

- Présentation de base des modèles
- Comparaison des benchmarks de Qwen3-Coder-480B-A35B-Instruct et Claude 4 Sonnet
- Test des compétences appliquées de Qwen3-Coder-480B-A35B-Instruct et Claude 4 Sonnet
- Forces et faiblesses de Qwen3-Coder-480B-A35B-Instruct et Claude 4 Sonnet
- Comment accéder à Qwen3-Coder-480B-A35B-Instruct sur Novita AI
- Foire aux questions
Points clés
Qwen3-Coder-480B-A35B-Instruct : Modèle de codage spécialisé avec une longueur de contexte de 262K tokens, optimisé pour l’excellence algorithmique et les performances de référence dans les tâches de programmation.
Claude 4 Sonnet : IA conversationnelle avancée aux capacités équilibrées, optimisée pour les interactions naturelles et l’assistance complète dans divers domaines.
Novita AI propose non seulement des services API stables, mais aussi des tarifs extrêmement compétitifs. Par exemple, Qwen3-Coder-480B-A35B-Instruct coûte 0,95 $ par million de tokens en entrée et 5 $ par million de tokens en sortie.
Présentation de base des modèles
Qwen3-Coder-480B-A35B-Instruct
Qwen3-Coder-480B-A35B-Instruct est un modèle de langage causal à grande échelle de pointe publié par Alibaba en juillet 2025, conçu principalement pour le codage agentique et les tâches de développement logiciel. Il utilise une architecture Mixture-of-Experts (MoE) avec 480 milliards de paramètres au total et 35 milliards de paramètres actifs par passage avant, trouvant un équilibre entre capacité du modèle et efficacité d’inférence. Ce modèle prend en charge des contextes extrêmement longs nativement (256K tokens) et atteint des performances de pointe parmi les modèles ouverts.
Caractéristiques et architecture clés
- Type : Causal Language Models
- Phase d’entraînement : Pré-entraînement et post-entraînement
- Nombre de paramètres : 480B au total, 35B activés
- Nombre de couches : 62
- Nombre de têtes d’attention (GQA) : 96 pour Q et 8 pour KV
- Nombre d’experts : 160
- Nombre d’experts activés : 8
- Longueur de contexte : 262 144 tokens nativement.
Claude 4 Sonnet
Claude 4 Sonnet est le modèle de taille moyenne d’Anthropic, conçu pour équilibrer performances et rentabilité dans un large éventail d’applications, notamment la génération de contenu, les bots d’assistance et les tâches de développement courantes. Claude 4 Sonnet améliore considérablement les capacités de son prédécesseur, Sonnet 3.7, en excellent dans les tâches de codage et de raisonnement avec une précision et une contrôlabilité accrues.
Caractéristiques et architecture clés
- Architecture : Dense Transformer (non-MoE) utilisant une paramétrisation dense à grande échelle.
- Focus d’entraînement : Met l’accent sur la sécurité, l’alignement et la dirigabilité, ainsi que sur la compréhension et la génération du langage naturel à usage général.
- Capacités : Performant en IA conversationnelle, raisonnement multi-étapes, résumé, assistance au codage et conscience éthique.
- Langues : Principalement optimisé pour l’anglais, avec de fortes capacités multilingues.
- Longueur de contexte : 200k tokens.
Comparaison des benchmarks de Qwen3-Coder-480B-A35B-Instruct et Claude 4 Sonnet
1. Benchmarks d’intelligence appliquée

2. Fenêtre de contexte :
Qwen3-Coder-480B-A35B-Instruct: 262k tokens
Claude 4 Sonnet: 200k tokens
3. Tarification API :
Qwen3-Coder-480B-A35B-Instruct : 0,95 $ / 5 $ en entrée/sortie par million de tokens
Claude 4 Sonnet : 3 $ / 15 $ en entrée/sortie par million de tokens
Explorez Qwen3-Coder-480B-A35B-Instruct dès maintenant !
Test des compétences appliquées de Qwen3-Coder-480B-A35B-Instruct et Claude 4 Sonnet
1. Tâche de codage : Classe d’ensemble d’intervalles robuste
Description
Implémentez une classe appelée IntervalSet qui prend en charge les opérations suivantes :
add(interval: List[int])
Ajoute un intervalle[start, end]à l’ensemble. Fusionne automatiquement tous les intervalles qui se chevauchent ou sont adjacents.remove(interval: List[int])
Supprime toutes les portions des intervalles de l’ensemble qui chevauchent[start, end]. Cela peut diviser certains intervalles en deux intervalles disjoints.contains(point: int) -> bool
RenvoieTruesipointse trouve dans un intervalle courant de l’ensemble, sinonFalse.to_list() -> List[List[int]]
Renvoie les intervalles courants dans l’ordre croissant sous forme de liste de paires[start, end].
Exigences supplémentaires
- Toutes les opérations doivent être en O(log n) ou mieux dans le pire des cas (n = nombre d’intervalles).
- Doit gérer robustement les entrées invalides : tout intervalle où
end < startdoit être ignoré. - Le code ne doit pas dépasser 40 lignes (hors espaces blancs trivaux/commentaires ; peut être légèrement étendu si absolument nécessaire, mais se concentrer sur une logique concise et essentielle).
Critères d’évaluation
- Exactitude algorithmique (40 %) :
Gère correctement tous les cas (fusion, division, requêtes, entrées invalides). - Choix de la structure de données et complexité (30 %) :
Utilise une approche efficace (ex. BST équilibré, bisect, SortedList, ou similaire) pour garantir des opérations en O(log n). - Qualité du code (20 %) :
Implémentation claire et lisible ; bon nommage des variables ; gestion robuste des cas limites. - Complétude de l’implémentation (10 %) :
Toutes les méthodes se comportent comme spécifié ; pas de logique auxiliaire manquante.
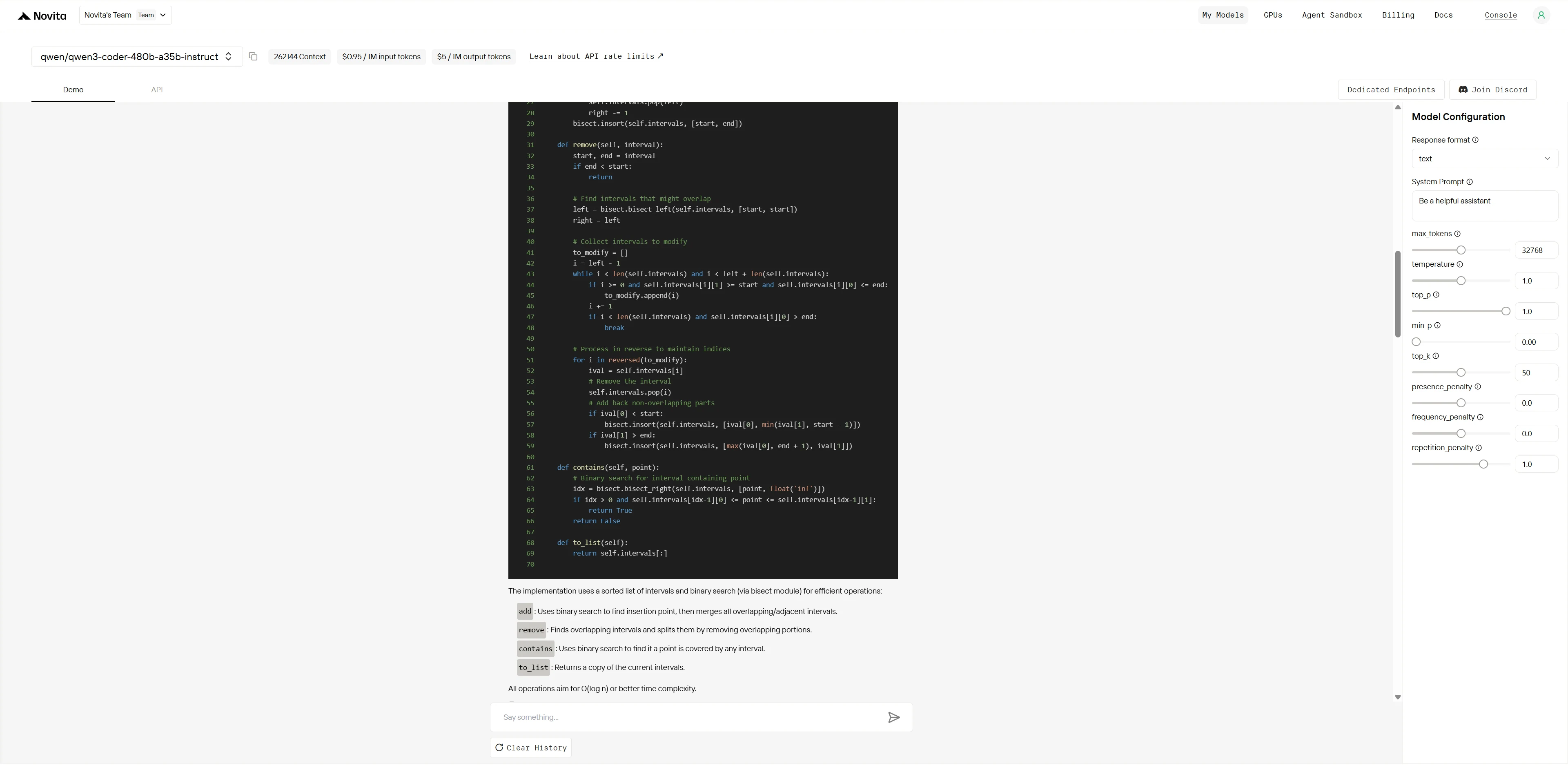
Qwen3-Coder-480B-A35B-Instruct
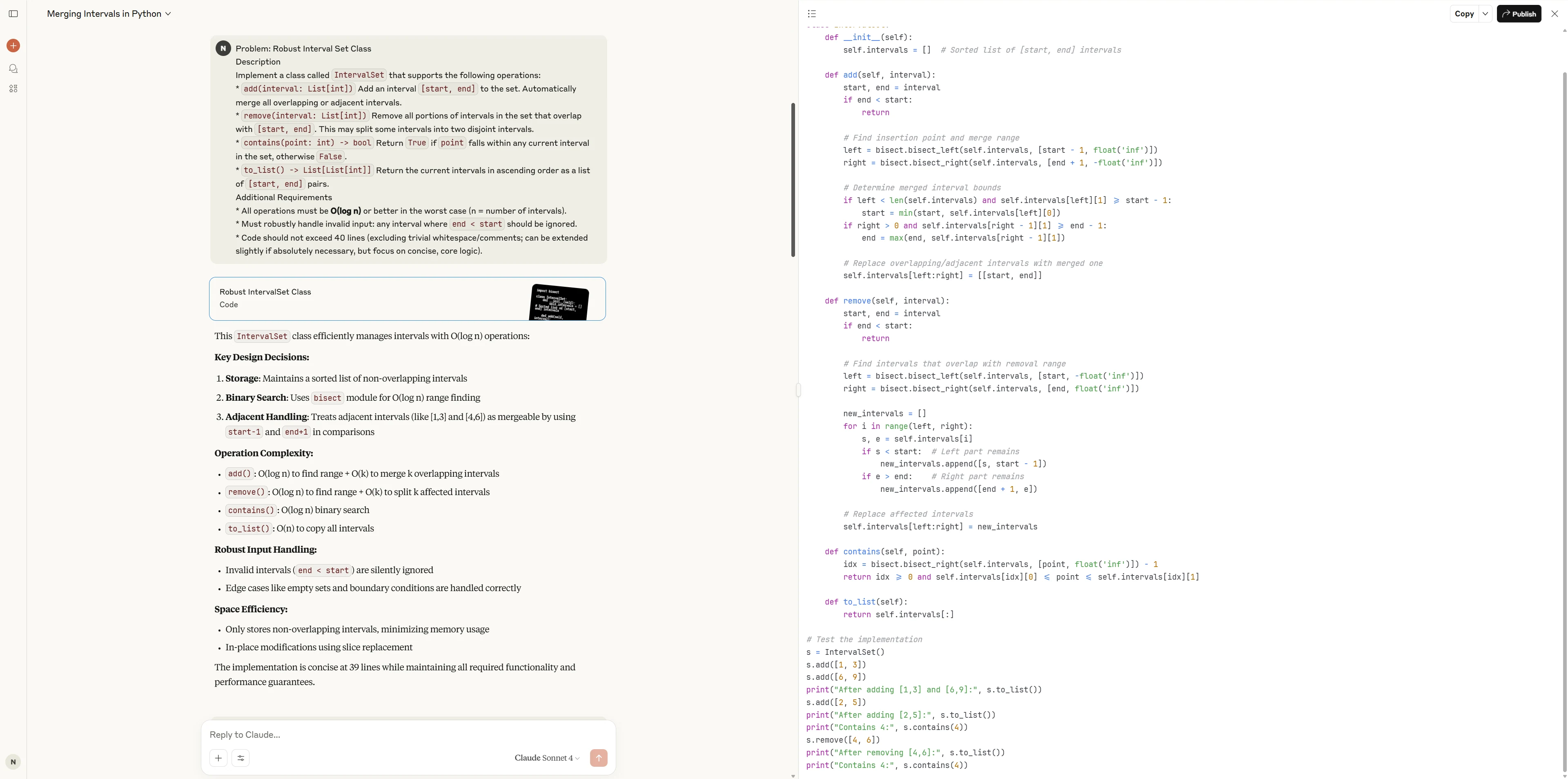
Claude 4 Sonnet
Résumé de l’évaluation
| Modèle | Exactitude | Complexité | Qualité du code | Complétude | Total |
|---|---|---|---|---|---|
| Claude 4 Sonnet | 39 | 30 | 20 | 10 | 99 |
| Qwen3-Coder-480B | 40 | 30 | 19 | 9 | 98 |
Claude 4 Sonnet fournit une implémentation propre et très professionnelle, tirant parti des bibliothèques standard pour l’exactitude et l’efficacité. Le code est élégant, modulaire et comprend une couverture de test complète, ce qui le rend bien adapté aux environnements de production ou aux scénarios exigeant fiabilité et maintenabilité.
Qwen3-Coder-480B propose une solution simple et pratique qui démontre clairement la logique principale. Bien que légèrement plus verbeux et manquant de certaines constructions Python avancées, il met l’accent sur l’explicit et la gestion solide des cas limites. Il est donc très fiable pour la plupart des besoins d’ingénierie quotidiens.
2. Tâche de débogage : Bug de fusion d’arbre d’intervalles
Voici une implémentation (buggée) d’un Interval Tree pour la fusion et l’interrogation d’intervalles. Elle est censée prendre en charge l’ajout d’intervalles et la vérification si un point est contenu dans un intervalle, mais elle renvoie parfois des résultats erronés ou plante.
Votre tâche :
- Identifiez tous les bugs dans le code (pas seulement le premier que vous voyez).
- Pour chaque bug, expliquez pourquoi c’est un bug et comment le corriger.
- Fournissez une version corrigée du code.
Code buggé
class Node:
def __init__(self, start, end):
self.start = start
self.end = end
self.left = None
self.right = None
self.max_end = end
class IntervalTree:
def __init__(self):
self.root = None
def insert(self, node, start, end):
if node is None:
return Node(start, end)
if end < node.start:
node.left = self.insert(node.left, start, end)
elif start > node.end:
node.right = self.insert(node.right, start, end)
else:
# fusionner les intervalles qui se chevauchent
node.start = min(node.start, start)
node.end = max(node.end, end)
# fusionner également les enfants (mais buggé !)
node.left = self.insert(node.left, node.start, node.end)
node.right = self.insert(node.right, node.start, node.end)
node.max_end = max(node.max_end, end)
return node
def add(self, start, end):
self.root = self.insert(self.root, start, end)
def contains(self, node, point):
if node is None:
return False
if node.start <= point <= node.end:
return True
if node.left and point <= node.left.max_end:
return self.contains(node.left, point)
return self.contains(node.right, point)
Critères d’évaluation
- Identification des bugs (40 %) : Trouvez tous les bugs logiques et structurels (pas seulement le premier !), y compris les plus subtils.
- Explication et correction des bugs (30 %) : Explication claire et précise et correction pour chaque bug.
- Code corrigé (20 %) : Fournissez une version entièrement corrigée, propre et lisible.
- Complétude (10 %) : Toutes les méthodes fonctionnent comme spécifié, robustes face aux cas limites.
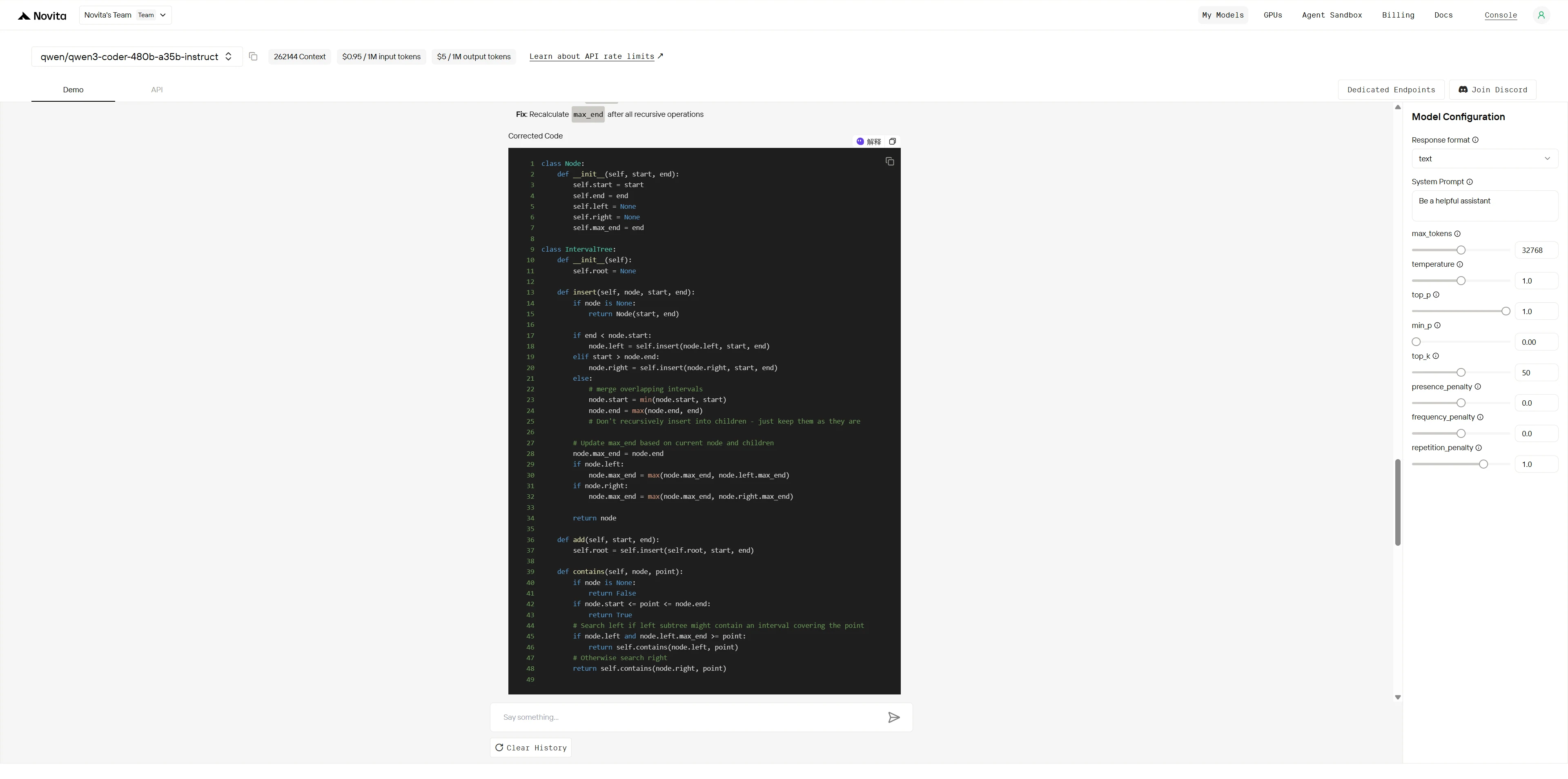
Qwen3-Coder-480B-A35B-Instruct
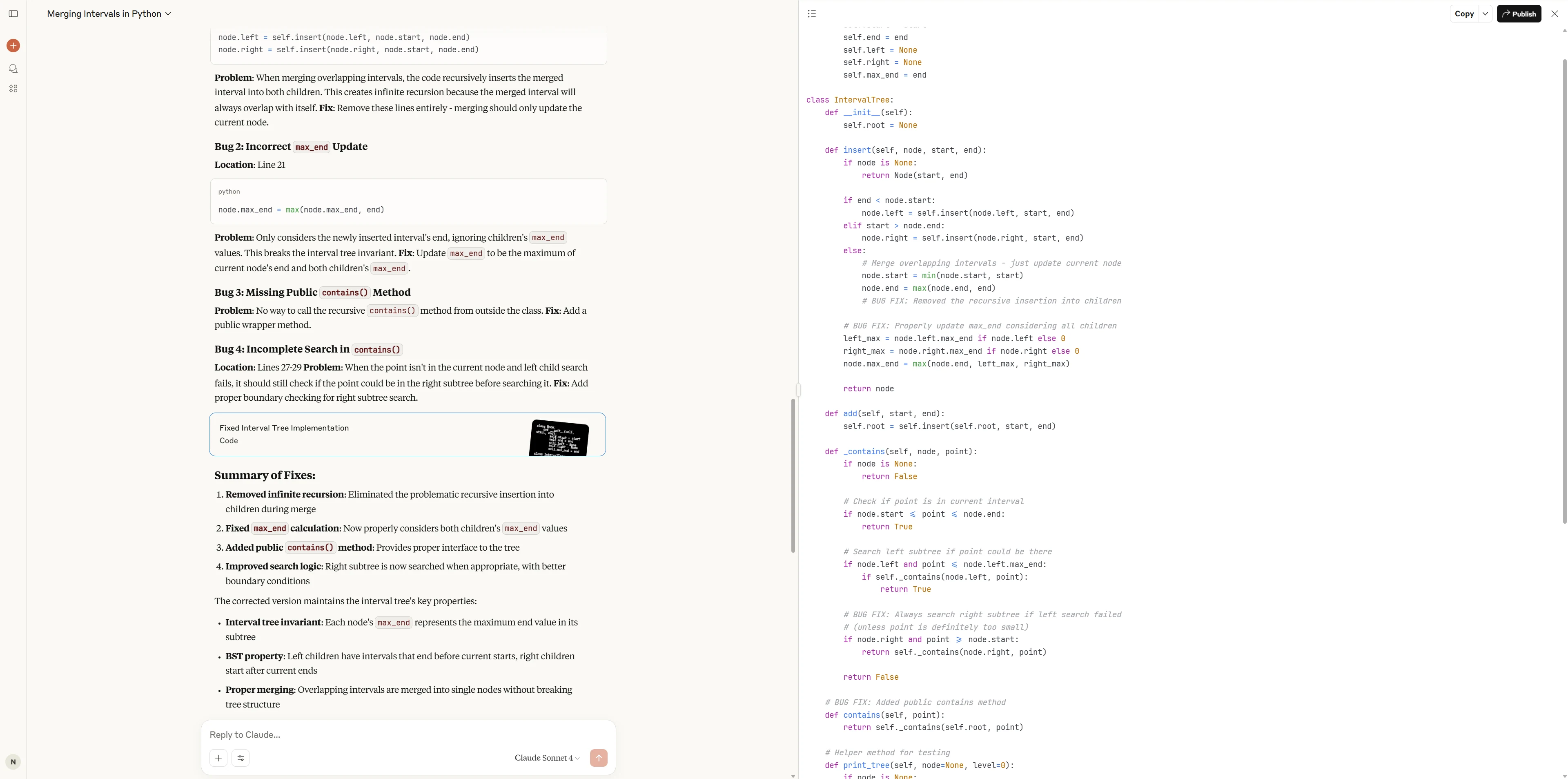
Claude 4 Sonnet
Résumé de l’évaluation
| Modèle | Recherche de bugs | Explication | Code | Complétude | Total |
|---|---|---|---|---|---|
| Qwen3-Coder-480B | 40 | 30 | 19 | 8 | 97 |
| Claude 4 Sonnet | 40 | 30 | 20 | 10 | 100 |
Claude 4 Sonnet a non seulement résolu tous les bugs clés, mais a également optimisé l’utilisabilité de l’API et la convivialité pour les entretiens (méthode contains indépendante, cas de test riches, documentation complète), ce qui donne un style de code et une utilisabilité supérieurs.
Qwen3-Coder-480B a démontré de solides compétences en compréhension de code et débogage, identifiant et corrigeant avec précision tous les bugs majeurs avec des stratégies directes et efficaces.
Forces et faiblesses de Qwen3-Coder-480B-A35B-Instruct et Claude 4 Sonnet
Qwen3-Coder-480B-A35B-Instruct
Forces :
- Robustesse de codage exceptionnelle : Démontre une forte capacité à trouver et corriger des bugs, excellant dans le débogage de code et la gestion explicite des erreurs.
- Fenêtre de contexte massive : prend en charge jusqu’à 262k tokens nativement, idéal pour traiter et analyser de très grandes bases de code ou documents.
- Efficacité Mixture-of-Experts : équilibre une grande capacité de modèle avec une inférence efficace, permettant des performances agiles sur des tâches complexes de développement logiciel.
- Raisonnement clair et direct : fournit des solutions simples et pratiques avec une logique centrale fiablement solide.
Faiblesses :
- Qualité de code légèrement moins soignée : la sortie peut être moins élégante ou modulaire par rapport à Claude 4 Sonnet, avec moins de conventions d’ingénierie avancées.
Claude 4 Sonnet
Forces :
- Qualité de code très soignée : excelle dans le style de code, la modularité et la maintenabilité, produisant des scripts professionnels prêts pour la production.
- Tests et explications complets : fournit une documentation détaillée, des justifications claires pour les bugs et une couverture de test riche, facilitant la vérification et la prise en main.
- Capacités généralistes supérieures : bonnes performances sur un large éventail de tâches, y compris le raisonnement multi-étapes, le résumé et la conception centrée sur l’utilisateur.
- Précision du Dense Transformer : exactitude, contrôlabilité et alignement améliorés dans les scénarios de codage et de raisonnement.
Faiblesses :
- Fenêtre de contexte plus petite : la limite native de 200k tokens est généreuse, mais reste inférieure à celle de Qwen3-Coder-480B (262k), ce qui peut impacter pour des bases de code extrêmement grandes.
- Complexité potentielle pour des tâches simples : a tendance à favoriser un code plus élaboré ou riche en fonctionnalités, ce qui peut introduire une complexité inutile pour des tâches très simples.
Comment accéder à Qwen3-Coder-480B-A35B-Instruct sur Novita AI
1. Utiliser le Playground (sans codage requis)
- Accès instantané : Inscrivez-vous, obtenez vos crédits gratuits et commencez à expérimenter avec Qwen3-Coder-480B-A35B-Instruct et d’autres modèles de premier plan en quelques secondes.
- Interface interactive : testez des prompts, le raisonnement en chaîne de pensée et visualisez les résultats en temps réel.
- Comparaison de modèles : basculez facilement entre Kimi K2, Llama 4, DeepSeek, et plus encore pour trouver la solution parfaite à vos besoins.
Explorez la démo de Qwen3-Coder-480B-A35B-Instruct dès maintenant !
2. Intégration via l’API (pour développeurs)
Connectez Qwen3-Coder-480B-A35B-Instruct à vos applications, workflows ou chatbots de manière transparente grâce à l’API REST unifiée de Novita AI — sans avoir à gérer les poids du modèle ou l’infrastructure.
Intégration API directe (exemple en Python)
Pour commencer, utilisez simplement l’extrait de code ci-dessous :
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_cYQSfVMpIb2mRiKf8UOlCSYLuHBjC623pEitotYA8OlPUtMvoE7Z2RUjgDru_x8JpcRARGnvjQGONtIl9VhMuA==",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 32768
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Foire aux questions
Quel modèle Claude est le meilleur pour le codage, Sonnet ou Opus ?
Opus est généralement plus performant pour les tâches de codage avancées et complexes, tandis que Sonnet est également très capable et plus rentable pour la plupart des besoins de codage courants.
Qu’est-ce que Qwen3 coder ?
Qwen3-Coder est la série de modèles de langage d’Alibaba optimisée pour le codage et le développement logiciel, offrant un raisonnement puissant et un support de contexte extrêmement long.
Claude 4 Sonnet est-il bon pour le codage ?
Oui, Claude 4 Sonnet donne de très bons résultats dans les tâches de codage, offrant une qualité de code, un raisonnement et une polyvalence solides pour un large éventail de défis de programmation.
*Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.



