

Key Highlights
MiniMax M1: Hybrid MoE architecture with 1M token context length, optimized for cost-effective processing of extremely long sequences.
DeepSeek R1 0528: Large-scale model focused on precision and robustness for enterprise-grade accuracy in complex reasoning tasks.
Novita AI not only provides stable API services but also offers extremely cost-effective pricing. For example, Minimax M1 costs only $0.55 per 1M input tokens and $2.2 per 1M output tokens, while DeepSeek R1 0528 costs $0.7 per 1M input tokens and $2.5 per 1M output tokens.
For a limited time, new users can claim **$10 in free credits**to explore and build with LLM API on Novita AI.
MiniMax M1 vs DeepSeek R1 0528: Basic Introduction
MiniMax M1 Introduction
MiniMax M1, released in June 2025, is an open-source large language model built on a cutting-edge hybrid Mixture-of-Experts architecture enhanced with Lightning Attention technology. The model excels at function calling and long-context reasoning, supporting an impressive maximum context length of 1 million tokens—enabling comprehensive analysis of extensive documents and complex codebases.
Trained on over 10 trillion tokens sourced from web content, code repositories, and documents, MiniMax M1 supports more than 30 languages and delivers text-to-text capabilities with specialized strength in long-context document and code understanding. The model employs CISPO, a novel and efficient reinforcement learning algorithm that optimizes the training process.
What sets MiniMax M1 apart is its efficiency, requiring only approximately 25% of the FLOPs compared to comparable dense models when processing long-context tasks. This efficiency advantage, combined with its open-source accessibility and extensive language support, makes MiniMax M1 an ideal solution for organizations seeking powerful AI capabilities without prohibitive computational costs.
DeepSeek R1 0528 Introduction
DeepSeek R1 0528 was launched on May 28, 2025, as an open-source large model with approximately 685 billion parameters. It uses a Mixture-of-Experts (MoE) architecture, activating about 37 billion parameters per token during inference. The model supports a maximum context length of 128K tokens.
The model excels in chat, reasoning, coding, mathematics, and function calling, with added support for JSON output and function call interfaces, significantly enhancing its ability to handle complex tasks. It was trained on over 10 trillion tokens, including web content, code, mathematical data, and documents, with a strong focus on bilingual capabilities in English and Chinese.
Training involved traditional Reinforcement Learning from Human Feedback (RLHF) and fine-tuning methods, combined with substantial compute resources and algorithmic optimizations in the later stages. This approach prioritizes accuracy and reliability over efficiency, making the model well-suited for enterprise applications, especially those requiring complex reasoning and high precision.
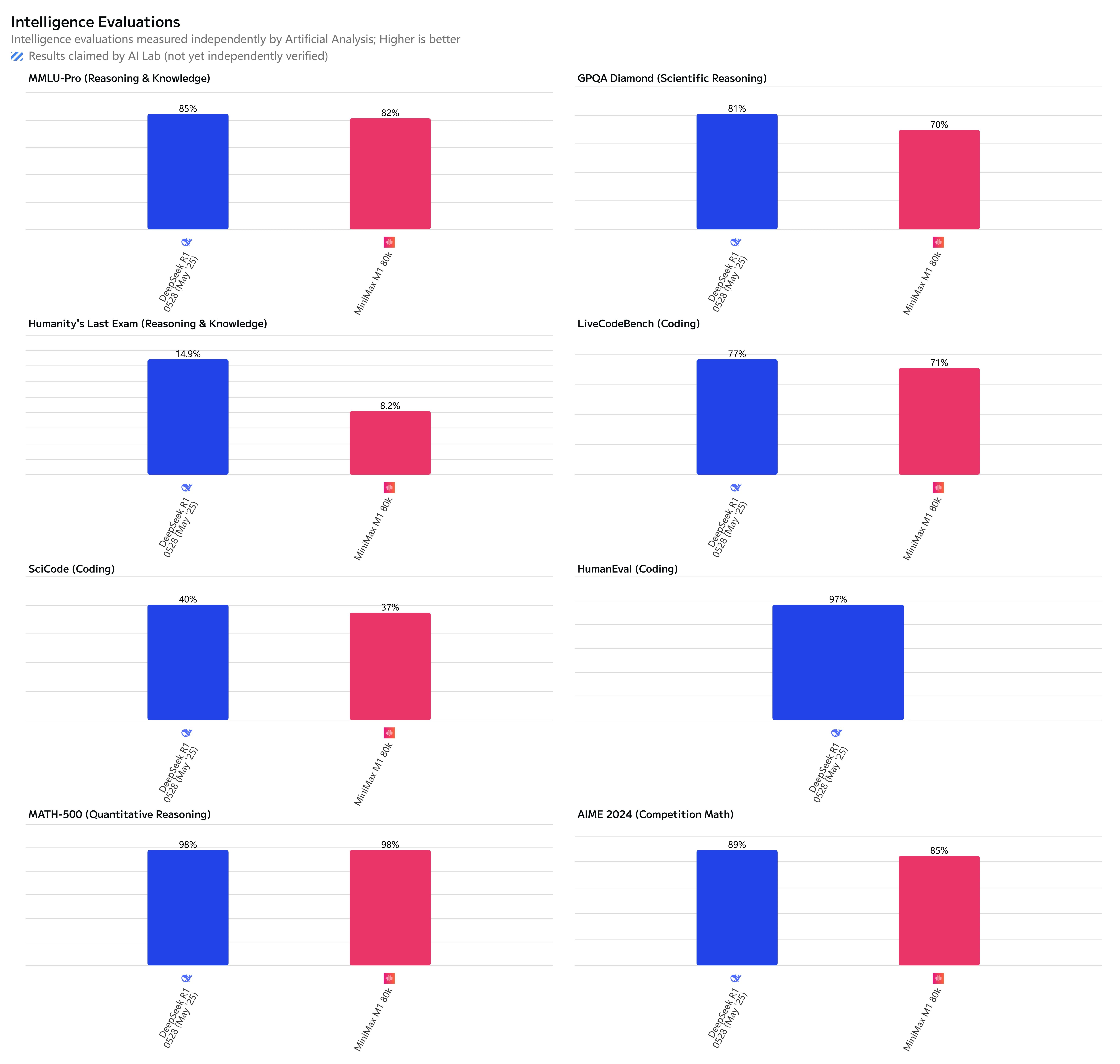
Minimax M1 vs DeepSeek R1 0528: Benchmark Comparison
DeepSeek R1 0528 demonstrates stronger capabilities and better versatility across multi-domain tasks, particularly excelling in scientific reasoning, complex knowledge application, and coding challenges. While Minimax M1 shows competitive performance in mathematical reasoning and offers superior long-context capabilities, it lags behind DeepSeek R1 0528 in most evaluation categories, suggesting DeepSeek R1 offers more robust general-purpose AI capabilities for diverse applications.
If you want to test it yourself, you can start a free trial on the Novita AI website. For a limited time, new users can claim **$10 in free credits**to explore and build with LLM API on Novita AI.
Try MiniMax M1 and DeepSeek R1 0528 Now!
Minimax M1 vs DeepSeek R1 0528: Hardware Requirements
MiniMax M1
GPU Memory Requirements:
- Minimum: 640GB VRAM
- Recommended: 1,128GB VRAM (8 x H200 SXM 141GB configuration) for optimal performance
DeepSeek R1 0528
GPU Memory Requirements:
- Minimum: 640GB VRAM
- Recommended: 1,128GB VRAM (8 x H200 SXM 141GB configuration) for optimal performance
MiniMax M1 vs DeepSeek R1 0528: Applications
MiniMax M1
Efficient Long-Context Processing:
- Supports long context window, enabling processing of extremely long documents, technical codebases, and multi-turn conversations in a single pass.
- Uses a hybrid Mixture-of-Experts (MoE) architecture with lightning attention for efficient inference, reducing computational cost to about 25% of comparable dense models.
- Ideal for enterprises handling large-scale knowledge bases, research papers, and agentic workflows requiring deep contextual understanding.
Cost-Effective Deployment:
- Available via Novita AI with competitive costs especially for ultra-long context usage($0.55/2.2 in/out MTokens).
Open-Source and Research Friendly:
- Fully open-weight model encouraging community fine-tuning and integration, supporting domain-specific customization in fields like legal, medical, and scientific research.
- Supports function calling and agentic AI tool use, enabling complex workflows and multi-step reasoning.
DeepSeek R1 0528
High-Precision Reasoning and Multitask Performance:
- A 685 billion parameter MoE model with a maximum context window of 128K tokens, suitable for complex reasoning, coding, and math tasks.
- Achieves strong benchmark results and top ranks on LiveCodeBench, reflecting advanced fine-tuning and reinforcement learning optimization.
- Supports chat, coding, summarization, and multi-domain NLP applications with emphasis on precision and robustness.
- Supports function calling and structured outputs, making it ideal for enterprise applications requiring precise data formatting and tool integration.
Enterprise-Grade Cloud and Local Deployment:
- Available via Novita AI with competitive pricing($0.7/2.5 in/out MTokens).
- Can be run locally on high-memory GPUs or CPU setups with offloading, though full 685B model inference typically requires multi-GPU clusters due to size and compute demands. For easier deployment, Novita AI offers Cloud GPU solutions with one-click DeepSeek R1 0528 deployment through our official template, eliminating the complexity of multi-GPU setup and infrastructure management.
- Offers distilled smaller variants for resource-constrained environments, balancing performance and accessibility.
Multilingual and Bilingual Focus:
- Primarily supports English and Chinese, targeting global and domestic enterprise applications.
- Focused on robust chat and reasoning tasks rather than ultra-long context or multimodal inputs.
Try DeepSeek R1 0528 Yourself!
Minimax M1 vs DeepSeek R1 0528: Tasks
Prompt:
Solve this step-by-step in under 200 words:
Problem:
A data scientist has a dataset with 10,000 user reviews. Each review has:
- Rating (1-5 stars)
- Text length (10-500 words)
- Category (electronics, books, clothing)
Given these statistics:
- Electronics: 3,500 reviews, average 3.2 stars, 180 words
- Books: 4,200 reviews, average 4.1 stars, 120 words
- Clothing: 2,300 reviews, average 2.8 stars, 95 words
Tasks:
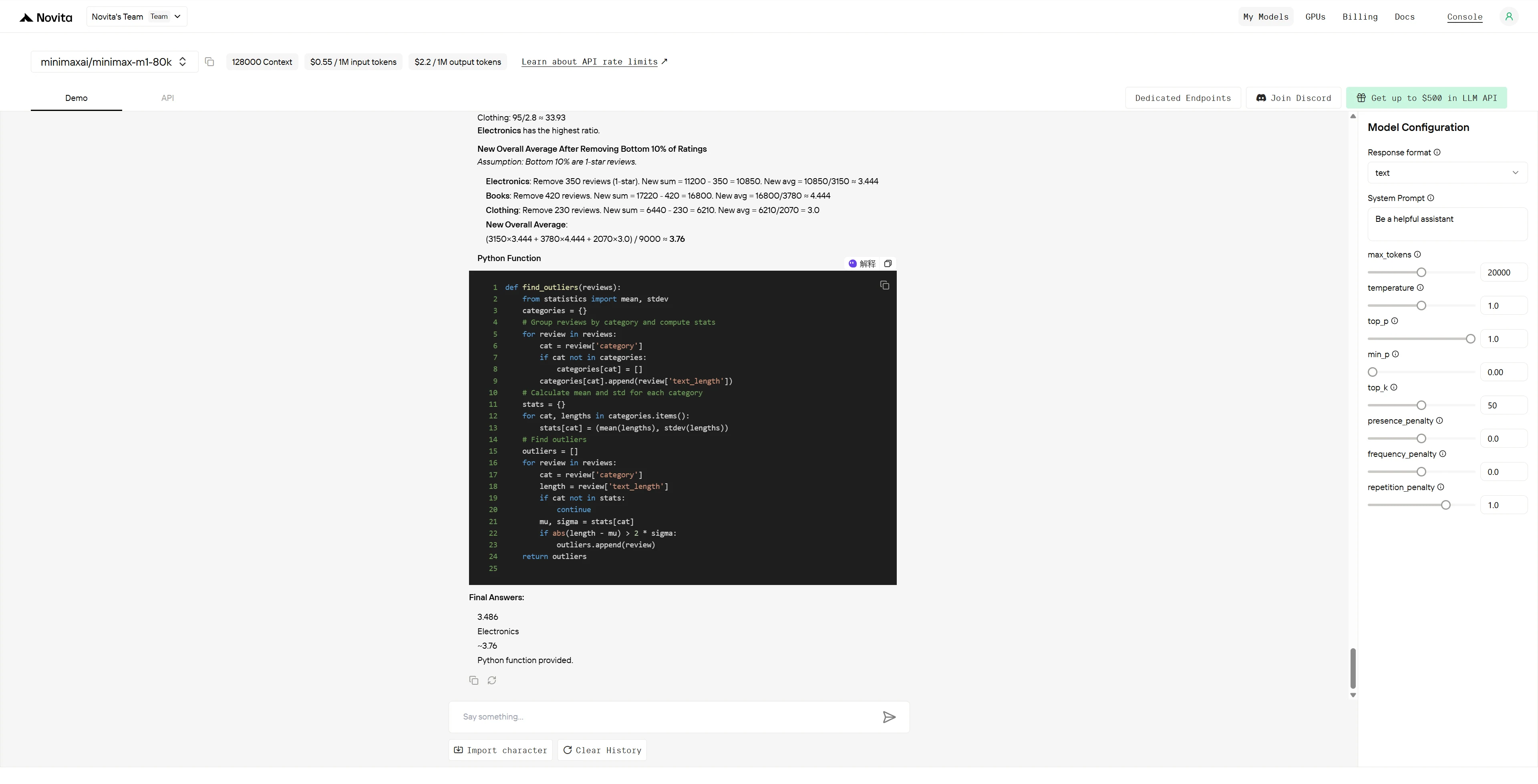
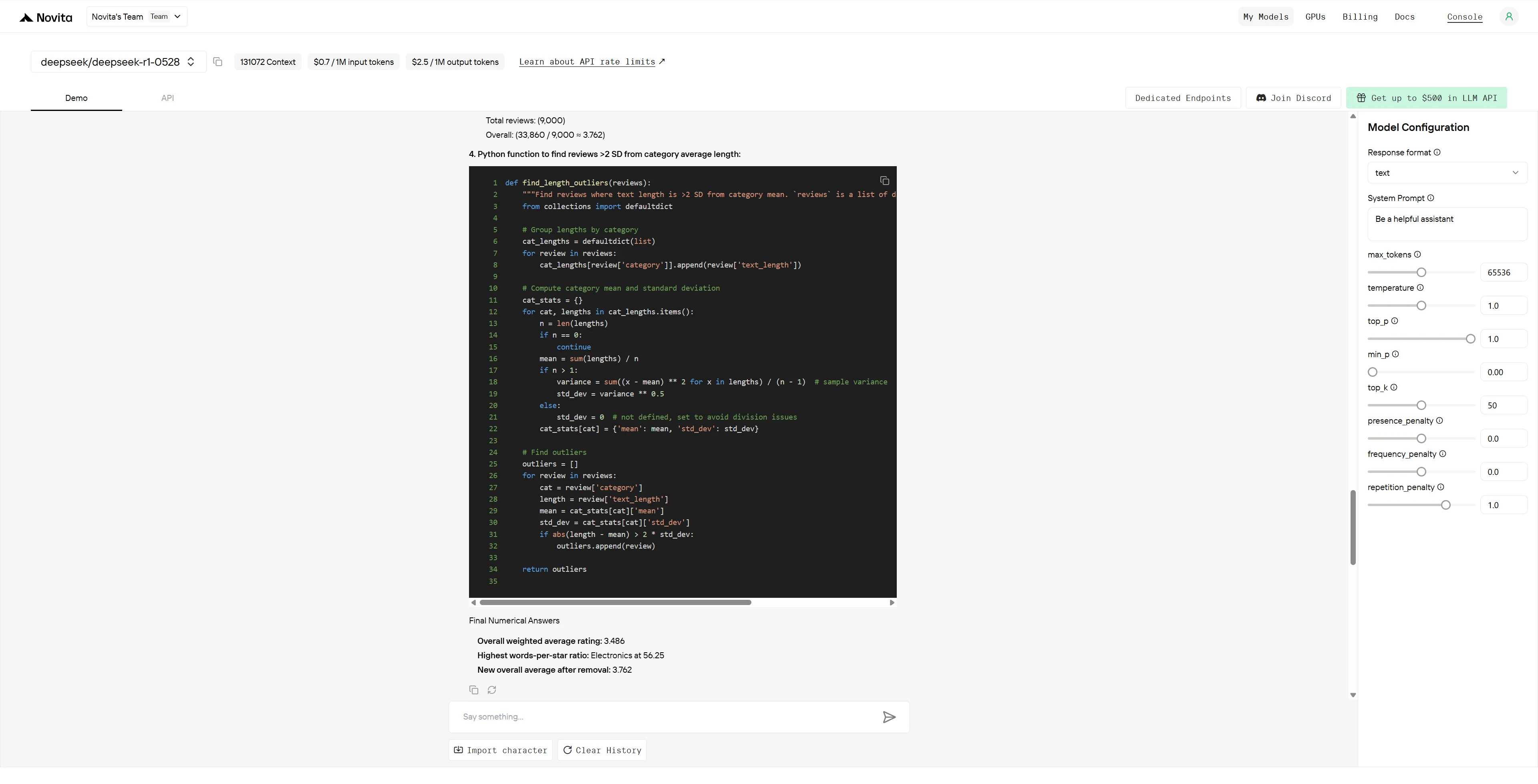
- Calculate the overall weighted average rating
- Which category has the highest words-per-star ratio?
- If you remove the bottom 10% of ratings from each category, what’s the new overall average?
- Write a Python function to find reviews that are >2 standard deviations from their category’s average length
Answer format:
- Show calculations clearly
- Provide the Python function
- State final numerical answers
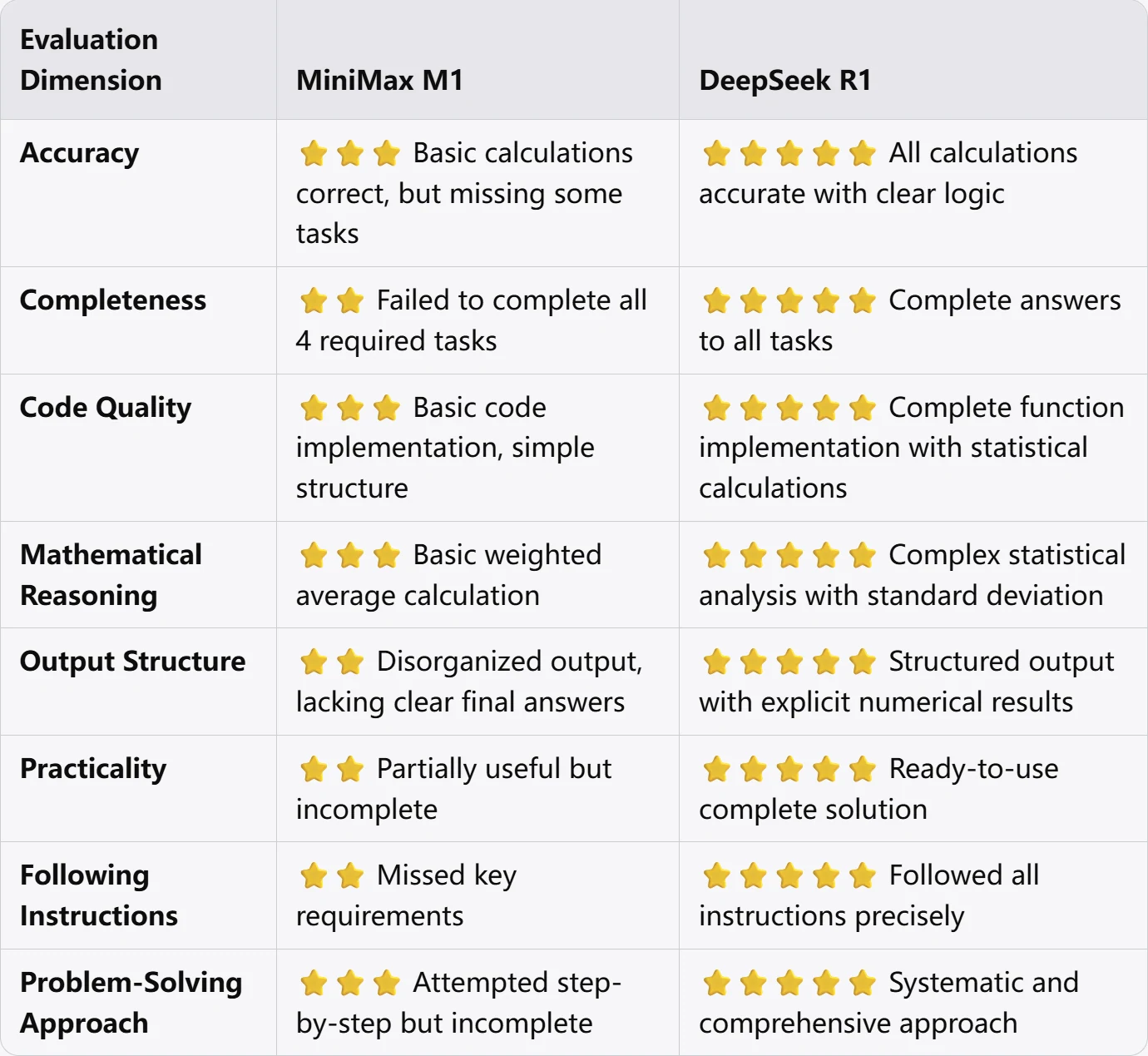
Minimax M1
DeepSeek R1 0528
Minimax M1 vs DeepSeek R1 0528
How to Access Minimax M1 and DeepSeek R1 0528 via Novita API?
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.
Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.
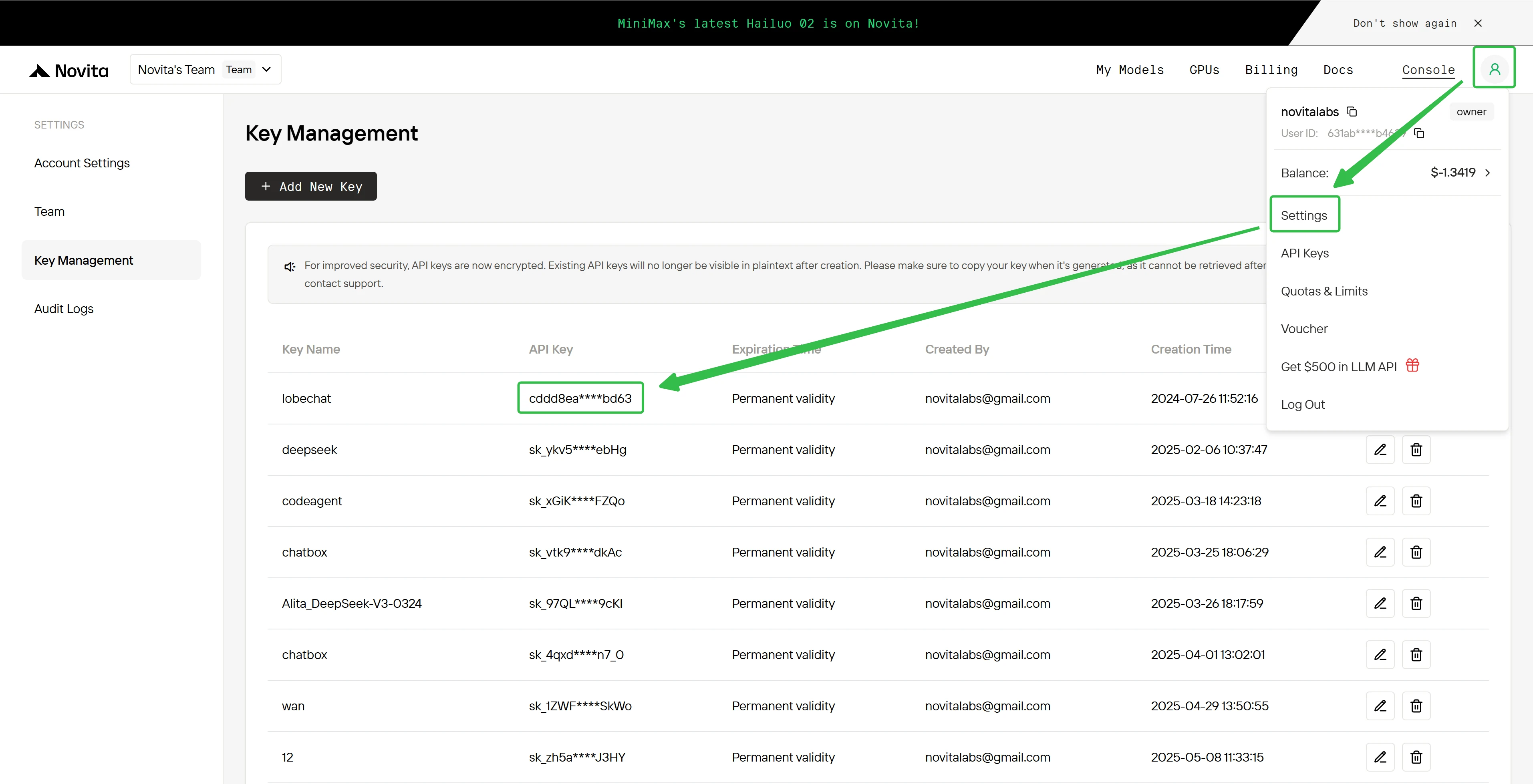
Step 5: Install the API
Install API using the package manager specific to your programming language.
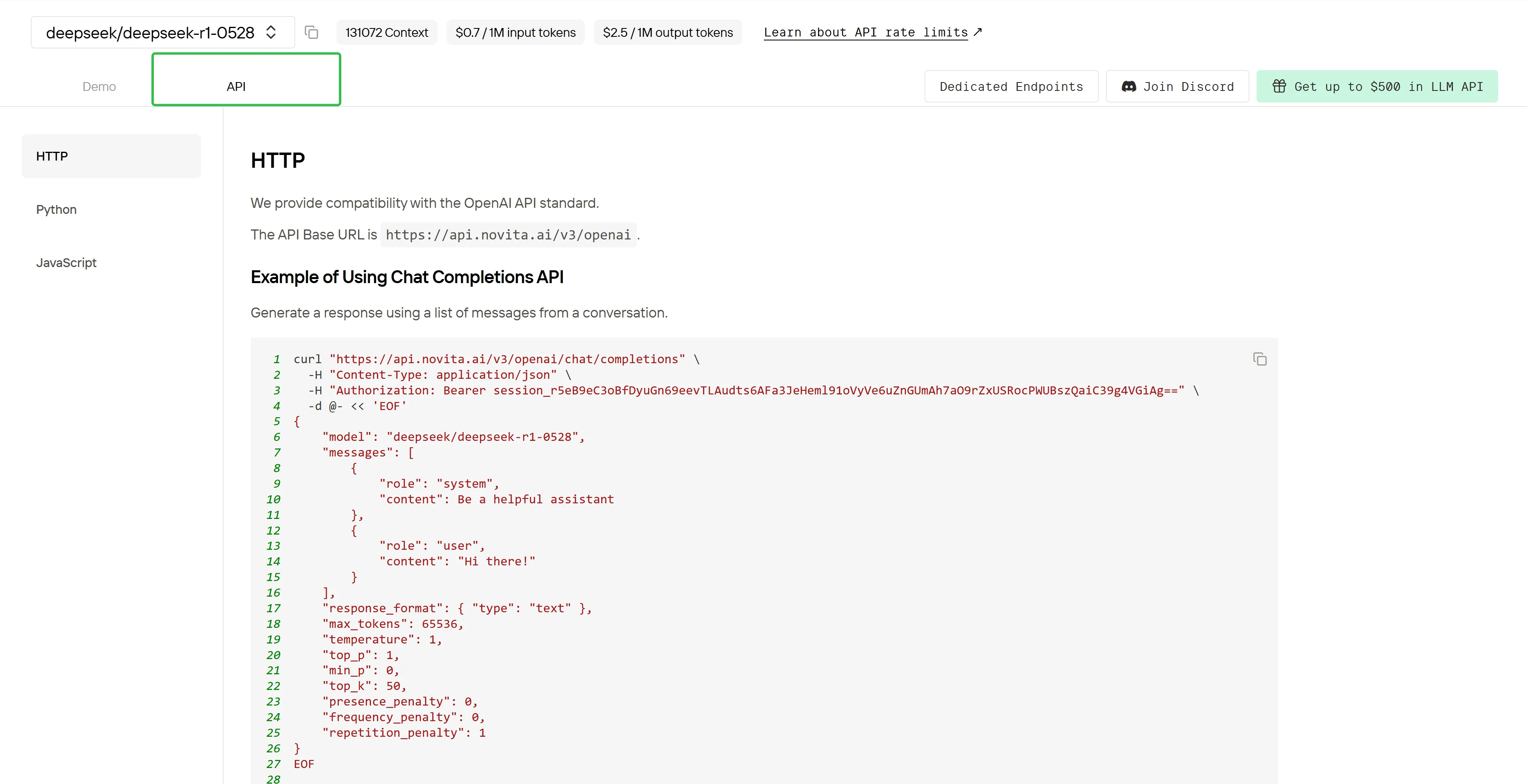
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_r5eB9eC3oBfDyuGn69eevTLAudts6AFa3JeHeml91oVyVe6uZnGUmAh7aO9rZxUSRocPWUBszQaiC39g4VGiAg==",
)
model = "deepseek/deepseek-r1-0528"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
MiniMax M1 excels at cost-effective long-context processing with its 1M token capacity and efficient architecture, making it ideal for organizations handling large documents or codebases on limited budgets. DeepSeek R1 0528 prioritizes precision and robust reasoning with superior mathematical capabilities, making it better suited for enterprise applications requiring high accuracy in complex analytical tasks.
Choose MiniMax M1 for long-document analysis and cost-sensitive deployments; choose DeepSeek R1 0528 for mission-critical reasoning, coding, and mathematical problem-solving where accuracy outweighs efficiency concerns.
Frequently Asked Questions
Is DeepSeek R1 0528 the best model?
DeepSeek R1 excels in mathematical reasoning and precision tasks, but “best” depends on your needs.For enterprise-grade accuracy in coding and analysis, DeepSeek R1 is superior.
Can I try MiniMax M1 and DeepSeek R1 0528 for free?
Yes! You can access free trials for both models via Novita AI’s platform and integrate them easily into your development workflow through the API.
Which model is better for coding tasks?
DeepSeek R1 generally performs better for complex coding and mathematical problems due to its robust reasoning capabilities. MiniMax M1 is more suitable for code analysis and documentation tasks requiring long-context understanding.
About Novita AI
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



