

MiniMax-M2.1 的發布標誌著開源 AI 模型的重要演進,尤其對於專注於智能體能力與軟體工程任務的開發者而言更是如此。這款模型擁有 2287 億個參數,在多語言編碼基準測試中表現優異,同時完全透明且支援本地部署。不過,對於規劃本地部署的開發者來說,關鍵問題是:MiniMax-M2.1 實際需要多少 VRAM?
快速解答:MiniMax M2.1 VRAM 需求
對於規劃本地執行 MiniMax-M2.1 的開發者來說,VRAM 限制會直接影響以下面向:
- 部署可行性:現有硬體是否足以執行該模型
- 推理速度:GPU 記憶體能實現平行處理;CPU 卸載會大幅降低生成速度
- 上下文視窗利用率:更長的上下文需要額外記憶體來儲存 KV 快取
- 批次大小:同時處理多個請求會倍增記憶體需求
- 成本規劃:GPU 租賃或硬體購買決策取決於精確的 VRAM 估算

關鍵部署配置:
- 生產環境全精度:官方未公開確切 VRAM 需求;根據參數量估算約 400-500GB
- 4-bit 量化:200GB VRAM(2 張 RTX 6000 Pro,支援 400k 上下文)
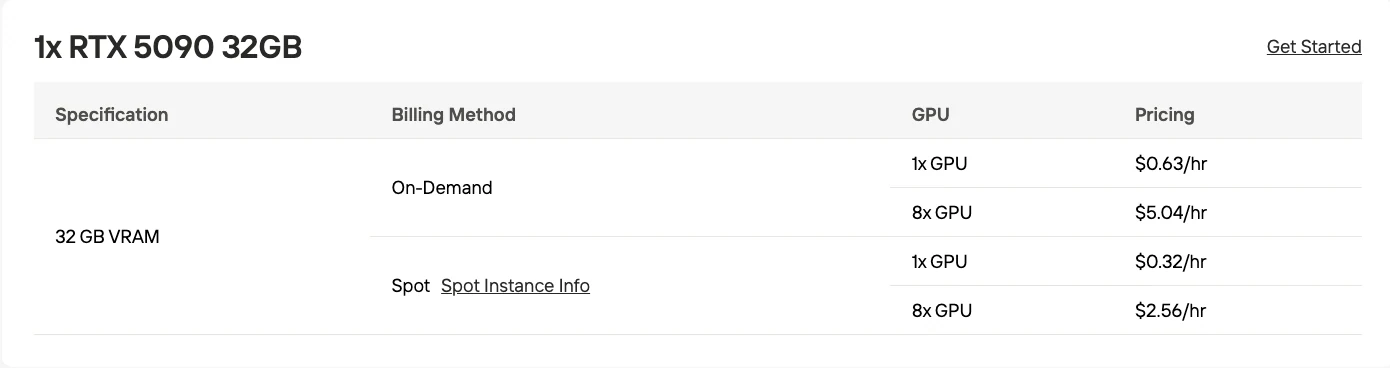
- 混合 CPU 卸載:32GB VRAM(等同 RTX 5090),搭配 CPU 記憶體輔助
依部署配置劃分的 MiniMax M2.1 VRAM 需求
全精度部署
| 組件 | 所需記憶體 | 計算依據 |
|---|---|---|
| 模型權重(FP16) | 458 GB | 2287 億參數 × 2 位元組 |
| 框架開銷 | 20-40 GB | 典型 PyTorch/vLLM 額外消耗 |
| 總估算值 | 480-500 GB | 推理(短上下文)最低需求 |
量化部署方案
4-bit 量化
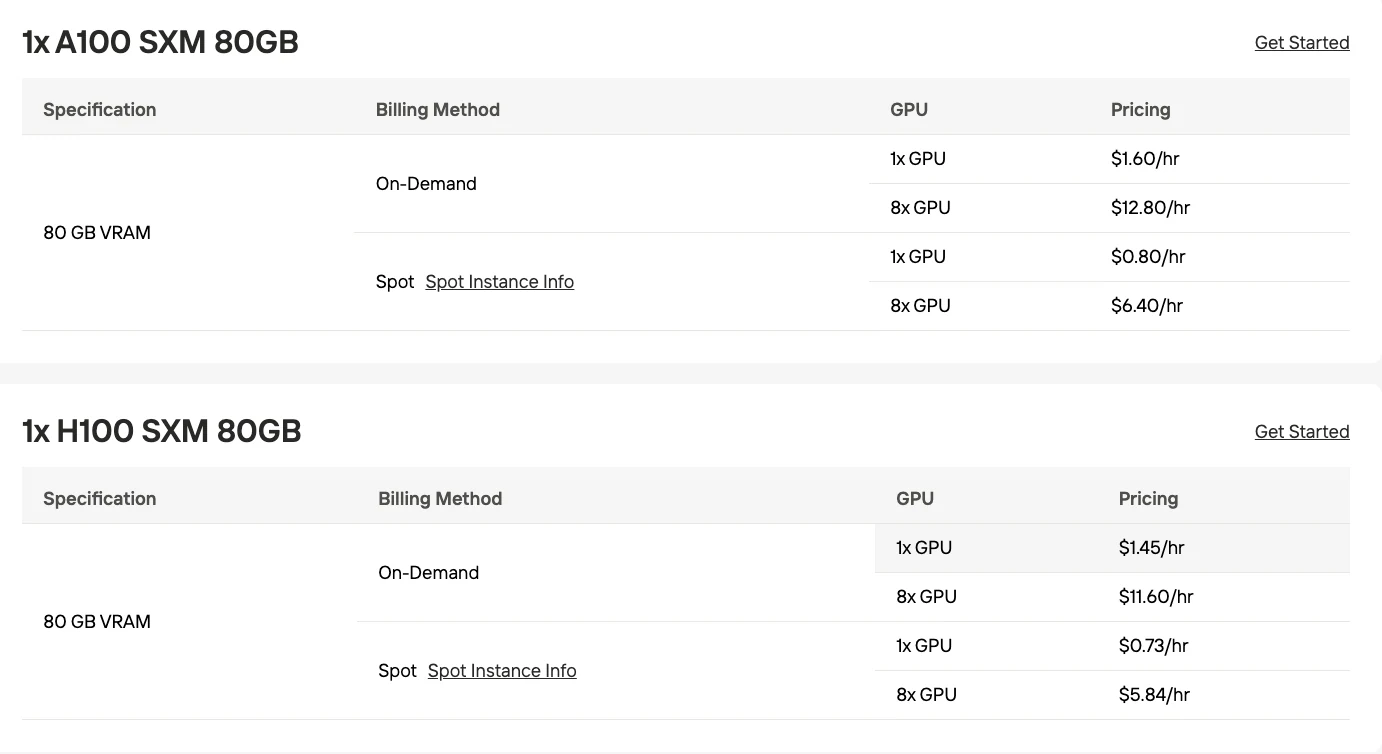
根據 Hacker News 的討論,MiniMax-M2.1 在 4-bit 量化下可於 2 張 RTX 6000 Pro GPU(總共 200GB VRAM) 上執行,支援約 400k 的上下文視窗,這相比全精度需求大幅降低。
使用 M2 的話,我曾在 Claude Code(例如原生工具呼叫)、Roo/Cline(例如自訂工具解析)等場景中使用過,表現相當優異,一度是自托管的最佳選擇。在 4-bit 量化下,它可容納於 2 張 RTX 6000 Pro(約 200GB VRAM)上,搭配 fp8 KV 快取可支援約 400k 上下文。由於活躍參數較低,執行速度非常快,長上下文表現穩定,在任何智能體框架中能力都相當出眾(這也是它的訓練特長)。M2.1 應該會比 M2 有明顯提升,後者相比甚至更小的模型都還有訓練不足的問題。
資料來源:Hacker News
4-bit 量化通常會將模型大小較 FP16 減少約 75%,與這些部署觀察結果一致:
- 模型權重:115GB(2287 億參數 × 0.5 位元組)
- 框架 + KV 快取:額外 85GB
- 總計:200GB VRAM
混合 CPU-GPU 卸載
對於使用消費級 GPU 的開發者來說,ktransformers 框架證明 M2.1 可透過將部分模型卸載至 CPU 記憶體,在 32GB VRAM(等同 RTX 5090)的硬體上執行。
這種混合方案以推理速度換取可及性:
- GPU VRAM:32GB(用於關鍵層與活躍計算)
- 系統記憶體:需要額外的大量 RAM(確切數量未指定)
- 效能取捨:相比全 GPU 部署,CPU 卸載會增加延遲
MiniMax-M2.1 部署的硬體建議
開發與實驗用途
若您正在構建原型或測試 M2.1 的能力,混合 CPU-GPU 方案是最容易入手的選擇:
| 組件 | 最低規格 | 推薦規格 |
|---|---|---|
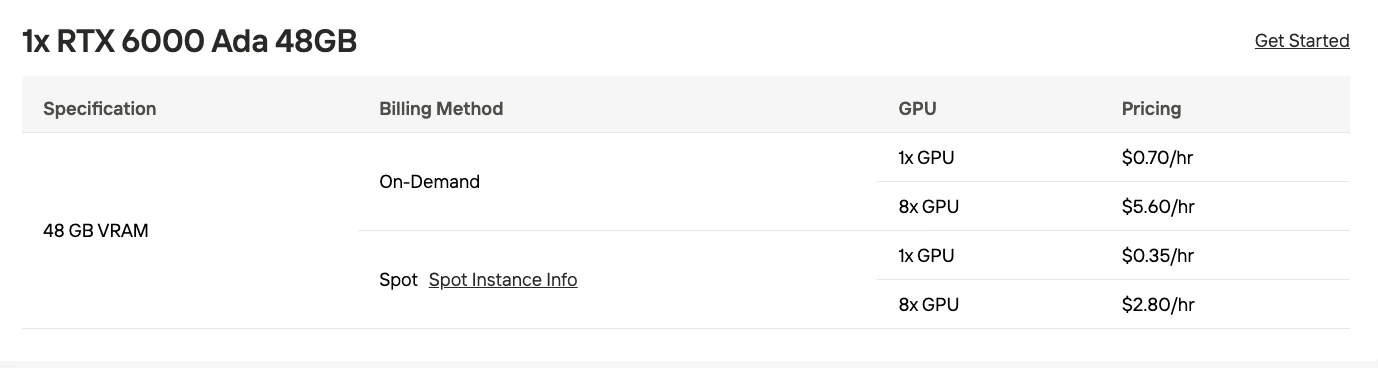
| GPU | 32GB VRAM(RTX 5090) | 48GB VRAM(RTX 6000 Ada) |
| 系統記憶體 | 128GB DDR4/DDR5 | 256GB DDR5 |
| 儲存空間 | 1TB NVMe SSD | 2TB NVMe SSD |
| 框架 | 搭配 CPU 卸載的 ktransformers |
預期效能:適合單使用者實驗與開發。推理速度會比全 GPU 部署慢,但足以測試智能體工作流程與程式碼生成任務。
生產環境部署
服務多個使用者或需要低延遲回應的生產環境,需要完整的 GPU 記憶體分配:
| 部署類型 | GPU 配置 | 總 VRAM | 使用場景 |
|---|---|---|---|
| 多 GPU(4-bit) | 2 張 RTX 6000 Pro(各 96GB) | 約 192GB | 中規模生產環境 |
| 資料中心 GPU | 4 張 H100(各 80GB) | 320GB | 高吞吐量生產環境 |
| 雲端替代方案 | API | 受管服務 | 無需基礎設施的生產環境 |
成本考量:2 張 RTX 6000 Pro 的配置對於需要本地部署但無資料中心規模基礎設施的組織來說,是務實的平衡選擇。對許多使用場景而言,API 的經濟效益可能比維護本地 GPU 基礎設施更好。
實務部署策略
策略 1:混合 CPU-GPU 卸載(消費級硬體)
ktransformers 框架透過將模型智慧分配至 GPU 與 CPU 記憶體,實現消費級 GPU 的部署:
# 部署範例(确切指令請參考 ktransformers 官方文件)
# 需求:32GB 以上 VRAM 的 GPU、128GB 以上系統記憶體
# 框架會根據可用資源自動分配
# GPU 與 CPU 記憶體之間的圖層
優點:
- 搭配高端消費級 GPU(RTX 5090、RTX 6000 Ada)即可使用
- 前期硬體投資成本較低
- 適合開發與低量產場景
缺點:
- 因 CPU-GPU 資料傳輸導致推理速度較慢
- 需要大量系統記憶體(128GB 以上)
- 不適合高併發的生產工作負載
策略 2:多 GPU 量化部署
步驟 1:註冊帳號
透過我們的官方網站建立 Novita AI 帳號。註冊完成後,前往左側邊欄的「探索」板塊,即可查看我們的 GPU 產品,開啟您的 AI 開發之旅。

步驟 2:瀏覽模板與 GPU 伺服器
根據您的專案需求選擇對應模板,例如 PyTorch、TensorFlow 或 CUDA。接著選擇您偏好的 GPU 配置,可選方案包含強大的 L40S、RTX 4090 或 A100 SXM4,各搭載不同的 VRAM、RAM 與儲存規格。
步驟 3:客製化您的部署
選擇您偏好的作業系統與配置選項,客製化您的環境,確保您的特定 AI 工作負載與開發需求能獲得最佳效能。
步驟 4:啟動實例
點選「啟動實例」即可開始部署。您的高效能 GPU 環境將在數分鐘內就緒,讓您可以立即著手進行機器學習、渲染或計算專案。
優點:
- 無 CPU 瓶頸,享有完整 GPU 效能
- 可處理多個並行請求
- 支援擴展上下文視窗(約 400k tokens)
缺點:
- 需要企業級 GPU 硬體投資
- 量化會造成輕微的品質下降(4-bit 通常影響極小)
- 需要多 GPU 張量並行配置的專業知識
策略 3:受管 API 服務
選擇 API 的時機:
- 使用模式變動大或難以預測
- 希望避免 GPU 基礎設施管理負擔
- 需要立即存取,無需等待硬體採購流程
- 在投入本地部署前進行原型開發
選擇本地部署的時機:
- 高量且穩定的使用場景,單一 token 成本會累積可觀費用
- 資料隱私或合規要求禁止使用外部 API
- 需要完全掌控模型行為與版本
- 正在開發自訂微調版本
給開發者的核心洞察:本地部署 M2.1 是可實現的,但需要策略性的硬體選擇。雖然全精度部署需要 400-500GB 的 VRAM(屬於企業資料中心級別),但仍有實務替代方案:4-bit 量化可實現於 2 張 RTX 6000 Pro GPU(總共約 200GB)上,而混合 CPU-GPU 策略甚至可從 32GB VRAM 的消費級 GPU 開始運行。
對大多數開發者與組織而言,決策樹非常明確:
- 實驗與開發:採用 RTX 5090/6000 Ada + 128GB 以上 RAM 的混合 CPU-GPU 方案
- 生產環境部署(自托管):多 GPU 量化配置(至少 2 張 RTX 6000 Pro)
- 生產環境部署(受管):使用 API 以實現營運簡化與成本可預測性
常見問題
MiniMax-M2.1 本地部署需要多少 VRAM? FP16 格式估算需要 450–500GB VRAM,而實務部署通常使用 4-bit 量化(200GB) 或 CPU-GPU 混合部署(32GB VRAM + 大容量系統 RAM)。
我可以在 RTX 4090 或 RTX 5090 等消費級 GPU 上執行 MiniMax-M2.1 嗎? 可以,但通常需要搭配 CPU 卸載 與 128GB 以上系統 RAM,以速度換取執行可行性。
M2 與 M2.1 的 VRAM 需求差異為何? 官方未提供相關比較,但兩者參數量級相近,推測 VRAM 需求大致相當。
Novita AI 是能實現您 AI 抱負的一站式雲端平台。整合 API、無伺服器架構、GPU 實例——都是您需要的高性價比工具。免除基礎設施煩惱,免費開始使用,讓您的 AI 願景成為現實。
推薦閱讀
Kimi K2 Thinking VRAM 限制解析:適合成本受限的開發者



