

Die Veröffentlichung von MiniMax-M2.1 markiert eine bedeutende Weiterentwicklung quelloffener KI-Modelle, insbesondere für Entwickler, die sich auf agentische Funktionen und Software-Engineering-Aufgaben konzentrieren. Mit 228,7 Milliarden Parametern liefert dieses Modell beeindruckende Leistung bei mehrsprachigen Code-Benchmarks, ist vollständig transparent und kann lokal bereitgestellt werden. Die entscheidende Frage für Entwickler, die eine lokale Bereitstellung planen, lautet jedoch: Wie viel VRAM benötigt MiniMax-M2.1 tatsächlich?
Kurze Antwort: VRAM-Anforderungen von MiniMax M2.1
Für Entwickler, die MiniMax-M2.1 lokal ausführen möchten, wirken sich VRAM-Einschränkungen direkt auf folgende Punkte aus:
- Bereitstellungsmöglichkeit: Ob Sie das Modell überhaupt auf der verfügbaren Hardware ausführen können
- Inferenzgeschwindigkeit: GPU-Speicher ermöglicht parallele Verarbeitung; CPU-Auslagerung verlangsamt die Generierung deutlich
- Nutzung des Kontextfensters: Längere Kontexte erfordern zusätzlichen Speicher für den KV-Cache
- Batch-Größe: Die gleichzeitige Verarbeitung mehrerer Anfragen vervielfacht den Speicherbedarf
- Kostenplanung: Entscheidungen über GPU-Miete oder Hardwarekauf hängen von genauen VRAM-Schätzungen ab

Wichtige Bereitstellungskonfigurationen:
- Volllastproduktion (volle Genauigkeit): Der genaue VRAM-Bedarf ist nicht öffentlich bekannt; basierend auf der Parameteranzahl wird er auf 400–500 GB geschätzt
- 4-Bit-Quantisierung: 200 GB VRAM (2x RTX 6000 Pro mit 400k Kontext)
- Hybride CPU-Auslagerung: 32 GB VRAM (RTX 5090-Äquivalent) mit Unterstützung durch CPU-Speicher
VRAM-Anforderungen von MiniMax M2.1 nach Bereitstellungskonfiguration
Bereitstellung in voller Genauigkeit
| Komponente | Erforderlicher Speicher | Berechnungsgrundlage |
|---|---|---|
| Modellgewichte (FP16) | 458 GB | 228,7 Mrd. Parameter × 2 Byte |
| Framework-Overhead | 20–40 GB | Typischer Overhead von PyTorch/vLLM |
| Geschätzter Gesamtbedarf | 480–500 GB | Minimum für Inferenz (kurzer Kontext) |
Quantisierte Bereitstellungsoptionen
4-Bit-Quantisierung
Laut einer Diskussion auf Hacker News kann MiniMax-M2.1 bei 4-Bit-Quantisierung auf 2x RTX 6000 Pro GPUs (insgesamt 200 GB VRAM) mit Unterstützung für ein Kontextfenster von ca. 400k ausgeführt werden. Dies stellt eine deutliche Reduzierung gegenüber den Anforderungen bei voller Genauigkeit dar.
Mit M2 ja – ich habe es in Claude Code (z. B. native Tool-Aufrufe), Roo/Cline (z. B. benutzerdefinierte Tool-Parsing) usw. verwendet. Es ist ziemlich gut und war für einige Zeit das beste Modell für das Selbsthosting. Bei 4-Bit passt es auf 2x RTX 6000 Pro (z. B. ~200 GB VRAM) mit einem Kontext von ca. 400k bei fp8-KV-Cache. Es ist sehr schnell aufgrund der geringen Anzahl aktiver Parameter, stabil bei langen Kontexten und ziemlich leistungsfähig in jedem Agenten-Framework (seine Trainingsspezialität). M2.1 sollte eine deutliche Verbesserung gegenüber M2 sein, das im Vergleich zu sogar viel kleineren Modellen untertrainiert war.
Aus Hacker News
4-Bit-Quantisierung reduziert die Modellgröße typischerweise um ca. 75 % im Vergleich zu FP16, was mit diesen Beobachtungen zur Bereitstellung übereinstimmt:
- Modellgewichte: 115 GB (228,7 Mrd. Parameter × 0,5 Byte)
- Framework + KV-Cache: 85 GB zusätzlich
- Gesamt: 200 GB VRAM
Hybride CPU-GPU-Auslagerung
Für Entwickler mit Consumer-GPUs zeigt das ktransformers-Framework, dass M2.1 mit 32 GB VRAM (äquivalent zu einer RTX 5090) ausgeführt werden kann, indem Teile des Modells in den CPU-Speicher ausgelagert werden.
Dieser hybride Ansatz tauscht Inferenzgeschwindigkeit gegen Zugänglichkeit:
- GPU-VRAM: 32 GB (kritische Schichten und aktive Berechnungen)
- System-RAM: Erheblicher zusätzlicher RAM erforderlich (genaue Menge nicht angegeben)
- Leistungskompromiss: CPU-Auslagerung führt im Vergleich zu einer vollständigen GPU-Bereitstellung zu Latenz
Hardware-Empfehlungen für die Bereitstellung von MiniMax-M2.1
Für Entwicklung und Experimente
Wenn Sie Prototypen erstellen oder die Fähigkeiten von M2.1 testen, bietet der hybride CPU-GPU-Ansatz den zugänglichsten Einstieg:
| Komponente | Mindestspezifikation | Empfohlen |
|---|---|---|
| GPU | 32 GB VRAM (RTX 5090) | 48 GB VRAM (RTX 6000 Ada) |
| System-RAM | 128 GB DDR4/DDR5 | 256 GB DDR5 |
| Speicher | 1 TB NVMe-SSD | 2 TB NVMe-SSD |
| Framework | ktransformers mit CPU-Auslagerung |
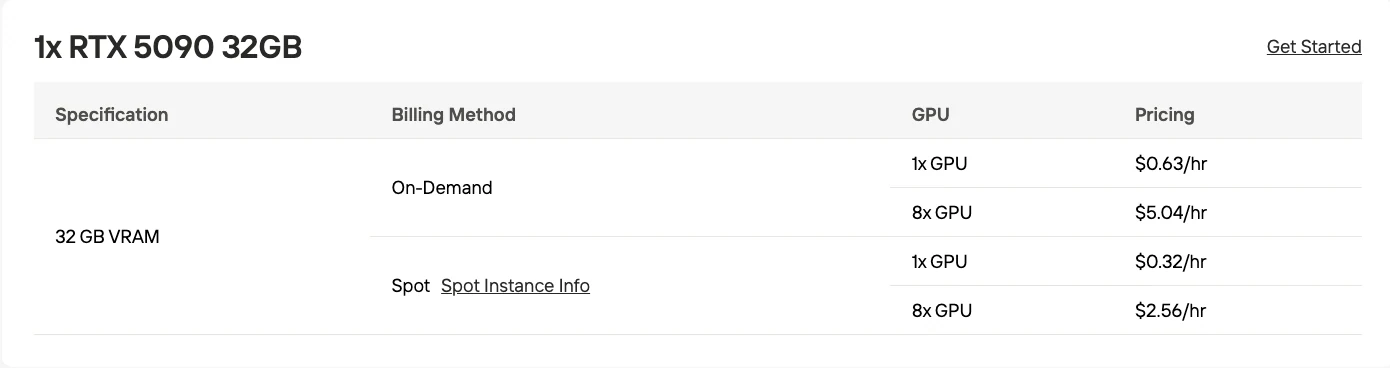
Probieren Sie kostengünstige GPUs aus!
Erwartete Leistung: Geeignet für Experimente und Entwicklung für einzelne Benutzer. Die Inferenzgeschwindigkeit ist langsamer als bei einer vollständigen GPU-Bereitstellung, aber funktional für das Testen von agentischen Workflows und Code-Generierungsaufgaben.
Für Produktionsbereitstellung
Produktionsumgebungen, die mehrere Benutzer bedienen oder niedrige Latenzzeiten erfordern, benötigen eine vollständige GPU-Speicherzuweisung:
| Bereitstellungstyp | GPU-Konfiguration | Gesamt-VRAM | Anwendungsfall |
|---|---|---|---|
| Multi-GPU (4-Bit) | 2x RTX 6000 Pro (je 96 GB) | ~192 GB | Mittelgroße Produktion |
| Rechenzentrums-GPUs | 4x H100 (je 80 GB) | 320 GB | Hochdurchsatzproduktion |
| Cloud-Alternative | API | Verwalteter Dienst | Produktion ohne Infrastruktur |
Kostenüberlegung: Die Konfiguration mit 2x RTX 6000 Pro stellt ein praktisches Gleichgewicht für Organisationen dar, die eine lokale Bereitstellung ohne rechenzentrumsgroße Infrastruktur benötigen. Für viele Anwendungsfälle bietet die API möglicherweise eine bessere Wirtschaftlichkeit als die Wartung lokaler GPU-Infrastruktur.
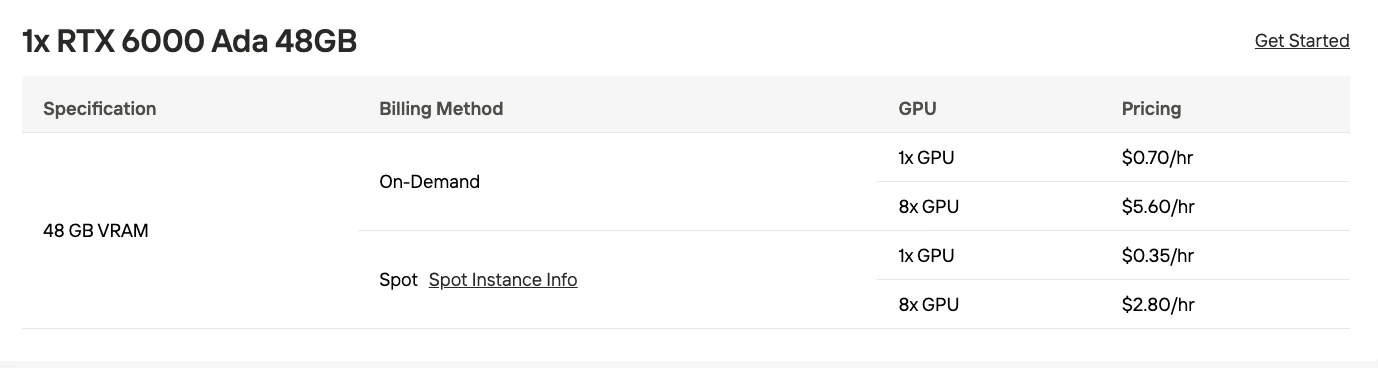
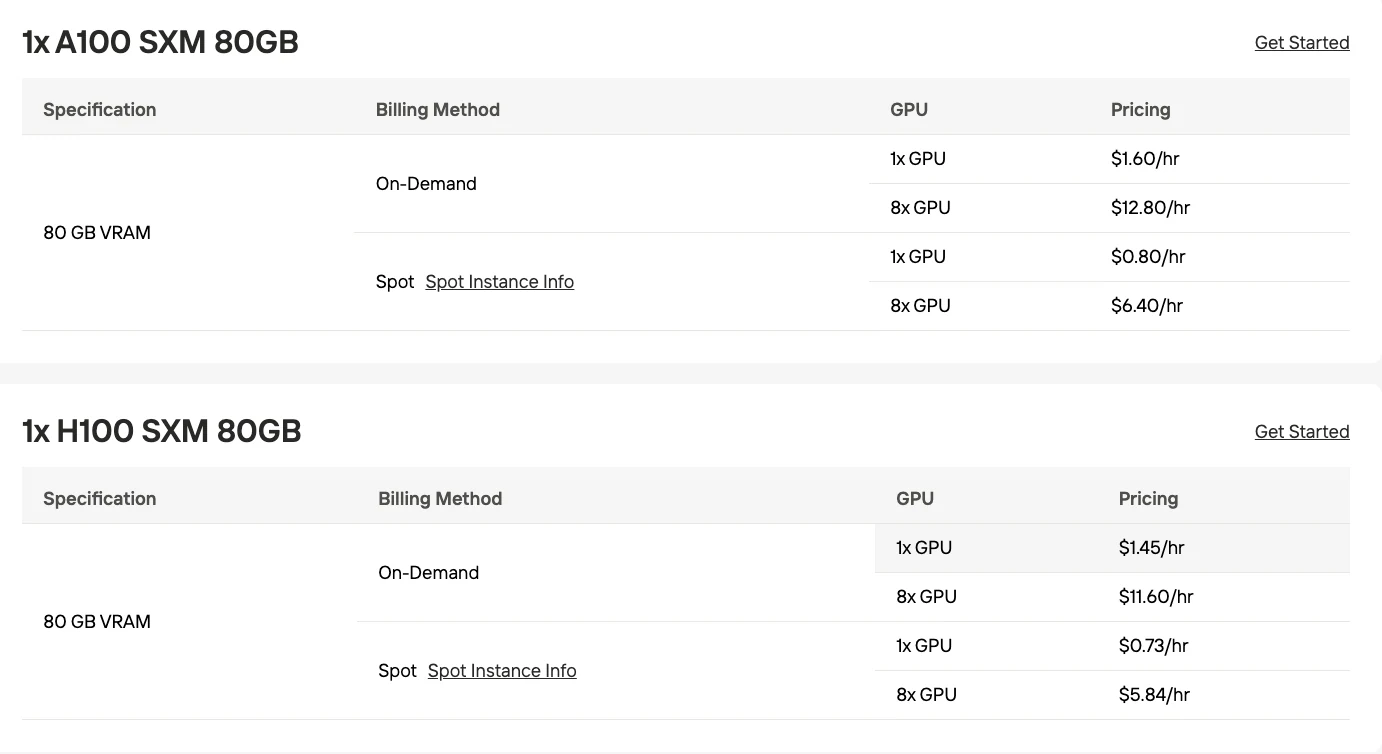
Probieren Sie kostengünstige GPUs aus!
Praktische Bereitstellungsstrategien
Strategie 1: Hybride CPU-GPU-Auslagerung (Consumer-Hardware)
Das ktransformers-Framework ermöglicht die Bereitstellung auf Consumer-GPUs, indem es das Modell intelligent auf GPU- und CPU-Speicher verteilt:
# Example deployment approach (refer to ktransformers documentation for exact commands)
# Requires: 32GB+ VRAM GPU, 128GB+ system RAM
# Framework handles automatic layer distribution
# between GPU and CPU memory based on available resources
Vorteile:
- Zugänglich mit High-End-Consumer-GPUs (RTX 5090, RTX 6000 Ada)
- Geringere anfängliche Hardwareinvestition
- Geeignet für Entwicklung und Produktion mit geringem Volumen
Nachteile:
- Langsamere Inferenzgeschwindigkeit aufgrund von CPU-GPU-Datenübertragung
- Erfordert erheblichen System-RAM (128 GB+)
- Nicht geeignet für Produktionsarbeitslasten mit hoher Gleichzeitigkeit
Strategie 2: Multi-GPU-quantisierte Bereitstellung
Schritt 1:Konto erstellen
Erstellen Sie Ihr Novita AI-Konto über unsere Website. Nach der Registrierung navigieren Sie zum Bereich „Explore“ in der linken Seitenleiste, um unsere GPU-Angebote anzusehen und Ihre KI-Entwicklungsreise zu beginnen.

Schritt 2:Erkunden von Vorlagen und GPU-Servern**
Wählen Sie Vorlagen wie PyTorch, TensorFlow oder CUDA, die zu den Anforderungen Ihres Projekts passen. Wählen Sie anschließend Ihre bevorzugte GPU-Konfiguration – zu den Optionen gehören die leistungsstarken L40S, RTX 4090 oder A100 SXM4, jeweils mit unterschiedlichen Spezifikationen für VRAM, RAM und Speicher.
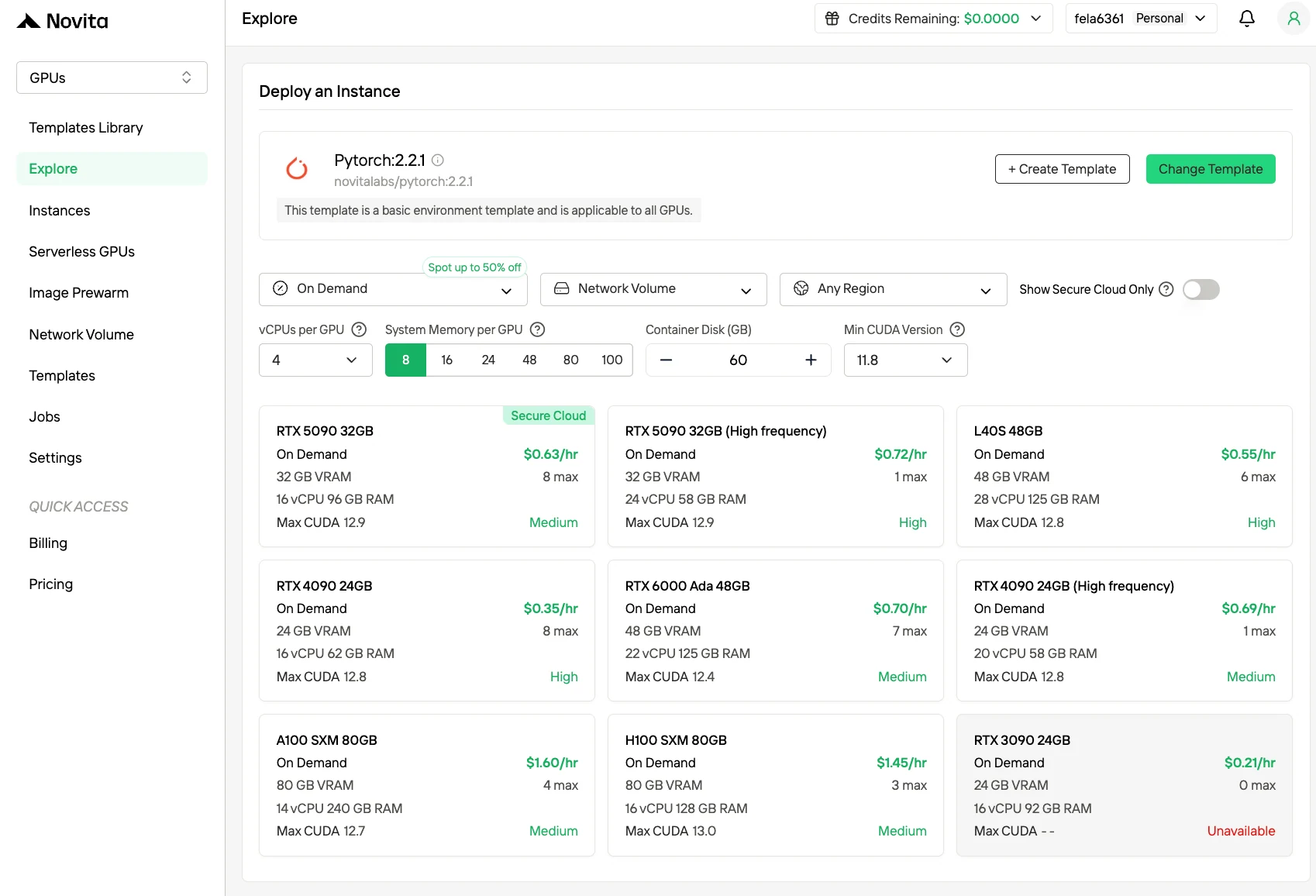
Schritt 3:Passen Sie Ihre Bereitstellung an
Passen Sie Ihre Umgebung an, indem Sie Ihr bevorzugtes Betriebssystem und Konfigurationsoptionen auswählen, um eine optimale Leistung für Ihre spezifischen KI-Arbeitslasten und Entwicklungsanforderungen zu gewährleisten.
Probieren Sie kostengünstige GPUs aus!
Schritt 4:Starten einer Instanz
Wählen Sie „Instanz starten“, um Ihre Bereitstellung zu beginnen. Ihre leistungsstarke GPU-Umgebung ist innerhalb von Minuten einsatzbereit, sodass Sie sofort mit Ihren Machine-Learning-, Rendering- oder Rechenprojekten beginnen können.
Vorteile:
- Volle GPU-Leistung ohne CPU-Engpässe
- Kann mehrere gleichzeitige Anfragen verarbeiten
- Unterstützung für erweitertes Kontextfenster (~400k Token)
Nachteile:
- Erfordert Investitionen in Enterprise-GPU-Hardware
- Leichte Qualitätseinbußen durch Quantisierung (bei 4-Bit typischerweise minimal)
- Erfordert Fachwissen bei der Konfiguration von Multi-GPU-Tensorparallelität
Strategie 3: Verwalteter API-Dienst
Probieren Sie MiniMax M2.1 jetzt aus!
Wann Sie die API wählen sollten:
- Variable oder unvorhersehbare Nutzungsmuster
- Sie möchten die Verwaltung von GPU-Infrastruktur vermeiden
- Sie benötigen sofortigen Zugriff ohne Verzögerungen bei der Hardwarebeschaffung
- Prototypentwicklung vor der Entscheidung für eine lokale Bereitstellung
Wann Sie eine lokale Bereitstellung wählen sollten:
- Hohes, gleichmäßiges Nutzungsvolumen, bei dem die Kosten pro Token anfallen
- Datenschutz- oder Compliance-Anforderungen verbieten die Nutzung externer APIs
- Sie benötigen vollständige Kontrolle über Modellverhalten und -version
- Entwicklung von benutzerdefinierten feinabgestimmten Versionen
Die wichtigste Erkenntnis für Entwickler: Die lokale M2.1-Bereitstellung ist zugänglich, erfordert aber strategische Hardware-Entscheidungen. Während die Bereitstellung in voller Genauigkeit 400–500 GB VRAM erfordert (Enterprise-Rechenzentrumsbereich), gibt es praktische Alternativen: 4-Bit-Quantisierung ermöglicht die Bereitstellung auf 2x RTX 6000 Pro GPUs (insgesamt ~200 GB), und hybride CPU-GPU-Strategien funktionieren mit Consumer-GPUs ab 32 GB VRAM.
Für die meisten Entwickler und Organisationen ist der Entscheidungsbaum klar:
- Experimente und Entwicklung: Hybrider CPU-GPU-Ansatz mit RTX 5090/6000 Ada + 128 GB+ RAM
- Produktionsbereitstellung (selbst gehostet): Multi-GPU-quantisierte Konfiguration (mindestens 2x RTX 6000 Pro)
- Produktionsbereitstellung (verwaltet): API für betriebliche Einfachheit und vorhersehbare Kosten
Häufig gestellte Fragen
Wie viel VRAM benötigt MiniMax-M2.1 für die lokale Bereitstellung? FP16 wird schätzungsweise 450–500 GB VRAM benötigen, während praktische Setups 4-Bit-Quantisierung (200 GB) oder CPU-GPU-Hybridbereitstellung (32 GB VRAM + großer System-RAM) verwenden.
Kann ich MiniMax-M2.1 auf einer Consumer-GPU wie RTX 4090 oder RTX 5090 ausführen? Ja, aber typischerweise nur mit CPU-Auslagerung und 128 GB+ System-RAM, wobei Geschwindigkeit gegen Machbarkeit eingetauscht wird.
Was ist der Unterschied zwischen den VRAM-Anforderungen von M2 und M2.1? Es liegt kein offizieller Vergleich vor, aber ihre ähnliche Parameteranzahl deutet auf annähernd vergleichbare VRAM-Anforderungen hin.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen verwirklicht. Integrierte APIs, Serverless, GPU-Instanzen – die kostengünstigen Tools, die Sie benötigen. Eliminieren Sie Infrastruktur, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.
Empfohlene Lektüre
VRAM-Grenzen von Kimi K2 Thinking erklärt für kostenbewusste Entwickler
DeepSeek vs. Qwen: Finden Sie heraus, welches Ökosystem zu Ihren Produktionsanforderungen passt
Kosten von DeepSeek R1 0528: Vergleich von API, GPU und On-Prem



