

Wichtige Highlights
Qwen 3 30B A3B unterstützt nahtloses Umschalten zwischen Thinking- und Non-Thinking-Modus und bietet so überragende Flexibilität für Reasoning- und Allzweckaufgaben. Es aktiviert nur 3B Parameter zur Inferenz, was die Rechenkosten im Vergleich zu dichten Modellen wie QWQ 32B drastisch senkt.
In Benchmark-Tests (ArenaHard, AIME’24/25, Codeforces usw.) übertrifft Qwen 3 QWQ 32B sowohl bei logisch anspruchsvollen als auch bei kreativen Aufgaben durchweg.
Qwen 3 zeichnet sich durch mehrsprachige Unterstützung (100+ Sprachen), menschenzentrierte Dialoge und Agentenintegration aus.
Qwen 3 30B A3B vs QWQ 32B stellt einen Kontrast zwischen moderner spärlicher MoE und traditioneller dichter Architektur dar. Qwen 3 bietet fortschrittliches Reasoning und Effizienz durch Dual-Mode-Betrieb und niedrige Aktivierungskosten. QWQ 32B bietet Stabilität und Kompatibilität für Forschung und lokale Bereitstellung mit Unterstützung für verschiedene Präzisionsstufen.
Qwen 3 30B A3B VS QWQ 32B: Grundlegende Einführung
Qwen 3 30B A3B
Von Qwen
Qwen 3 30B A3B wird aus Qwen 235B A22B destilliert und erbt dessen Stärken in einer effizienteren Form.
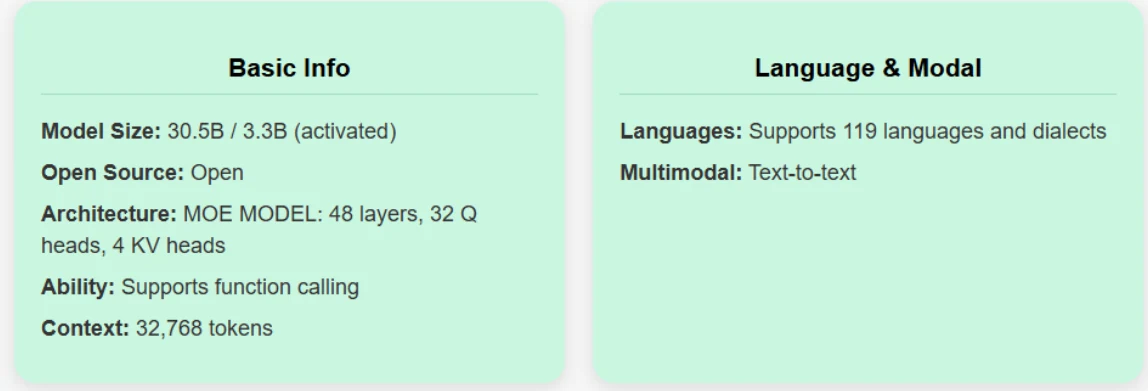
Nahtloser Dual-Mode-Betrieb: Unterstützt einzigartig das Umschalten zwischen Thinking-Modus (für komplexes Reasoning, Mathematik und Programmierung) und Non-Thinking-Modus (für effiziente allgemeine Dialoge) innerhalb eines einzigen Modells und gewährleistet so optimale Leistung in verschiedenen Szenarien.
Fortschrittliche Reasoning-Fähigkeiten: Liefert deutliche Verbesserungen bei Logik, Mathematik und Codegenerierung – übertrifft sowohl QwQ (im Thinking-Modus) als auch Qwen2.5 Instruct (im Non-Thinking-Modus).
Menschenzentrierte Gesprächserfahrung: Hervorragend in kreativem Schreiben, Rollenspielen, mehrrundigen Gesprächen und Befolgung von Anweisungen, bietet ein natürlicheres, ansprechenderes und immersiveres Benutzererlebnis.
Expertenwissen zur Agentenintegration: Zeigt starke Tool-Nutzungsfähigkeiten sowohl im Thinking- als auch im Non-Thinking-Modus und erreicht führende Leistung unter Open-Source-Modellen bei komplexen agentenbasierten Aufgaben.
Robuste mehrsprachige Unterstützung: Deckt über 100 Sprachen und Dialekte ab, mit hoher Kompetenz bei Anweisungsbefolgung und Übersetzung in mehrsprachigen Kontexten.
QWQ 32B

Qwen 3 30B A3B VS QWQ 32B: Benchmark
| Aufgabe | Qwen3-30B-A3B | QwQ-32B |
| ArenaHard | 91 | 89.5 |
| AIME’24 | 80.4 | 79.5 |
| AIME’25 | 70.9 | 69.5 |
| LiveCodeBench | 62.6 | 62.7 |
| CodeForces | 1974 | 1982 |
| GPQA | 65.8 | 65.6 |
| LiveBench | 74.3 | 72 |
| BFCL | 69.1 | 66.4 |
| MultiIF | 72.2 | 68.3 |
Wenn Sie es selbst testen möchten, können Sie eine kostenlose Testversion auf der Novita AI-Website starten.

Jetzt Qwen 3 30B A3B und QWQ 32B Demo testen!
Qwen 3 30B A3B VS QWQ 32B: Hardware-Anforderungen
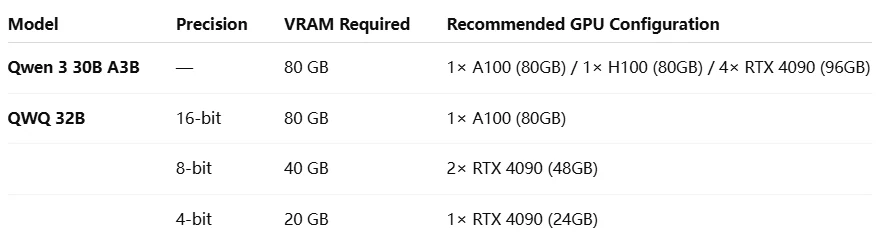
Qwen 3 30B A3B aktiviert während der Inferenz nur 3B Parameter, was bedeutet, dass seine Rechenkosten deutlich niedriger sind als bei traditionellen dichten Modellen wie QWQ 32B, die bei jeder Berechnung alle Parameter einbeziehen müssen.
Qwen 3 30B A3B VS QWQ 32B: Anwendungen
Qwen 3 30B A3B
Komplexes Reasoning & Generierung
Ideal für Mathematik, Code und Logikaufgaben mit dem „Thinking-Modus“.
Gesprächsagenten
Hervorragend in mehrrundigen Dialogen, Rollenspielen und kontextbewussten Interaktionen.
Mehrsprachige Anwendungen
Unterstützt 100+ Sprachen, perfekt für globale Chatbots und Übersetzungssysteme.
Cloud-/API-Bereitstellung
Nur 3B aktive Parameter → niedrige Rechenkosten, hohe Effizienz für SaaS/API-Nutzung.
Kreative Inhaltserstellung
Gut abgestimmt auf menschliche Präferenzen beim Schreiben, Geschichtenerzählen und Befolgen von Anweisungen.
QWQ 32B
Dichte Inferenzszenarien
Aktiviert alle Parameter – geeignet für konsistente Ausgaben bei logisch anspruchsvollen Aufgaben.
Lokale Bereitstellungen
Funktioniert gut in Umgebungen mit stabilem Zugang zu A100/RTX 4090-GPUs.
Offline-Experimente
Mehrere Quantisierungsmodi (16/8/4-Bit) ermöglichen Flexibilität für Forschung und Tests.
Statische Q&A und Dienstprogramme
Am besten geeignet für festgelegte Funktionen wie FAQs oder Kurzantwort-Kundensupport.
Qwen 3 30B A3B VS QWQ 32B: Aufgaben
Prompts: Ich möchte ein SVG eines Kindes, das Fahrrad fährt.

Qwen 3 30B A3B

QWQ 32B
Wie greife ich über die Novita-API auf Qwen 3 30B A3B und QWQ 32B zu?
Schritt 1: Einloggen und Modellbibliothek aufrufen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.
Schritt 3: Kostenlose Testversion starten
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Jetzt Qwen 3 30B A3B und QWQ 32B testen!
Schritt 4: API-Schlüssel abrufen
Zur Authentifizierung mit der API erhalten Sie von uns einen neuen API-Schlüssel. Rufen Sie die Seite „Einstellungen“ auf und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: API installieren
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwq-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Für hochmoderne KI-Anwendungen mit Reasoning, mehrsprachigen Agenten und skalierbaren API-Bereitstellungen ist Qwen 3 30B A3B der klare Gewinner. Für Experimente mit dichten Modellen, statische Q&A und Offline-Quantisierungstests bleibt QWQ 32B eine zuverlässige Wahl.
Häufig gestellte Fragen
Was ist der Hauptunterschied zwischen Qwen 3 30B A3B und QWQ 32B?
QwQ 32B ist ein groß angelegtes, leistungsstarkes Modell, das für Unternehmensbereitstellungen geeignet ist, während Qwen 2.5 7B leichtgewichtig und effizient ist und sich perfekt für lokale Entwicklung und Forschungsprojekte eignet.
Welches Modell ist kosteneffizienter für die Bereitstellung?
Qwen 3 30B A3B ist aufgrund seines geringeren aktiven Rechenaufwands während der Inferenz deutlich kosteneffizienter.
Kann ich Qwen 3 30B A3B und QWQ 32B kostenlos testen?
Ja! Besuchen Sie die Novita AI Modellbibliothek, starten Sie eine kostenlose Testversion und greifen Sie über die API auf beide Modelle zu.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitzustellen.



