

主なハイライト
Qwen3-Coder-480B-A35B-Instruct: コーディングに特化したモデル。262Kトークンのコンテキスト長を持ち、プログラミングタスクにおけるアルゴリズムの優位性とベンチマークパフォーマンスに最適化されています。
Claude 4 Sonnet: バランスの取れた機能を持つ高度な会話AI。自然な対話と多様な領域での包括的な支援に最適化されています。
Novita AIは安定したAPIサービスを提供するだけでなく、非常にコストパフォーマンスの高い価格設定も行っています。例えば、Qwen3-Coder-480B-A35B-Instruct は入力100万トークンあたり$0.95、出力100万トークンあたり$5です。
モデルの基本紹介
Qwen3-Coder-480B-A35B-Instruct
Qwen3-Coder-480B-A35B-Instructは、2025年7月にAlibabaがリリースした最先端の大規模因果言語モデルで、主にエージェンティックコーディングおよびソフトウェア開発タスク向けに設計されています。Mixture-of-Experts(MoE)アーキテクチャを採用し、総パラメータ数4800億、フォワードパスあたりのアクティブパラメータは350億で、モデル容量と推論効率のバランスを実現しています。このモデルはネイティブで256Kトークンの非常に長いコンテキストをサポートし、オープンモデルの中で最先端のパフォーマンスを達成しています。
主な特徴とアーキテクチャ
- タイプ: 因果言語モデル
- トレーニングステージ: 事前学習 & 事後学習
- パラメータ数: 合計480B、アクティブ35B
- レイヤー数: 62
- アテンションヘッド数(GQA): Q用96、KV用8
- エキスパート数: 160
- アクティブエキスパート数: 8
- コンテキスト長: 262,144(ネイティブ)
Claude 4 Sonnet
Claude 4 SonnetはAnthropicの中規模言語モデルで、コンテンツ生成、サポートボット、日常的な開発タスクなど、幅広いアプリケーションにおいてパフォーマンスとコスト効率のバランスを取るために設計されています。Claude 4 Sonnetは、その前身であるSonnet 3.7の能力を大幅に強化し、コーディングと推論の両方のタスクで、精度と制御性が向上しています。
主な特徴とアーキテクチャ
- アーキテクチャ: Dense Transformerモデル(非MoE)、大規模な密なパラメータ化を使用
- トレーニングの焦点: 安全性、アライメント、操縦性を重視し、汎用の自然言語理解と生成を両立
- 能力: 会話AI、多段階推論、要約、コーディング支援、倫理的認識に優れる
- 言語: 主に英語に最適化されているが、多言語対応も強力
- コンテキスト長: 200kトークン
Qwen3-Coder-480B-A35B-Instruct と Claude 4 Sonnet のベンチマーク比較
1. 応用知能ベンチマーク

2. コンテキストウィンドウ
Qwen3-Coder-480B-A35B-Instruct: 262k トークン
Claude 4 Sonnet: 200k トークン
3. API価格
Qwen3-Coder-480B-A35B-Instruct: 入力/出力 100万トークンあたり $0.95 / $5
Claude 4 Sonnet: 入力/出力 100万トークンあたり $3 / $15
今すぐ Qwen3-Coder-480B-A35B-Instruct を試す!
Qwen3-Coder-480B-A35B-Instruct と Claude 4 Sonnet の応用スキルテスト
1. コーディングタスク: 堅牢な区間集合クラス
説明
以下の操作をサポートする IntervalSet というクラスを実装してください。
add(interval: List[int])
区間[start, end]を集合に追加します。重複または隣接する区間は自動的にマージされます。remove(interval: List[int])
[start, end]と重複する集合内の区間の部分をすべて削除します。これにより、区間が2つの分離した区間に分割される場合があります。contains(point: int) -> bool
pointが現在の集合内のいずれかの区間に含まれている場合はTrue、それ以外はFalseを返します。to_list() -> List[List[int]]
現在の区間を[start, end]ペアのリストとして昇順で返します。
追加要件
- すべての操作は、最悪の場合でも O(log n) 以上であること(n = 区間数)。
end < startとなる無効な入力は無視するように堅牢に処理すること。- コードは40行を超えないこと(空白やコメントは除く。絶対に必要な場合は若干の延長可。ただし簡潔で核となるロジックに集中すること)。
評価基準
- アルゴリズムの正確性 (40%):
すべてのケース(マージ、分割、クエリ、無効入力)を正しく処理できること。 - データ構造の選択と計算量 (30%):
効率的なアプローチ(例: 平衡二分探索木、bisect、SortedList など)を用いて O(log n) 操作を保証すること。 - コード品質 (20%):
明確で読みやすい実装、適切な変数命名、エッジケースの堅牢な処理。 - 実装の完全性 (10%):
すべてのメソッドが仕様通りに動作し、欠落しているヘルパーロジックがないこと。
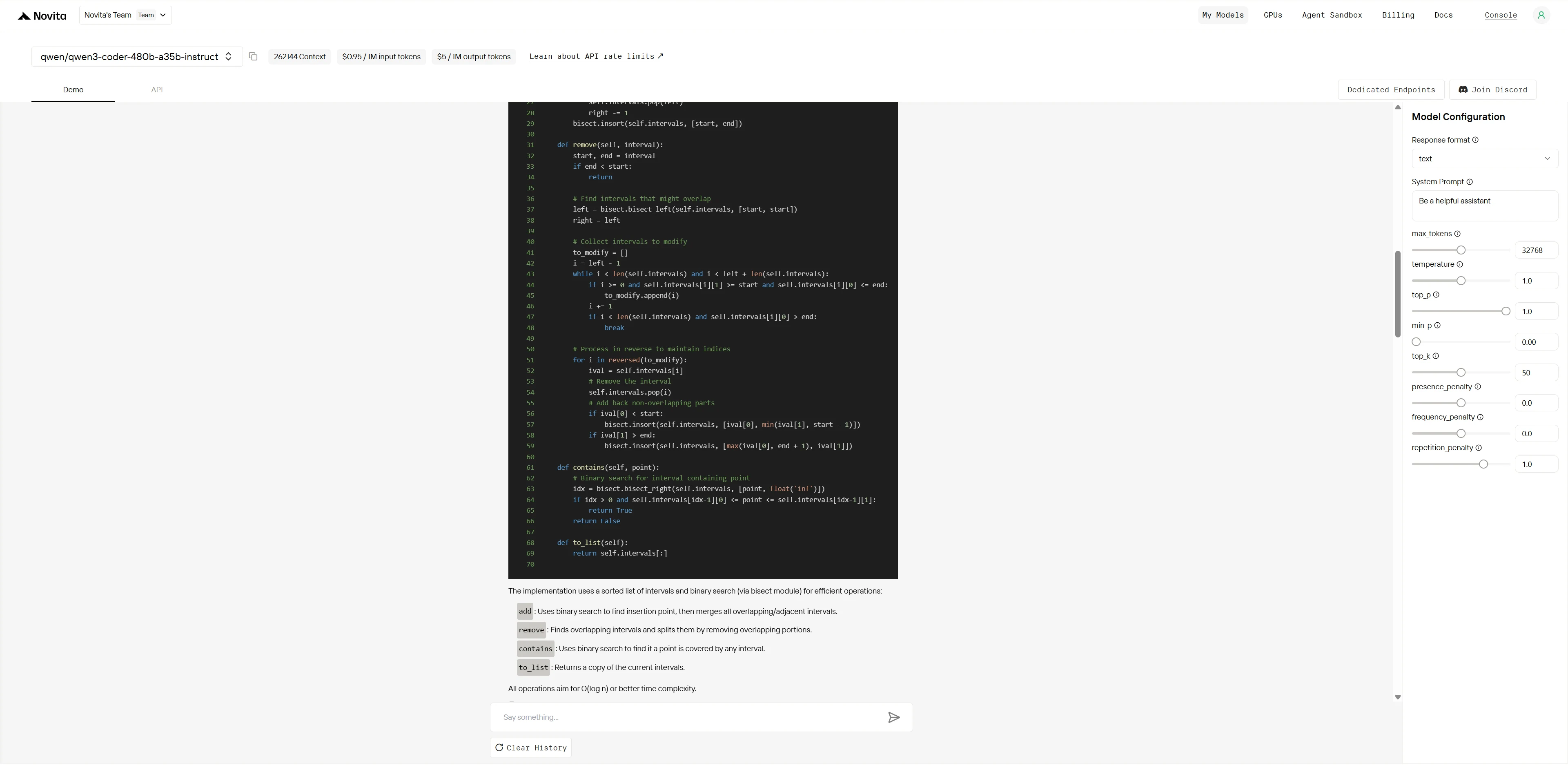
Qwen3-Coder-480B-A35B-Instruct
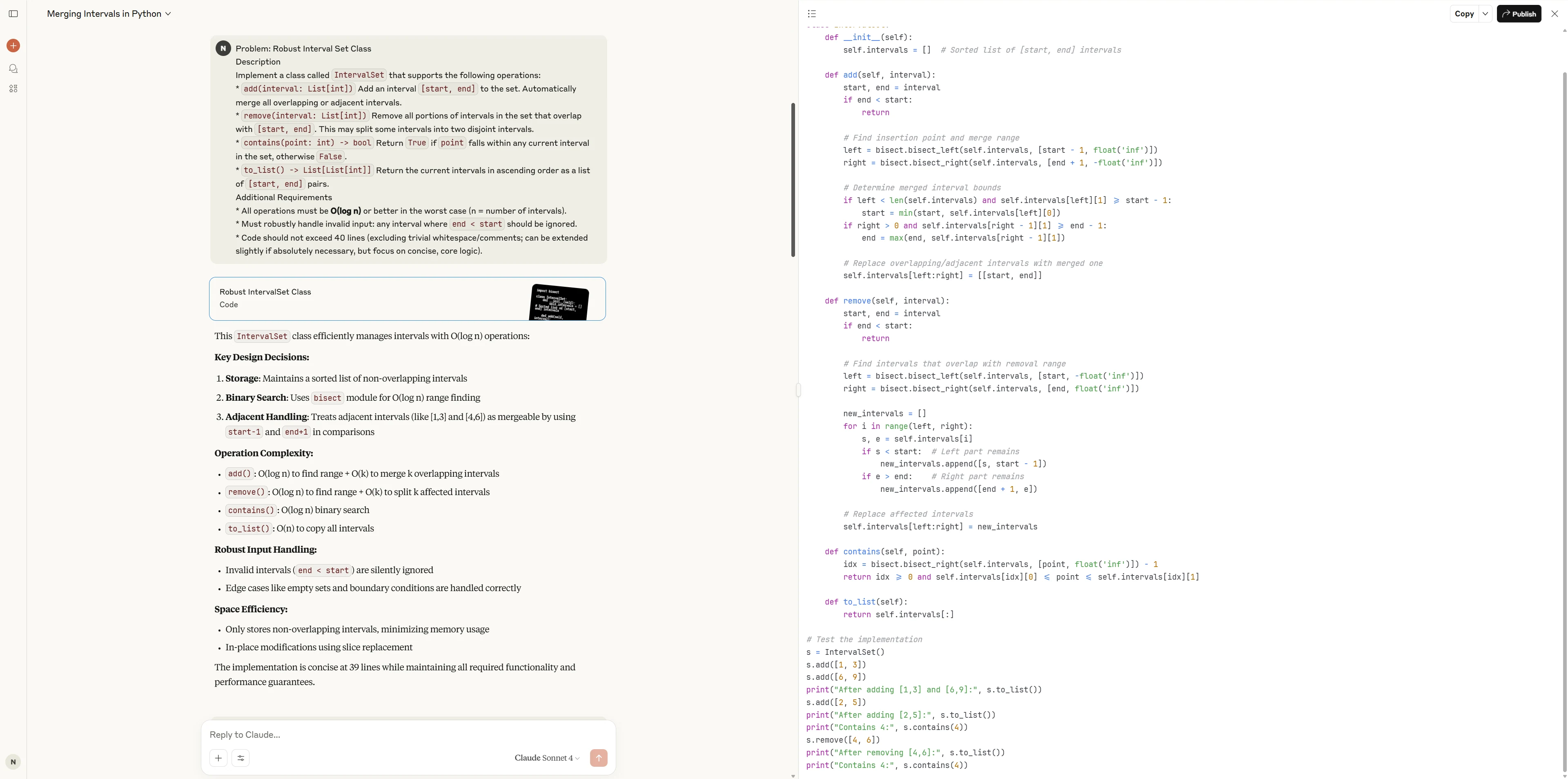
Claude 4 Sonnet
評価サマリー
| モデル | 正確性 | 計算量 | コード品質 | 完全性 | 合計 |
|---|---|---|---|---|---|
| Claude 4 Sonnet | 39 | 30 | 20 | 10 | 99 |
| Qwen3-Coder-480B | 40 | 30 | 19 | 9 | 98 |
Claude 4 Sonnet は、標準ライブラリを活用したクリーンで高度にプロフェッショナルな実装を提供し、正確性と効率性を両立しています。コードはエレガントでモジュール化されており、包括的なテストカバレッジも備えているため、本番環境や信頼性・保守性が求められるシナリオに適しています。
Qwen3-Coder-480B は、核となるロジックを明確に示す、率直で実用的なソリューションを提供します。やや冗長で高度なPython構造に欠ける部分もありますが、明示性とエッジケースの堅牢な処理を重視しており、日常的なエンジニアリングニーズのほとんどに対して高い信頼性を発揮します。
2. デバッグタスク: 区間木のマージバグ
以下に、区間のマージとクエリを行う 区間木(Interval Tree) の(バグのある)実装を示します。このコードは、区間の追加とポイントが任意の区間に含まれるかどうかのチェックをサポートすることになっていますが、誤った結果を返したり、クラッシュしたりすることがあります。
あなたのタスク:
- コード内の すべてのバグ を特定してください(最初に見つけたものだけではありません)。
- 各バグについて、なぜそれがバグなのか、どのように修正するかを説明してください。
- 修正版のコードを提供してください。
バグのあるコード
class Node:
def __init__(self, start, end):
self.start = start
self.end = end
self.left = None
self.right = None
self.max_end = end
class IntervalTree:
def __init__(self):
self.root = None
def insert(self, node, start, end):
if node is None:
return Node(start, end)
if end < node.start:
node.left = self.insert(node.left, start, end)
elif start > node.end:
node.right = self.insert(node.right, start, end)
else:
# 重複する区間をマージ
node.start = min(node.start, start)
node.end = max(node.end, end)
# 子もマージする(ただしバグあり!)
node.left = self.insert(node.left, node.start, node.end)
node.right = self.insert(node.right, node.start, node.end)
node.max_end = max(node.max_end, end)
return node
def add(self, start, end):
self.root = self.insert(self.root, start, end)
def contains(self, node, point):
if node is None:
return False
if node.start <= point <= node.end:
return True
if node.left and point <= node.left.max_end:
return self.contains(node.left, point)
return self.contains(node.right, point)
評価基準
- バグの特定 (40%): 論理バグや構造バグをすべて(最初だけではなく!)見つけること。微妙なバグも含む。
- バグの説明と修正 (30%): 各バグに対して明確で正確な説明と修正方法を示すこと。
- 修正版コード (20%): 完全に修正された、クリーンで読みやすいコードを提供すること。
- 完全性 (10%): すべてのメソッドが仕様通りに動作し、エッジケースに対して堅牢であること。
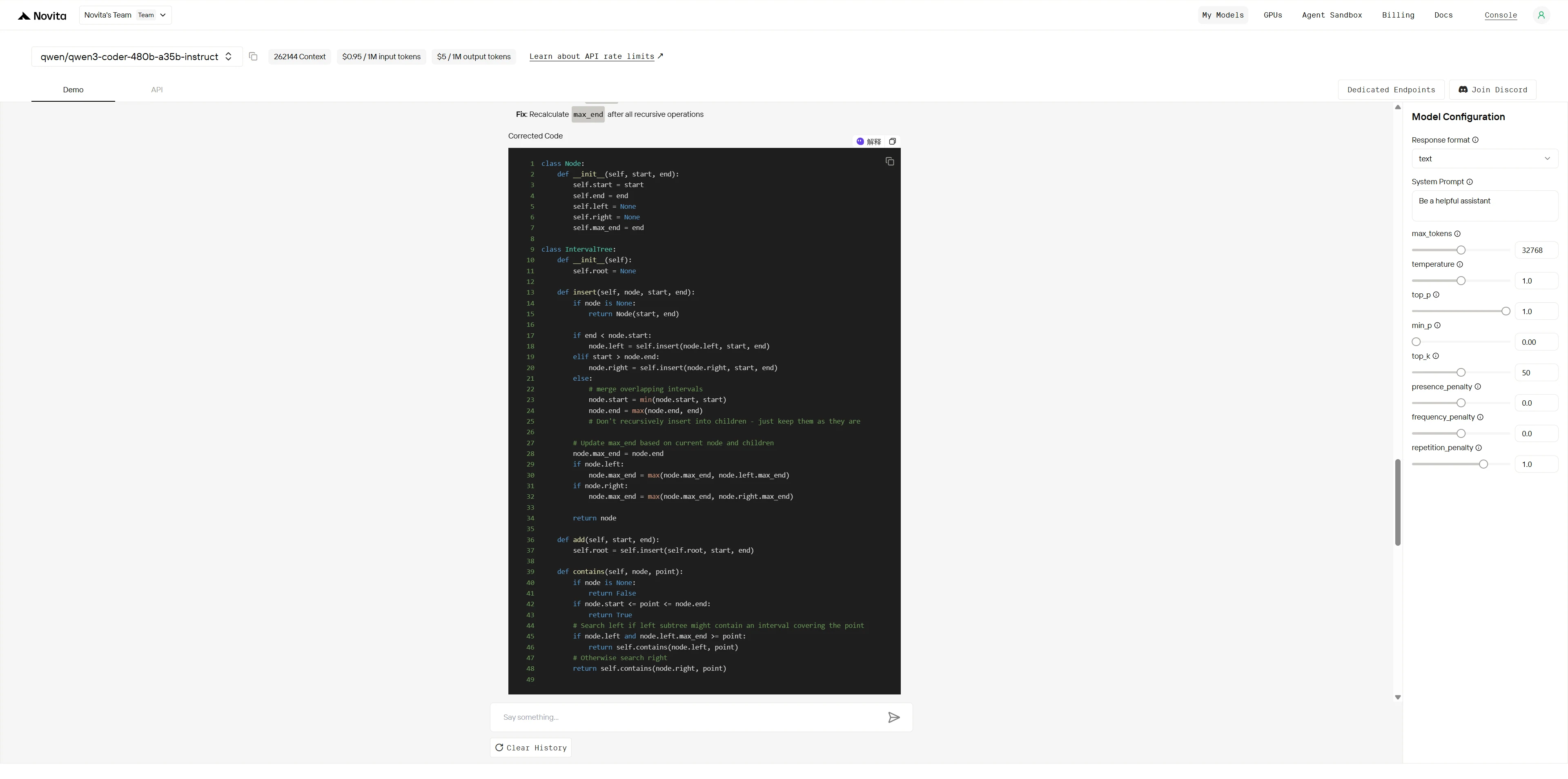
Qwen3-Coder-480B-A35B-Instruct
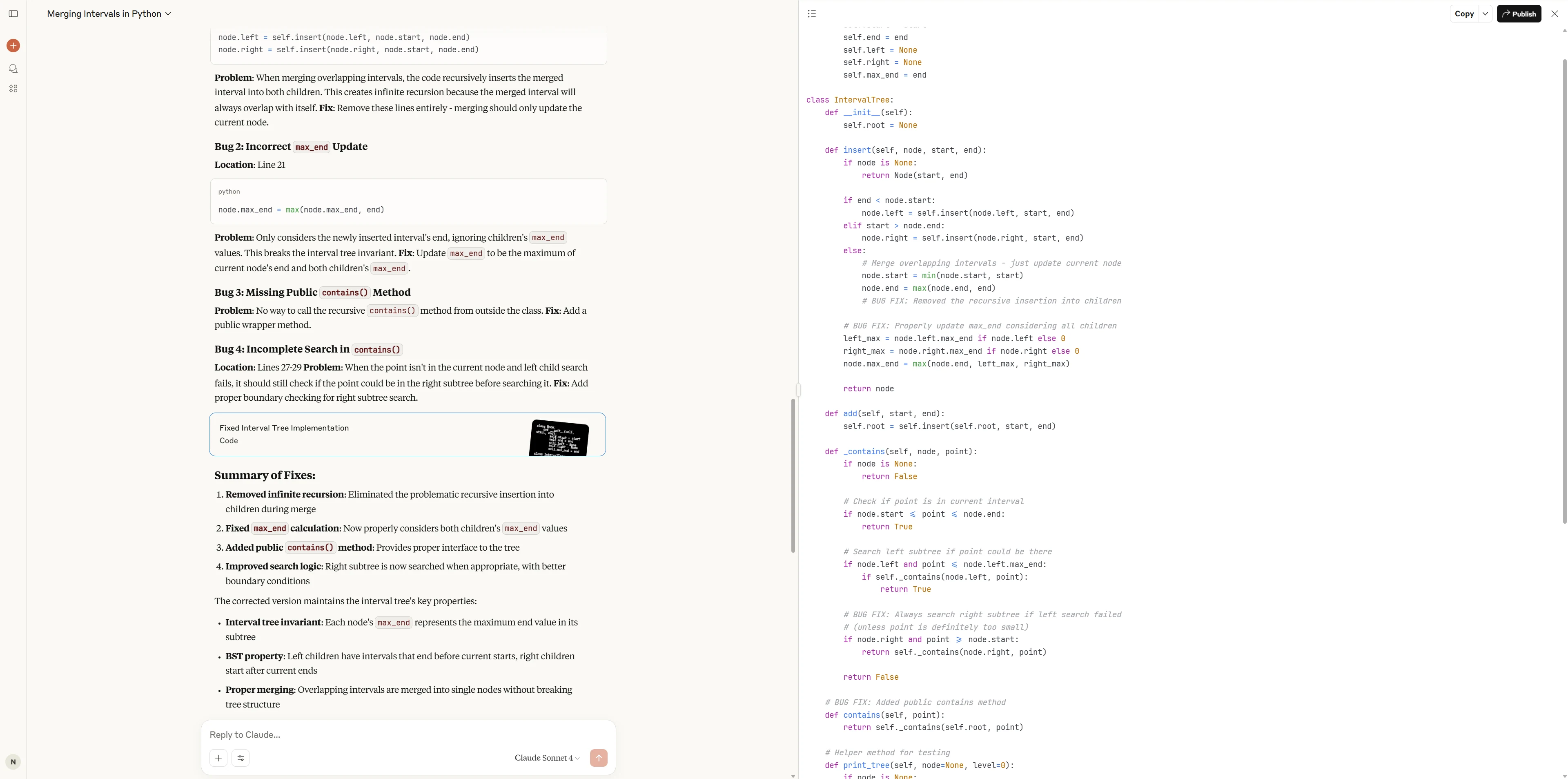
Claude 4 Sonnet
評価サマリー
| モデル | バグ発見 | 説明 | コード | 完全性 | 合計 |
|---|---|---|---|---|---|
| Qwen3-Coder-480B | 40 | 30 | 19 | 8 | 97 |
| Claude 4 Sonnet | 40 | 30 | 20 | 10 | 100 |
Claude 4 Sonnet は、すべての主要なバグを解決しただけでなく、APIの使いやすさや面接対策としての親しみやすさ(スタンドアロンの contains メソッド、豊富なテストケース、詳細なドキュメントなど)も最適化し、優れたコードスタイルと使いやすさを実現しました。
Qwen3-Coder-480B は、高いコード理解力とデバッグスキルを示し、すべての主要なバグを正確に特定して修正し、直接的で効果的な戦略を提供しました。
Qwen3-Coder-480B-A35B-Instruct と Claude 4 Sonnet の強みと弱み
Qwen3-Coder-480B-A35B-Instruct
強み:
- 卓越したコーディング堅牢性: バグの発見と修正に優れ、コードデバッグと明示的なエラー処理で秀でています。
- 巨大なコンテキストウィンドウ: ネイティブで最大262kトークンをサポートし、非常に大規模なコードベースやドキュメントの処理・分析に最適です。
- Mixture-of-Experts の効率性: 巨大なモデル容量と効率的な推論のバランスを取り、複雑なソフトウェア開発タスクで機敏なパフォーマンスを発揮します。
- 明確で直接的な推論: 信頼性の高い強力なコアロジックを備えた、率直で実用的なソリューションを提供します。
弱み:
- コードの洗練度がやや劣る: 出力が Claude 4 Sonnet に比べてエレガントさやモジュール性に欠ける場合があり、高度なエンジニアリング慣行が少ない可能性があります。
Claude 4 Sonnet
強み:
- 高度に洗練されたコード品質: コードスタイル、モジュール性、保守性に優れ、プロフェッショナルグレードの本番即応スクリプトを生成します。
- 包括的なテストと説明: 詳細なドキュメント、明確なバグの根拠、豊富なテストカバレッジを提供し、検証と導入を容易にします。
- 優れたジェネラリスト能力: 多段階推論、要約、ユーザー中心設計など、幅広いタスクで強力なパフォーマンスを発揮します。
- Dense Transformer の精度: コーディングと推論の両方のシナリオで、精度、制御性、アライメントが向上しています。
弱み:
- コンテキストウィンドウが小さい: ネイティブの200kトークン制限は十分ですが、Qwen3-Coder-480B の262kより短く、非常に大規模なコードベースでは影響が出る可能性があります。
- シンプルなタスクでのオーバーヘッド: より精巧で機能豊富なコードを好む傾向があり、非常に単純なタスクでは不必要な複雑さをもたらす可能性があります。
Novita AI で Qwen3-Coder-480B-A35B-Instruct にアクセスする方法
1. Playground を使用する(コーディング不要)
- すぐにアクセス: サインアップ して無料クレジットを取得し、Qwen3-Coder-480B-A35B-Instruct やその他のトップモデルを数秒で試せます。
- インタラクティブ UI: プロンプトや思考連鎖推論をテストし、結果をリアルタイムで可視化できます。
- モデル比較: Kimi K2、Llama 4、DeepSeek などに簡単に切り替えて、ニーズに最適なモデルを見つけられます。
今すぐ Qwen3-Coder-480B-A35B-Instruct デモを試す!
2. API経由で統合する(開発者向け)
Novita AI の統一 REST API を使用して、Qwen3-Coder-480B-A35B-Instruct をアプリケーション、ワークフロー、チャットボットにシームレスに接続できます。モデルウェイトやインフラストラクチャを管理する必要はありません。
直接API統合(Python サンプル)
開始するには、以下のコードスニペットを使用してください。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_cYQSfVMpIb2mRiKf8UOlCSYLuHBjC623pEitotYA8OlPUtMvoE7Z2RUjgDru_x8JpcRARGnvjQGONtIl9VhMuA==",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 32768
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
よくある質問
コーディングに最適なClaudeモデルは、SonnetとOpusのどちらですか?
Opusは一般的に高度で複雑なコーディングタスクに強く、Sonnetも非常に有能で、ほとんどの一般的なコーディングニーズにはよりコスト効率が優れています。
Qwen3 coderとは何ですか?
Qwen3-CoderはAlibabaの大規模言語モデルシリーズで、コーディングとソフトウェア開発に最適化されており、強力な推論と非常に長いコンテキストサポートを備えています。
Claude 4 Sonnetはコーディングに適していますか?
はい、Claude 4 Sonnetはコーディングタスクで非常に優れたパフォーマンスを発揮し、幅広いプログラミング課題に対して強力なコード品質、推論、汎用性を提供します。
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、手頃な価格で信頼性の高いGPUクラウドも提供しています。



