

Destaques Principais
O Qwen 2.5 7B é um modelo de linguagem de alto desempenho e código aberto.
A inferência em precisão total (FP16) requer ~17,18 GB de VRAM; o fine-tuning pode exceder 92 GB.
Executar localmente exige GPUs de ponta, tornando a implantação cara para a maioria.
Novita AI, nCompass e Nineteen AI suportam o acesso ao Qwen 2.5 7B.
Convide seus amigos para Novita AI e vocês dois ganharão $10 em créditos de API LLM — até $500 em recompensas totais.
Para apoiar a comunidade de desenvolvedores, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B estão atualmente disponíveis gratuitamente na Novita AI.

O Qwen 2.5 7B é um modelo poderoso de 7B parâmetros construído para geração de linguagem de alta qualidade. Embora seu desempenho seja impressionante, suas exigências de hardware representam uma barreira para muitas equipes. Através de provedores de API terceirizados confiáveis como Novita AI, nCompass e Nineteen AI, desenvolvedores podem implantar e escalar o Qwen 2.5 7B em segundos — sem necessidade de configuração de GPU de ponta.
O que é Qwen 2.5 7B?

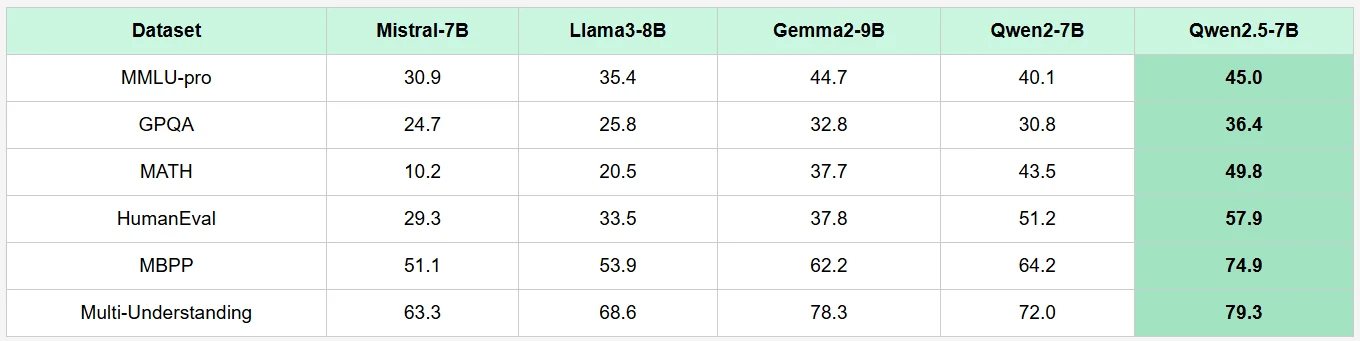
Benchmark do Qwen 2.5 7B
Requisitos de Hardware do Qwen 2.5 7B
| Precisão | VRAM aproximada necessária para inferência |
| FP32 | 32,26 GB |
| FP16 | 17,18 GB |
| Precisão | VRAM aproximada necessária para fine-tuning |
| FP16 | 92,57 GB |
Por que usar uma API para Qwen 2.5 7B?
O Qwen 2.5 7B oferece desempenho robusto, mas seus requisitos de hardware podem ser proibitivos. Em precisão FP16, a inferência normalmente demanda 17,18 GB de VRAM, enquanto o fine-tuning pode exigir até 92,57 GB. Implantar o modelo localmente frequentemente necessita de GPUs de ponta como A100s ou RTX 4090s — recursos além do alcance da maioria dos desenvolvedores e equipes. O acesso via API fornece uma alternativa prática, oferecendo disponibilidade imediata de recursos computacionais sem custos de infraestrutura iniciais ou complexidade operacional.
Vantagens do Acesso via API
| ⚙️ Automação Automatize tarefas, reduza trabalho manual, aumente a eficiência. |
🧩 Integração Conecte sistemas, crie experiências integradas. |
📈 Escalabilidade Escalone facilmente sem grandes reformulações. |
💡 Inovação Construa soluções mais rápidas, baratas e inteligentes. |
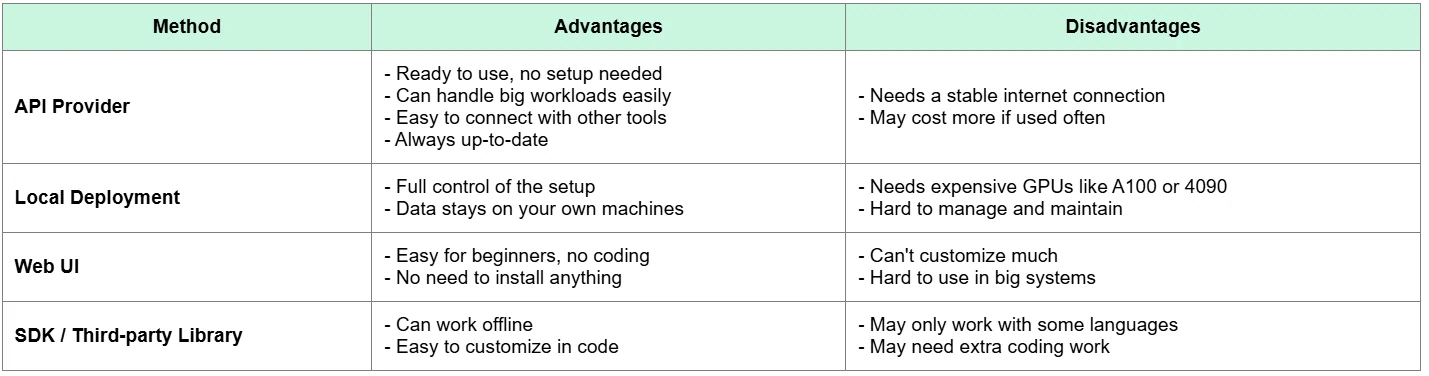
Comparação: API vs Outros Métodos de Implantação
Como Escolher um Provedor de API (5 métricas)
Máximo de tokens: Quanto mais tokens permitidos por resposta, melhor.
Maior = Melhor
Custo de entrada: Custo por milhão de tokens de entrada.
Menor = Melhor
Custo de saída: Custo por milhão de tokens de saída.
Menor = Melhor
Latência: Tempo entre o envio da solicitação e o recebimento do primeiro byte.
Menor = Melhor
Vazão (Throughput): Número de solicitações que a API pode processar por segundo.
Maior = Melhor
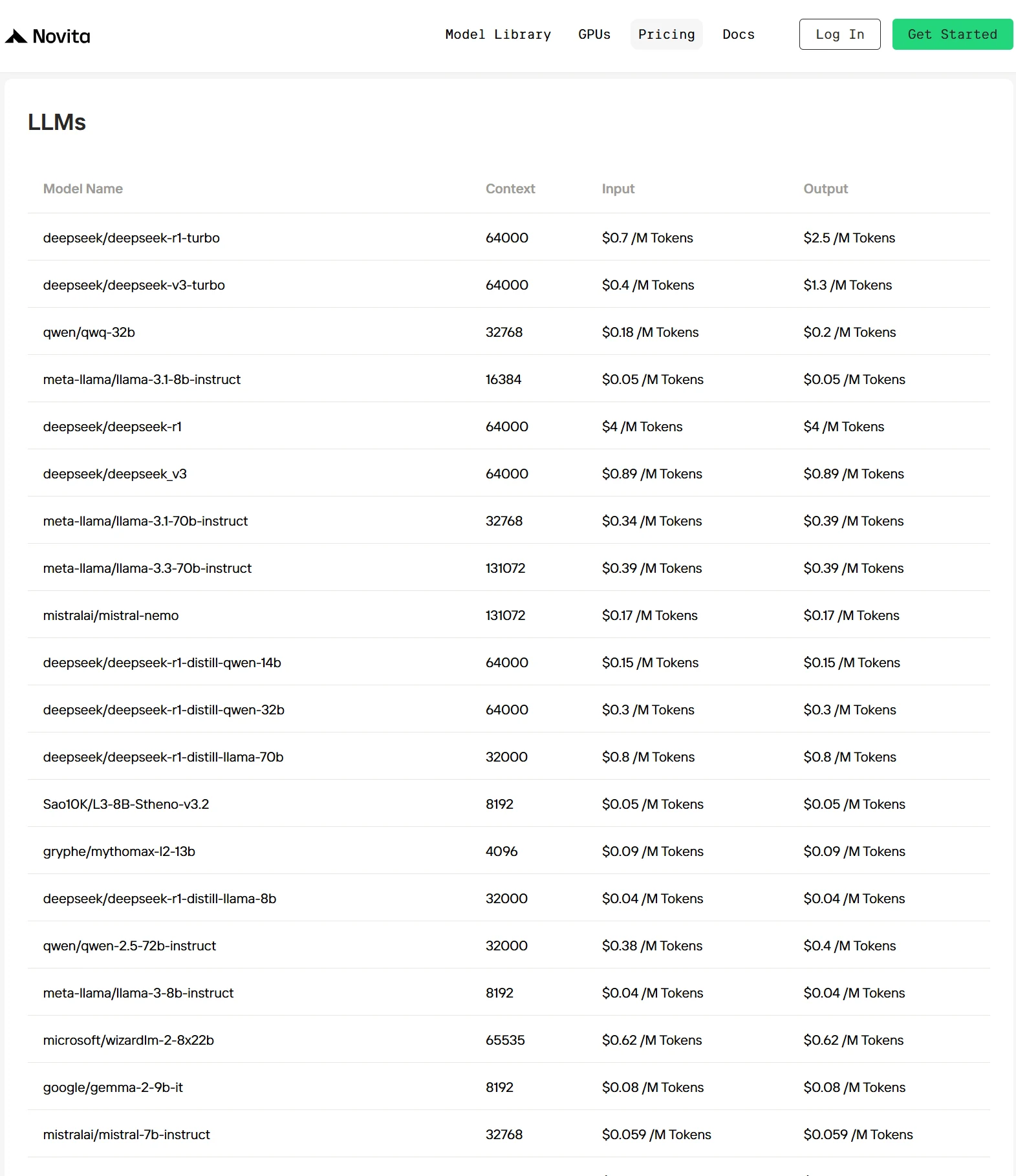
Os 3 Principais Provedores de API para Qwen 2.5 7B
1. Novita AI
Novita AI é uma plataforma em nuvem amigável para desenvolvedores que permite implantação rápida de modelos de IA através de uma API simples, apoiada por infraestrutura de GPU acessível e confiável. Com modelos multimodais pré-integrados como DeepSeek V3, DeepSeek R1 e LLaMA 3.3 70B, os desenvolvedores podem começar imediatamente — sem necessidade de configuração. A tecnologia de otimização proprietária da Novita reduz ainda mais os custos de inferência em 30%–50% em comparação com grandes provedores, tornando-a eficiente e econômica para escalar aplicações de IA.

Experimente o Qwen 2.5 7B Demo Agora!
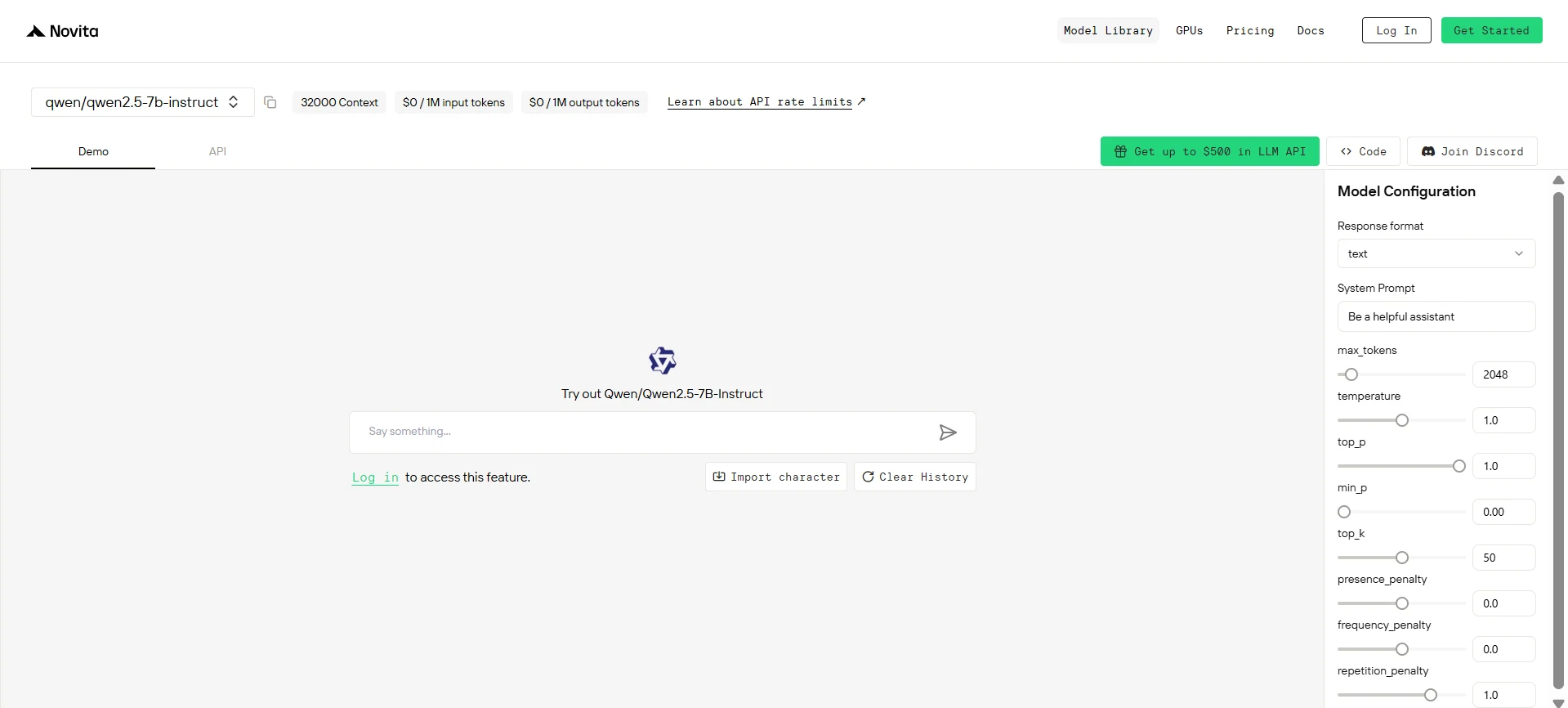
Como acessar o Qwen 2.5 7B via API da Novita?
Você pode iniciar seu teste gratuito para explorar as capacidades do modelo selecionado. Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com a LLM da Novita AI. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwq-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
2. nCompass
nCompass Technologies é uma líder emergente em otimização de infraestrutura de IA, oferecendo soluções avançadas que abordam os crescentes desafios de desempenho e custo da inferência de IA em larga escala. Ao desenvolver kernels de GPU personalizados e software de serviço, a nCompass permite que as empresas mantenham serviços de alta qualidade com menos GPUs — reduzindo drasticamente os custos de hardware sem sacrificar velocidade ou escalabilidade.
Como acessar o Qwen 2.5 7B através dela?
from openai import OpenAI
client = OpenAI(
base_url="https://api.ncompass.tech/v1",
api_key="YOUR_API_KEY",
)
completion = client.chat.completions.create(
model="meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
messages=[
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)
3. Nineteen AI
A Nineteen AI é especializada em inferência, fornecendo acesso simplificado aos principais LLMs de código aberto, modelos de geração de imagem — incluindo aqueles treinados em conjuntos de dados do Subnet 19 — e uma variedade de modelos especializados como embeddings. Também desenvolvemos e disponibilizamos como código aberto nossos próprios fluxos de trabalho, como geração de avatar, para apoiar o desenvolvimento de IA rápido e flexível.
Como acessar o Qwen 2.5 7B através dela?
import json
import contextlib
import requests
url = "https://api.nineteen.ai/v1/chat/completions"
headers = {
"Authorization": "Bearer YOUR_NINETEEN_API_KEY",
"Content-Type": "application/json"
}
data = {
"messages": [],
"model": "chat-qwen-2-5-7b",
"temperature": 0.5,
"max_tokens": 500,
"top_p": 0.5,
"stream": True
}
response = requests.post(url, headers=headers, json=data)
if response.status_code != 200:
raise Exception(response.text)
for x in response.content.decode().split("\
"):
if not x:
continue
with contextlib.suppress(Exception):
print(json.loads(x.split("data: ")[1].strip())["choices"][0]["delta"]["content"], end="", flush=True)
Para desenvolvedores que desejam integrar o Qwen 2.5 7B em sua pilha de forma eficiente, o acesso baseado em API é a escolha mais prática. Ele elimina a sobrecarga de infraestrutura, reduz custos e simplifica a escalabilidade. Seja você construindo chatbots, embeddings ou aplicativos criativos, as APIs de terceiros permitem que você comece rapidamente — com desempenho equivalente à implantação local.
Perguntas Frequentes
Quanta VRAM o Qwen 2.5 7B precisa?
~17,18 GB para inferência (FP16); fine-tuning requer até 92,57 GB.
Por que usar uma API em vez de executar localmente?
APIs eliminam a necessidade de GPUs caras, fornecem acesso instantâneo e são mais fáceis de escalar.
Quais provedores suportam o Qwen 2.5 7B?
Novita AI, nCompass Technologies, Nineteen AI e outros……
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a GPU em nuvem acessível e confiável para construir e escalar.



