

주요 내용
Qwen 3 30B A3B는 thinking 과 non-thinking 모드 간의 원활한 전환을 지원하여 추론 및 일반 작업 전반에 걸쳐 뛰어난 유연성을 제공합니다. 추론 시 3B 파라미터만 활성화하여 QWQ 32B와 같은 밀집 모델에 비해 계산 비용을 획기적으로 줄입니다.
벤치마크 테스트(ArenaHard, AIME’24/25, Codeforces 등)에서 Qwen 3는 논리 중심 및 창의적 작업 모두에서 QWQ 32B를 일관되게 능가합니다.
Qwen 3는 다국어 지원(100개 이상 언어), 인간 중심 대화 및 에이전트 통합에서 뛰어납니다.
Qwen 3 30B A3B와 QWQ 32B 는 현대적인 희소 MoE와 전통적인 밀집 아키텍처 간의 대비를 보여줍니다. Qwen 3는 이중 모드 작동과 낮은 활성화 비용을 통해 고급 추론과 효율성을 제공합니다. QWQ 32B는 다양한 정밀도 수준을 지원하며 연구 및 로컬 배포를 위한 안정성과 호환성을 제공합니다.
Qwen 3 30B A3B와 QWQ 32B: 기본 소개
Qwen 3 30B A3B
Qwen에서
Qwen 3 30B A3B는 Qwen 235B A22B에서 증류되어 더 효율적인 형태로 강점을 계승합니다.
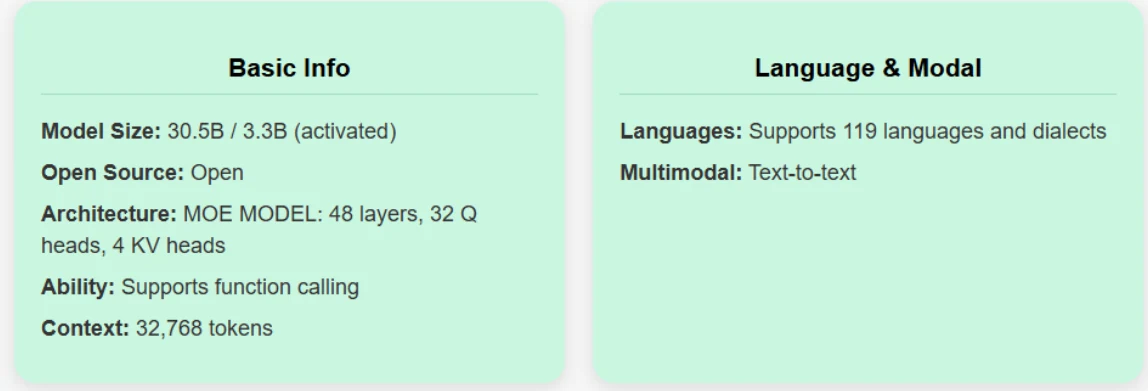
원활한 이중 모드 작동: 단일 모델 내에서 thinking mode(복잡한 추론, 수학, 코딩용)와 non-thinking mode(효율적인 일반 대화용) 간 전환을 독특하게 지원하여 다양한 시나리오에서 최적의 성능을 보장합니다.
고급 추론 능력: 논리, 수학, 코드 생성에서 상당한 개선을 제공하여 추론 모드의 QwQ와 비추론 모드의 Qwen2.5 Instruct를 모두 능가합니다.
인간 중심 대화 경험: 창작 글쓰기, 롤플레잉, 다중 턴 대화, 지시 따르기에서 뛰어나며 더 자연스럽고 매력적이며 몰입감 있는 사용자 경험을 제공합니다.
에이전트 통합 전문성: 생각 모드와 비생각 모드 모두에서 강력한 도구 사용 능력을 보여주며, 복잡한 에이전트 기반 작업에서 오픈소스 모델 중 선도적인 성능을 달성합니다.
강력한 다국어 지원: 100개 이상의 언어와 방언을 지원하며, 다국어 맥락에서 지시 따르기 및 번역에 높은 능숙도를 자랑합니다.
QWQ 32B

Qwen 3 30B A3B와 QWQ 32B: 벤치마크
| Task | Qwen3-30B-A3B | QwQ-32B |
| ArenaHard | 91 | 89.5 |
| AIME’24 | 80.4 | 79.5 |
| AIME’25 | 70.9 | 69.5 |
| LiveCodeBench | 62.6 | 62.7 |
| CodeForces | 1974 | 1982 |
| GPQA | 65.8 | 65.6 |
| LiveBench | 74.3 | 72 |
| BFCL | 69.1 | 66.4 |
| MultiIF | 72.2 | 68.3 |
직접 테스트해보고 싶다면 Novita AI 웹사이트에서 무료 체험을 시작할 수 있습니다.

지금 Qwen 3 30B A3B와 QWQ 32B 데모 사용해보기!
Qwen 3 30B A3B와 QWQ 32B: 하드웨어 요구 사항
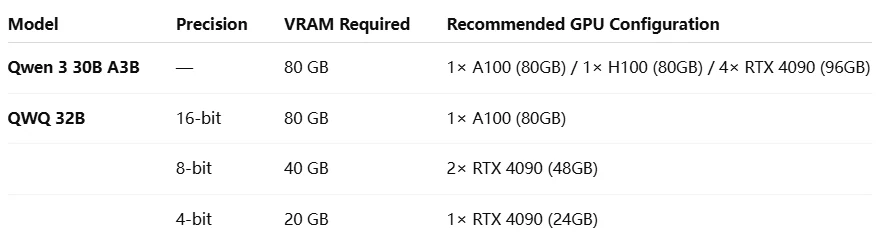
Qwen 3 30B A3B는 추론 중 3B 파라미터만 활성화하므로, 모든 파라미터가 매 계산에 참여해야 하는 QWQ 32B와 같은 전통적인 밀집 모델에 비해 계산 비용이 현저히 낮습니다.
Qwen 3 30B A3B와 QWQ 32B: 애플리케이션
Qwen 3 30B A3B
복잡한 추론 및 생성
수학, 코드, 논리 작업에 'thinking mode’를 사용하여 적합합니다.
대화형 에이전트
다중 턴 대화, 롤플레잉, 맥락 인식 상호작용에서 뛰어납니다.
다국어 애플리케이션
100개 이상의 언어를 지원하여 글로벌 챗봇 및 번역 시스템에 완벽합니다.
클라우드/API 배포
3B 활성 파라미터만 사용 → 낮은 계산 비용, SaaS/API 사용에 높은 효율성.
창의적 콘텐츠 제작
글쓰기, 스토리텔링, 지시 따르기에서 인간 선호도에 잘 맞춰져 있습니다.
QWQ 32B
밀집 추론 시나리오
모든 파라미터를 활성화하여 논리 중심 작업에서 일관된 출력에 적합합니다.
온프레미스 배포
A100/RTX 4090급 GPU에 안정적으로 접근할 수 있는 환경에서 잘 작동합니다.
오프라인 실험
다양한 양자화 모드(16/8/4비트)로 연구 및 테스트에 유연성을 제공합니다.
정적 Q&A 및 유틸리티
FAQ나 짧은 답변 고객 지원과 같은 고정 기능 작업에 가장 적합합니다.
Qwen 3 30B A3B와 QWQ 32B: 작업
프롬프트: 자전거를 타는 어린이의 SVG를 원합니다.

Qwen 3 30B A3B

QWQ 32B
Novita API를 통해 Qwen 3 30B A3B와 QWQ 32B에 액세스하는 방법
1단계: 로그인 및 모델 라이브러리 액세스
계정에 로그인하고 모델 라이브러리 버튼을 클릭합니다.

2단계: 모델 선택
사용 가능한 옵션을 탐색하고 필요에 맞는 모델을 선택합니다.
3단계: 무료 체험 시작
무료 체험을 시작하여 선택한 모델의 기능을 탐색합니다.
지금 Qwen 3 30B A3B와 QWQ 32B 사용해보기!
4단계: API 키 받기
API 인증을 위해 새 API 키를 제공해 드립니다. “설정” 페이지로 이동하여 이미지에 표시된 대로 API 키를 복사할 수 있습니다.

5단계: API 설치
프로그래밍 언어에 맞는 패키지 관리자를 사용하여 API를 설치합니다.
설치 후 필요한 라이브러리를 개발 환경에 임포트합니다. API 키로 API를 초기화하여 Novita AI LLM과 상호작용을 시작합니다. 다음은 Python 사용자를 위한 채팅 완성 API 사용 예시입니다.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwq-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
추론, 다국어 에이전트 및 확장 가능한 API 배포를 포함한 최첨단 AI 애플리케이션의 경우 **Qwen 3 30B A3B가 확실한 승자 ** 입니다. 밀집 모델 실험, 정적 QA 및 오프라인 양자화 테스트의 경우 QWQ 32B는 신뢰할 수 있는 선택 으로 남아 있습니다.
자주 묻는 질문
Qwen 3 30B A3B와 QWQ 32B의 주요 차이점은 무엇인가요?
QwQ 32B는 엔터프라이즈 배포에 적합한 대규모 고성능 모델인 반면, Qwen 2.5 7B는 가볍고 효율적이며 로컬 개발 및 연구 프로젝트에 완벽합니다.
어떤 모델이 배포 비용 효율성이 더 높나요?
Qwen 3 30B A3B는 추론 시 활성 컴퓨팅이 적기 때문에 비용 효율성이 훨씬 높습니다.
Qwen 3 30B A3B와 QWQ 32B를 무료로 사용해볼 수 있나요?
네! Novita AI 모델 라이브러리를 방문하여 무료 체험을 시작하고 API를 통해 두 모델 모두 액세스하세요.
*Novita AI *는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있는 AI 클라우드 플랫폼이며, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드를 제공합니다.



