 1:Зарегистрируйте аккаунт
Создайте аккаунт Novita AI на нашем сайте. После регистрации перейдите в раздел «Explore» (Обзор) в левой боковой панели, чтобы ознакомиться с нашими предложениями GPU и начать свой путь в разработке ИИ.

Шаг 2:Изучение шаблонов и GPU-серверов**
Выбирайте шаблоны, такие как PyTorch, TensorFlow или CUDA, соответствующие потребностям вашего проекта. Затем выберите предпочитаемую конфигурацию GPU: доступны мощные L40S, RTX 4090 или A100 SXM4, каждый с разными характеристиками по объему VRAM, оперативной памяти и накопителям.
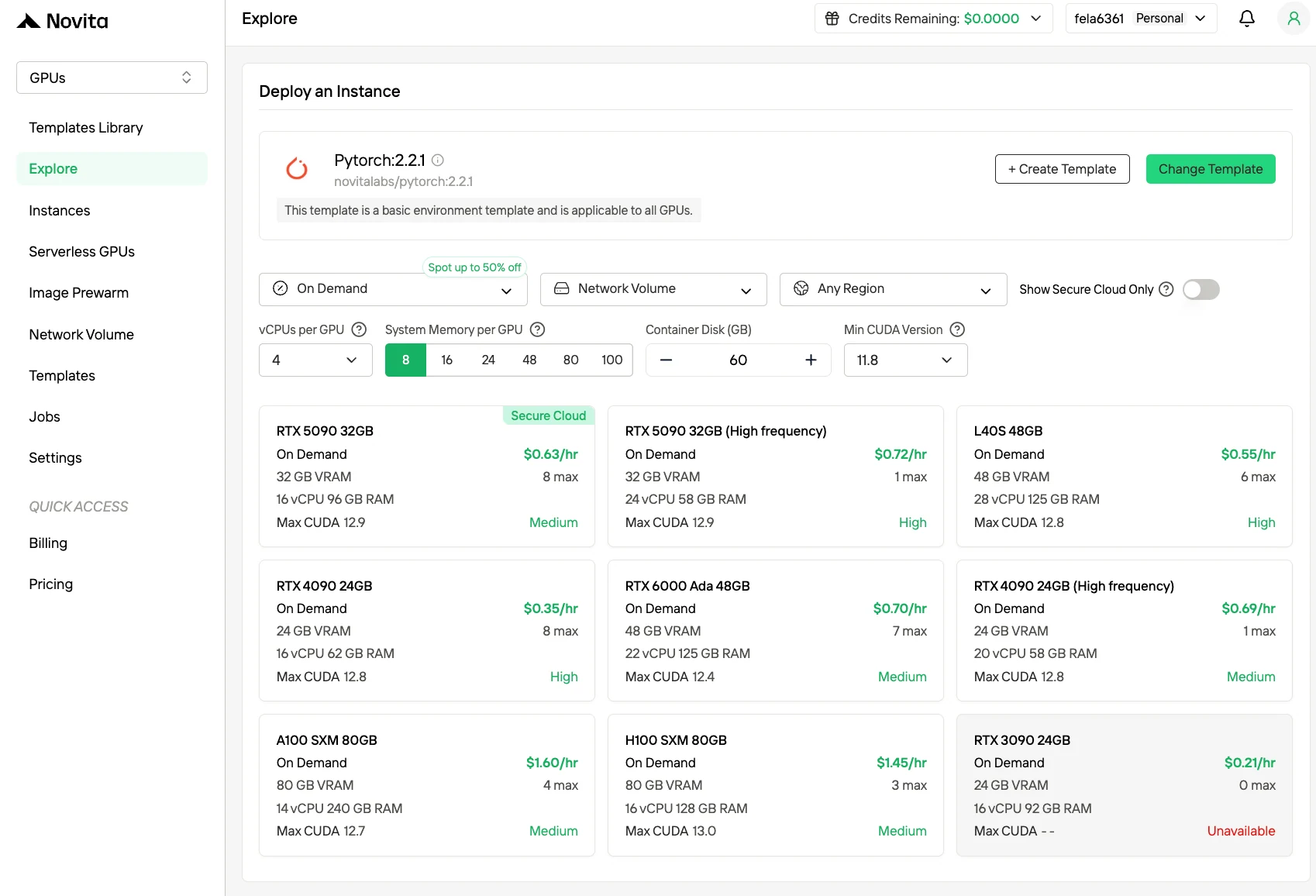
Шаг 3:Настройте развертывание под ваши нужды
Настройте окружение, выбрав предпочитаемую операционную систему и параметры конфигурации, чтобы обеспечить оптимальную производительность для ваших конкретных рабочих нагрузок ИИ и потребностей в разработке.
Шаг 4:Запустите инстанс**
Выберите «Launch Instance» (Запустить инстанс), чтобы начать развертывание. Ваше высокопроизводительное GPU-окружение будет готово в течение нескольких минут, что позволит вам немедленно приступить к проектам в области машинного обучения, рендеринга или вычислительных задач.
Преимущества:
- Полная производительность GPU без узких мест на стороне CPU
- Может обрабатывать несколько одновременных запросов
- Поддержка расширенного окна контекста (~400k токенов)
Недостатки:
- Требует инвестиций в корпоративное GPU-оборудование
- Незначительное снижение качества из-за квантования (обычно минимальное для 4-битного)
- Требует экспертизы в настройке тензорного параллелизма на нескольких GPU
Стратегия 3: Управляемый API-сервис
Попробуйте MiniMax M2.1 сейчас!
Когда выбирать API:
- Изменяющиеся или непредсказуемые паттерны использования
- Хотите избежать управления GPU-инфраструктурой
- Нужен немедленный доступ без задержек на закупку оборудования
- Разработка прототипов перед принятием решения о локальном развертывании
Когда выбирать локальное развертывание:
- Высокообъемное стабильное использование, при котором накапливаются затраты на токен
- Требования к конфиденциальности данных или соответствию нормам не позволяют использовать внешний API
- Нужен полный контроль над поведением и версией модели
- Разработка пользовательских дообученных версий
Ключевой вывод для разработчиков: локальное развертывание M2.1 доступно, но требует стратегического выбора оборудования. Хотя развертывание в полной точности требует 400–500 ГБ VRAM (уровень корпоративных дата-центров), существуют практические альтернативы: 4-битное квантование позволяет развертывать на 2x GPU RTX 6000 Pro (общий объем ~200 ГБ), а гибридные стратегии с выгрузкой на CPU работают на потребительских GPU от 32 ГБ VRAM.
Для большинства разработчиков и организаций дерево решений очевидно:
- Эксперименты и разработка: гибридный подход с выгрузкой на CPU на RTX 5090/6000 Ada + 128+ ГБ оперативной памяти
- Продакшен-развертывание (самостоятельное размещение): многопроцессорная конфигурация с квантованием (минимум 2x RTX 6000 Pro)
- Продакшен-развертывание (управляемое): API для простоты эксплуатации и предсказуемости затрат
Часто задаваемые вопросы
Сколько VRAM требуется MiniMax-M2.1 для локального развертывания? По оценкам, для FP16 требуется 450–500 ГБ VRAM, в то время как в практических конфигурациях используют 4-битное квантование (200 ГБ) или гибридное развертывание на CPU и GPU (32 ГБ VRAM + большой объем оперативной памяти системы).
Можно ли запустить MiniMax-M2.1 на потребительской GPU, такой как RTX 4090 или RTX 5090? Да, но обычно только с выгрузкой части вычислений на CPU и 128+ ГБ оперативной памяти системы, при этом скорость жертвуется в favor возможности запуска.
В чем разница в требованиях к VRAM между M2 и M2.1? Официального сравнения не предоставлено, но их схожий масштаб количества параметров предполагает примерно сопоставимые требования к VRAM.
Novita AI — это универсальная облачная платформа, которая помогает реализовать ваши амбиции в области ИИ. Интегрированные API, бессерверные вычисления, GPU-инстансы — это экономически эффективные инструменты, которые вам нужны. Избавьтесь от необходимости управления инфраструктурой, начните бесплатно и воплотите ваше видение ИИ в реальность.
Рекомендуемые материалы для чтения
Объяснение ограничений по VRAM для Kimi K2 Thinking для разработчиков с ограниченным бюджетом
DeepSeek против Qwen: определите, какая экосистема подходит для ваших продакшен-задач



