

واجهت نماذج اللغة الكبيرة دائمًا مفاضلة أساسية: المزيد من المعاملات يعني أداء أفضل، ولكن أيضًا تكاليف أعلى واستدلال أبطأ. يحطم نموذج Qwen3-Next-80B-A3B هذه القاعدة بالكامل.
بمعاملات إجمالية تبلغ 80 مليار ولكن مع 3 مليار فقط نشطة أثناء الاستدلال، يتفوق نموذج MoE فائق التفرق هذا على نموذج Qwen3-32B بينما يستخدم أقل من 1/10 من موارد التدريب. توفر بنيته الثورية - التي تتضمن انتباهًا هجينًا، وتفرق MoE بنسبة 1:50، وتنبؤًا متعدد الرموز - استدلالًا أسرع بأكثر من 10 أضعاف في السياقات الطويلة.
تقدم نوفيتا AI الآن متغيرين من سلسلة Qwen3-Next:
- qwen/qwen3-next-80b-a3b-instruct: 0.15 دولار لكل مليون رمز إدخال، 1.5 دولار لكل مليون رمز إخراج
- qwen/qwen3-next-80b-a3b-thinking: 0.15 دولار لكل مليون رمز إدخال، 1.5 دولار لكل مليون رمز إخراج
كلا النموذجين جاهزان للاستخدام عبر منصة نوفيتا AI، سواء كنت تجرب في مساحة التجربة أو تدمج عبر واجهة برمجة التطبيقات (API) - لا يلزم إعداد بنية تحتية.
سلسلة Qwen3-Next
تمثل سلسلة Qwen3-Next نماذج أساسية من الجيل التالي، محسّنة لطول سياق متطرد وكفاءة معاملات على نطاق واسع. تقدم هذه السلسلة الرائدة ابتكارات معمارية مصممة لتعظيم الأداء مع تقليل التكلفة الحسابية:
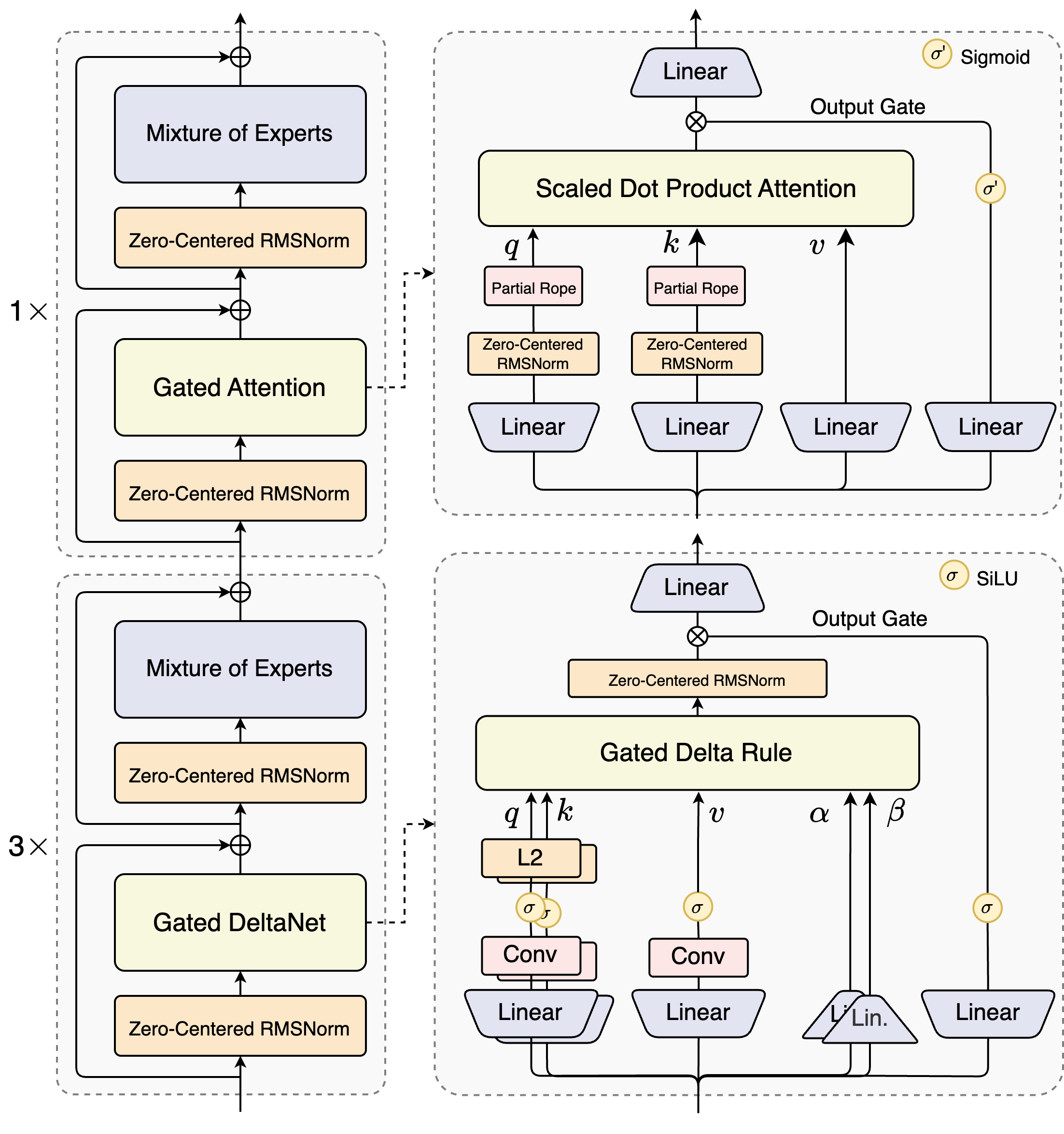
المصدر: مدونة Qwen3-Next الرسمية
- الانتباه الهجين: يحل محل الانتباه القياسي من خلال الجمع بين Gated DeltaNet و Gated Attention، مما يتيح نمذجة سياق فعالة.
- MoE عالي التفرق: يحقق نسبة تنشيط منخفضة للغاية تبلغ 1:50 في طبقات MoE - مما يقلل بشكل كبير من عدد العمليات الحسابية (FLOPs) لكل رمز مع الحفاظ على سعة النموذج.
- التنبؤ متعدد الرموز (MTP): يعزز أداء النموذج في مرحلة ما قبل التدريب ويُسرع عملية الاستدلال.
- تحسينات أخرى: تتضمن تقنيات مثل Layernorm المتمركز حول الصفر والمُخفَّف بالوزن، و Gated Attention، وتحسينات استقرار أخرى لتدريب قوي.
مبني على هذه البنية، يتميز نموذج Qwen3-Next-80B-A3B بـ 80 مليار معامل إجمالي مع 3 مليار فقط نشطة - مما يحقق تفرقًا وكفاءة متطرفين.
على الرغم من كفاءته الفائقة، فإنه يتفوق على نموذج Qwen3-32B في المهام اللاحقة بينما يتطلب أقل من 1/10 من تكلفة التدريب. علاوة على ذلك، يوفر معدل نقل استدلال أعلى بأكثر من 10 أضعاف من نموذج Qwen3-32B عند التعامل مع سياقات أطول من 32 ألف رمز.
معايير أداء Qwen3-Next-80B-A3B
أداء نموذج Instruct
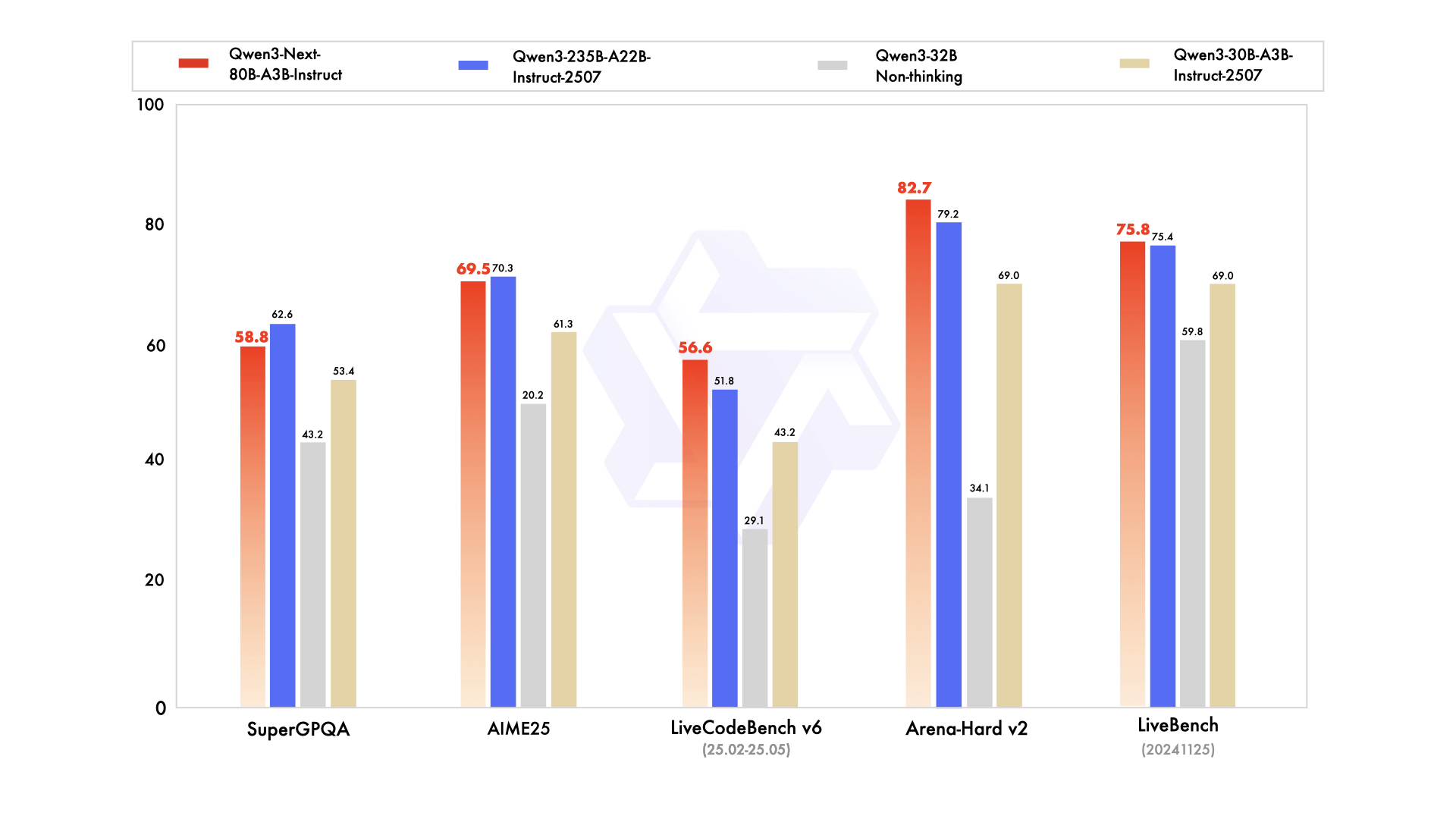
المصدر: مدونة Qwen3-Next الرسمية
أداء نموذج Thinking
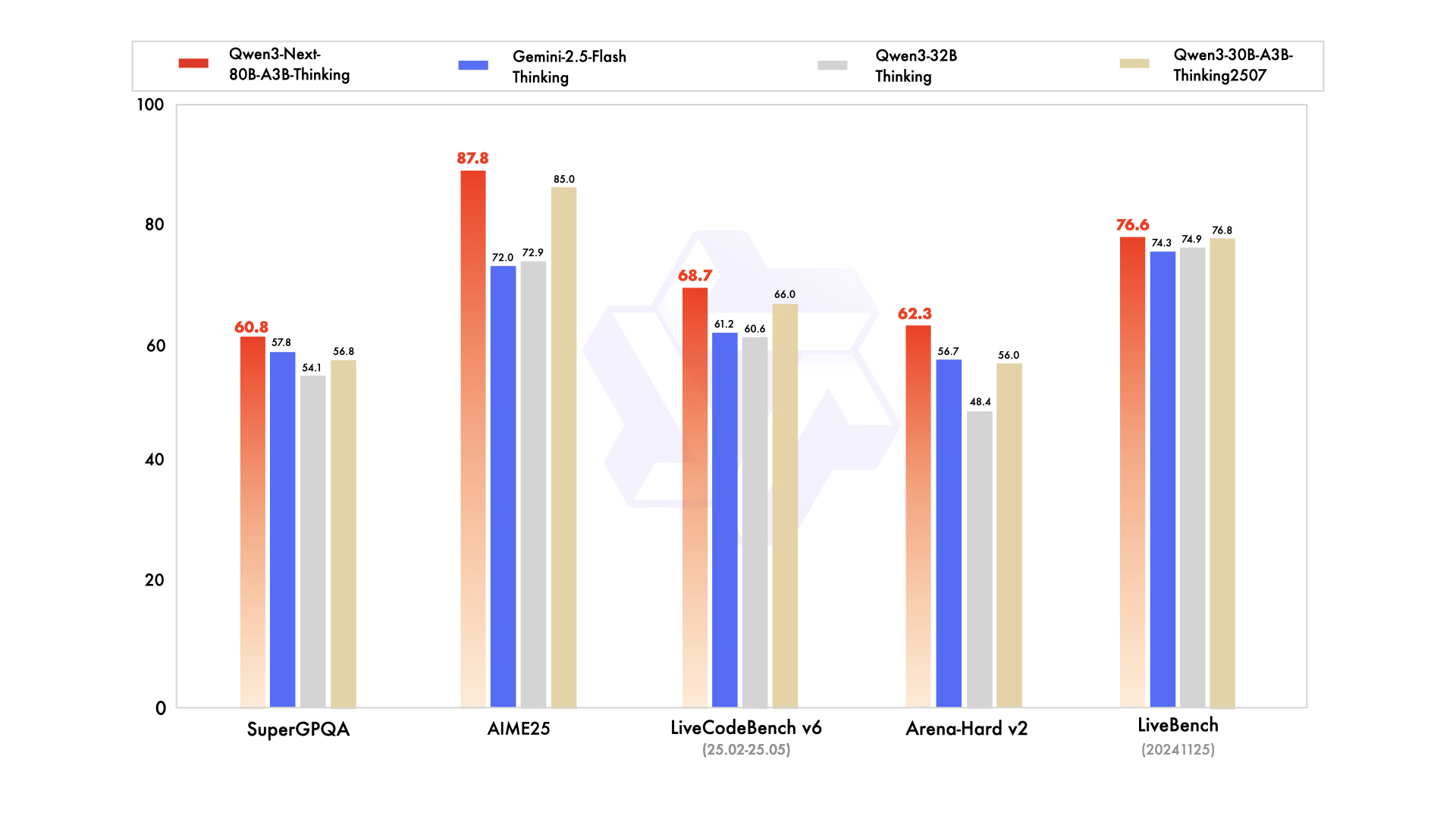
المصدر: مدونة Qwen3-Next الرسمية
كيفية الوصول إلى Qwen3-Next-80B-A3B على نوفيتا AI
يمكنك الوصول إلى نموذج Qwen3-Next-80B-A3B الثوري عبر بنية نوفيتا AI الأساسية - مستفيدًا من التفرق المتطرف لكفاءة غير مسبوقة. تلغي منصة نوفيتا AI تعقيدات النشر بينما تقدم الإمكانات الكاملة لهذه البنية من الجيل التالي.
استخدم مساحة التجربة (لا يتطلب برمجة)
- وصول فوري: سجّل وابدأ التجربة مع Qwen3-Next-80B-A3B في ثوانٍ عبر واجهة الويب الخاصة بنوفيتا AI - لا يلزم إعداد بنية تحتية.
- اختبار تفاعلي: جرب آلية الانتباه الهجين للنموذج وإمكانيات التنبؤ متعدد الرموز عبر واجهة مساحة التجربة البديهية الخاصة بنوفيتا AI.
- خيارات التكوين الرئيسية:
- max_tokens: اختبر إمكانيات السياق الطويل الاستثنائية لـ Qwen3-Next
- temperature و top_p: اضبط بدقة الإبداع وتنوع الاستجابات
- موجه النظام: خصص سلوك النموذج فورًا
- استدعاء الوظائف: اختبر تكامل الأدوات مباشرة في مساحة التجربة
- مقارنة النماذج: بدل بين متغيرات Qwen3-Next-80B-A3B-Instruct و Thinking، أو قارن مع نماذج أخرى متاحة على نوفيتا AI لتقييم الأداء لحالات الاستخدام الخاصة بك.
الدمج عبر واجهة برمجة التطبيقات (للمطورين)
اربط نموذج Qwen3-Next-80B-A3B بتطبيقاتك عبر واجهة برمجة التطبيقات REST الخاصة بنوفيتا AI - مستفيدًا من معدل نقل الاستدلال 10 أضعاف للنموذج في السياقات الطويلة دون إدارة بنية تحتية.
الخيار 1: تكامل مباشر عبر واجهة برمجة التطبيقات (مثال بلغة بايثون)
يمكنك الوصول إلى البنية الفعالة لـ Qwen3-Next عبر نقطة النهاية المتوافقة مع OpenAI الخاصة بنوفيتا AI:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
ميزات المنصة:
- نقطة نهاية متوافقة مع OpenAI:
/v3/openaiلتكامل سلس - معلمات مرنة: تحكم في التوليد باستخدام درجة الحرارة، وأعلى-p، والجزاءات، والمزيد
- دعم البث: اختر بين الاستجابات المتدفقة أو الدفعية
- اختيار النموذج: الوصول إلى كلا متغيرات instruct و thinking
الخيار 2: سير عمل متعدد الوكلاء باستخدام OpenAI Agents SDK
ابنِ أنظمة وكلاء تستفيد من كفاءة Qwen3-Next عبر بنية نوفيتا AI الأساسية:
- توافق مع OpenAI Agents SDK: استخدم OpenAI Agents SDK مع نقطة النهاية الخاصة بنوفيتا لسير عمل الوكلاء
- إمكانيات الوكلاء: صمم أنظمة تستفيد من التفرق المتطرف وأداء السياق الطويل
- تكامل بسيط: وجه الـ SDK إلى
https://api.novita.ai/v3/openai
تكاملات مع أطراف ثالثة
- تكامل مع الأطر: الوصول إلى Qwen3-Next-80B-A3B عبر LangChain، و Dify، و Langflow
- أدوات التطوير: متوافق مع أدوات معيار OpenAI بما في ذلك Trae، و Claude Code، و Qwen Code، و Cline، و Cursor
- نظام Hugging Face البيئي: دمج في المساحات (Spaces) والأنابيب (pipelines) عبر واجهة برمجة التطبيقات الخاصة بنوفيتا AI
الخاتمة
لا يمثل نموذج Qwen3-Next-80B-A3B مجرد نموذج فعال آخر - بل يثبت أن الابتكار المعماري يمكن أن يوفر إمكانيات على نطاق المؤسسات دون تكاليف على نطاق المؤسسات.
متاح الآن على نوفيتا AI، كلا متغيري instruct و thinking جاهزان للاستخدام الفوري. يمكنك الوصول إلى 80 مليار معامل من الذكاء بسرعة وتكلفة نموذج 3 مليار معامل عبر مساحة التجربة أو واجهة برمجة التطبيقات أو التكاملات مع أطراف ثالثة الخاصة بنوفيتا AI.
جرب مستقبل الذكاء الاصطناعي الفعال اليوم مع Qwen3-Next-80B-A3B على نوفيتا AI.
نوفيتا AI هي منصة سحابة ذكاء اصطناعي رائدة توفر للمطورين واجهات برمجة تطبيقات سهلة الاستخدام وبنية تحتية لـ GPU موثوقة وبأسعار معقولة لبناء وتوسيع نطاق تطبيقات الذكاء الاصطناعي.



