

主なハイライト
Qwen 2.5 7B は高性能なオープンソース言語モデルです。
完全精度(FP16)の推論には約 17.18 GB の VRAM が必要で、ファインチューニングでは 92 GB を超えることがあります。
ローカル実行にはハイエンド GPU が必要なため、ほとんどのチームにとって導入コストが高くなります。
Novita AI、nCompass、Nineteen AI はいずれも Qwen 2.5 7B へのアクセスをサポートしています。
友達を Novita AI に紹介すると、あなたと友達の両方が LLM API クレジットとして 10 ドルを獲得できます。最大 500 ドルまで獲得可能です。
開発者コミュニティを支援するため、Qwen2.5-7B、Qwen 3 0.6B、Qwen 3 1.7B、Qwen 3 4B は現在 Novita AI で無料でご利用いただけます。

Qwen 2.5 7B は、高品質な言語生成のために構築された強力な 7B パラメータモデルです。その性能は印象的ですが、ハードウェア要件が多くのチームにとって障壁となっています。Novita AI、nCompass、Nineteen AI のような信頼できるサードパーティ API プロバイダーを利用すれば、開発者はハイエンド GPU のセットアップなしで、Qwen 2.5 7B を数秒でデプロイし、スケールさせることができます。
Qwen 2.5 7B とは?

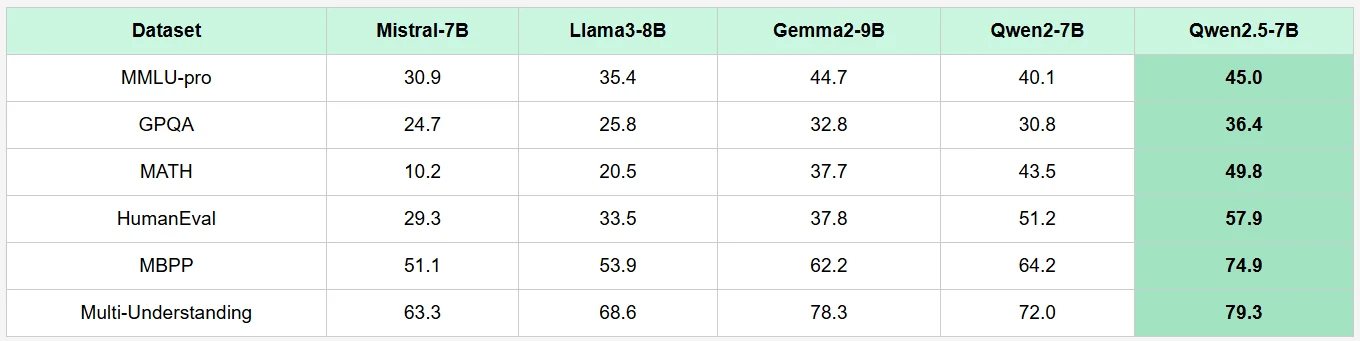
Qwen 2.5 7B ベンチマーク
Qwen 2.5 7B ハードウェア要件
| **精度 ** | ** 推論に必要なVRAM(概算)** |
| FP32 | 32.26GB |
| FP16 | 17.18GB |
| **精度 ** | ** ファインチューニングに必要なVRAM(概算)** |
| FP16 | 92.57GB |
Qwen 2.5 7B に API を使う理由とは?
Qwen 2.5 7B は強力なパフォーマンスを発揮しますが、そのハードウェア要件は導入の障壁となります。FP16 精度では、推論に一般的に 17.18 GB の VRAM が必要で、ファインチューニングには最大 92.57 GB が必要になる場合があります。モデルをローカルにデプロイするには、多くの場合 A100 や RTX 4090 のようなハイエンド GPU が必要となり、これはほとんどの開発者やチームにとって手の届かないリソースです。API アクセスは、初期のインフラコストや運用の複雑さなしに、計算リソースをすぐに利用できる実用的な代替手段を提供します。
API アクセスの利点
| ⚙️ **自動化 ** タスクを自動化し、手作業を減らし、効率を向上させる。 |
🧩 ** 統合 ** システムを接続し、シームレスな体験を生み出す。 |
📈 ** スケーラビリティ ** 大規模な改修なしで簡単にスケールする。 |
💡 ** イノベーション** より速く、より安く、よりスマートなソリューションを構築する。 |
比較:API とその他のデプロイ方法
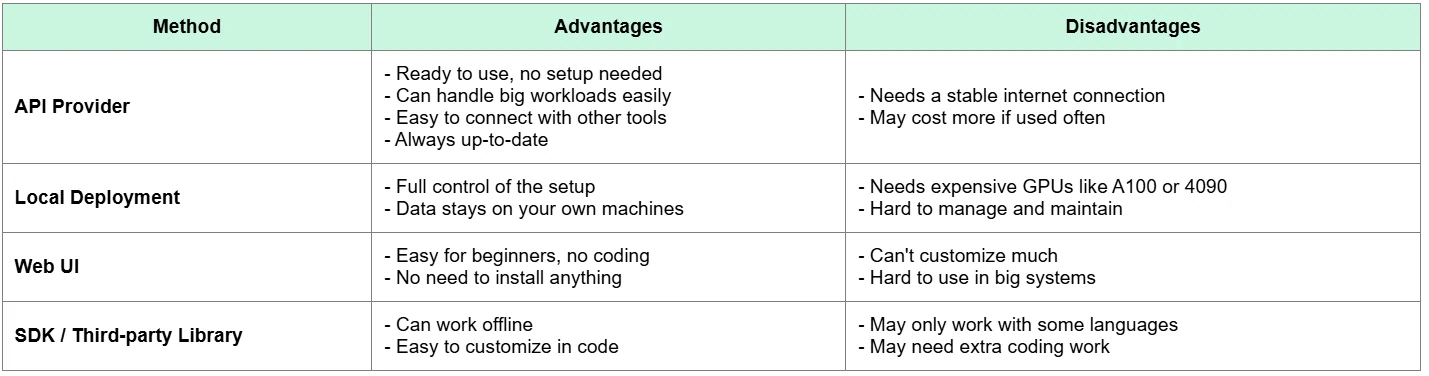
API プロバイダーの選び方(5つの指標)
最大出力:レスポンスあたりの許容トークン数が多いほど良い。
高いほど良い
入力コスト:100万入力トークンあたりのコスト。
低いほど良い
出力コスト:100万出力トークンあたりのコスト。
低いほど良い
レイテンシ:リクエスト送信から最初のバイトを受信するまでの時間。
低いほど良い
スループット:API が1秒間に処理できるリクエスト数。
高いほど良い
Qwen 2.5 7B のトップ3 API プロバイダー
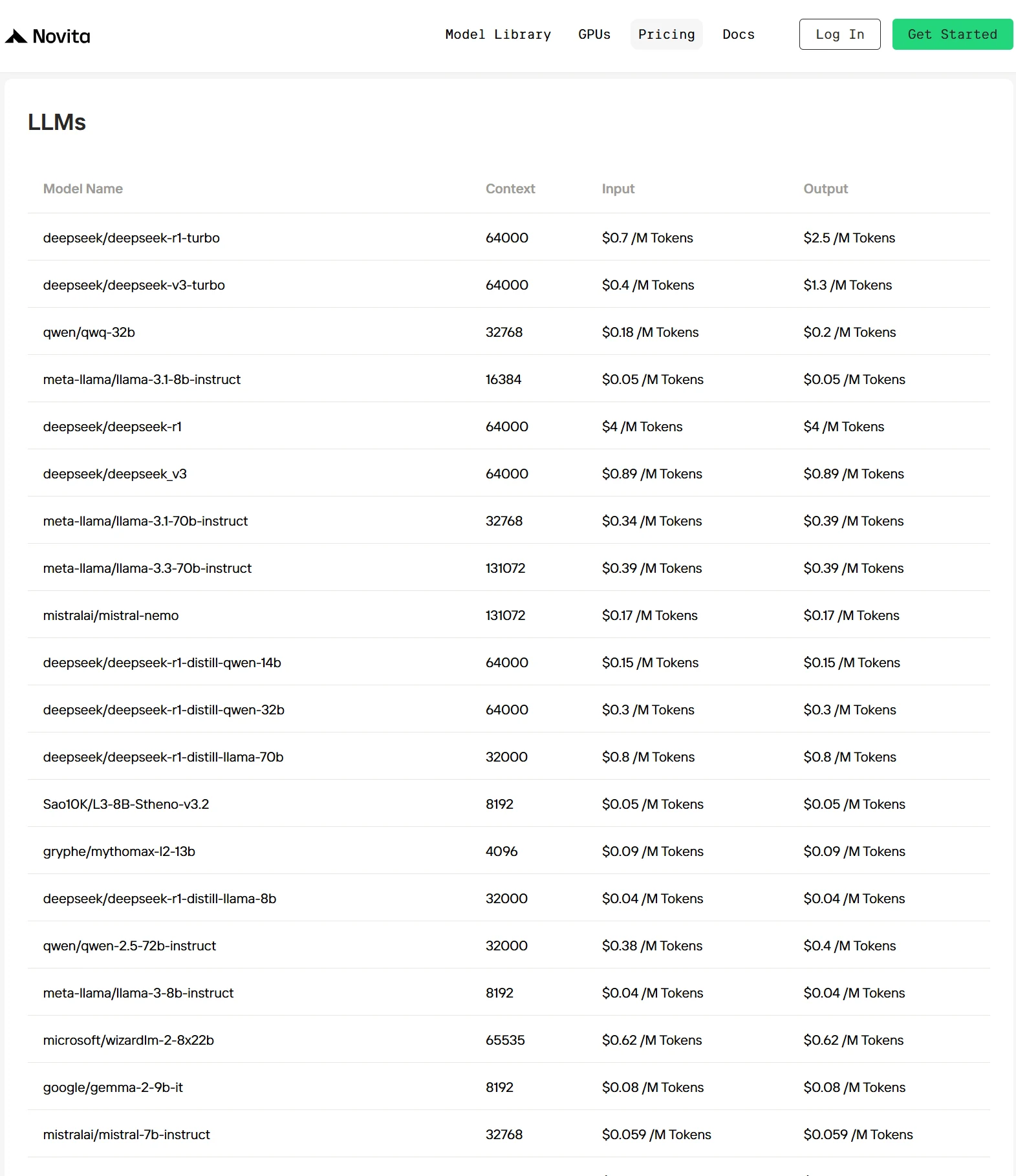
1. Novita AI
Novita AI は開発者フレンドリーなクラウドプラットフォームで、シンプルな API を通じて AI モデルの迅速なデプロイを可能にし、手頃で信頼性の高い GPU インフラを提供します。 DeepSeek V3、DeepSeek R1、LLaMA 3.3 70B などの事前統合されたマルチモーダルモデルにより、開発者はセットアップ不要ですぐに開始できます。Novita の独自の最適化技術により、主要プロバイダーと比較して推論コストを 30%~50%削減し、効率的でコスト効果の高い AI アプリケーションのスケーリングを実現します。

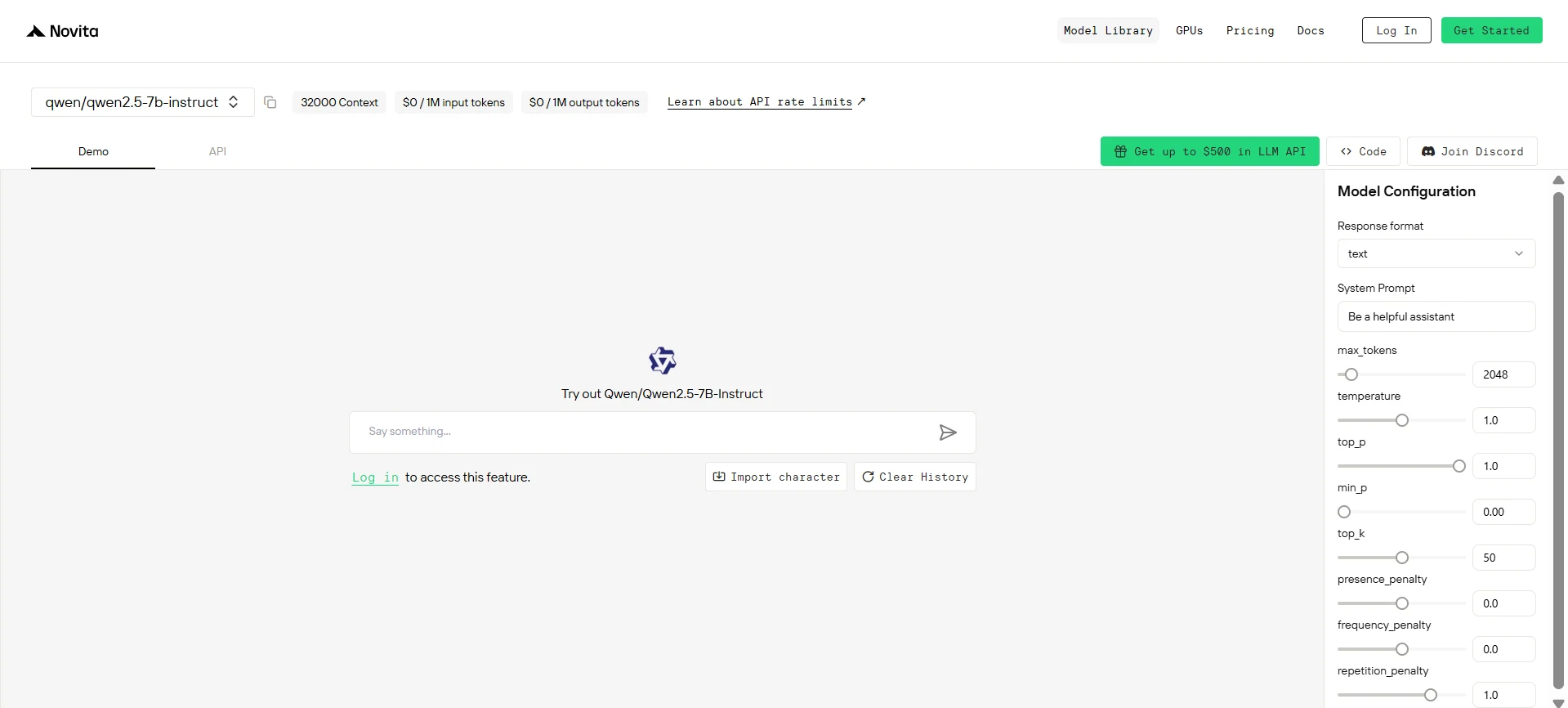
Novita API 経由で Qwen 2.5 7B にアクセスする方法
無料トライアルを開始して、選択したモデルの機能を試すことができます。インストール後、必要なライブラリを開発環境にインポートします。API キーを使用して API を初期化し、Novita AI LLM との対話を開始します。これは Python ユーザー向けの chat completions API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwq-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
2. nCompass
nCompass Technologies は AI インフラ最適化の新興リーダーであり、大規模 AI 推論のパフォーマンスとコストの課題に対応する高度なソリューションを提供しています。カスタム GPU カーネルと提供ソフトウェアを開発することで、nCompass は企業がより少ない GPU で高品質なサービスを維持できるようにし、速度や拡張性を犠牲にすることなくハードウェアコストを大幅に削減します。
それを介して Qwen 2.5 7B にアクセスする方法
from openai import OpenAI
client = OpenAI(
base_url="https://api.ncompass.tech/v1",
api_key="YOUR_API_KEY",
)
completion = client.chat.completions.create(
model="meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
messages=[
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)
3. Nineteen AI
Nineteen AI は推論に特化し、トップクラスのオープンソース LLM、画像生成モデル(Subnet 19 データセットで学習されたモデルを含む)、および埋め込みなどの専門モデルへの合理化されたアクセスを提供します。また、アバター生成など、高速で柔軟な AI 開発を支援する独自のワークフローを開発し、オープンソース化しています。
それを介して Qwen 2.5 7B にアクセスする方法
import json
import contextlib
import requests
url = "https://api.nineteen.ai/v1/chat/completions"
headers = {
"Authorization": "Bearer YOUR_NINETEEN_API_KEY",
"Content-Type": "application/json"
}
data = {
"messages": [],
"model": "chat-qwen-2-5-7b",
"temperature": 0.5,
"max_tokens": 500,
"top_p": 0.5,
"stream": True
}
response = requests.post(url, headers=headers, json=data)
if response.status_code != 200:
raise Exception(response.text)
for x in response.content.decode().split("\
"):
if not x:
continue
with contextlib.suppress(Exception):
print(json.loads(x.split("data: ")[1].strip())["choices"][0]["delta"]["content"], end="", flush=True)
開発者が Qwen 2.5 7B を効率的にスタックに統合したい場合、API ベースのアクセスが最も実用的な選択肢です。インフラのオーバーヘッドを排除し、コストを削減し、スケーリングを簡素化します。チャットボット、埋め込み、クリエイティブアプリのいずれを構築する場合でも、サードパーティ API を使用すれば、ローカルデプロイと同等のパフォーマンスで迅速に開始できます。
よくある質問
Qwen 2.5 7B にはどのくらいの VRAM が必要ですか?
~17.18 GB(推論、FP16)。ファインチューニングには最大 92.57 GB が必要です。
ローカルで実行する代わりに API を使う理由は?
API は高価な GPU を不要にし、即座にアクセスでき、スケーリングが容易です。
Qwen 2.5 7B をサポートしているプロバイダーは?
Novita AI、nCompass Technologies、Nineteen AI などです。
Novita AI は、シンプルな API を使用して AI モデルを簡単にデプロイできる方法を開発者に提供すると同時に、アプリケーションの構築とスケーリングのための手頃で信頼性の高い GPU クラウドを提供する AI クラウドプラットフォームです。



