

يُمثل إطلاق MiniMax-M2.1 تطورًا كبيرًا في نماذج الذكاء الاصطناعي مفتوحة المصدر، خاصة للمطورين الذين يركزون على القدرات المعتمدة على الوكلاء ومهام هندسة البرمجيات. بفضل 228.7 مليار معامل، يقدم هذا النموذج أداءً مذهلاً في معايير البرمجة متعددة اللغات، مع كونه شفافًا بالكامل وقابلًا للنشر محليًا. لكن السؤال الحاسم للمطورين الذين يخططون للنشر المحلي هو: ما مقدار ذاكرة الوصول العشوائي للفيديو (VRAM) الذي يتطلبه MiniMax-M2.1 في الواقع؟
إجابة سريعة: متطلبات ذاكرة الوصول العشوائي للفيديو لـ MiniMax M2.1
للمطورين الذين يخططون لتشغيل MiniMax-M2.1 محليًا، تؤثر قيود ذاكرة الوصول العشوائي للفيديو مباشرة على:
- جدوى النشر: ما إذا كان بإمكانك تشغيل النموذج على الإطلاق باستخدام الأجهزة المتاحة
- سرعة الاستدلال: تتيح ذاكرة معالج الرسوميات المعالجة المتوازية؛ يؤدي إلغاء التحميل إلى وحدة المعالجة المركزية إلى إبطاء التوليد بشكل كبير
- استخدام نافذة السياق: تتطلب السياقات الأطول ذاكرة إضافية لذاكرة التخزين المؤقت KV
- حجم الدفعة: ضرب معالجة الطلبات المتعددة في نفس الوقت من احتياجات الذاكرة
- تخطيط التكاليف: تعتمد قرارات تأجير معالج الرسوميات أو شراء الأجهزة على تقديرات دقيقة لذاكرة الوصول العشوائي للفيديو

التكوينات الرئيسية للنشر:
- الدقة الكاملة للإنتاج: لم يتم الكشف عن مقدار ذاكرة الوصول العشوائي للفيديو بدقة علنًا؛ تقديريًا 400-500 جيجابايت بناءً على عدد المعاملات
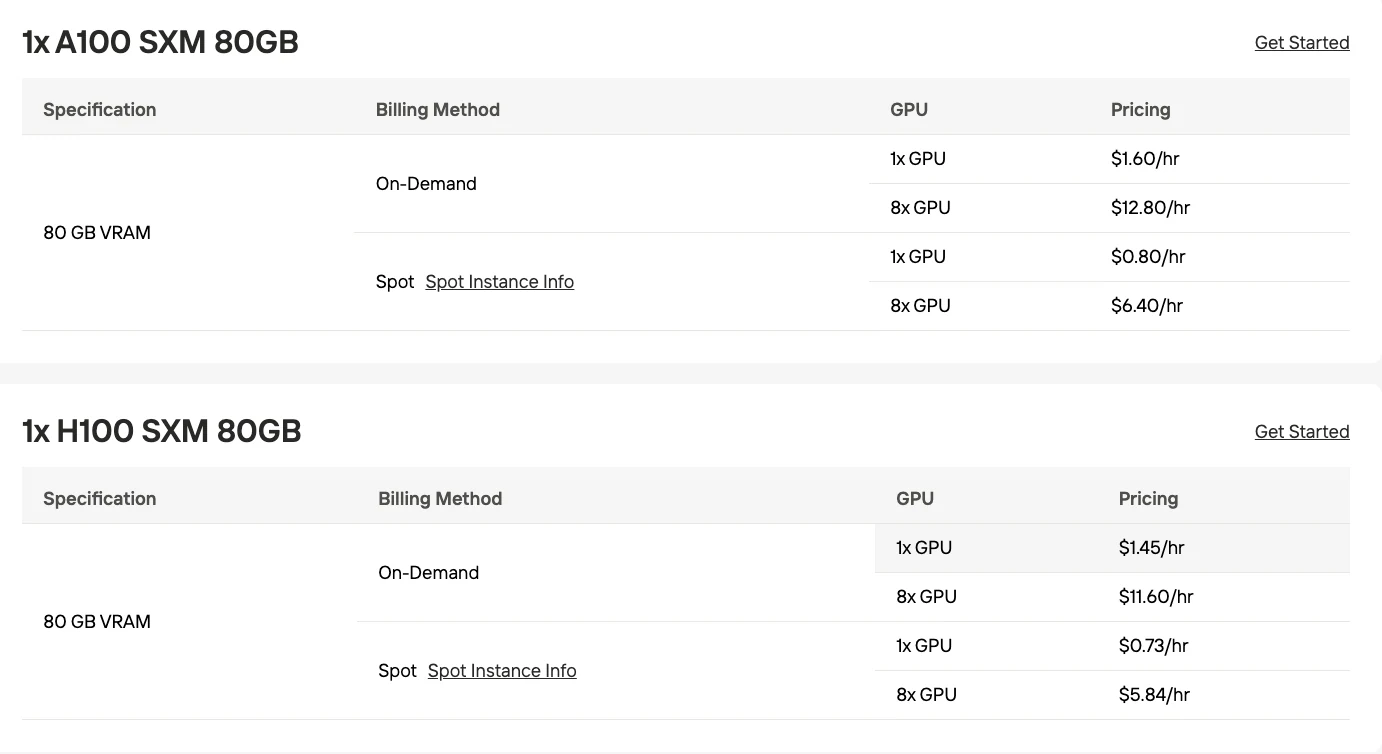
- مكمّمة بدقة 4 بت: 200 جيجابايت VRAM (2x RTX 6000 Pro مع سياق 400 ألف رمز)
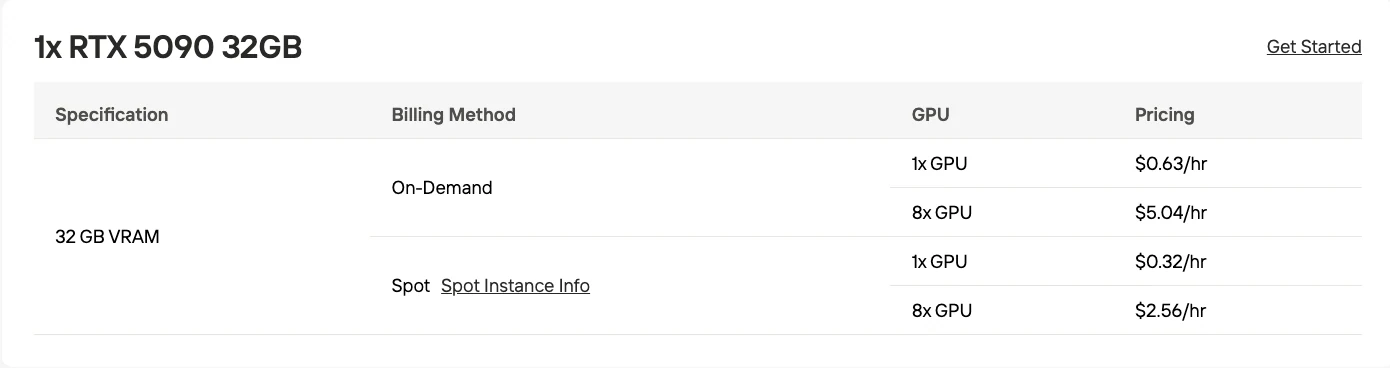
- إلغاء تحميل هجين لوحدة المعالجة المركزية: 32 جيجابايت VRAM (ما يعادل RTX 5090) بمساعدة ذاكرة وحدة المعالجة المركزية
متطلبات ذاكرة الوصول العشوائي للفيديو لـ MiniMax M2.1 حسب تكوين النشر
نشر الدقة الكاملة
| المكون | الذاكرة المطلوبة | أساس الحساب |
|---|---|---|
| أوزان النموذج (FP16) | 458 جيجابايت | 228.7B معامل × 2 بايت |
| النفقات العامة للإطار | 20-40 جيجابايت | نفقات عامة نموذجية لـ PyTorch/vLLM |
| الإجمالي التقديري | 480-500 جيجابايت | الحد الأدنى للاستدلال (سياق قصير) |
خيارات النشر المكمّمة
تككمية بدقة 4 بت
وفقًا لمناقشة على موقع Hacker News، يمكن تشغيل MiniMax-M2.1 على 2x وحدات معالجة رسوميات RTX 6000 Pro (إجمالي 200 جيجابايت VRAM) بتكمية بدقة 4 بت مع دعم نافذة سياق تبلغ حوالي 400 ألف رمز. يمثل هذا انخفاضًا كبيرًا مقارنة بمتطلبات الدقة الكاملة.
نعم، مع M2 - لقد استخدمته في Claude Code (مثل استدعاء الأدوات الأصلي)، و Roo/Cline (مثل تحليل الأدوات المخصصة)، إلخ. إنه جيد جدًا وكان لبعض الوقت أفضل نموذج للاستضافة الذاتية. بدقة 4 بت، يمكن أن يتناسب على 2x RTX 6000 Pro (مثل ~200 جيجابايت VRAM) مع سياق يبلغ حوالي 400 ألف رمز في ذاكرة التخزين المؤقت fp8 kv. إنه سريع جدًا بسبب انخفاض المعاملات النشطة، مستقر في السياقات الطويلة، وقادر جدًا في أي إطار عمل للوكلاء (تخصصه في التدريب). يجب أن يكون M2.1 تحسنًا جيدًا يتجاوز M2، الذي كان مدربًا بشكل غير كافٍ مقارنة حتى بالنماذج الأصغر بكثير.
من Hacker News
يقلل التكمية بدقة 4 بت عادةً حجم النموذج بنسبة 75% تقريبًا مقارنة بـ FP16، وهو ما يتوافق مع ملاحظات النشر هذه:
- أوزان النموذج: 115 جيجابايت (228.7B معامل × 0.5 بايت)
- الإطار + ذاكرة التخزين المؤقت KV: 85 جيجابايت إضافية
- الإجمالي: 200 جيجابايت VRAM
إلغاء التحميل الهجين لوحدة المعالجة المركزية / معالج الرسوميات
بالنسبة للمطورين الذين يمتلكون وحدات معالجة رسوميات للمستهلكين، يثبت إطار عمل ktransformers أن M2.1 يمكن تشغيله باستخدام 32 جيجابايت VRAM (ما يعادل RTX 5090) عن طريق إلغاء تحميل أجزاء من النموذج إلى ذاكرة وحدة المعالجة المركزية.
يتاجر هذا النهج الهجين بسرعة الاستدلال من أجل إمكانية الوصول:
- ذاكرة الوصول العشوائي للفيديو لوحدة المعالجة الرسومية: 32 جيجابايت (الطبقات الحرجة والحسابات النشطة)
- ذاكرة الوصول العشوائي للنظام: مطلوب كمية إضافية كبيرة من الذاكرة (لم يتم تحديد المقدار الدقيق)
- مقايضات الأداء: يقدم إلغاء التحميل إلى وحدة المعالجة المركزية زمن استجابة مقارنة بالنشر الكامل على معالج الرسوميات
توصيات الأجهزة لنشر MiniMax-M2.1
للتطوير والتجريب
إذا كنت تبني نماذج أولية أو تختبر قدرات M2.1، فإن النهج الهجين لوحدة المعالجة المركزية / معالج الرسوميات يقدم نقطة دخول الأكثر سهولة:
| المكون | المواصفات الدنيا | موصى به |
|---|---|---|
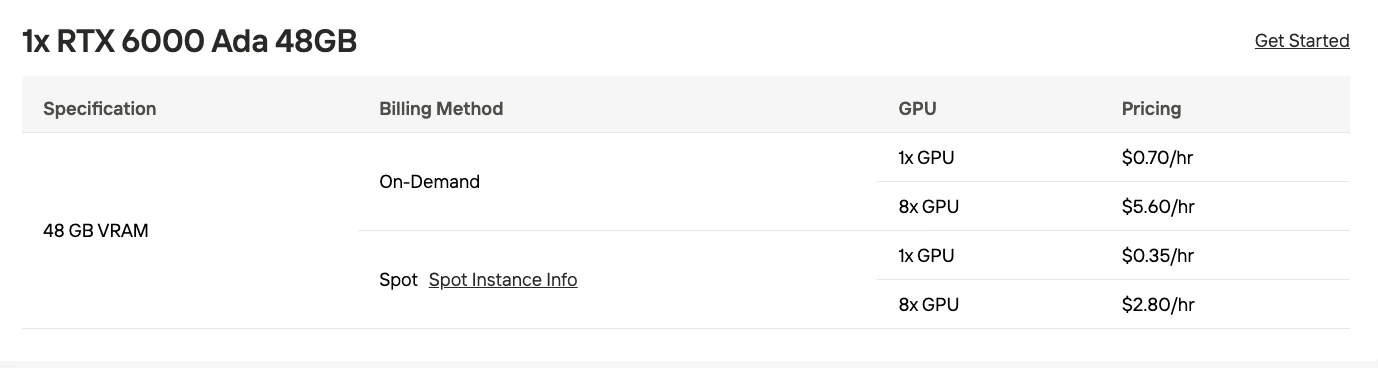
| معالج الرسوميات | 32 جيجابايت VRAM (RTX 5090) | 48 جيجابايت VRAM (RTX 6000 Ada) |
| ذاكرة الوصول العشوائي للنظام | 128 جيجابايت DDR4/DDR5 | 256 جيجابايت DDR5 |
| التخزين | 1 تيرابايت NVMe SSD | 2 تيرابايت NVMe SSD |
| الإطار | ktransformers مع إلغاء التحميل إلى وحدة المعالجة المركزية |
جرب معالج رسوميات فعال من حيث التكلفة!
الأداء المتوقع: مناسب للتجارب والتطوير لمستخدم واحد. ستكون سرعة الاستدلال أبطأ من النشر الكامل على معالج الرسوميات ولكنها تعمل لاختبار سير عمل الوكلاء ومهام توليد الأكواد.
للنشر الإنتاجي
تحتاج البيئات الإنتاجية التي تخدم مستخدمين متعددين أو تتطلب استجابات منخفضة الزمن إلى تخصيص كامل لذاكرة معالج الرسوميات:
| نوع النشر | تكوين معالج الرسوميات | إجمالي VRAM | حالة الاستخدام |
|---|---|---|---|
| متعدد وحدات المعالجة الرسومية (4 بت) | 2x RTX 6000 Pro (96 جيجابايت لكل منهما) | ~192 جيجابايت | إنتاج متوسط الحجم |
| وحدات معالجة رسومية لمراكز البيانات | 4x H100 (80 جيجابايت لكل منهما) | 320 جيجابايت | إنتاج عالي الإنتاجية |
| بديل سحابي | واجهة برمجة التطبيقات | خدمة مُدارة | إنتاج بدون بنية تحتية |
اعتبار التكلفة: يمثل تكوين 2x RTX 6000 Pro توازنًا عمليًا للمؤسسات التي تحتاج إلى نشر محلي بدون بنية تحتية لمراكز البيانات. للعديد من حالات الاستخدام، قد تقدم واجهة برمجة التطبيقات اقتصاديات أفضل من الحفاظ على بنية تحتية لوحدات المعالجة الرسومية محلية.
جرب معالج رسوميات فعال من حيث التكلفة!
استراتيجيات النشر العملية
الاستراتيجية 1: إلغاء التحميل الهجين لوحدة المعالجة المركزية / معالج الرسوميات (أجهزة المستهلك)
يتيح إطار عمل ktransformers النشر على وحدات معالجة الرسوميات من فئة المستهلكين عن طريق توزيع النموذج بذكاء عبر ذاكرة معالج الرسوميات وذاكرة وحدة المعالجة المركزية:
# Example deployment approach (refer to ktransformers documentation for exact commands)
# Requires: 32GB+ VRAM GPU, 128GB+ system RAM
# Framework handles automatic layer distribution
# between GPU and CPU memory based on available resources
المزايا:
- متاح مع وحدات معالجة الرسوميات عالية الأداء للمستهلكين (RTX 5090, RTX 6000 Ada)
- استثمار أولي أقل في الأجهزة
- مناسب للتطوير والإنتاج منخفض الحجم
العيوب:
- سرعة استدلال أبطأ بسبب نقل البيانات بين وحدة المعالجة المركزية ومعالج الرسوميات
- يتطلب كمية كبيرة من ذاكرة الوصول العشوائي للنظام (128 جيجابايت على الأقل)
- غير مناسب لأحمال العمل الإنتاجية ذات التزامن العالي
الاستراتيجية 2: النشر المكمّم متعدد وحدات المعالجة الرسومية
الخطوة 1:تسجيل حساب
أنشئ حسابك على Novita AI من خلال موقعنا الإلكتروني. بعد التسجيل، انتقل إلى قسم “استكشاف” في الشريط الجانبي الأيسر لعرض عروض وحدات المعالجة الرسومية لدينا وابدأ رحلة تطوير الذكاء الاصطناعي الخاصة بك.

الخطوة 2:استكشاف القوالب وخوادم وحدات المعالجة الرسومية**
اختر من بين القوالب مثل PyTorch أو TensorFlow أو CUDA التي تناسب احتياجات مشروعك. ثم اختر تكوين وحدات المعالجة الرسومية المفضل لديك — تتضمن الخيارات L40S القوي، أو RTX 4090 أو A100 SXM4، لكل منها مواصفات مختلفة لذاكرة الوصول العشوائي للفيديو والذاكرة والتخزين.
الخطوة 3:تخصيص النشر الخاص بك
خصص بيئتك عن طريق اختيار نظام التشغيل وخيارات التكوين المفضلة لديك لضمان الأداء الأمثل لأحمال عمل الذكاء الاصطناعي الخاصة بك واحتياجات التطوير.
جرب معالج رسوميات فعال من حيث التكلفة!
الخطوة 4:إطلاق مثيل
اختر “إطلاق مثيل” لبدء النشر الخاص بك. ستكون بيئة معالج الرسوميات عالية الأداء جاهزة في غضون دقائق، مما يسمح لك بالبدء فورًا في مشاريع التعلم الآلي أو العرض الحاسوبي أو المشاريع الحسابية الخاصة بك.
المزايا:
- أداء كامل لوحدة المعالجة الرسومية بدون اختناقات لوحدة المعالجة المركزية
- يمكنه التعامل مع طلبات متزامنة متعددة
- دعم نافذة سياق ممتدة (~400 ألف رمز)
العيوب:
- يتطلب استثمار في أجهزة وحدات معالجة رسومية للمؤسسات
- تدهور طفيف في الجودة من التكمية (عادةً ما يكون ضئيلًا لدقة 4 بت)
- يتطلب خبرة في تكوين التوازي المتعدد لوحدات المعالجة الرسومية للموشورات
الاستراتيجية 3: خدمة واجهة برمجة التطبيقات المُدارة
متى تختار واجهة برمجة التطبيقات:
- أنماط استخدام متغيرة أو غير متوقعة
- ترغب في تجنب إدارة بنية تحتية لوحدات المعالجة الرسومية
- تحتاج إلى وصول فوري بدون تأخيرات في شراء الأجهزة
- تطوير نماذج أولية قبل الالتزام بالنشر المحلي
متى تختار النشر المحلي:
- استخدام متسق كبير الحجم حيث تتراكم تكاليف الرمز الواحد
- متطلبات خصوصية البيانات أو الامتثال تمنع استخدام واجهة برمجة التطبيقات الخارجية
- تحتاج إلى تحكم كامل في سلوك النموذج وإصداره
- تطوير إصدارات مخصصة مُعدلة بدقة
الرؤية الأساسية للمطورين: النشر المحلي لـ M2.1 متاح ولكنه يتطلب اختيارات استراتيجية للأجهزة. بينما يتطلب النشر بدقة كاملة 400-500 جيجابايت من ذاكرة الوصول العشوائي للفيديو (منطقة مراكز بيانات للمؤسسات)، توجد بدائل عملية: تتيح التكمية بدقة 4 بت النشر على 2x وحدات معالجة رسومية RTX 6000 Pro (~200 جيجابايت إجمالي)، وتعمل استراتيجيات وحدة المعالجة المركزية / معالج الرسوميات الهجينة مع وحدات المعالجة الرسومية للمستهلكين بدءًا من 32 جيجابايت VRAM.
للمطورين والمؤسسات في الغالب، شجرة القرار واضحة:
- التجارب والتطوير: النهج الهجين لوحدة المعالجة المركزية / معالج الرسوميات مع RTX 5090/6000 Ada + 128 جيجابايت على الأقل من الذاكرة
- النشر الإنتاجي (مستضاف محليًا): تكوين مكمّم متعدد وحدات المعالجة الرسومية (2x RTX 6000 Pro كحد أدنى)
- النشر الإنتاجي (مُدار): واجهة برمجة التطبيقات لتبسيط العمليات وتوقع التكاليف
الأسئلة الشائعة
كم مقدار ذاكرة الوصول العشوائي للفيديو الذي يتطلبه MiniMax-M2.1 للنشر المحلي؟ يُقدر أن FP16 يحتاج إلى 450–500 جيجابايت VRAM، بينما تستخدم الإعدادات العملية التكمية بدقة 4 بت (200 جيجابايت) أو النشر الهجين لوحدة المعالجة المركزية / معالج الرسوميات (32 جيجابايت VRAM + ذاكرة نظام كبيرة).
هل يمكنني تشغيل MiniMax-M2.1 على وحدة معالجة رسومية للمستهلكين مثل RTX 4090 أو RTX 5090؟ نعم، ولكن عادةً فقط مع إلغاء التحميل إلى وحدة المعالجة المركزية و ذاكرة نظام 128 جيجابايت على الأقل، متاجرًا بالسرعة من أجل إمكانية التنفيذ.
ما الفرق بين متطلبات ذاكرة الوصول العشوائي للفيديو لـ M2 و M2.1؟ لم يتم تقديم مقارنة رسمية، لكن مقياس المعاملات المتماثل لهما يشير إلى احتياجات VRAM متشابهة إلى حد كبير.
Novita AI هي منصة سحابية شاملة تمكّن طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، بدون خوادم، مثيلات لوحدات معالجة الرسوميات — الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجانًا، وحقق رؤيتك في الذكاء الاصطناعي.
قراءات موصى بها
شرح حدود ذاكرة الوصول العشوائي للفيديو لـ Kimi K2 Thinking للمطورين ذوي الميزانيات المحدودة
DeepSeek مقابل Qwen: حدد أي نظام بيئي يناسب احتياجات الإنتاج
تكلفة DeepSeek R1 0528: مقارنة بين واجهة برمجة التطبيقات، وحدات المعالجة الرسومية، والنشر المحلي



