

重點摘要
Qwen3-Coder-480B-A35B-Instruct:專為程式碼設計的模型,支援 262K token 的上下文長度,在演算法表現與程式任務基準測試中表現卓越。
Claude 4 Sonnet:先進的對話式 AI,能力均衡,擅長自然互動,並能在多種領域提供全面協助。
Novita AI 不僅提供穩定的 API 服務,還提供極具成本效益的定價。例如,Qwen3-Coder-480B-A35B-Instruct 的輸入 token 價格為每 1M 個 $0.95,輸出 token 為每 1M 個 $5。
模型基本介紹
Qwen3-Coder-480B-A35B-Instruct
Qwen3-Coder-480B-A35B-Instruct 是由阿里巴巴於 2025 年 7 月發布的尖端大規模因果語言模型,主要專注於代理式程式開發與軟體開發任務。它採用混合專家(MoE)架構,總參數達 4800 億,每次前向傳播僅啟用 350 億個參數,在模型容量與推論效率之間取得平衡。該模型原生支援 256K token 的超長上下文,並在開放模型中達到頂尖效能。
主要特色與架構
- 類型:因果語言模型
- 訓練階段:預訓練與後訓練
- 參數量:總共 480B,啟用 35B
- 層數:62
- 注意力頭數(GQA):Q 為 96,KV 為 8
- 專家數量:160
- 啟用專家數量:8
- 上下文長度:原生 262,144。
Claude 4 Sonnet
Claude 4 Sonnet 是 Anthropic 的中型語言模型,專為在效能與成本效益之間取得平衡而設計,適用於廣泛的應用,包括內容生成、支援機器人與日常開發任務。Claude 4 Sonnet 大幅提升了前代 Sonnet 3.7 的能力,在程式碼與推理任務上展現更佳的精確性與可控性。
主要特色與架構
- 架構:密集 Transformer 模型(非 MoE),採用大規模密集參數化。
- 訓練重點:強調安全性、對齊性與可控性,同時具備通用自然語言理解與生成能力。
- 能力:擅長對話式 AI、多步驟推理、摘要、程式碼協助與倫理意識。
- 語言:主要最佳化英語,同時具備強大的多語言能力。
- 上下文長度:200k 個 token。
Qwen3-Coder-480B-A35B-Instruct 與 Claude 4 Sonnet 的基準測試比較
1. 應用智慧基準測試

2. 上下文視窗:
Qwen3-Coder-480B-A35B-Instruct: 262k 個 token
Claude 4 Sonnet: 200k 個 token
3. API 定價:
Qwen3-Coder-480B-A35B-Instruct:每 1M 個 token 輸入 / 輸出 $0.95 / $5
Claude 4 Sonnet: 每 1M 個 token 輸入 / 輸出 $3 / $15
立即探索 Qwen3-Coder-480B-A35B-Instruct!
Qwen3-Coder-480B-A35B-Instruct 與 Claude 4 Sonnet 的應用技能測試
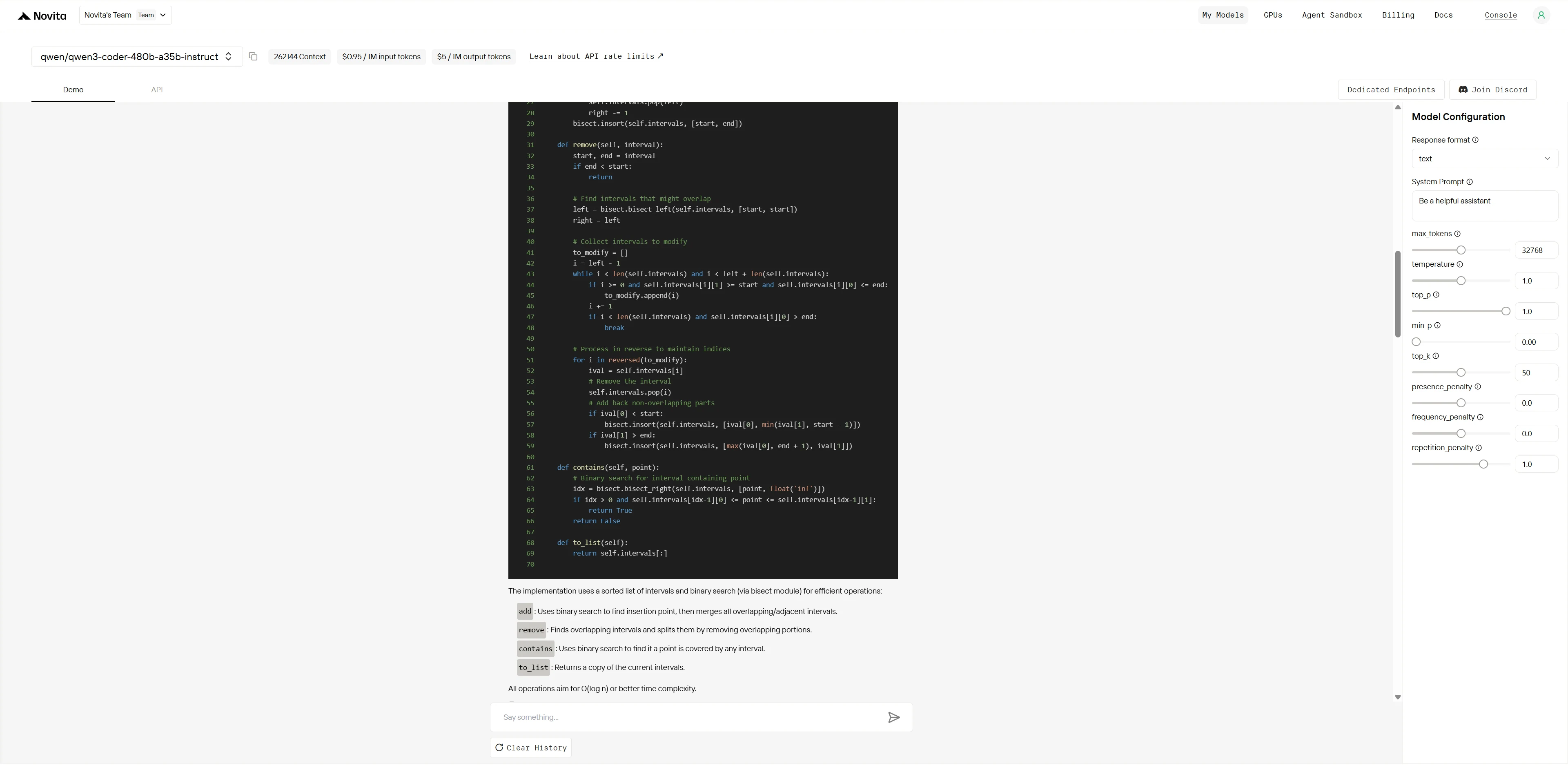
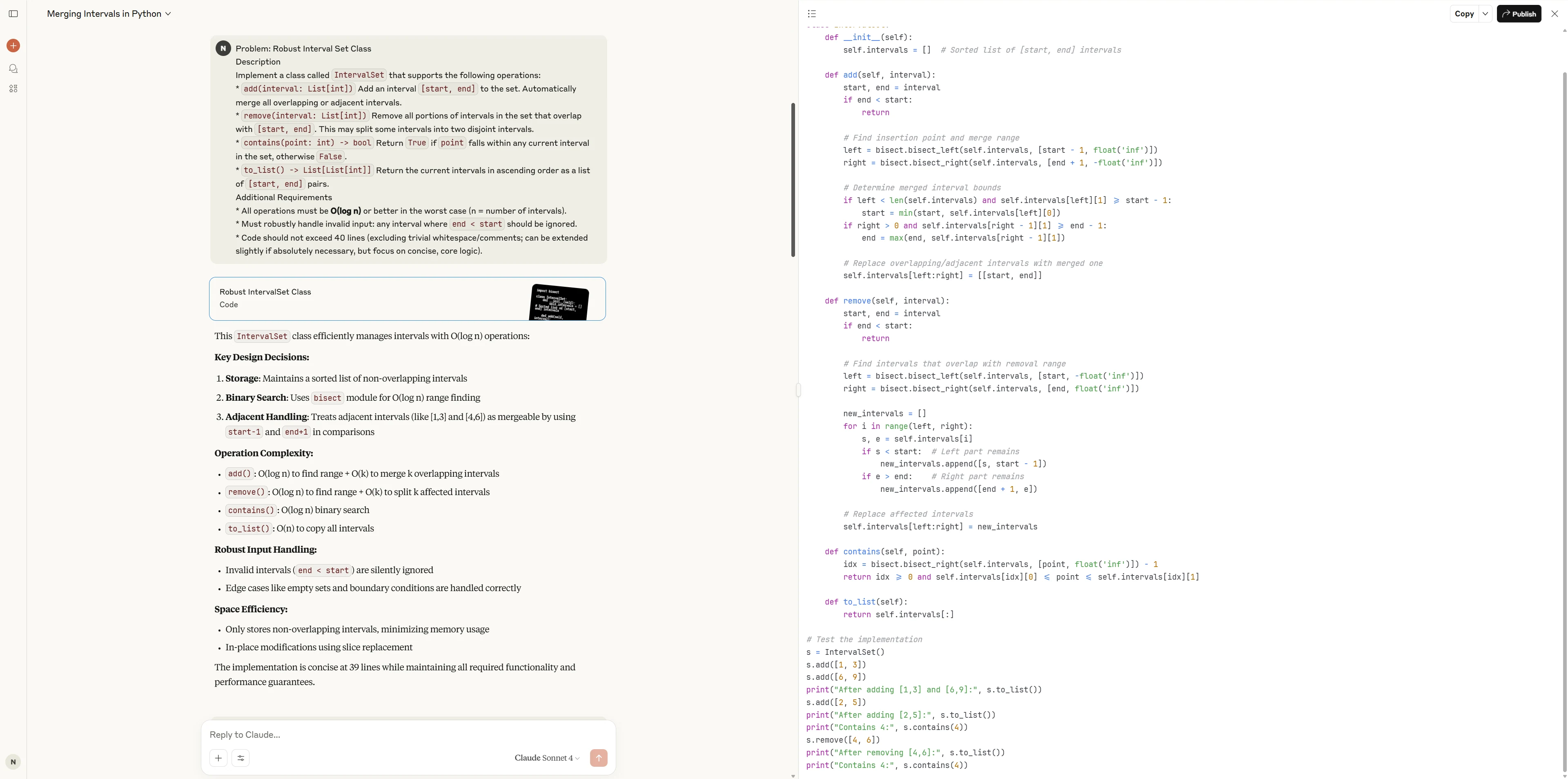
1. 程式設計任務:穩健的區間集合類別
描述
實作一個名為 IntervalSet 的類別,支援以下操作:
add(interval: List[int])
將區間[start, end]加入集合中。自動合併所有重疊或相鄰的區間。remove(interval: List[int])
從集合中移除與[start, end]重疊的所有區間部分。可能將某些區間分割成兩個不相交的區間。contains(point: int) -> bool
若point落在集合中任何現有區間內則回傳True,否則回傳False。to_list() -> List[List[int]]
以升序回傳當前區間清單,格式為[start, end]配對。
額外需求
- 所有操作在最壞情況下必須是 O(log n) 或更佳(n = 區間數量)。
- 必須穩健處理無效輸入:任何
end < start的區間應被忽略。 - 程式碼不得超過 40 行(不含多餘空白 / 註解;必要時可稍微延伸,但重點在於簡潔的核心邏輯)。
評估標準
- 演算法正確性 (40%):
正確處理所有情況(合併、分割、查詢、無效輸入)。 - 資料結構選擇與複雜度 (30%):
使用高效的方法(例如平衡 BST、bisect、SortedList 或類似機制)確保 O(log n) 操作。 - 程式碼品質 (20%):
清晰、可讀的實作;良好的變數命名;穩健的邊際情況處理。 - 實作完整性 (10%):
所有方法按規格運作;無遺漏輔助邏輯。
Qwen3-Coder-480B-A35B-Instruct
Claude 4 Sonnet
評估摘要
| 模型 | 正確性 | 複雜度 | 程式碼品質 | 完整性 | 總分 |
|---|---|---|---|---|---|
| Claude 4 Sonnet | 39 | 30 | 20 | 10 | 99 |
| Qwen3-Coder-480B | 40 | 30 | 19 | 9 | 98 |
Claude 4 Sonnet 提供了乾淨且高度專業的實作,利用標準函式庫兼顧正確性與效率。程式碼優雅且模組化,並包含全面的測試覆蓋,非常適合生產環境或需要可靠性和可維護性的場景。
Qwen3-Coder-480B 提供了直接且實用的解決方案,清楚展現核心邏輯。雖然稍顯冗長且缺乏一些進階 Python 結構,但它強調明確性與穩健的邊際情況處理。對於大多數日常工程需求而言,它非常可靠。
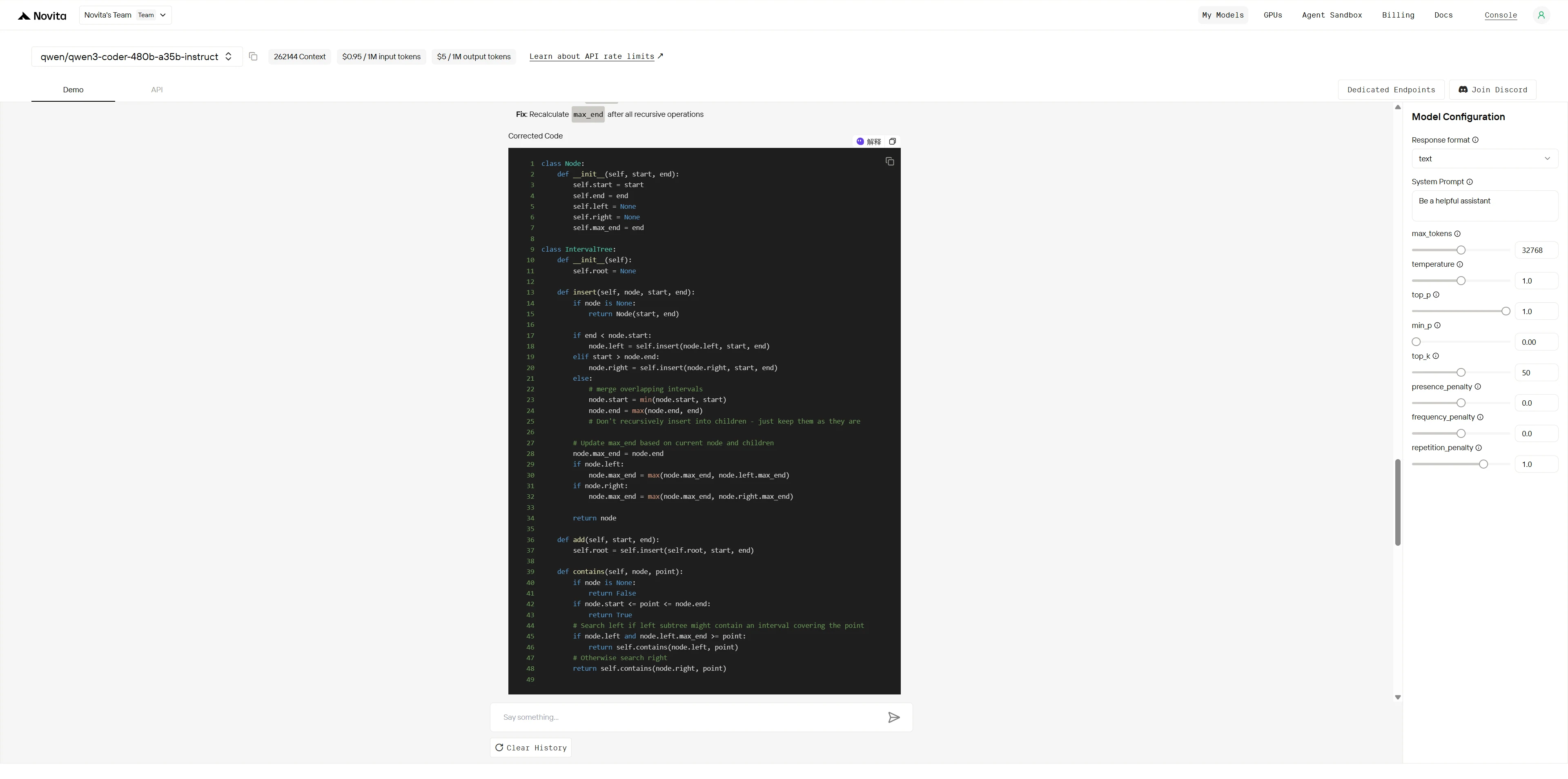
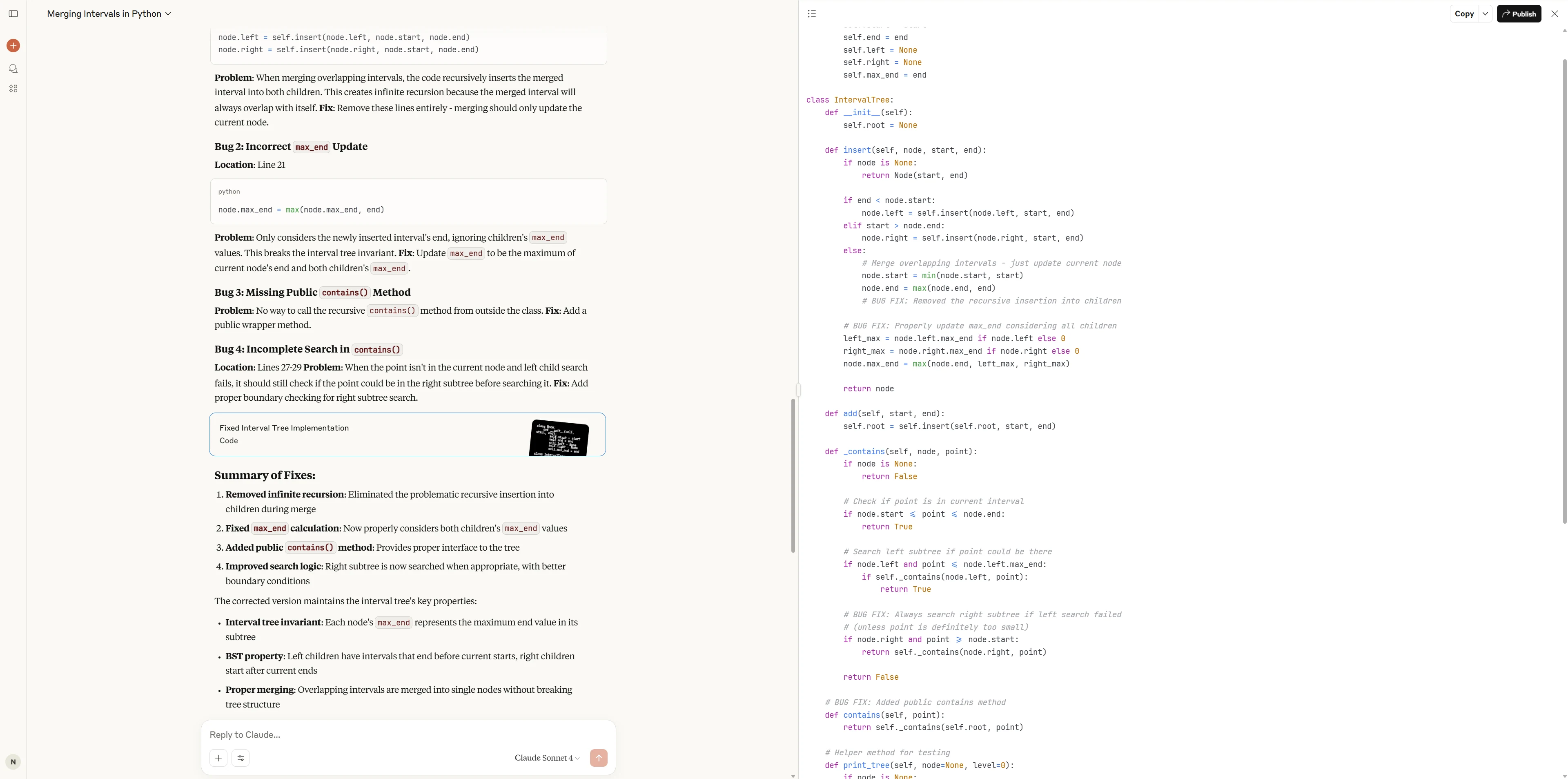
2. 除錯任務:區間樹合併錯誤
以下是一個(有錯誤的)區間樹 實作,用於合併與查詢區間。它應該支援加入區間以及檢查某個點是否落在任何區間內,但有時會回傳錯誤結果甚至崩潰。
你的任務:
- 找出程式碼中 所有錯誤(不只是你看到的第一個)。
- 對每個錯誤解釋為什麼是錯誤,以及如何修復。
- 提供修正後的程式碼版本。
有錯誤的程式碼
class Node:
def __init__(self, start, end):
self.start = start
self.end = end
self.left = None
self.right = None
self.max_end = end
class IntervalTree:
def __init__(self):
self.root = None
def insert(self, node, start, end):
if node is None:
return Node(start, end)
if end < node.start:
node.left = self.insert(node.left, start, end)
elif start > node.end:
node.right = self.insert(node.right, start, end)
else:
# merge overlapping intervals
node.start = min(node.start, start)
node.end = max(node.end, end)
# merge children as well (but buggy!)
node.left = self.insert(node.left, node.start, node.end)
node.right = self.insert(node.right, node.start, node.end)
node.max_end = max(node.max_end, end)
return node
def add(self, start, end):
self.root = self.insert(self.root, start, end)
def contains(self, node, point):
if node is None:
return False
if node.start <= point <= node.end:
return True
if node.left and point <= node.left.max_end:
return self.contains(node.left, point)
return self.contains(node.right, point)
評估標準
- 錯誤辨識 (40%):找出所有邏輯與結構錯誤(不只第一個!),包括細微錯誤。
- 錯誤解釋與修正 (30%):對每個錯誤提供清晰、精確的解釋與修正方法。
- 修正後程式碼 (20%):提供完全修正的版本,乾淨且可讀。
- 完整性 (10%):所有方法按規格運作,對邊際情況穩健。
Qwen3-Coder-480B-A35B-Instruct
Claude 4 Sonnet
評估摘要
| 模型 | 錯誤發現 | 解釋 | 程式碼 | 完整性 | 總分 |
|---|---|---|---|---|---|
| Qwen3-Coder-480B | 40 | 30 | 19 | 8 | 97 |
| Claude 4 Sonnet | 40 | 30 | 20 | 10 | 100 |
Claude 4 Sonnet 不僅解決了所有關鍵錯誤,還最佳化了 API 易用性與面試友善度(例如獨立 contains 方法、豐富的測試案例與詳盡文件),使程式碼風格與可用性更為出色。
Qwen3-Coder-480B 展現了強大的程式碼理解與除錯能力,準確找出並修正了所有主要錯誤,策略直接有效。
Qwen3-Coder-480B-A35B-Instruct 與 Claude 4 Sonnet 的優點與缺點
Qwen3-Coder-480B-A35B-Instruct
優點:
- 卓越的程式碼穩健性: 展現強大的錯誤尋找與修正能力,在程式碼除錯與明確錯誤處理上表現出色。
- 龐大的上下文視窗: 原生支援高達 262k 個 token,非常適合處理與分析極大型程式碼庫或文件。
- 混合專家效率: 平衡龐大模型容量與高效推論,能在複雜軟體開發任務中靈活表現。
- 清晰直接的推理: 提供直截了當的實用解決方案,核心邏輯可靠強大。
缺點:
- 程式碼精緻度略低: 與 Claude 4 Sonnet 相比,輸出可能較不優雅或模組化,進階工程慣例較少。
Claude 4 Sonnet
優點:
- 高度精緻的程式碼品質: 在程式碼風格、模組化與可維護性方面表現優異,產出專業級、可投入生產的腳本。
- 全面的測試與解釋: 提供詳盡的文件、清晰的錯誤理由與豐富的測試覆蓋,有助於輕鬆驗證與上手。
- 出色的通才能力: 在多種任務中表現強勁,包括多步驟推理、摘要與以使用者為中心的設計。
- 密集 Transformer 的精確性: 在程式碼與推理場景中展現更佳的精確度、可控性與對齊性。
缺點:
- 較小的上下文視窗: 原生 200k 個 token 的限制雖然不小,但仍短於 Qwen3-Coder-480B 的 262k,對於極大型程式碼庫可能有所影響。
- 簡單任務可能過度設計: 傾向於偏愛更複雜或功能豐富的程式碼,對於非常簡單的任務可能引入不必要的複雜性。
如何在 Novita AI 上使用 Qwen3-Coder-480B-A35B-Instruct
1. 使用 Playground(無需編碼)
- 立即存取: 註冊,領取免費額度,立即開始體驗 Qwen3-Coder-480B-A35B-Instruct 及其他頂尖模型。
- 互動式 UI: 測試提示、思維鏈推理,並即時視覺化結果。
- 模型比較: 輕鬆在 Kimi K2、Llama 4、DeepSeek 等模型之間切換,找到最適合您需求的模型。
立即探索 Qwen3-Coder-480B-A35B-Instruct 示範!
2. 透過 API 整合(適合開發者)
使用 Novita AI 的統一 REST API,將 Qwen3-Coder-480B-A35B-Instruct 無縫連接到您的應用程式、工作流程或聊天機器人 — 無需管理模型權重或基礎設施。
直接 API 整合(Python 範例)
要開始使用,只需使用以下程式碼片段:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_cYQSfVMpIb2mRiKf8UOlCSYLuHBjC623pEitotYA8OlPUtMvoE7Z2RUjgDru_x8JpcRARGnvjQGONtIl9VhMuA==",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 32768
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
常見問題
哪個 Claude 模型最適合寫程式,Sonnet 還是 Opus?
Opus 通常對進階與複雜的程式任務更為強大,而 Sonnet 也非常有能力,且對大多數常見程式需求更具成本效益。
什麼是 Qwen3 coder?
Qwen3-Coder 是阿里巴巴專為程式碼與軟體開發最佳化的大型語言模型系列,具備強大的推理能力與極長的上下文支援。
Claude 4 Sonnet 適合寫程式嗎?
是的,Claude 4 Sonnet 在程式任務中表現非常出色,能夠提供優異的程式碼品質、推理能力與多樣性,適用於各種程式設計挑戰。
*Novita AI *是 AI 雲端平台,為開發者提供簡單的 API 來部署 AI 模型,同時也提供經濟實惠且可靠的 GPU 雲端服務,用於建構與擴展應用。



