

主なハイライト
Qwen 3 30B A3B は、思考モードと非思考モードのシームレスな切り替えをサポートし、推論タスクと汎用タスクの両方で優れた柔軟性を発揮します。推論時にアクティブになるパラメータはわずか 3B であり、QWQ 32B のような高密度モデルと比較して計算コストを大幅に削減します。
ベンチマークテスト(ArenaHard、AIME’24/25、Codeforces など)では、Qwen 3 は論理重視のタスクとクリエイティブなタスクの両方で QWQ 32B を一貫して上回っています。
Qwen 3 は、多言語サポート(100 以上の言語)、人間の好みに合わせた対話、エージェント統合に優れています。
Qwen 3 30B A3B と QWQ 32B は、現代のスパース MoE と従来の高密度アーキテクチャの対比を表しています。Qwen 3 は、デュアルモード動作と低アクティベーションコストにより、高度な推論と効率性を実現します。QWQ 32B は、研究やローカル展開に安定性と互換性を提供し、さまざまな精度レベルをサポートします。
Qwen 3 30B A3B VS QWQ 32B:基本紹介
Qwen 3 30B A3B
Qwen より
Qwen 3 30B A3B は Qwen 235B A22B から蒸留されており、より効率的な形でその強みを受け継いでいます。
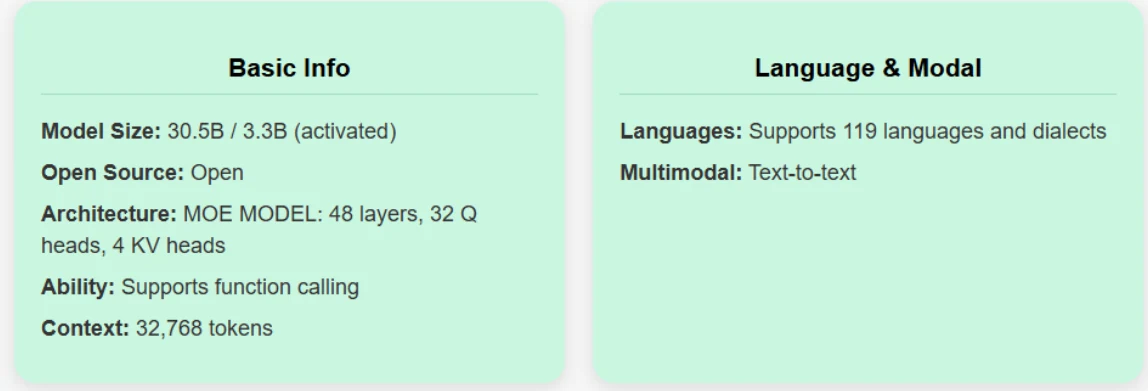
シームレスなデュアルモード操作: 単一モデル内で 思考モード(複雑な推論、数学、コーディング用)と 非思考モード(効率的な汎用対話用)の切り替えを独自にサポートし、多様なシナリオで最適なパフォーマンスを保証します。
高度な推論能力: 論理、数学、コード生成において大幅な改善を実現し、QwQ(思考モード)と Qwen2.5 Instruct(非思考モード)の両方を上回ります。
人間の好みに合わせた対話体験: クリエイティブライティング、ロールプレイング、マルチターン会話、指示追従に優れ、より自然で魅力的、没入感のあるユーザー体験を提供します。
エージェント統合の専門知識: 思考モードと非思考モードの両方で強力なツール使用能力を示し、複雑なエージェントベースのタスクにおいてオープンソースモデルの中でトップクラスのパフォーマンスを達成します。
堅牢な多言語サポート: 100 以上の言語と方言をカバーし、多言語コンテキストでの指示追従と翻訳に高い習熟度を発揮します。
QWQ 32B

Qwen 3 30B A3B VS QWQ 32B:ベンチマーク
| タスク | Qwen3-30B-A3B | QwQ-32B |
| ArenaHard | 91 | 89.5 |
| AIME’24 | 80.4 | 79.5 |
| AIME’25 | 70.9 | 69.5 |
| LiveCodeBench | 62.6 | 62.7 |
| CodeForces | 1974 | 1982 |
| GPQA | 65.8 | 65.6 |
| LiveBench | 74.3 | 72 |
| BFCL | 69.1 | 66.4 |
| MultiIF | 72.2 | 68.3 |
自分でテストしたい場合は、Novita AI ウェブサイトで無料トライアルを開始できます。

Qwen 3 30B A3B と QWQ 32B のデモを今すぐ試す!
Qwen 3 30B A3B VS QWQ 32B:ハードウェア要件
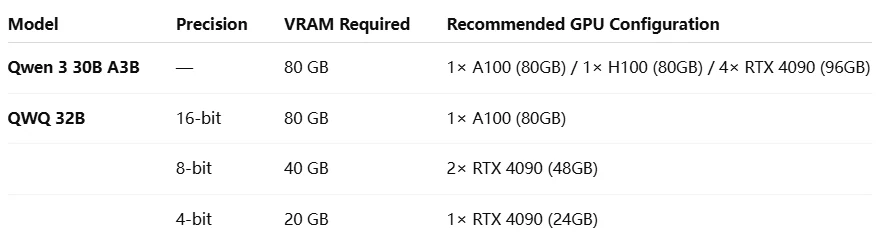
Qwen 3 30B A3B は推論中に 3B パラメータのみをアクティブにするため、その計算コストは、すべてのパラメータがすべての計算に関与する必要がある QWQ 32B のような従来の高密度モデルよりも大幅に低くなります。
Qwen 3 30B A3B VS QWQ 32B:アプリケーション
Qwen 3 30B A3B
複雑な推論と生成 「思考モード」を使用した数学、コード、論理タスクに最適です。
会話エージェント マルチターン対話、ロールプレイング、コンテキスト認識型インタラクションに優れています。
多言語アプリケーション 100 以上の言語をサポートし、グローバルなチャットボットや翻訳システムに最適です。
クラウド / API デプロイメント アクティブパラメータはわずか 3B → 低計算コスト、SaaS / API 使用時の高効率。
クリエイティブコンテンツ作成 ライティング、ストーリーテリング、指示追従において人間の好みにしっかりと適合しています。
QWQ 32B
高密度推論シナリオ すべてのパラメータをアクティブ化し、論理重視のタスクで一貫した出力に適しています。
オンプレミスデプロイメント A100 / RTX 4090 レベルの GPU に安定してアクセスできる環境でうまく機能します。
オフライン実験 複数の量子化モード(16 / 8 / 4 ビット)により、研究とテストに柔軟性をもたらします。
静的 Q&A とユーティリティ FAQ や短答形式のカスタマーサポートなど、固定機能タスクに最適です。
Qwen 3 30B A3B VS QWQ 32B:タスク
プロンプト:自転車に乗っている子供の SVG が欲しい。

Qwen 3 30B A3B

QWQ 32B
Novita API 経由で Qwen 3 30B A3B と QWQ 32B にアクセスする方法
ステップ 1:ログインしてモデルライブラリにアクセス
アカウントにログインし、Model Library ボタンをクリックします。

ステップ 2:モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。
ステップ 3:無料トライアルを開始
無料トライアルを開始して、選択したモデルの機能を試します。
Qwen 3 30B A3B と QWQ 32B を今すぐ試す!
ステップ 4:API キーを取得
API で認証するために、新しい API キーを提供します。Settings ページに移動し、画像に示されているように API キーをコピーします。

ステップ 5:API をインストール
使用しているプログラミング言語に固有のパッケージマネージャーを使用して API をインストールします。
インストール後、必要なライブラリを開発環境にインポートします。API キーを使用して API を初期化し、Novita AI LLM とのやり取りを開始します。以下は、Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwq-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
推論、多言語エージェント、スケーラブルな API デプロイメントを含む最先端の AI アプリケーションには、**Qwen 3 30B A3B が明らかな勝者です **。高密度モデルの実験、静的 QA、オフライン量子化テストには、QWQ 32B は依然として信頼できる選択肢です。
よくある質問
Qwen 3 30B A3B と QWQ 32B の主な違いは何ですか?
QwQ 32B はエンタープライズデプロイメントに適した大規模で高性能なモデルですが、Qwen 2.5 7B は軽量で効率的であり、ローカル開発や研究プロジェクトに最適です。
デプロイメントにおいてコスト効率が良いのはどちらのモデルですか?
Qwen 3 30B A3B は、推論時のアクティブな計算量が少ないため、はるかにコスト効率が優れています。
Qwen 3 30B A3B と QWQ 32B を無料で試せますか?
はい!Novita AI モデルライブラリにアクセスし、無料トライアルを開始して、API 経由で両方のモデルにアクセスしてください。
Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできるようにすると同時に、スケーリングのための手頃で信頼性の高い GPU クラウドを提供する AI クラウドプラットフォームです。



