

大型語言模型長期面臨一個根本取捨:參數越多表現越好,但成本也越高、推論速度越慢。Qwen3-Next-80B-A3B 完全打破了這項限制。
這款超高稀疏度 MoE 模型總共擁有 800 億參數,推理時僅啟用 30 億活躍參數,表現優於 Qwen3-32B,且訓練資源消耗不到後者的 1/10。其革命性架構結合了混合注意力機制(Hybrid Attention)、1:50 的 MoE 稀疏度以及多標記預測(Multi-Token Prediction),在長上下文場景下的推論速度提升超過 10 倍。
Novita AI 現已上線 Qwen3-Next 系列的兩個版本:
- qwen/qwen3-next-80b-a3b-instruct:每百萬輸入 token 0.15 美元,每百萬輸出 token 1.5 美元
- qwen/qwen3-next-80b-a3b-thinking:每百萬輸入 token 0.15 美元,每百萬輸出 token 1.5 美元
兩個模型都可以透過 Novita AI 平台直接使用,無論是在 playground 中進行實驗,還是透過 API 整合,都无需額外部署基礎設施。
Qwen3-Next 系列
Qwen3-Next 系列是次世代基礎模型,針對極長上下文與大規模參數效率進行優化。這個開創性的系列引入了多項架構創新,旨在最大化性能的同時最小化運算成本:
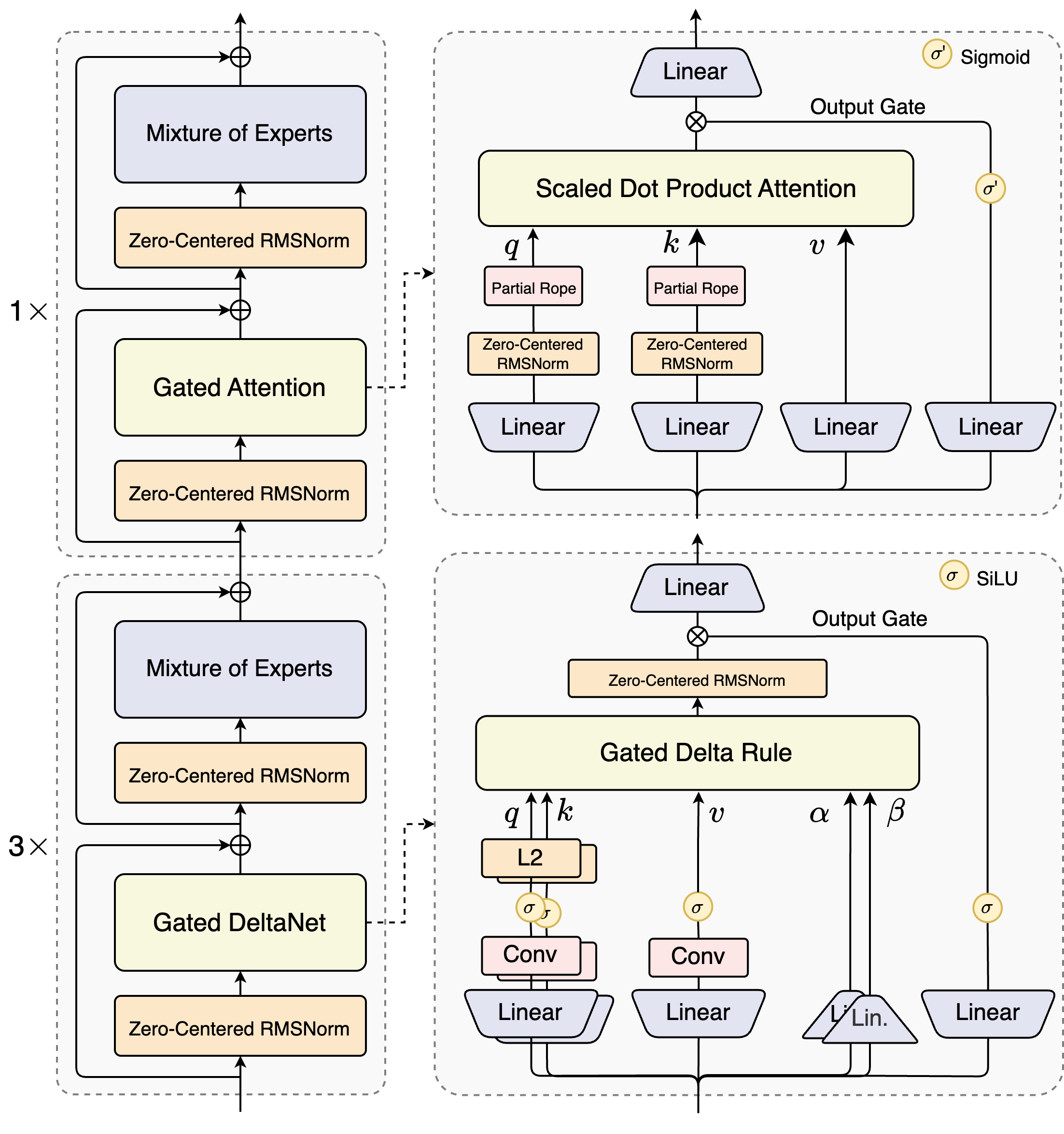
- 混合注意力機制(Hybrid Attention):以**門控 DeltaNet(Gated DeltaNet)與門控注意力(Gated Attention)**的組合取代標準注意力機制,實現高效的上下文建模。
- 超高稀疏度 MoE:在 MoE 層中實現 1:50 的極低啟動比例,在保留模型容量的同時大幅降低每個 token 的運算量(FLOPs)。
- 多標記預測(Multi-Token Prediction, MTP):提升預訓練模型性能,同時加速推論速度。
- 其他優化:包含零中心化且帶權重衰減的層歸一化(zero-centered and weight-decayed layernorm)、門控注意力等穩定性增強技術,確保訓練穩定性。
基於此架構,Qwen3-Next-80B-A3B 總共擁有 800 億參數,僅有 30 億處於活躍狀態,實現了極致的稀疏度與效率。
儘管效率極高,它在下游任務中的表現仍優於 Qwen3-32B,且訓練成本不到後者的 1/10。此外,在處理超過 32K token 的長上下文時,其推論吞吐量比 Qwen3-32B 高出 10 倍以上。
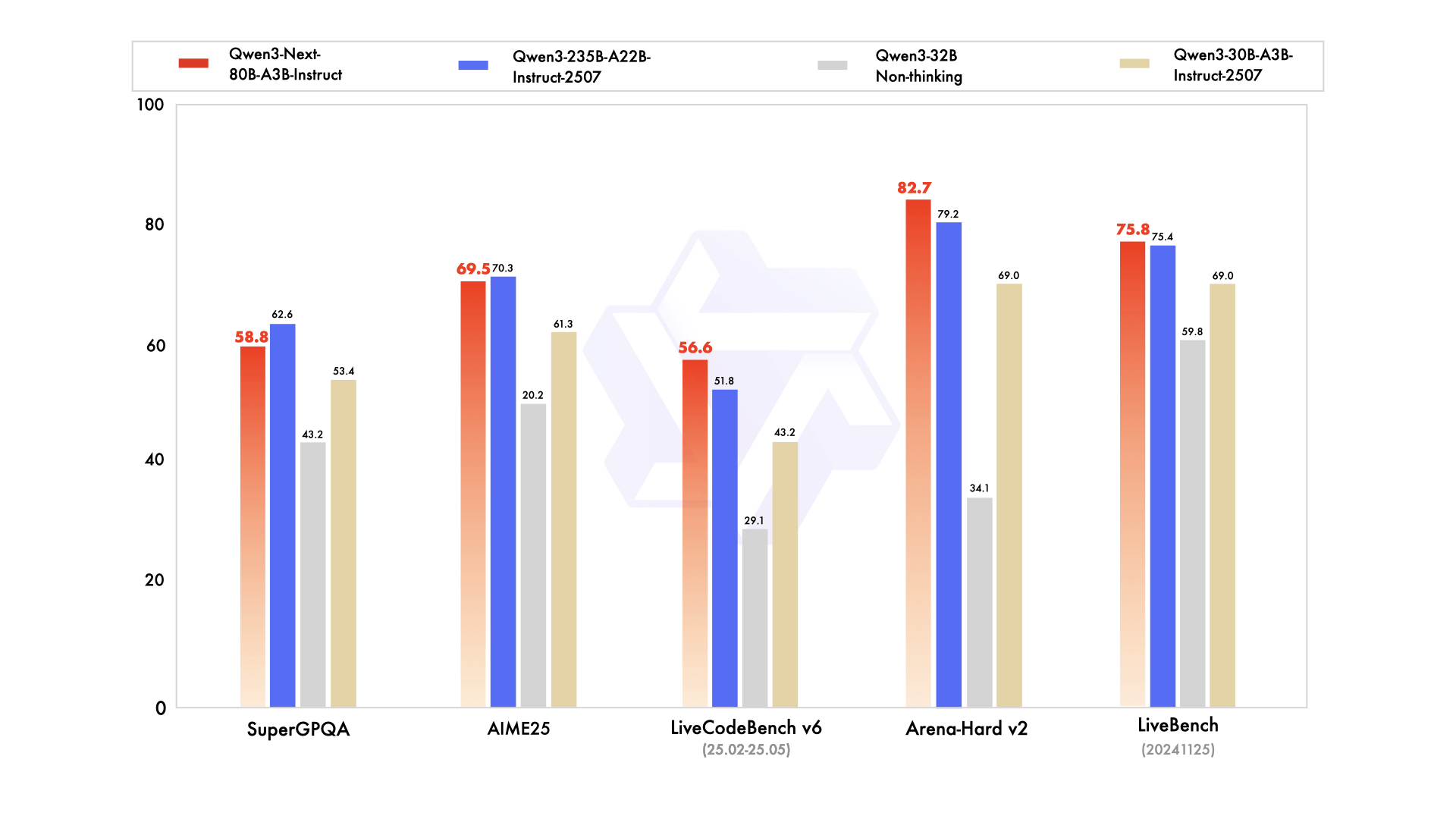
Qwen3-Next-80B-A3B 性能基準測試
Instruct 版本性能
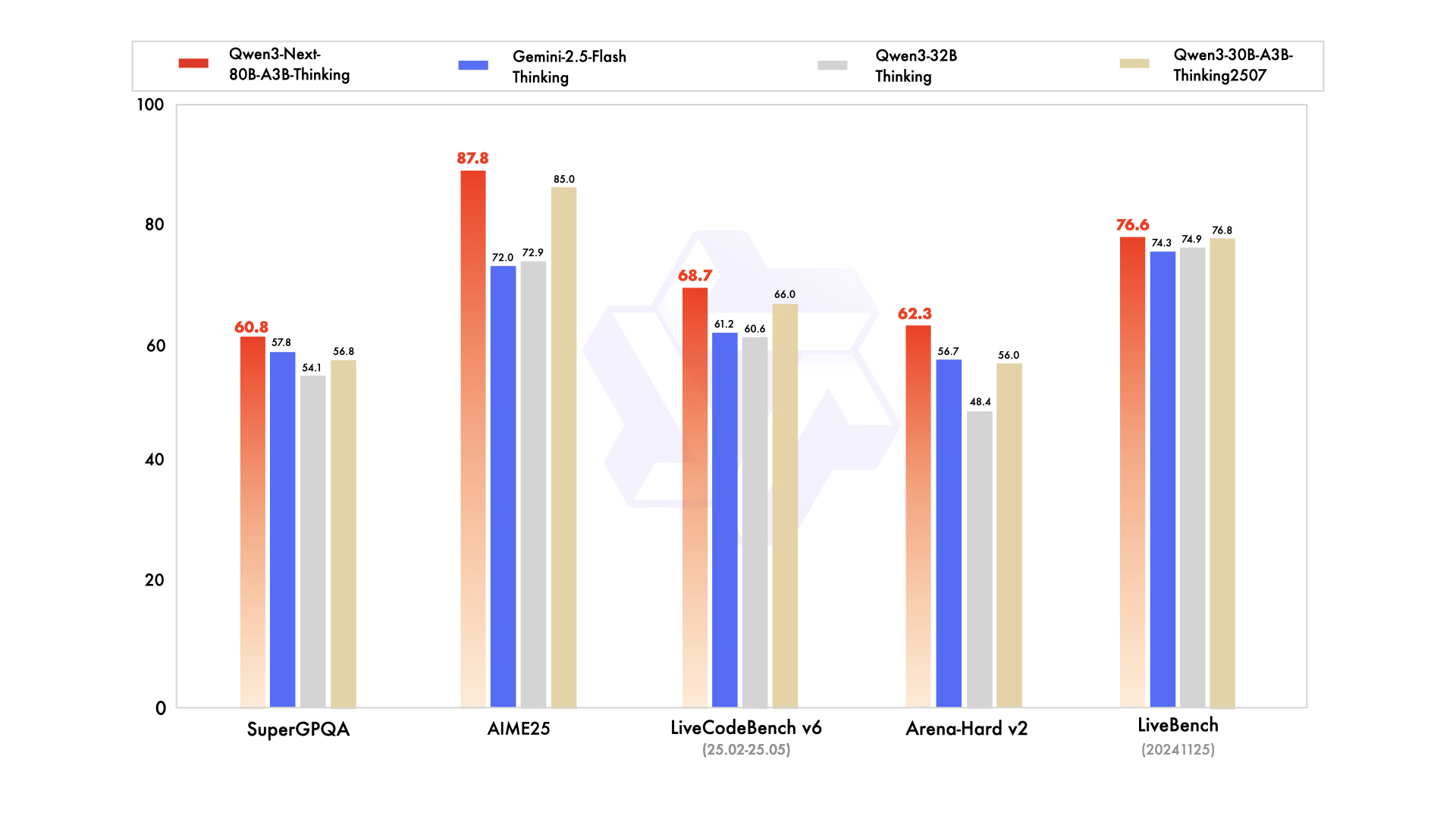
Thinking 版本性能
如何在 Novita AI 上使用 Qwen3-Next-80B-A3B
透過 Novita AI 的基礎設施使用這款革命性的 Qwen3-Next-80B-A3B 模型,充分利用其極致稀疏度帶來的超高效能。Novita AI 平台消除了部署複雜度,可充分發揮這款次世代架構的全部潛力。
使用 Playground(无需編程)
即刻使用:註冊後即可透過 Novita AI 網頁介面在幾秒內開始體驗 Qwen3-Next-80B-A3B,无需額外部署基礎設施。
互動測試:透過 Novita AI 直觀的 playground 介面,體驗模型的混合注意力機制與多標記預測能力。
關鍵配置選項:
- max_tokens:測試 Qwen3-Next 優異的長上下文能力
- temperature & top_p:微調創造力與回應的多樣性
- System Prompt:即時自定義模型行為
- Function Calling:直接在 playground 中測試工具整合能力
模型對比:切換 Qwen3-Next-80B-A3B 的 Instruct 與 Thinking 版本,或與 Novita AI 上的其他模型進行對比,評估其對您使用場景的性能表現。
透過 API 整合(開發者適用)
透過 Novita AI 的 REST API 將 Qwen3-Next-80B-A3B 連接至您的應用程式,無需管理基礎設施即可享受模型在長上下文場景下 10 倍推論吞吐量的優勢。
選項 1:直接 API 整合(Python 範例)
透過 Novita AI 相容 OpenAI 的端點使用 Qwen3-Next 的高效架構:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
平台特性:
- 相容 OpenAI 的端點:
/v3/openai實現無縫整合 - 彈性參數:透過 temperature、top-p、懲罰係數等參數控制生成結果
- 串流支援:可選擇串流或批次回應
- 模型選擇:支援存取 Instruct 與 Thinking 兩個版本
選項 2:使用 OpenAI Agents SDK 構建多代理工作流
透過 Novita AI 的基礎設施構建能發揮 Qwen3-Next 效率的代理系統:
- 相容 OpenAI Agents SDK:可搭配 Novita 的端點使用 OpenAI Agents SDK 構建代理工作流
- 代理能力:可設計能受益於極致稀疏度與長上下文性能的系統
- 簡單整合:將 SDK 指向
https://api.novita.ai/v3/openai即可
第三方整合
- 框架整合:可透過 LangChain、Dify 和 Langflow 使用 Qwen3-Next-80B-A3B
- 開發工具:相容 OpenAI 標準工具,包含 Trae、Claude Code、Qwen Code、Cline 和 Cursor
- Hugging Face 生態系:可透過 Novita AI 的 API 在 Hugging Face Spaces 和流水線中整合
總結
Qwen3-Next-80B-A3B 不僅是一款高效模型,更證明了架構創新可以實現企業級能力,卻无需企業級的成本。
两款模型現已於 Novita AI 上線,Instruct 版本與Thinking 版本均可立即使用。透過 Novita AI 的 playground、API 或第三方整合,即可以 30 億參數模型的速度與成本,使用 800 億參數的智能能力。
立即透過 Novita AI 體驗 Qwen3-Next-80B-A3B,感受高效 AI 的未來。
Novita AI 是領先的 AI 雲端平台,為開發者提供易於使用的 API 與高性價比、可靠的 GPU 基礎設施,協助構建與擴展 AI 應用程式。



