

Key Hightlights
Qwen3-Coder-480B-A35B-Instruct: Specialized coding model with 262K token context length, optimized for algorithmic excellence and benchmark performance in programming tasks.
ChatGPT-4.1: Multimodal foundation model with advanced reasoning capabilities, optimized for versatile problem-solving and human-like conversation across diverse domains and applications.
Novita AI not only provides stable API services but also offers extremely cost-effective pricing. For example, Qwen3-Coder-480B-A35B-Instruct costs $0.95 per 1M input tokens and $5 per 1M output tokens.
Basic Introduction of Model
Qwen3-Coder-480B-A35B-Instruct
Qwen3-Coder-480B-A35B-Instruct is a state-of-the-art large-scale causal language model released by Alibaba in July 2025, designed primarily for agentic coding and software development tasks. It employs a Mixture-of-Experts (MoE) architecture with 480 billion total parameters and 35 billion active parameters per forward pass, striking a balance between model capacity and inference efficiency. This model supports extremely long contexts natively at 256K tokens and achieves state-of-the-art performance among open models.
Key Features and Architecture
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 480B in total and 35B activated
- Number of Layers: 62
- Number of Attention Heads (GQA): 96 for Q and 8 for KV
- Number of Experts: 160
- Number of Activated Experts: 8
- Context Length: 262,144 natively.
ChatGPT-4.1
ChatGPT-4.1, released on April 14, 2025 by OpenAI, features breakthrough improvements in context understanding with a native 1 million token context window, 21% enhanced coding capabilities over GPT-4o, and superior multimodal processing for text, image, and document analysis. Built on an optimized transformer architecture with enhanced attention mechanisms, ChatGPT-4.1 achieves state-of-the-art performance across AIME, GPQA, MMLU academic benchmarks, SWE-bench coding evaluations, and MMMU/MathVista vision tasks.
Key Features and Architecture
- Type: Advanced Large Language Model with Multimodal Capabilities
- Release Date: April 14, 2025
- Context Window: 1M tokens natively
- Coding Performance: 21% improvement in software engineering capabilities over GPT-4o
- Multimodal Support: Enhanced text, image, and document analysis capabilities
- Instruction Following: Advanced adherence to user formatting and task requirements
Benchmark Comparison of Qwen3-Coder-480B-A35B-Instruct and ChatGPT**-**4.1
1. Intelligence Benchmarks

2. Agentic Performance Benchmarks

3. Context Window:
Qwen3-Coder-480B-A35B-Instruct: 262k Tokens
ChatGPT-4.1: 1M Tokens
4. API Pricing:
****Qwen3-Coder-480B-A35B-Instruct: $0.95 / $5 in/out per 1M Tokens
ChatGPT-4.1: $2 / $8 in/out per 1M Tokens
Applied Skills Test
1. Code Debugging Challenge
Problem: Multi-layered Nested Error Debugging
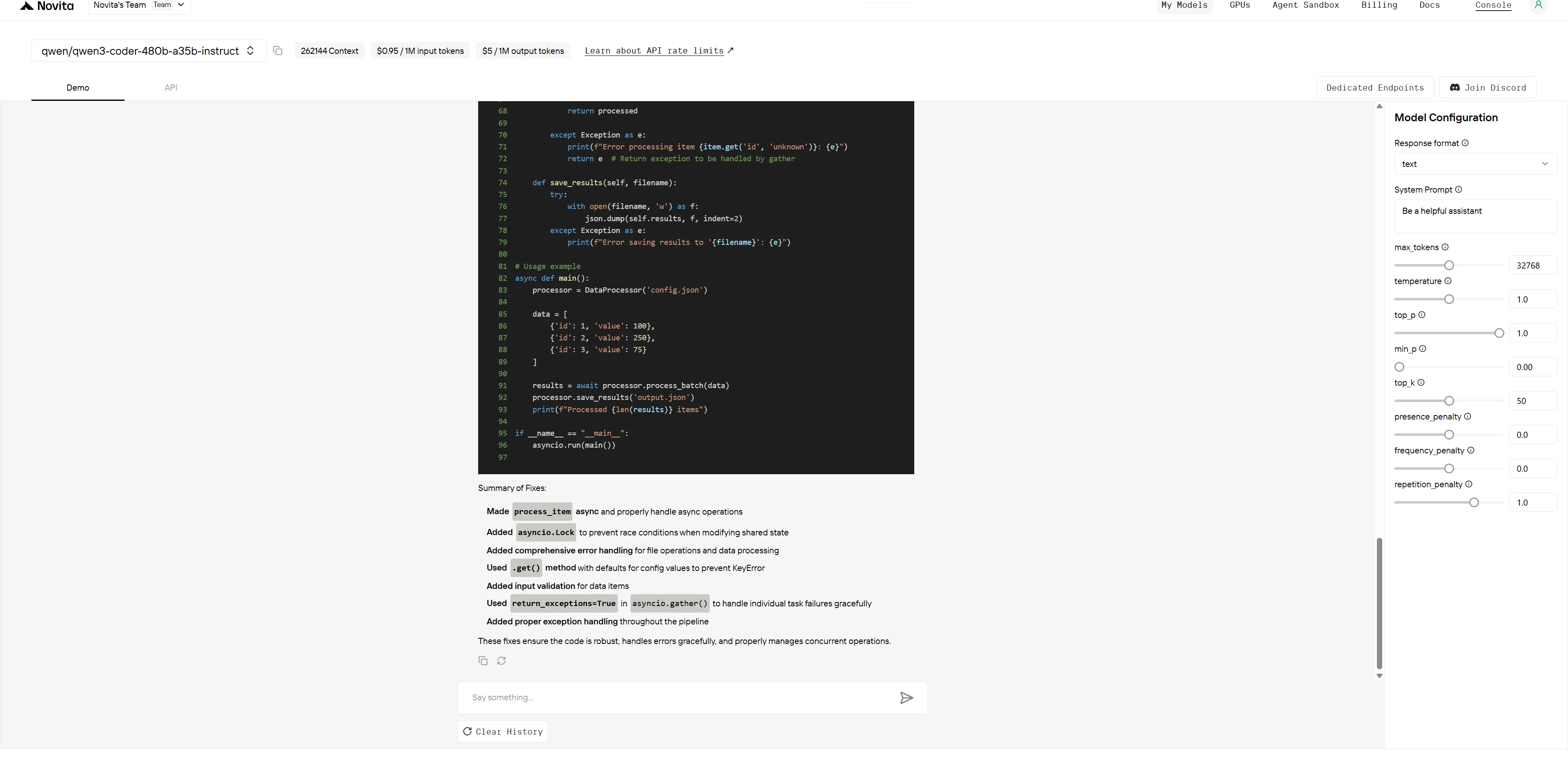
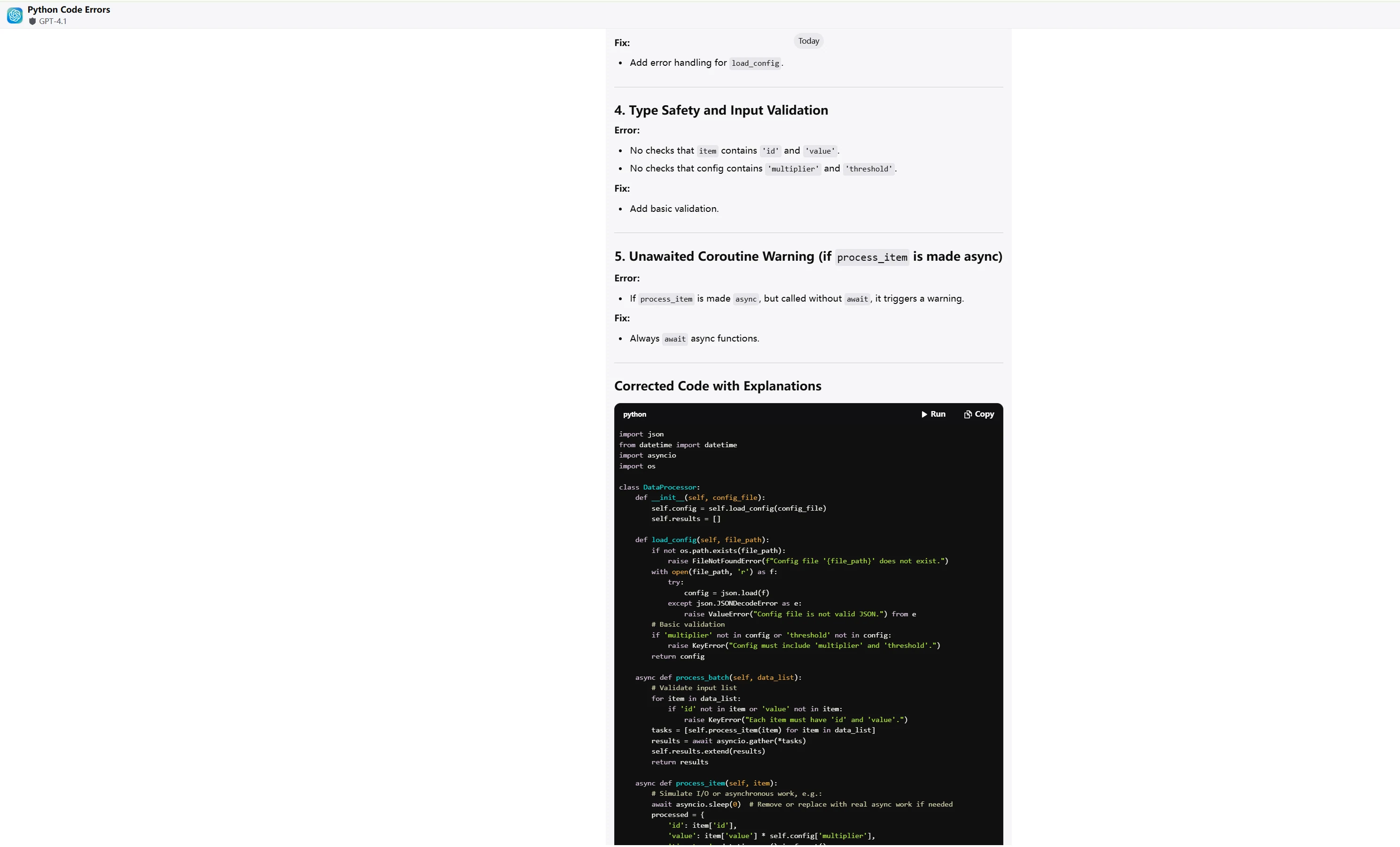
The following Python code attempts to implement a data processing pipeline but contains multiple hidden errors. Please identify all errors and provide fix solutions, while explaining the cause of each error and the repair logic.
import json
from datetime import datetime
import asyncio
class DataProcessor:
def __init__(self, config_file):
self.config = self.load_config(config_file)
self.results = []
def load_config(self, file_path):
with open(file_path, 'r') as f:
return json.load(f)
async def process_batch(self, data_list):
tasks = []
for item in data_list:
task = self.process_item(item)
tasks.append(task)
results = await asyncio.gather(*tasks)
return results
def process_item(self, item):
processed = {
'id': item['id'],
'value': item['value'] * self.config['multiplier'],
'timestamp': datetime.now().isoformat(),
'status': 'processed'
}
if processed['value'] > self.config['threshold']:
processed['category'] = 'high'
else:
processed['category'] = 'low'
self.results.append(processed)
return processed
def save_results(self, filename):
with open(filename, 'w') as f:
json.dump(self.results, f, indent=2)
# Usage example
async def main():
processor = DataProcessor('config.json')
data = [
{'id': 1, 'value': 100},
{'id': 2, 'value': 250},
{'id': 3, 'value': 75}
]
results = await processor.process_batch(data)
processor.save_results('output.json')
print(f"Processed {len(results)} items")
if __name__ == "__main__":
asyncio.run(main())Try with Qwen3-Coder-480B-A35B-Instruct Yourself!
Qwen3-Coder-480B-A35B-Instruct
ChatGPT-4.1
Code Debugging Challenge Comparison
| Evaluation Dimension | Qwen3-Coder | Score | ChatGPT-4.1 | Score |
|---|---|---|---|---|
| Error Identification | Comprehensive detection of all 4 critical bugs; detailed async/sync analysis | 4/4 | Systematic identification with clear prioritization; excellent categorization | 4/4 |
| Solution Quality | Functional but over-engineered; complex locking and exception handling patterns | 2/3 | Elegant, minimal fixes; smart main-thread result collection approach | 3/3 |
| Code Quality | Follows async best practices but unnecessarily complex implementation | 1/2 | Clean, readable code adhering to Python conventions; appropriate validation | 2/2 |
| Clarity & Structure | Verbose explanations; lacks organized presentation; lengthy summary | 0.5/1 | Well-structured with summary table; could be more concise | 0.5/1 |
| Technical Depth | Deep concurrent programming analysis; comprehensive edge case handling | Strong | Balanced technical insight with practical focus | Good |
| Practicality | Over-engineered solutions may hinder maintenance | Moderate | Clean, maintainable solutions ready for production | Strong |
| Innovation | Advanced async patterns and error propagation techniques | Good | Smart problem-solving with elegant simplicity | Strong |
| FINAL SCORE | Technically thorough but over-complicated | 7.5/10 | Balanced excellence in solution quality and clarity | 8.5/10 |
ChatGPT-4.1 demonstrates superior solution elegance and code maintainability, while Qwen3-Coder shows deeper technical analysis but suffers from over-engineering.
2. Python Programming Challenge
Problem: Smart Cache Decorator with TTL and Statistics
Implement a decorator @smart_cache that provides intelligent caching with the following features:
- Time-to-Live (TTL): Cache entries expire after specified duration
- Size Limit: LRU eviction when cache exceeds max size
- Statistics Tracking: Hit rate, miss count, eviction count
- Conditional Caching: Only cache results based on custom predicates
- Thread Safety: Support concurrent access
Requirements:
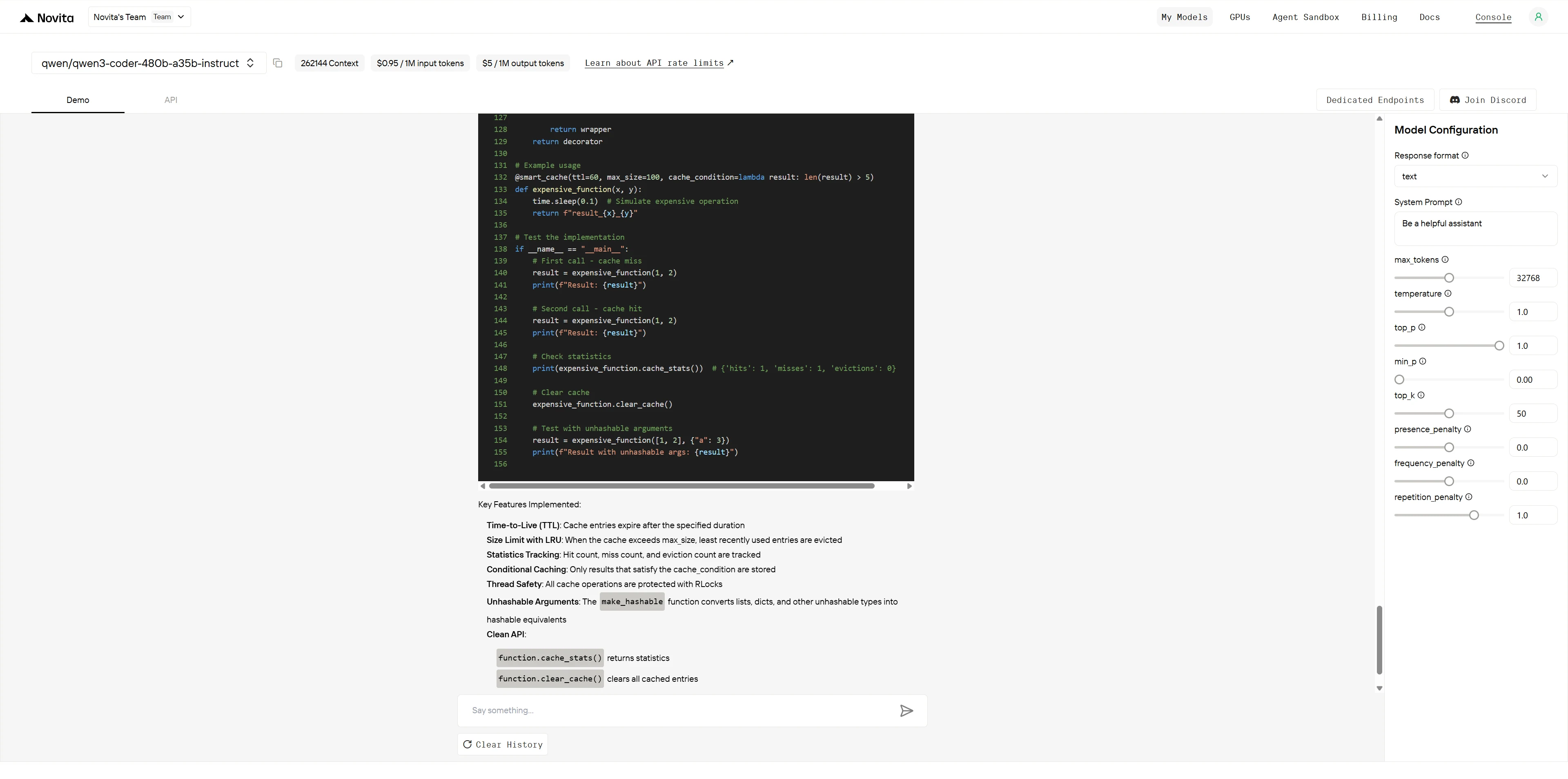
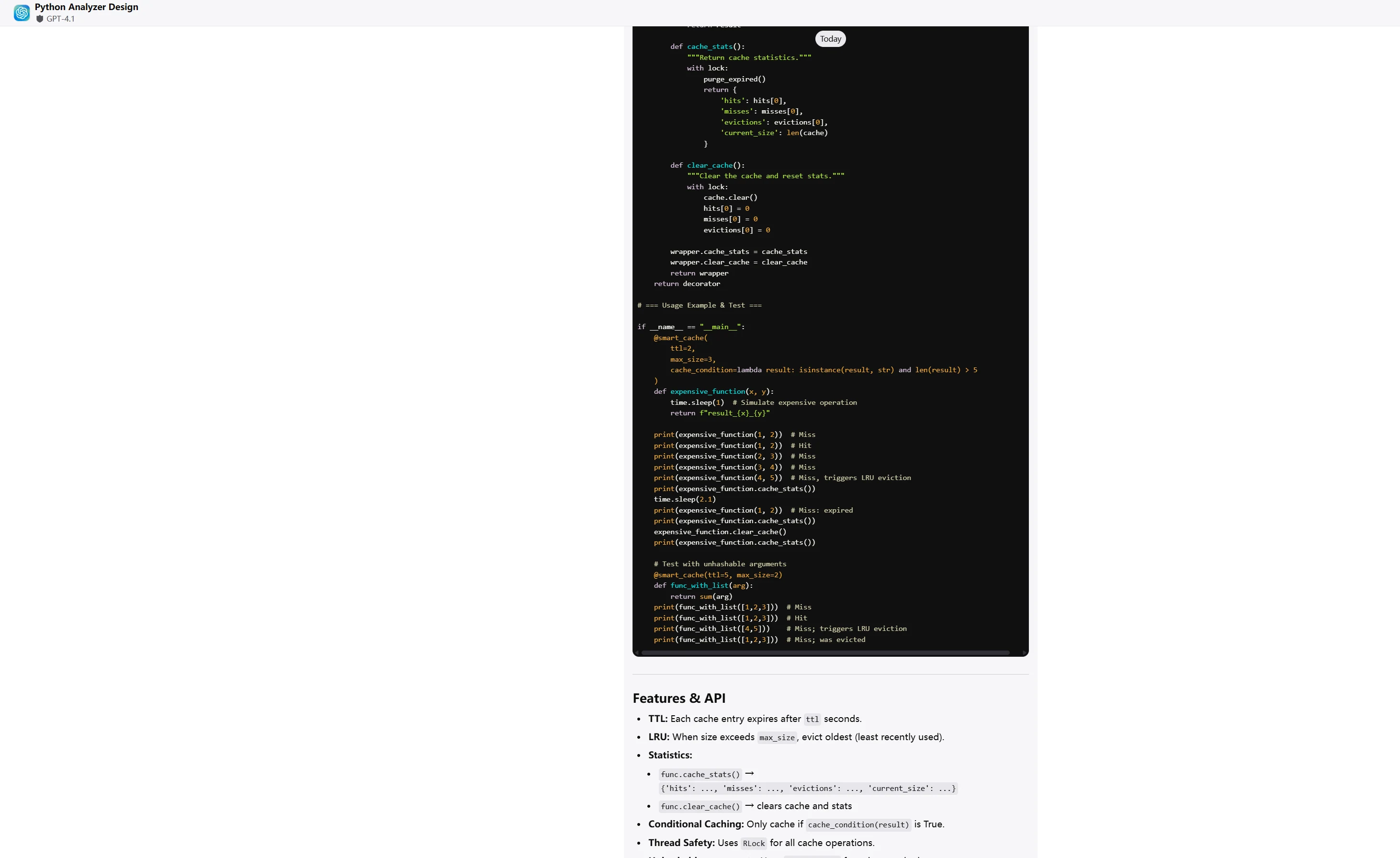
@smart_cache(ttl=60, max_size=100, cache_condition=lambda result: len(result) > 5)
def expensive_function(x, y):
time.sleep(1) # Simulate expensive operation
return f"result_{x}_{y}"
# Usage should support:
result = expensive_function(1, 2) # Cache miss
result = expensive_function(1, 2) # Cache hit
print(expensive_function.cache_stats()) # {'hits': 1, 'misses': 1, 'evictions': 0}
expensive_function.clear_cache()Key Challenges:
- Handle unhashable arguments (lists, dicts)
- Implement efficient TTL cleanup
- Maintain thread safety without performance degradation
- Provide clean API for cache management
Evaluation Criteria:
- Correctness (3 pts): All features work as specified
- Performance (2 pts): Efficient implementation, minimal overhead
- Code Quality (3 pts): Clean, readable, well-structured
- Edge Cases (2 pts): Handle unusual inputs gracefully
Expected Solution Length: 50-80 lines of core implementation
Qwen3-Coder-480B-A35B-Instruct
ChatGPT-4.1
Python Programming Comparison
| Evaluation Dimension | Qwen3-Coder | Score | ChatGPT-4.1 | Score |
|---|---|---|---|---|
| Correctness | Complete implementation; all features work correctly with proper TTL/LRU logic | 3/3 | Full feature set; proper TTL/LRU/stats implementation | 3/3 |
| Performance | Efficient freeze() function; smart cleanup during access; minimal overhead | 2/2 | pickle.dumps() adds significant serialization overhead for every cache key | 1/2 |
| Code Quality | Clean class-based design; proper separation of concerns; type hints included | 3/3 | Functional approach with stats as mutable lists; mixed concerns | 2/3 |
| Edge Cases | Robust recursive freeze() handles nested unhashable types elegantly | 2/2 | Pickle fallback works but less elegant; good error handling | 1.5/2 |
| Architecture | Professional OOP design with dedicated SmartCache class; excellent encapsulation | Outstanding | Simple closure-based approach; easier to understand but less extensible | Good |
| Thread Safety | Proper RLock usage with consistent locking strategy; efficient cleanup | Excellent | Correct RLock implementation with proper scoping | Excellent |
| API Design | Clean decorator interface; proper method exposure; cache inspection capability | Superior | Simple functional API; easy to use | Good |
| Code Documentation | Comprehensive docstrings; clear type hints; well-commented implementation | Excellent | Basic documentation; functional but minimal | Moderate |
| FINAL SCORE | Production-grade implementation with superior architecture and performance | 10/10 | Solid functional solution with performance trade-offs | 7.5/10 |
Qwen3-Coder Strengths:
- Performance Excellence: Custom
freeze()function vs expensivepickle.dumps()- significantly faster for complex arguments - Professional Architecture: Dedicated
SmartCacheclass with clear responsibilities and proper encapsulation - Code Quality: Type hints, comprehensive documentation, clean separation of concerns
- Efficient TTL Management: Cleanup during access operations rather than expensive periodic purging
- Robust Key Handling: Recursive freeze algorithm handles deeply nested unhashable structures
ChatGPT-4.1 Limitations:
- Performance Bottleneck:
pickle.dumps()for every cache lookup creates unnecessary overhead - Architecture: Functional approach with mutable lists for stats is less maintainable
- Key Generation: Pickle-based approach is less efficient and elegant
Winner: Qwen3-Coder demonstrates enterprise-level software engineering with superior performance, architecture, and maintainability.
Try with Qwen3-Coder-480B-A35B-Instruct Yourself!
Strengths & Weaknesses of Qwen3-Coder-480B-A35B-Instruct and ChatGPT-4.1
Qwen3-Coder Strengths:
- Engineering Precision: Professional OOP design patterns and enterprise-grade code structure
- Performance Optimization: Efficient algorithms with minimal computational overhead
- Code Quality: Comprehensive type hints, documentation, and separation of concerns
- Production Readiness: Robust implementations with proper error handling and scalability
Qwen3-Coder Weaknesses:
- Over-Engineering Tendency: Sometimes creates unnecessarily complex solutions
- Learning Curve: Higher complexity may reduce accessibility for beginners
- Domain Specialization: Highly focused on coding, less versatile for other tasks
ChatGPT-4.1 Strengths:
- Adaptive Intelligence: Flexible problem-solving with creative approaches across domains
- Multimodal Integration: Enhanced text, image, and document analysis capabilities
- User Accessibility: Intuitive solutions that are easy to understand and modify
- Broad Versatility: Superior performance across diverse task categories
ChatGPT-4.1 Weaknesses:
- Performance Trade-offs: Sometimes chooses simpler but less efficient implementations
- Architecture Simplicity: Functional approaches may lack scalability for complex systems
- Optimization Gaps: May miss performance optimizations in favor of readability
How to Access Qwen3-Coder-480B-A35B-Instruct on Novita AI
1. Use the Playground (No Coding Required)
- Instant Access: Sign up, claim your free credits, and start experimenting with Qwen3-Coder-480B-A35B-Instruct and other top models in seconds.
- Interactive UI: Test prompts, chain-of-thought reasoning, and visualize results in real time.
- Model Comparison: Effortlessly switch between Kimi K2, Llama 4, DeepSeek, and more to find the perfect fit for your needs.
Explore Qwen3-Coder-480B-A35B-Instruct Demo Now!
2. Integrate via API (For Developers)
Seamlessly connect Qwen3-Coder-480B-A35B-Instruct to your applications, workflows, or chatbots with Novita AI’s unified REST API—no need to manage model weights or infrastructure.
Direct API Integration (Python Example)
To get started, simply use the code snippet below:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_cYQSfVMpIb2mRiKf8UOlCSYLuHBjC623pEitotYA8OlPUtMvoE7Z2RUjgDru_x8JpcRARGnvjQGONtIl9VhMuA==",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 32768
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Frequently Asked Questions
Is the Qwen3 coder good?
Excellent for professional development with superior architecture and performance, but may be overly complex for simple tasks.
What is Qwen3 coder?
Qwen3-Coder is Alibaba’s large language model series optimized for coding and software development, featuring powerful reasoning and extremely long context support.
Is GPT-4.1 good for coding?
Good for coding with improved capabilities and user-friendly approach, but sometimes sacrifices performance for simplicity.g challenges.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



