

Puntos clave
Qwen 2.5 7B es un modelo de lenguaje open source de alto rendimiento.
La inferencia en precisión completa (FP16) requiere ~17.18 GB de VRAM; el fine-tuning puede superar los 92 GB.
Ejecutarlo localmente exige GPUs de gama alta, lo que hace que el despliegue sea costoso para la mayoría.
Novita AI, nCompass y Nineteen AI son compatibles con el acceso a Qwen 2.5 7B.
Invita a tus amigos a Novita AI y ambos ganarán $10 en créditos de API LLM — hasta $500 en recompensas totales.
Para apoyar a la comunidad de desarrolladores, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B y Qwen 3 4B están disponibles de forma gratuita en Novita AI.

Qwen 2.5 7B es un potente modelo de 7B parámetros diseñado para generación de lenguaje de alta calidad. Aunque su rendimiento es impresionante, sus requisitos de hardware suponen una barrera para muchos equipos. A través de proveedores de API de terceros confiables como Novita AI, nCompass y Nineteen AI, los desarrolladores pueden implementar y escalar Qwen 2.5 7B en segundos, sin necesidad de configurar GPUs de gama alta.
¿Qué es Qwen 2.5 7B?

Benchmark de Qwen 2.5 7B
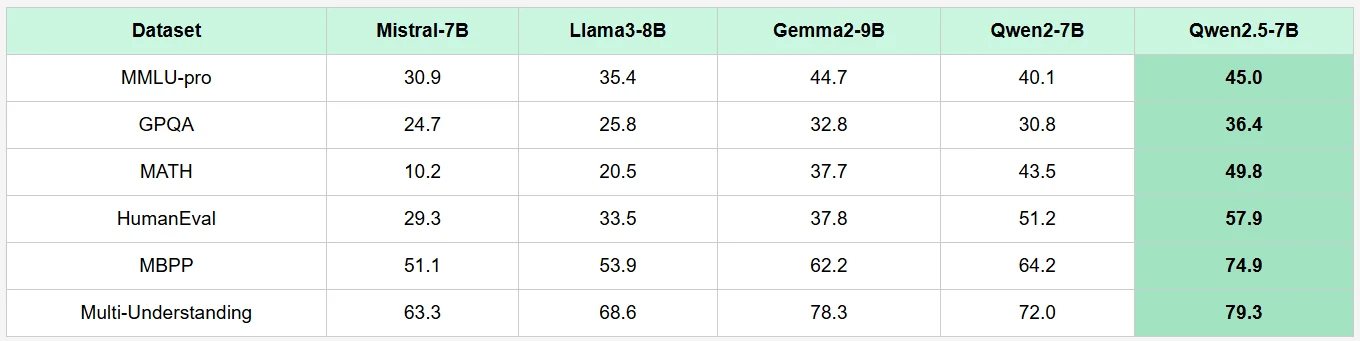
Requisitos de hardware de Qwen 2.5 7B
| Precisión | VRAM aproximada requerida para inferencia |
| FP32 | 32.26GB |
| FP16 | 17.18GB |
| Precisión | VRAM aproximada requerida para fine-tuning |
| FP16 | 92.57GB |
¿Por qué usar una API para Qwen 2.5 7B?
Qwen 2.5 7B ofrece un rendimiento sólido, pero sus requisitos de hardware pueden ser prohibitivos. En precisión FP16, la inferencia típicamente requiere 17.18 GB de VRAM, mientras que el fine-tuning puede necesitar hasta 92.57 GB. Implementar el modelo localmente a menudo exige GPUs de gama alta como A100s o RTX 4090s — recursos fuera del alcance de la mayoría de los desarrolladores y equipos. El acceso por API ofrece una alternativa práctica, brindando disponibilidad inmediata de recursos de cómputo sin costos iniciales de infraestructura ni complejidad operativa.
Ventajas del acceso por API
| ⚙️ Automatización Automatiza tareas, reduce trabajo manual, aumenta la eficiencia. |
🧩 Integración Conecta sistemas, crea experiencias fluidas. |
📈 Escalabilidad Escala fácilmente sin reestructuraciones. |
💡 Innovación Construye soluciones más rápidas, baratas e inteligentes. |
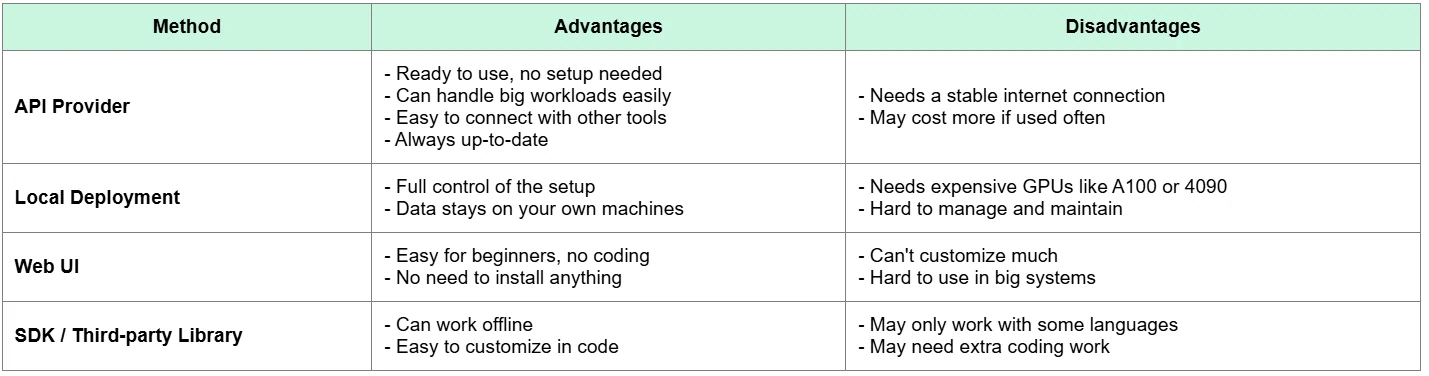
Comparación: API vs otros métodos de implementación
Cómo elegir un proveedor de API (5 métricas)
Salida máxima: Cuantos más tokens permita por respuesta, mejor.
Más alto = Mejor
Costo de entrada: Costo por millón de tokens de entrada.
Más bajo = Mejor
Costo de salida: Costo por millón de tokens de salida.
Más bajo = Mejor
Latencia: Tiempo entre enviar una solicitud y recibir el primer byte.
Más bajo = Mejor
Rendimiento: Número de solicitudes que la API puede manejar por segundo.
Más alto = Mejor
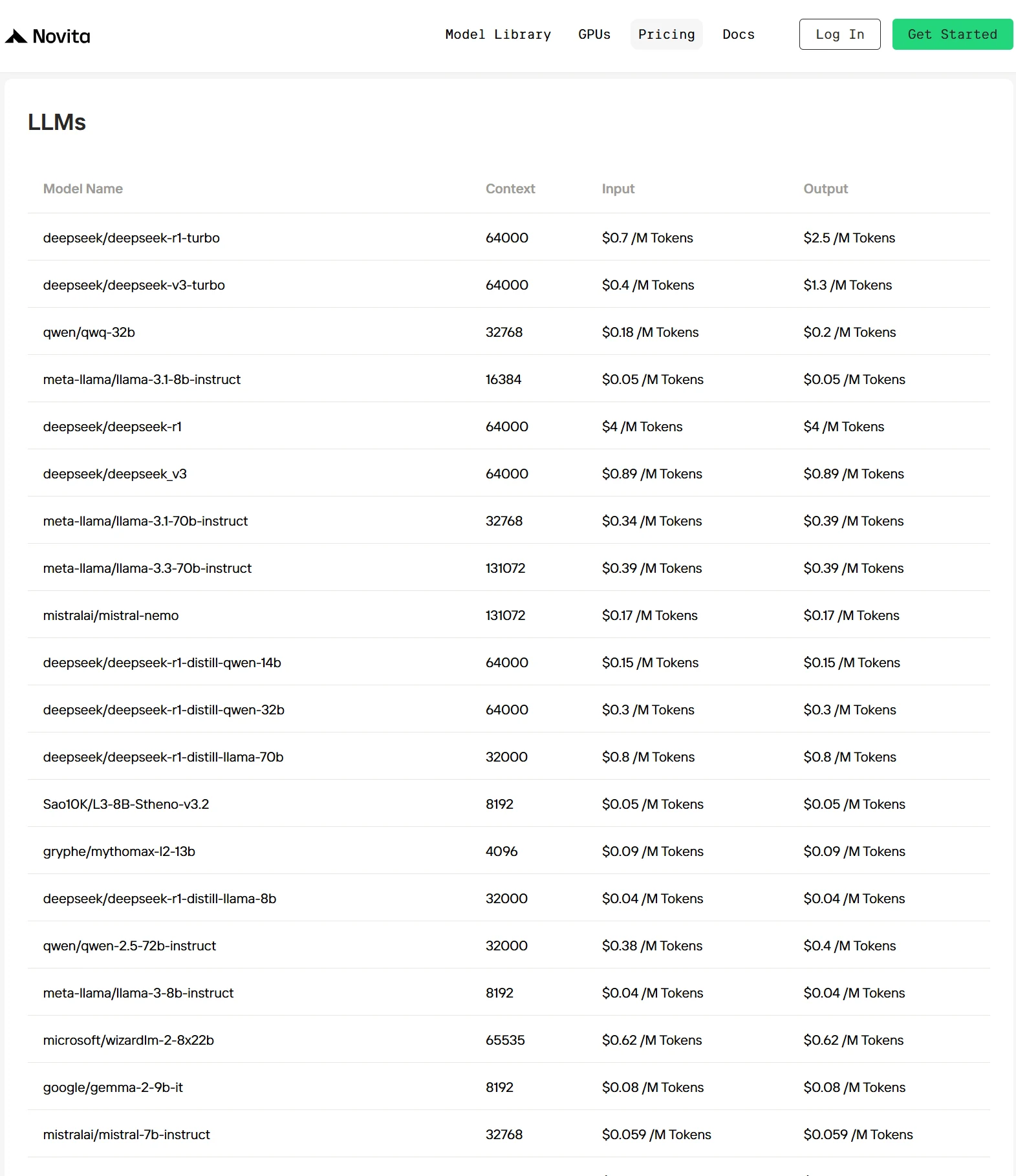
Los 3 mejores proveedores de API de Qwen 2.5 7B
1. Novita AI
Novita AI es una plataforma cloud amigable para desarrolladores que permite el despliegue rápido de modelos de IA mediante una API simple, respaldada por infraestructura GPU asequible y confiable. Con modelos multimodales preintegrados como DeepSeek V3, DeepSeek R1 y LLaMA 3.3 70B, los desarrolladores pueden empezar de inmediato, sin configuración previa. La tecnología de optimización propia de Novita reduce aún más los costos de inferencia entre un 30 % y un 50 % en comparación con los proveedores principales, lo que la hace eficiente y rentable para escalar aplicaciones de IA.

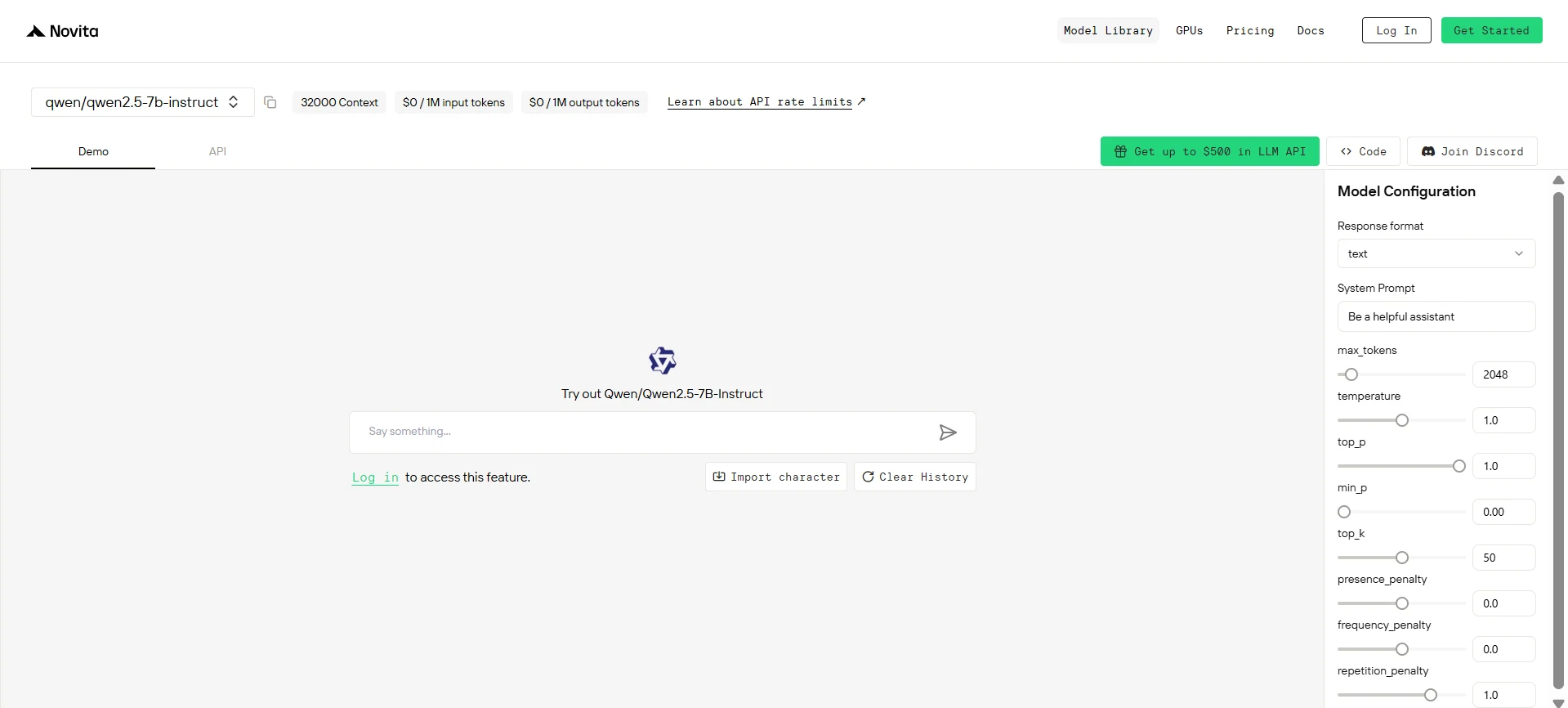
¡Prueba la demo de Qwen 2.5 7B ahora!
Cómo acceder a Qwen 2.5 7B a través de la API de Novita
Puedes iniciar una prueba gratuita para explorar las capacidades del modelo seleccionado. Después de la instalación, importa las bibliotecas necesarias a tu entorno de desarrollo. Inicializa la API con tu clave de API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwq-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
2.nCompass
nCompass Technologies es un líder emergente en optimización de infraestructura de IA, que ofrece soluciones avanzadas que abordan los crecientes desafíos de rendimiento y costo de la inferencia de IA a gran escala. Mediante el desarrollo de kernels GPU personalizados y software de servicio, nCompass permite a las empresas mantener un servicio de alta calidad con menos GPUs, reduciendo drásticamente los costos de hardware sin sacrificar velocidad ni escalabilidad.
Cómo acceder a Qwen 2.5 7B a través de nCompass
from openai import OpenAI
client = OpenAI(
base_url="https://api.ncompass.tech/v1",
api_key="YOUR_API_KEY",
)
completion = client.chat.completions.create(
model="meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
messages=[
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)
3.Nineteen AI
Nineteen AI se especializa en inferencia, proporcionando acceso simplificado a los principales LLMs open source, modelos de generación de imágenes (incluyendo aquellos entrenados en conjuntos de datos de Subnet 19) y una variedad de modelos especializados como embeddings. También hemos desarrollado y publicado como open source nuestros propios flujos de trabajo, como la generación de avatares, para apoyar un desarrollo de IA rápido y flexible.
Cómo acceder a Qwen 2.5 7B a través de Nineteen AI
import json
import contextlib
import requests
url = "https://api.nineteen.ai/v1/chat/completions"
headers = {
"Authorization": "Bearer YOUR_NINETEEN_API_KEY",
"Content-Type": "application/json"
}
data = {
"messages": [],
"model": "chat-qwen-2-5-7b",
"temperature": 0.5,
"max_tokens": 500,
"top_p": 0.5,
"stream": True
}
response = requests.post(url, headers=headers, json=data)
if response.status_code != 200:
raise Exception(response.text)
for x in response.content.decode().split("\
"):
if not x:
continue
with contextlib.suppress(Exception):
print(json.loads(x.split("data: ")[1].strip())["choices"][0]["delta"]["content"], end="", flush=True)
Para los desarrolladores que buscan integrar Qwen 2.5 7B en su stack de manera eficiente, el acceso basado en API es la opción más práctica. Elimina la sobrecarga de infraestructura, reduce costos y simplifica el escalado. Ya sea que estés construyendo chatbots, embeddings o aplicaciones creativas, las APIs de terceros te permiten empezar rápido, con un rendimiento equivalente al de un despliegue local.
Preguntas frecuentes
¿Cuánta VRAM necesita Qwen 2.5 7B?
~17.18 GB para inferencia (FP16); el fine-tuning requiere hasta 92.57 GB.
¿Por qué usar una API en lugar de ejecutarlo localmente?
Las APIs eliminan la necesidad de GPUs costosas, proporcionan acceso inmediato y son más fáciles de escalar.
¿Qué proveedores son compatibles con Qwen 2.5 7B?
Novita AI, nCompass Technologies, Nineteen AI y más…
Novita AI es una plataforma cloud de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona la nube GPU asequible y confiable para construir y escalar.



