

MiniMax-M2.1의 출시는 오픈소스 AI 모델, 특히 에이전트 기능과 소프트웨어 엔지니어링 작업에 집중하는 개발자에게 중요한 진화를 의미합니다. 2,287억 개의 매개변수를 가진 이 모델은 다국어 코딩 벤치마크에서 인상적인 성능을 제공하면서도 완전히 투명하고 로컬에 배포할 수 있습니다. 그러나 로컬 배포를 계획하는 개발자에게 중요한 질문은 MiniMax-M2.1이 실제로 얼마나 많은 VRAM을 필요로 하느냐는 것입니다.
빠른 답변: MiniMax M2.1 VRAM 요구 사항
로컬에서 MiniMax-M2.1을 실행하려는 개발자에게 VRAM 제약은 다음에 직접적인 영향을 미칩니다.
- 배포 가능성: 사용 가능한 하드웨어에서 모델을 실행할 수 있는지 여부
- 추론 속도: GPU 메모리는 병렬 처리를 가능하게 함; CPU 오프로딩은 생성 속도를 크게 저하시킴
- 컨텍스트 창 활용: 더 긴 컨텍스트는 KV 캐시를 위해 추가 메모리가 필요함
- 배치 크기: 여러 요청을 동시에 처리하면 메모리 요구량이 배가됨
- 비용 계획: GPU 대여 또는 하드웨어 구매 결정은 정확한 VRAM 추정에 기반함

주요 배포 구성:
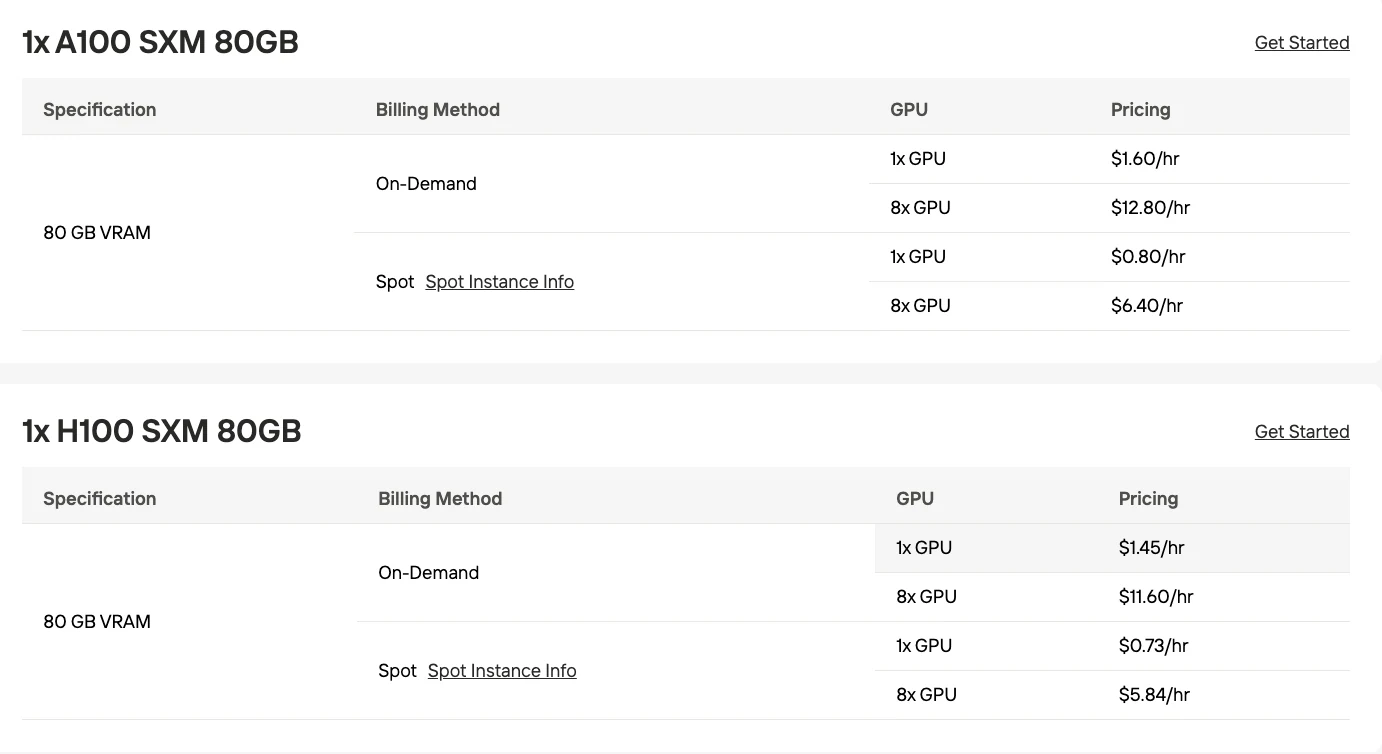
- 프로덕션 전체 정밀도: 정확한 VRAM은 공개되지 않음; 매개변수 수 기준으로 400~500GB로 추정
- 4비트 양자화: 200GB VRAM (400k 컨텍스트의 2x RTX 6000 Pro)
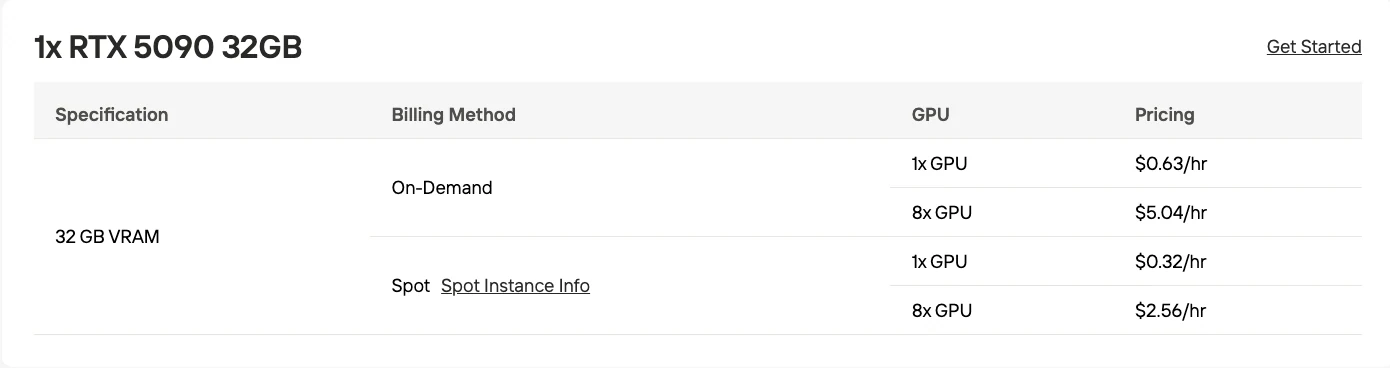
- 하이브리드 CPU 오프로드: 32GB VRAM (RTX 5090급) + CPU 메모리 지원
배포 구성별 MiniMax M2.1 VRAM 요구 사항
전체 정밀도 배포
| 구성 요소 | 필요 메모리 | 계산 기준 |
|---|---|---|
| 모델 가중치 (FP16) | 458 GB | 2287억 개 매개변수 × 2바이트 |
| 프레임워크 오버헤드 | 20~40 GB | 일반적인 PyTorch/vLLM 오버헤드 |
| 총 추정치 | 480~500 GB | 추론 최소 필요량 (짧은 컨텍스트) |
양자화 배포 옵션
4비트 양자화
Hacker News 토론에 따르면 MiniMax-M2.1은 4비트 양자화 상태에서 2x RTX 6000 Pro GPU(총 200GB VRAM) 로 약 400k 컨텍스트 윈도우를 지원하며 실행할 수 있습니다. 이는 전체 정밀도 요구량에서 상당한 감소를 의미합니다.
M2의 경우, 그렇습니다. Claude Code(예: 네이티브 툴 호출), Roo/Cline(예: 사용자 정의 툴 파싱) 등에서 사용해 봤습니다. 꽤 좋았고 한동안 셀프 호스팅하기에 가장 좋은 모델이었습니다. 4비트에서는 2x RTX 6000 Pro(약 200GB VRAM)에 fp8 KV 캐시로 약 400k 컨텍스트를 수용할 수 있습니다. 활성 매개변수가 적어 매우 빠르고, 긴 컨텍스트에서 안정적이며, 모든 에이전트 하네스에서 상당히 유능합니다(훈련 특화 분야). M2.1은 M2보다 훨씬 더 작은 모델과 비교해도 충분히 훈련되지 않았던 M2를 뛰어넘는 좋은 향상이어야 합니다.
Hacker News에서 발췌
4비트 양자화는 일반적으로 FP16 대비 모델 크기를 약 75% 줄이며, 이는 이러한 배포 관찰과 일치합니다.
- 모델 가중치: 115GB (2287억 개 매개변수 × 0.5바이트)
- 프레임워크 + KV 캐시: 85GB 추가
- 합계: 200GB VRAM
하이브리드 CPU-GPU 오프로딩
소비자용 GPU를 사용하는 개발자를 위해, ktransformers 프레임워크는 모델의 일부를 CPU 메모리로 오프로드함으로써 M2.1을 32GB VRAM(RTX 5090에 해당)으로 실행할 수 있음을 보여줍니다.
이 하이브리드 접근 방식은 접근성과 추론 속도를 맞바꿉니다.
- GPU VRAM: 32GB (중요 레이어 및 활성 계산)
- 시스템 RAM: 상당한 추가 RAM 필요 (정확한 양은 명시되지 않음)
- 성능 트레이드오프: CPU 오프로딩은 전체 GPU 배포에 비해 지연 시간을 증가시킵니다.
MiniMax-M2.1 배포를 위한 하드웨어 권장 사항
개발 및 실험용
프로토타입을 만들거나 M2.1의 기능을 테스트 중이라면, 하이브리드 CPU-GPU 방식이 가장 접근하기 쉬운 진입점을 제공합니다.
| 구성 요소 | 최소 사양 | 권장 사양 |
|---|---|---|
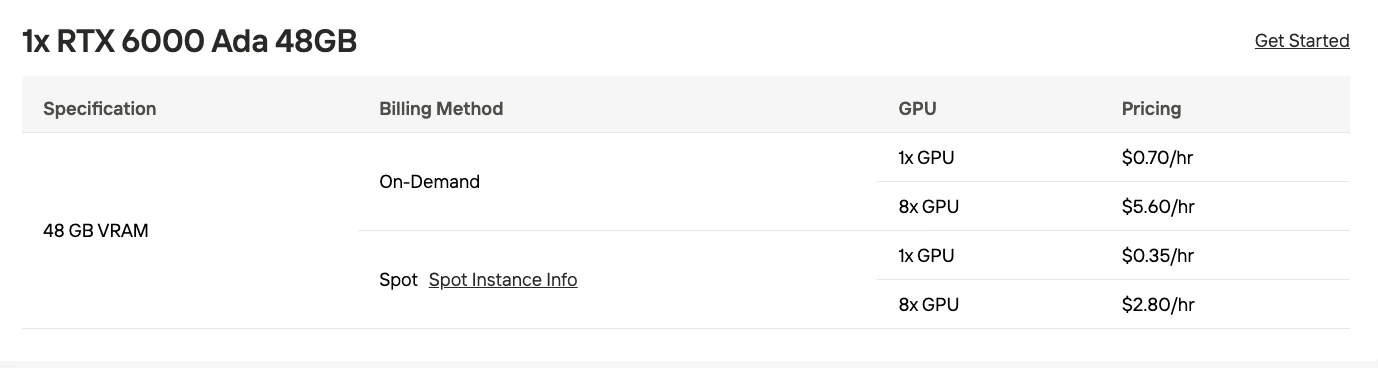
| GPU | 32GB VRAM (RTX 5090) | 48GB VRAM (RTX 6000 Ada) |
| 시스템 RAM | 128GB DDR4/DDR5 | 256GB DDR5 |
| 스토리지 | 1TB NVMe SSD | 2TB NVMe SSD |
| 프레임워크 | CPU 오프로딩이 포함된 ktransformers |
예상 성능: 단일 사용자 실험 및 개발에 적합합니다. 추론 속도는 전체 GPU 배포보다 느리지만 에이전트 워크플로 및 코드 생성 작업 테스트에는 충분히 기능적입니다.
프로덕션 배포용
여러 사용자에게 서비스하거나 저지연 응답이 필요한 프로덕션 환경은 전체 GPU 메모리 할당이 필요합니다.
| 배포 유형 | GPU 구성 | 총 VRAM | 사용 사례 |
|---|---|---|---|
| 멀티 GPU (4비트) | 2x RTX 6000 Pro (각 96GB) | ~192GB | 중간 규모 프로덕션 |
| 데이터센터 GPU | 4x H100 (각 80GB) | 320GB | 높은 처리량 프로덕션 |
| 클라우드 대안 | API | 관리형 서비스 | 인프라 없는 프로덕션 |
비용 고려사항: 2x RTX 6000 Pro 구성은 데이터센터 규모의 인프라 없이 로컬 배포가 필요한 조직에게 실용적인 균형을 제공합니다. 많은 사용 사례에서 로컬 GPU 인프라를 유지하는 것보다 API가 더 나은 경제성을 제공할 수 있습니다.
실용적인 배포 전략
전략 1: 하이브리드 CPU-GPU 오프로딩 (소비자 하드웨어)
ktransformers 프레임워크는 모델을 GPU와 CPU 메모리에 지능적으로 분산시켜 소비자용 GPU에서도 배포를 가능하게 합니다.
# 예시 배포 접근 방식 (정확한 명령어는 ktransformers 문서 참조)
# 필요 사항: 32GB+ VRAM GPU, 128GB+ 시스템 RAM
# 프레임워크가 사용 가능한 리소스에 따라
# GPU와 CPU 메모리 간의 자동 레이어 분배를 처리합니다.
장점:
- 고성능 소비자 GPU(RTX 5090, RTX 6000 Ada)로 사용 가능
- 낮은 초기 하드웨어 투자
- 개발 및 소규모 프로덕션에 적합
단점:
- CPU-GPU 데이터 전송으로 인한 느린 추론 속도
- 상당한 시스템 RAM 필요 (128GB+)
- 높은 동시성 프로덕션 워크로드에는 부적합
전략 2: 멀티 GPU 양자화 배포
1단계: 계정 등록
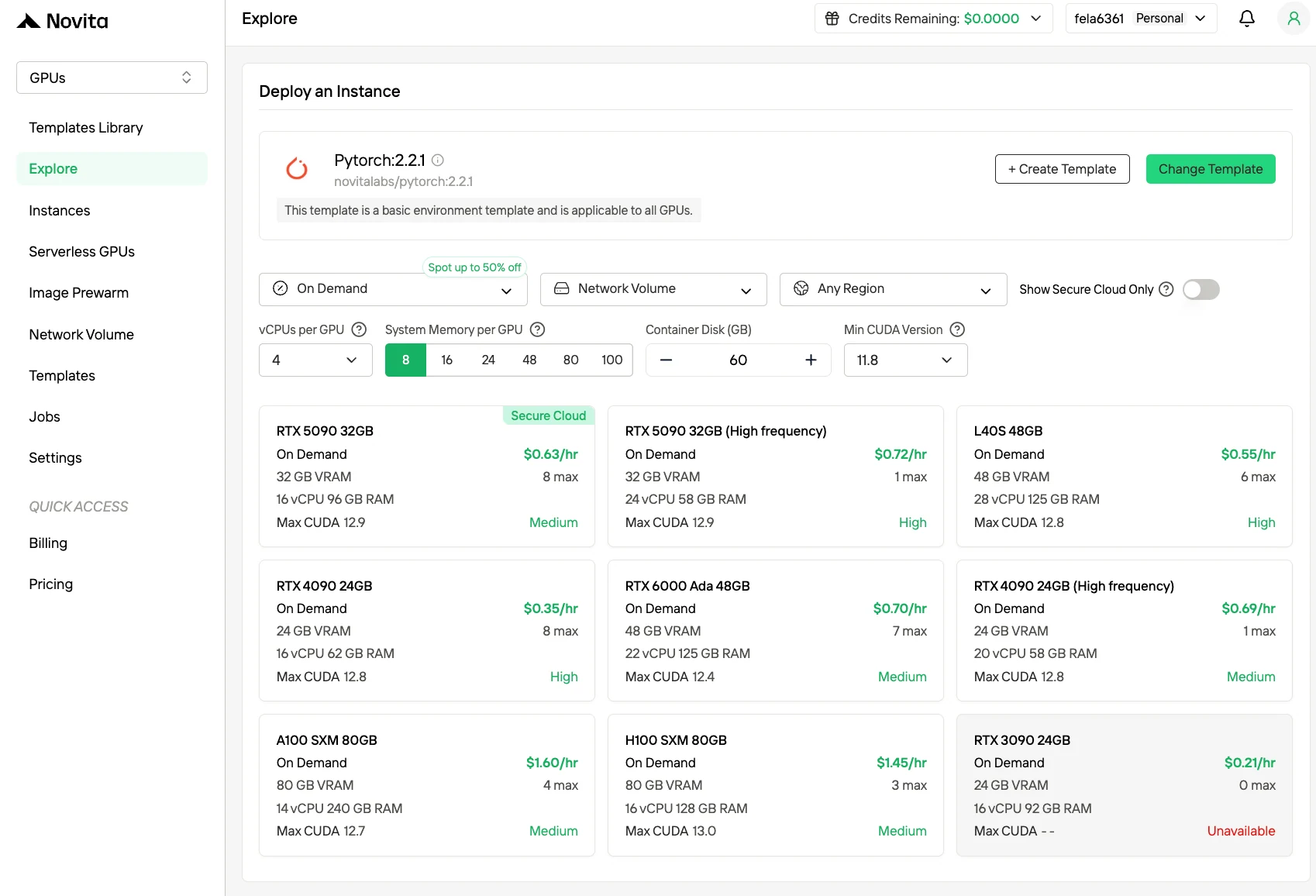
웹사이트를 통해 Novita AI 계정을 만드세요. 등록 후 왼쪽 사이드바에서 “탐색(Explore)” 섹션으로 이동하여 GPU 상품을 확인하고 AI 개발 여정을 시작하세요.

2단계: 템플릿 및 GPU 서버 탐색
프로젝트 요구 사항에 맞는 PyTorch, TensorFlow 또는 CUDA와 같은 템플릿을 선택하세요. 그런 다음 원하는 GPU 구성을 선택하세요. 강력한 L40S, RTX 4090 또는 A100 SXM4와 같은 옵션이 있으며 각각 다른 VRAM, RAM 및 스토리지 사양을 제공합니다.
3단계: 배포 맞춤 설정
선호하는 운영 체제와 구성 옵션을 선택하여 특정 AI 워크로드 및 개발 요구 사항에 최적의 성능을 보장하도록 환경을 맞춤 설정하세요.
4단계: 인스턴스 시작
"인스턴스 시작(Launch Instance)"을 선택하여 배포를 시작하세요. 고성능 GPU 환경이 몇 분 안에 준비되어 머신 러닝, 렌더링 또는 컴퓨팅 프로젝트를 즉시 시작할 수 있습니다.
장점:
- CPU 병목 현상 없는 전체 GPU 성능
- 여러 동시 요청 처리 가능
- 확장된 컨텍스트 윈도우 지원 (~400k 토큰)
단점:
- 엔터프라이즈 GPU 하드웨어 투자 필요
- 양자화로 인한 약간의 품질 저하 (일반적으로 4비트에서는 미미함)
- 멀티 GPU 텐서 병렬 처리 구성에 대한 전문 지식 필요
전략 3: 관리형 API 서비스
API를 선택해야 하는 경우:
- 변동적이거나 예측 불가능한 사용 패턴
- GPU 인프라 관리를 피하고 싶은 경우
- 하드웨어 조달 지연 없이 즉시 액세스가 필요한 경우
- 로컬 배포 전 프로토타입 개발
로컬 배포를 선택해야 하는 경우:
- 토큰당 비용이 누적되는 대량의 일관된 사용
- 데이터 프라이버시 또는 규정 준수 요구 사항으로 인해 외부 API 사용이 불가능한 경우
- 모델 동작 및 버전에 대한 완전한 제어가 필요한 경우
- 맞춤형 미세 조정 버전을 개발하는 경우
개발자를 위한 핵심 인사이트: 로컬 M2.1 배포는 가능하지만 전략적인 하드웨어 선택이 필요합니다. 전체 정밀도 배포는 400~500GB의 VRAM(엔터프라이즈 데이터센터 영역)을 요구하지만, 실용적인 대안이 존재합니다: 4비트 양자화는 2x RTX 6000 Pro GPU(총 ~200GB)에서 배포를 가능하게 하고, 하이브리드 CPU-GPU 전략은 32GB VRAM부터 시작하는 소비자 GPU에서도 작동합니다.
대부분의 개발자와 조직에게 의사 결정 트리는 명확합니다.
- 실험 및 개발: RTX 5090/6000 Ada + 128GB+ RAM을 사용한 하이브리드 CPU-GPU 방식
- 프로덕션 배포 (자체 호스팅): 멀티 GPU 양자화 구성 (최소 2x RTX 6000 Pro)
- 프로덕션 배포 (관리형): 운영 단순성과 비용 예측 가능성을 위한 API
자주 묻는 질문
MiniMax-M2.1을 로컬에 배포하려면 얼마나 많은 VRAM이 필요한가요?
FP16은 450~500GB VRAM이 필요한 것으로 추정되며, 실용적인 설정은 4비트 양자화(200GB) 또는 CPU-GPU 하이브리드 배포(32GB VRAM + 대용량 시스템 RAM) 를 사용합니다.
RTX 4090 또는 RTX 5090과 같은 소비자 GPU에서 MiniMax-M2.1을 실행할 수 있나요?
가능하지만, 일반적으로 CPU 오프로딩과 128GB+ 시스템 RAM이 필요하며, 속도를 희생하여 실행 가능성을 확보합니다.
M2와 M2.1의 VRAM 요구 사항 차이는 무엇인가요?
공식적인 비교는 제공되지 않지만, 유사한 매개변수 규모를 고려할 때 VRAM 요구량은 대략 비슷합니다.
Novita AI는 AI 야망을 실현하는 올인원 클라우드 플랫폼입니다. 통합 API, 서버리스, GPU 인스턴스 — 필요한 비용 효율적인 도구를 제공합니다. 인프라를 없애고, 무료로 시작하여 AI 비전을 현실로 만드세요.
추천 자료
Kimi K2 Thinking VRAM Limits Explained for Cost-Constrained Developers
DeepSeek vs Qwen: Identify Which Ecosystem Fits Production Needs



