

Large language models have always faced a fundamental trade-off: more parameters mean better performance, but also higher costs and slower inference. Qwen3-Next-80B-A3B breaks this rule entirely.
With 80 billion total parameters but only 3 billion active during inference, this ultra-sparse MoE model outperforms Qwen3-32B while using less than 1/10th the training resources. Its revolutionary architecture—featuring Hybrid Attention, 1:50 MoE sparsity, and Multi-Token Prediction—delivers over 10x faster inference on long contexts.
Novita AI now offers two variants from the Qwen3-Next series:
- qwen/qwen3-next-80b-a3b-instruct: $0.15/million input tokens, $1.5/million output tokens
- qwen/qwen3-next-80b-a3b-thinking:$0.15/million input tokens, $1.5/million output tokens
Both models are ready to use through Novita AI’s platform, whether you’re experimenting in the playground or integrating via API—no infrastructure setup required.
The Qwen3-Next Series
The Qwen3-Next series represents next-generation foundation models, optimized for extreme context length and large-scale parameter efficiency. This groundbreaking series introduces architectural innovations designed to maximize performance while minimizing computational cost:
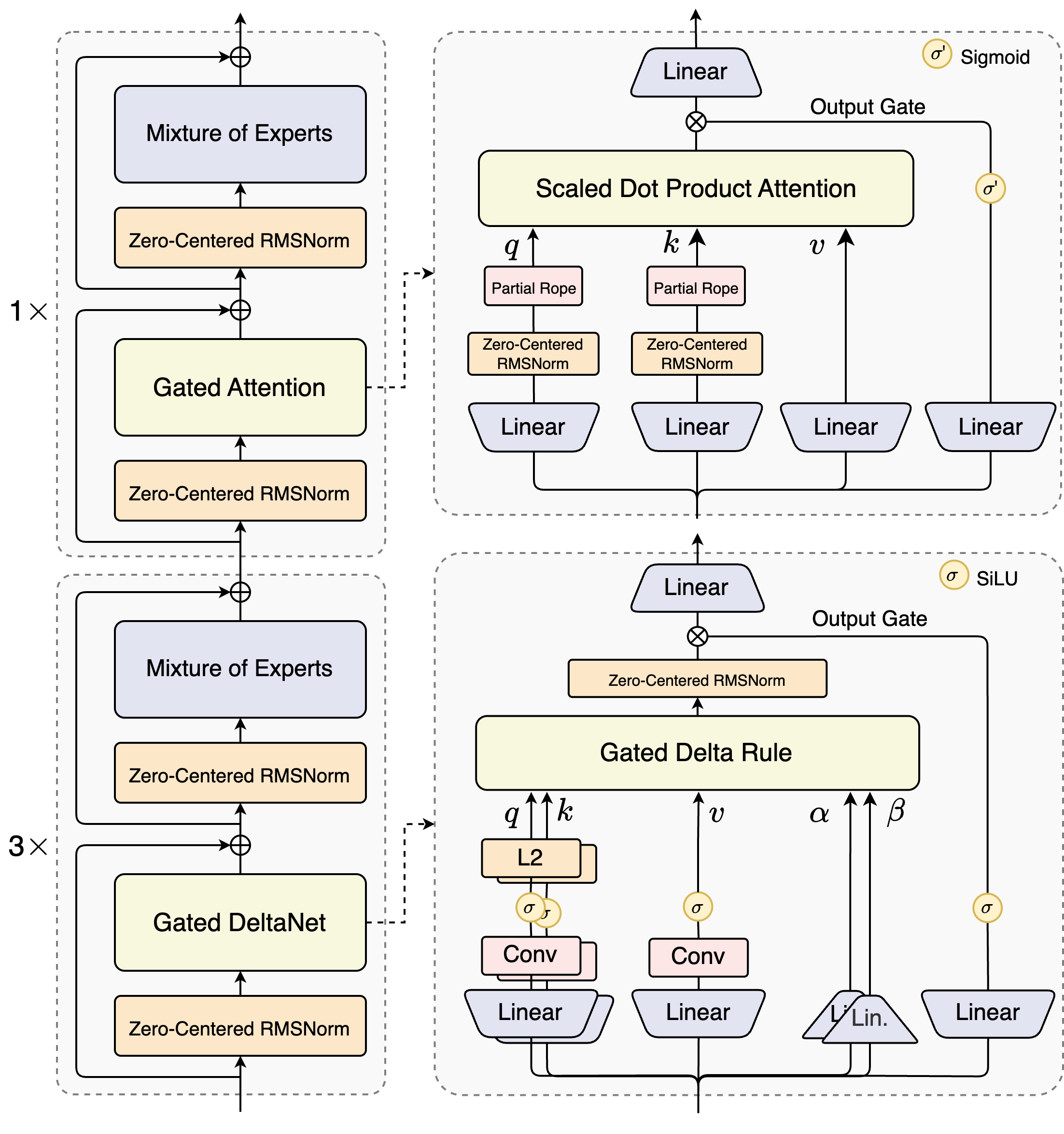
Source from: Official Qwen3-Next Blog
- Hybrid Attention: Replaces standard attention with the combination of Gated DeltaNet and Gated Attention, enabling efficient context modeling.
- High-Sparsity MoE: Achieves an extreme low activation ratio of 1:50 in MoE layers — drastically reducing FLOPs per token while preserving model capacity.
- Multi-Token Prediction (MTP): Boosts pretraining model performance and accelerates inference.
- Other Optimizations: Includes techniques such as zero-centered and weight-decayed layernorm, Gated Attention, and other stabilizing enhancements for robust training.
Built on this architecture, Qwen3-Next-80B-A3B features 80B total parameters with only 3B active — achieving extreme sparsity and efficiency.
Despite its ultra-efficiency, it outperforms Qwen3-32B on downstream tasks while requiring less than 1/10 of the training cost. Moreover, it delivers over 10x higher inference throughput than Qwen3-32B when handling contexts longer than 32K tokens.
Performance Benchmarks of Qwen3-Next-80B-A3B
Instruct Model Performance
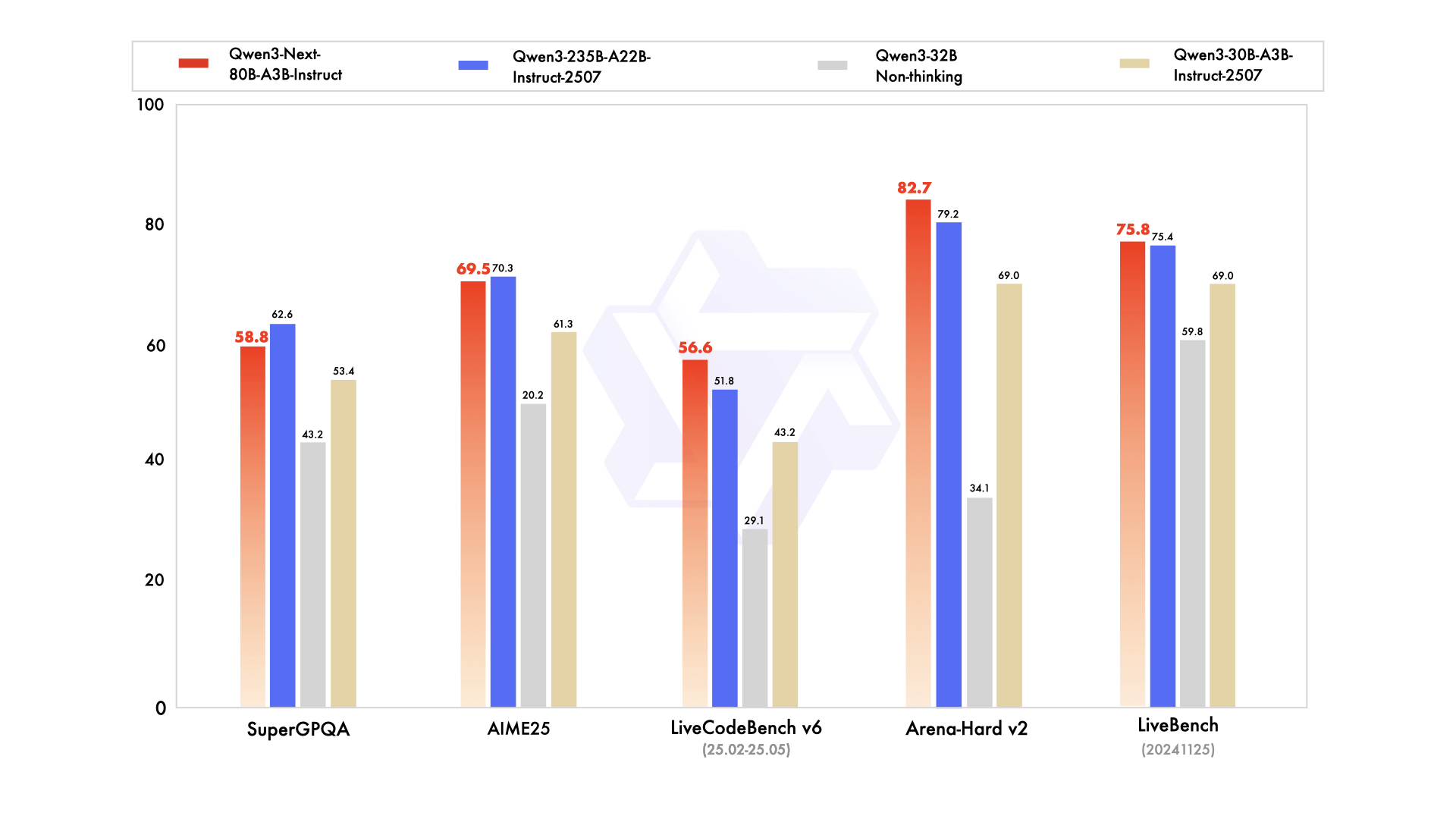
Source from: Official Qwen3-Next Blog
Thinking Model Performance
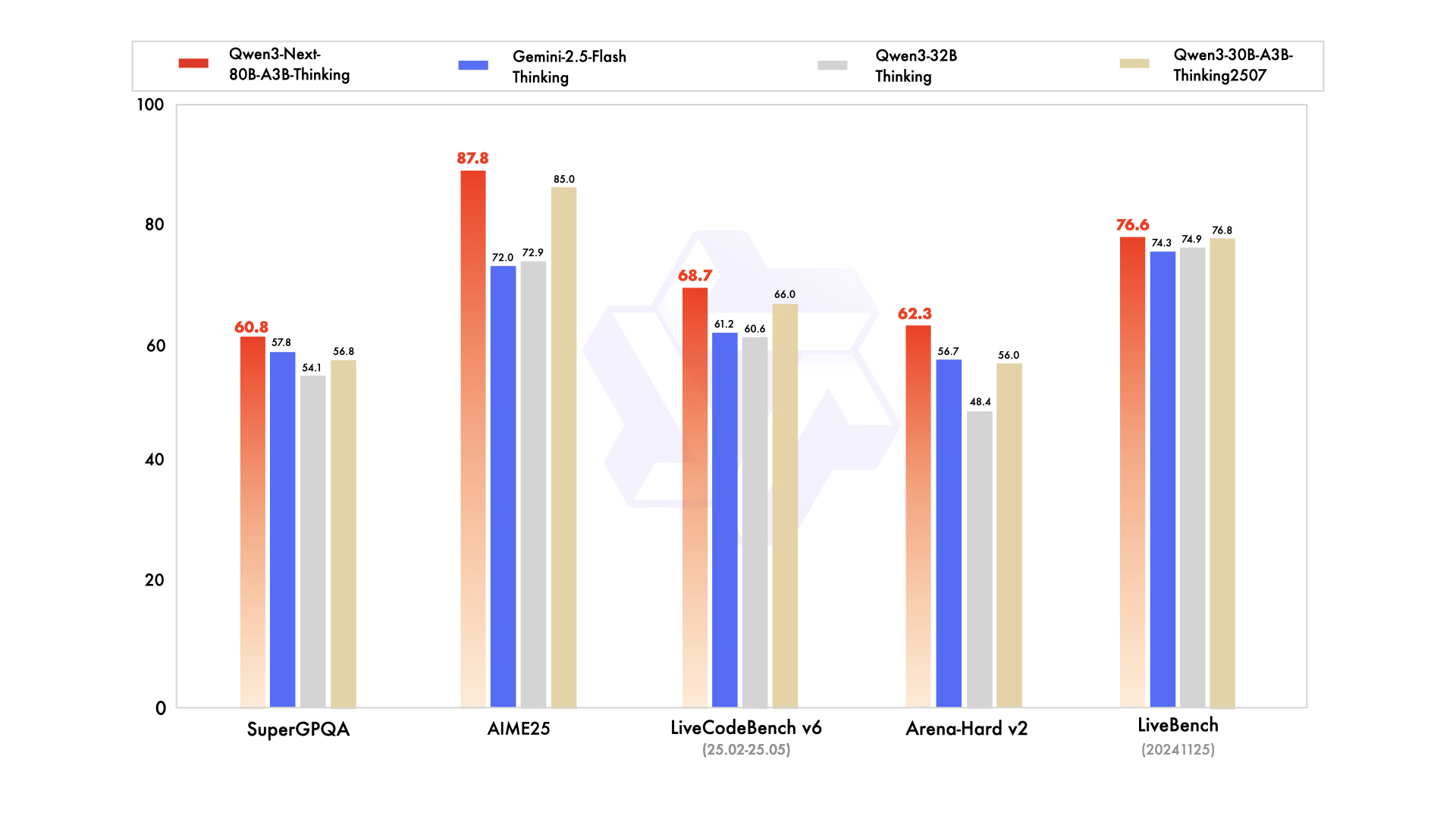
Source from: Official Qwen3-Next Blog
How to Access Qwen3-Next-80B-A3B on Novita AI
Access the revolutionary Qwen3-Next-80B-A3B model through Novita AI’s infrastructure—leveraging extreme sparsity for unprecedented efficiency. Novita AI’s platform eliminates deployment complexity while delivering this next-generation architecture’s full potential.
Use the Playground (No Coding Required)
Instant Access: Sign up and start experimenting with Qwen3-Next-80B-A3B in seconds through Novita AI’s web interface—no infrastructure setup required.
Interactive Testing: Experience the model’s Hybrid Attention mechanism and Multi-Token Prediction capabilities through Novita AI’s intuitive playground interface.
Key Configuration Options:
- max_tokens: Test Qwen3-Next’s exceptional long-context capabilities
- temperature & top_p: Fine-tune creativity and response diversity
- System Prompt: Customize model behavior instantly
- Function Calling: Test tool integration directly in playground
Model Comparison: Switch between Qwen3-Next-80B-A3B-Instruct and Thinking variants, or compare against other models available on Novita AI to evaluate performance for your use cases.
Integrate via API (For Developers)
Connect Qwen3-Next-80B-A3B to your applications through Novita AI’s REST API—benefiting from the model’s 10x inference throughput on long contexts without managing infrastructure.
Option 1: Direct API Integration (Python Example)
Access Qwen3-Next’s efficient architecture through Novita AI’s OpenAI-compatible endpoint:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)Platform Features:
- OpenAI-compatible endpoint:
/v3/openaifor seamless integration - Flexible parameters: Control generation with temperature, top-p, penalties, and more
- Streaming support: Choose between streaming or batch responses
- Model selection: Access both instruct and thinking variants
Option 2: Multi-Agent Workflows with OpenAI Agents SDK
Build agent systems that leverage Qwen3-Next’s efficiency through Novita AI’s infrastructure:
- OpenAI Agents SDK compatibility: Use the OpenAI Agents SDK with Novita’s endpoint for agent workflows
- Agent capabilities: Design systems that benefit from extreme sparsity and long-context performance
- Simple integration: Point the SDK to
https://api.novita.ai/v3/openai
Third-Party Integrations
- Framework Integration: Access Qwen3-Next-80B-A3B through LangChain, Dify, and Langflow
- Development Tools: Compatible with OpenAI-standard tools including Trae, Claude Code, Qwen Code, Cline, and Cursor
- Hugging Face Ecosystem: Integrate in Spaces and pipelines via Novita AI’s API
Conclusion
Qwen3-Next-80B-A3B represents more than just another efficient model—it demonstrates that architectural innovation can deliver enterprise-scale capabilities without enterprise-scale costs.
Available now on Novita AI, both the instruct and thinking variants are ready for immediate use. Access 80 billion parameters of intelligence with the speed and cost of a 3 billion parameter model through Novita AI’s playground, API, or third-party integrations.
Experience the future of efficient AI today with Qwen3-Next-80B-A3B on Novita AI.
Novita AI is a leading AI cloud platform that provides developers with easy-to-use APIs and affordable, reliable GPU infrastructure for building and scaling AI applications.



