

Große Sprachmodelle standen immer vor einem grundlegenden Kompromiss: Mehr Parameter bedeuten bessere Leistung, aber auch höhere Kosten und langsamere Inferenz. Qwen3-Next-80B-A3B durchbricht diese Regel vollständig.
Mit insgesamt 80 Milliarden Parametern, von denen nur 3 Milliarden während der Inferenz aktiv sind, übertrifft dieses ultra-gesparste MoE-Modell das Qwen3-32B und benötigt dabei weniger als 1/10 der Trainingsressourcen. Seine revolutionäre Architektur – mit Hybrid Attention, 1:50 MoE-Sparsität und Multi-Token-Vorhersage – liefert eine mehr als 10-fach schnellere Inferenz bei langen Kontexten.
Novita AI bietet nun zwei Varianten der Qwen3-Next-Serie an:
- qwen/qwen3-next-80b-a3b-instruct: $0,15 pro Million Eingabetoken, $1,5 pro Million Ausgabetoken
- qwen/qwen3-next-80b-a3b-thinking: $0,15 pro Million Eingabetoken, $1,5 pro Million Ausgabetoken
Beide Modelle sind über die Plattform von Novita AI sofort einsatzbereit, egal ob Sie im Playground experimentieren oder sie über eine API integrieren – keine Einrichtung von Infrastruktur erforderlich.
Die Qwen3-Next-Serie
Die Qwen3-Next-Serie repräsentiert Next-Generation-Basismodelle, die für extreme Kontextlängen und großskalige Parameter-Effizienz optimiert sind. Diese bahnbrechende Serie führt architektonische Innovationen ein, die darauf ausgelegt sind, die Leistung zu maximieren und gleichzeitig die Rechenkosten zu minimieren:
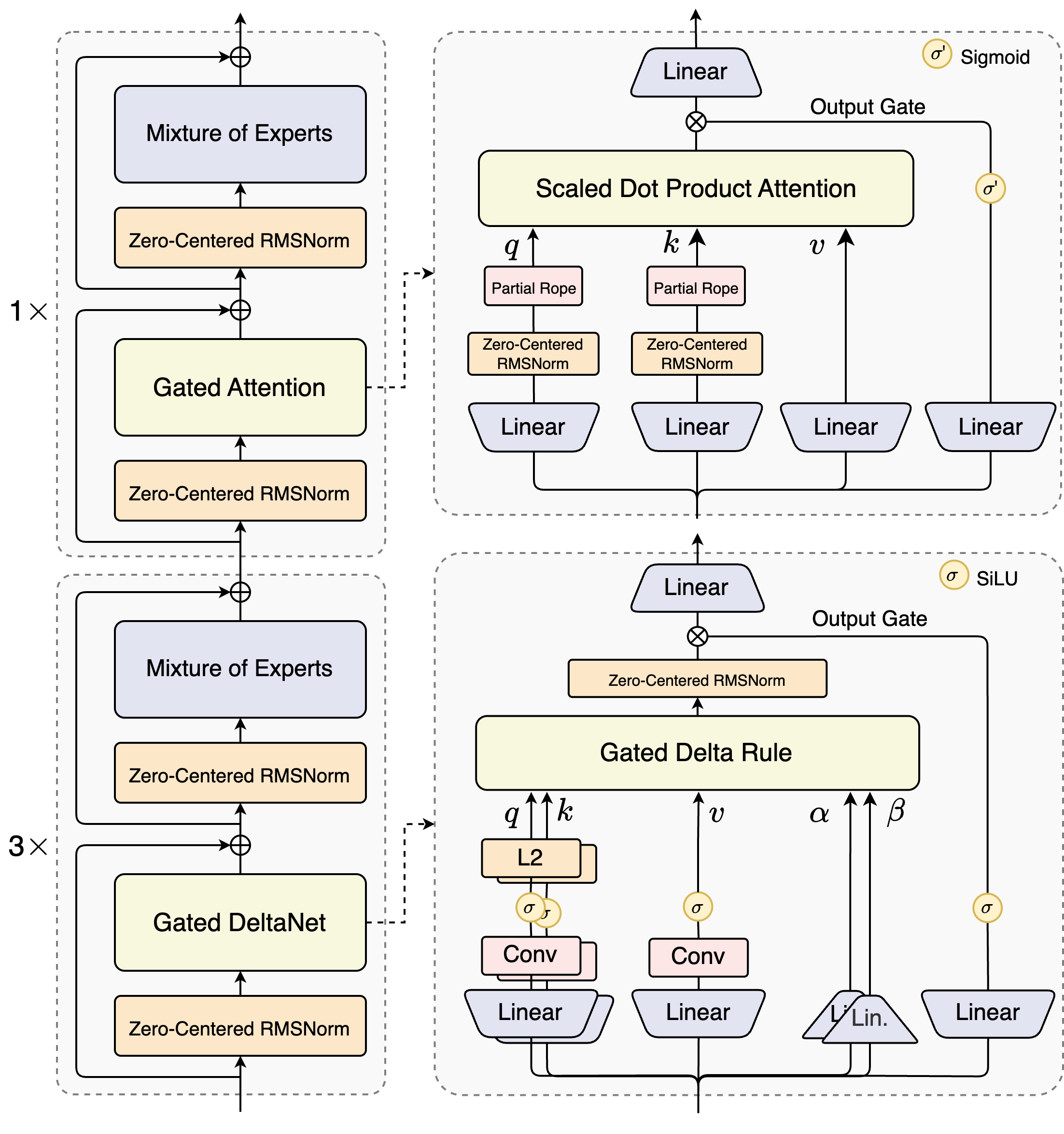
Quelle: Offizielles Qwen3-Next-Blog
- Hybrid Attention: Ersetzt die Standard-Attention durch die Kombination aus Gated DeltaNet und Gated Attention und ermöglicht eine effiziente Kontextmodellierung.
- Hohe MoE-Sparsität: Erreicht ein extrem niedriges Aktivierungsverhältnis von 1:50 in MoE-Schichten – reduziert die FLOPs pro Token drastisch, während die Modellkapazität erhalten bleibt.
- Multi-Token-Vorhersage (MTP): Steigert die Leistung des vortrainierten Modells und beschleunigt die Inferenz.
- Weitere Optimierungen: Umfasst Techniken wie um Null zentrierte und gewichts-dekrementierte Layernorm, Gated Attention und weitere stabilisierende Erweiterungen für robustes Training.
Auf dieser Architektur basierend verfügt Qwen3-Next-80B-A3B über insgesamt 80B Parameter, von denen nur 3B aktiv sind – und erreicht so extreme Sparsamkeit und Effizienz.
Trotz seiner ultra-hohen Effizienz übertrifft es Qwen3-32B bei nachgelagerten Aufgaben und benötigt dabei weniger als 1/10 der Trainingskosten. Darüber hinaus liefert es einen mehr als 10-fach höheren Inferenz-Durchsatz als Qwen3-32B bei der Verarbeitung von Kontexten länger als 32K Token.
Leistungsbenchmarks von Qwen3-Next-80B-A3B
Instruct-Modellleistung
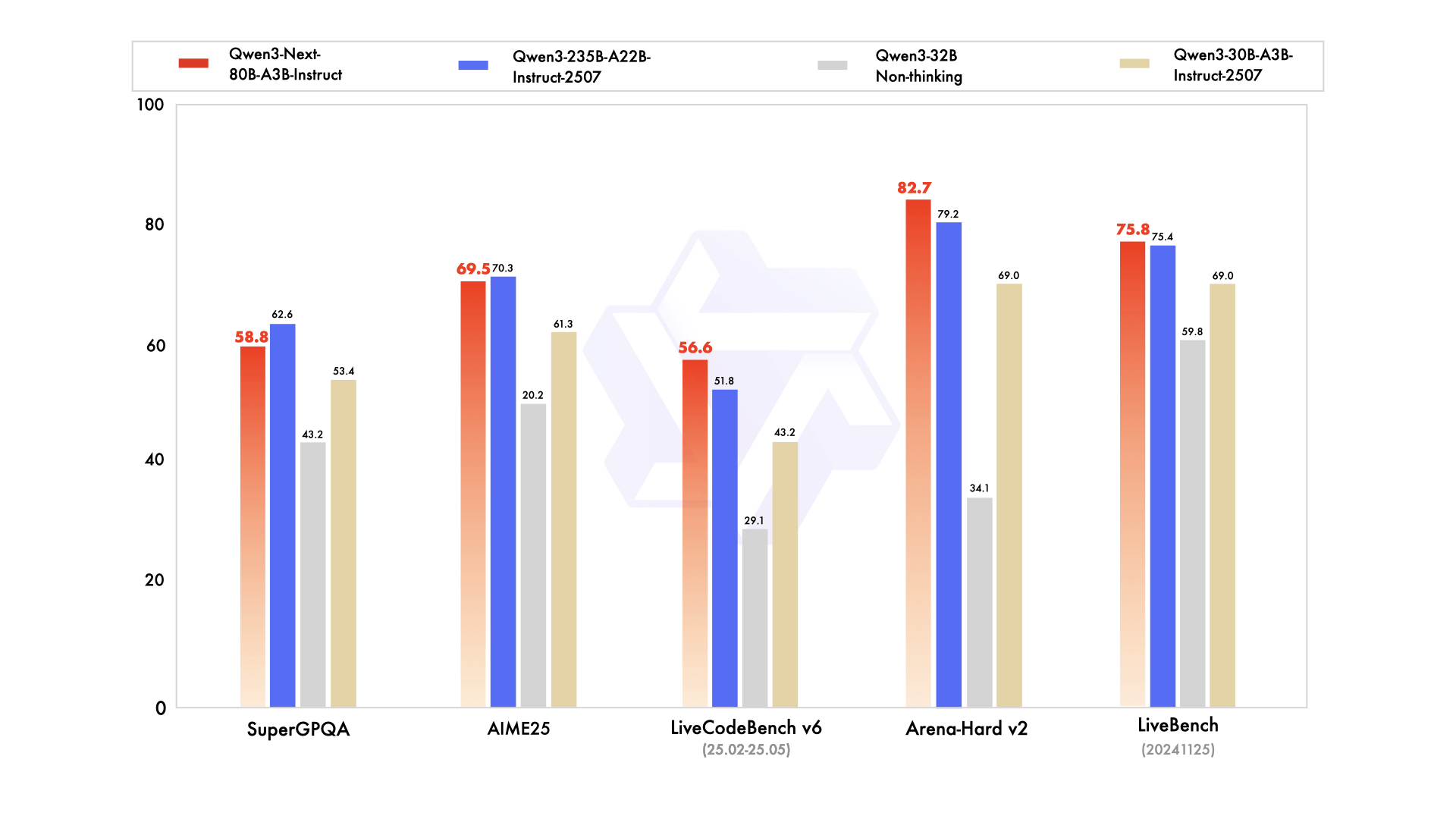
Quelle: Offizielles Qwen3-Next-Blog
Leistung des Thinking-Modells
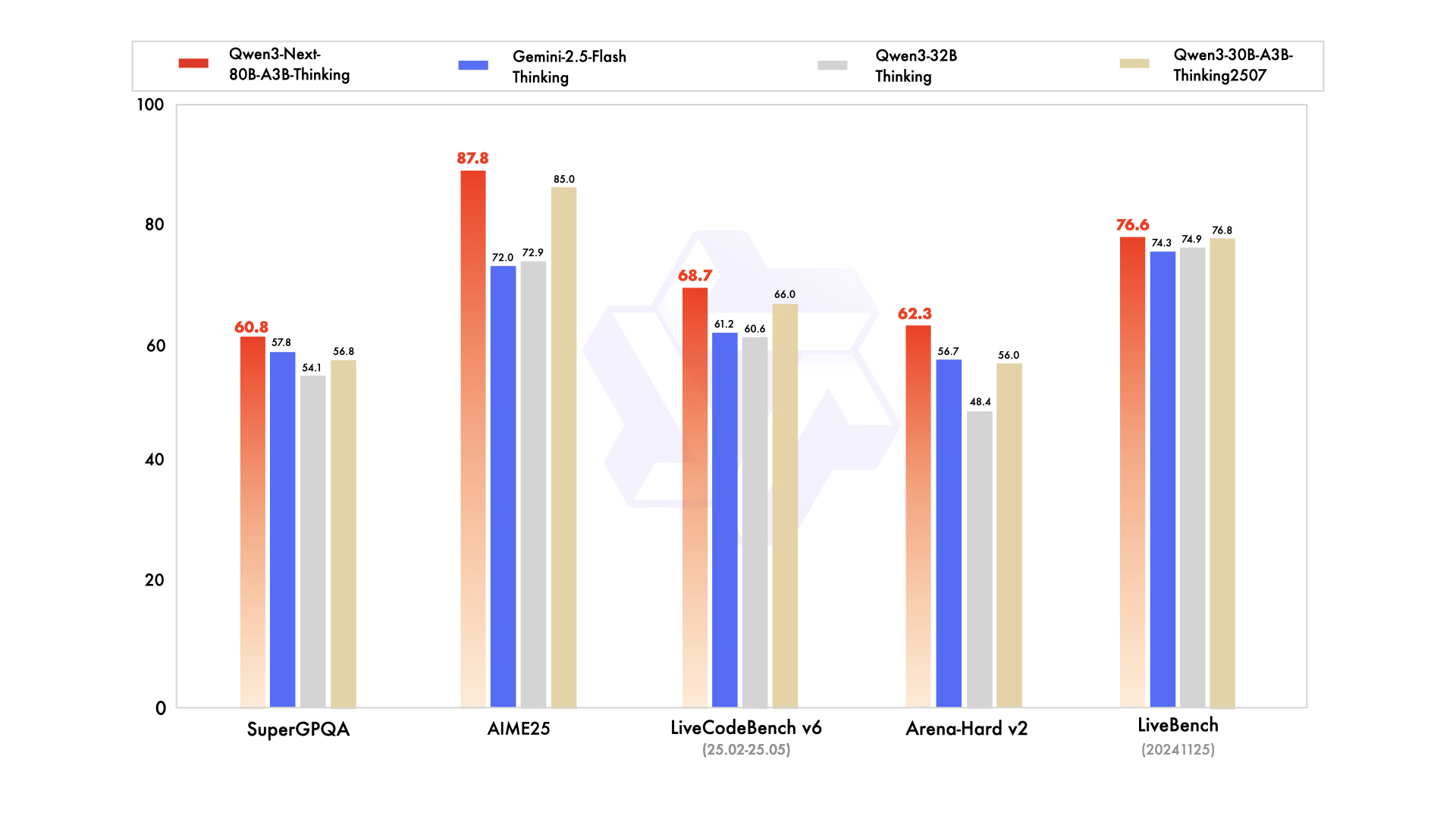
Quelle: Offizielles Qwen3-Next-Blog
Zugriff auf Qwen3-Next-80B-A3B auf Novita AI
Greifen Sie über die Infrastruktur von Novita AI auf das revolutionäre Qwen3-Next-80B-A3B-Modell zu – nutzen Sie die extreme Sparsamkeit für beispiellose Effizienz. Die Plattform von Novita AI beseitigt die Komplexität der Bereitstellung und erschließt gleichzeitig das volle Potenzial dieser Next-Generation-Architektur.
Playground nutzen (kein Code erforderlich)
- Sofortiger Zugriff: Melden Sie sich an und beginnen Sie innerhalb von Sekunden mit dem Experimentieren mit Qwen3-Next-80B-A3B über die Weboberfläche von Novita AI – keine Einrichtung von Infrastruktur erforderlich.
- Interaktives Testen: Erleben Sie den Hybrid-Attention-Mechanismus und die Multi-Token-Vorhersage-Funktionen des Modells über die intuitive Playground-Oberfläche von Novita AI.
- Wichtige Konfigurationsoptionen:
- max_tokens: Testen Sie die außergewöhnlichen Langkontext-Fähigkeiten von Qwen3-Next
- temperature & top_p: Passen Sie Kreativität und Antwortvielfalt fein ab
- System Prompt: Passen Sie das Modellverhalten sofort an
- Function Calling: Testen Sie die Tool-Integration direkt im Playground
- Modellvergleich: Wechseln Sie zwischen den Qwen3-Next-80B-A3B-Instruct- und Thinking-Varianten oder vergleichen Sie das Modell mit anderen auf Novita AI verfügbaren Modellen, um die Leistung für Ihre Anwendungsfälle zu bewerten.
Über API integrieren (für Entwickler)
Verbinden Sie Qwen3-Next-80B-A3B über die REST-API von Novita AI mit Ihren Anwendungen – profitieren Sie von dem 10-fachen Inferenz-Durchsatz des Modells bei langen Kontexten, ohne Infrastruktur verwalten zu müssen.
Option 1: Direkte API-Integration (Python-Beispiel)
Greifen Sie über den OpenAI-kompatiblen Endpunkt von Novita AI auf die effiziente Architektur von Qwen3-Next zu:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Plattformfunktionen:
- OpenAI-kompatibler Endpunkt:
/v3/openaifür nahtlose Integration - Flexible Parameter: Steuern Sie die Generierung mit Temperatur, Top-P, Strafen und weiteren Einstellungen
- Streaming-Unterstützung: Wählen Sie zwischen Streaming- oder Batch-Antworten
- Modellauswahl: Zugriff auf beide Instruct- und Thinking-Varianten
Option 2: Multi-Agent-Workflows mit OpenAI Agents SDK
Erstellen Sie Agent-Systeme, die die Effizienz von Qwen3-Next über die Infrastruktur von Novita AI nutzen:
- Kompatibilität mit OpenAI Agents SDK: Nutzen Sie das OpenAI Agents SDK mit dem Endpunkt von Novita AI für Agent-Workflows
- Agent-Funktionen: Entwerfen Sie Systeme, die von der extremen Sparsamkeit und der Langkontext-Leistung profitieren
- Einfache Integration: Zeigen Sie das SDK auf
https://api.novita.ai/v3/openai
Drittanbieter-Integrationen
- Framework-Integration: Greifen Sie über LangChain, Dify und Langflow auf Qwen3-Next-80B-A3B zu
- Entwicklungstools: Kompatibel mit OpenAI-standardisierten Tools, einschließlich Trae, Claude Code, Qwen Code, Cline und Cursor
- Hugging Face Ökosystem: Integrieren Sie das Modell über die API von Novita AI in Spaces und Pipelines
Fazit
Qwen3-Next-80B-A3B ist mehr als nur ein weiteres effizientes Modell – es zeigt, dass architektonische Innovationen Unternehmensfunktionen ohne Unternehmenskosten liefern können.
Jetzt auf Novita AI verfügbar: Sowohl die Instruct- als auch die Thinking- Variante sind sofort einsatzbereit. Nutzen Sie 80 Milliarden Parameter an Intelligenz mit der Geschwindigkeit und den Kosten eines 3-Milliarden-Parameter-Modells über den Playground, die API oder Drittanbieter-Integrationen von Novita AI.
Erleben Sie noch heute die Zukunft der effizienten KI mit Qwen3-Next-80B-A3B auf Novita AI.
Novita AI ist eine führende KI-Cloud-Plattform, die Entwicklern einfach zu nutzende APIs sowie erschwingliche, zuverlässige GPU-Infrastruktur zum Erstellen und Skalieren von KI-Anwendungen bietet.



