

- Grundlegende Einführung der Modelle
- Benchmark-Vergleich von Qwen3-Coder-480B-A35B-Instruct und Claude 4 Sonnet
- Angewandte Fähigkeitstests von Qwen3-Coder-480B-A35B-Instruct und Claude 4 Sonnet
- Stärken und Schwächen von Qwen3-Coder-480B-A35B-Instruct und Claude 4 Sonnet
- So erhältst du Zugriff auf Qwen3-Coder-480B-A35B-Instruct auf Novita AI
- Häufig gestellte Fragen
Wichtigste Highlights
Qwen3-Coder-480B-A35B-Instruct: Spezialisiertes Codierungsmodell mit 262K Token Kontextlänge, optimiert für algorithmische Exzellenz und Benchmark-Leistung bei Programmieraufgaben.
Claude 4 Sonnet: Fortschrittliche Konversations-KI mit ausgewogenen Fähigkeiten, optimiert für natürliche Interaktion und umfassende Unterstützung in verschiedenen Bereichen.
Novita AI bietet nicht nur stabile API-Dienste, sondern auch äußerst kostengünstige Preise. Beispielsweise kostet Qwen3-Coder-480B-A35B-Instruct $0,95 pro 1M Eingabe-Token und $5 pro 1M Ausgabe-Token.
Grundlegende Einführung der Modelle
Qwen3-Coder-480B-A35B-Instruct
Qwen3-Coder-480B-A35B-Instruct ist ein hochmodernes, kausales Sprachmodell, das von Alibaba im Juli 2025 veröffentlicht wurde und hauptsächlich für agentisches Codieren und Softwareentwicklungsaufgaben entwickelt wurde. Es verwendet eine Mixture-of-Experts (MoE)-Architektur mit insgesamt 480 Milliarden Parametern und 35 Milliarden aktiven Parametern pro Vorwärtspass, wodurch ein Gleichgewicht zwischen Modellkapazität und Inferenzeffizienz erreicht wird. Dieses Modell unterstützt nativ extrem lange Kontexte von 256K Token und erreicht unter offenen Modellen modernste Leistung.
Hauptmerkmale und Architektur
- Typ: Kausale Sprachmodelle
- Trainingsstufe: Vortraining & Nachbereitung
- Anzahl Parameter: 480B insgesamt und 35B aktiviert
- Anzahl Schichten: 62
- Anzahl Aufmerksamkeitsköpfe (GQA): 96 für Q und 8 für KV
- Anzahl Experten: 160
- Anzahl aktivierter Experten: 8
- Kontextlänge: 262.144 nativ.
Claude 4 Sonnet
Claude 4 Sonnet ist das mittelgroße Sprachmodell von Anthropic, das darauf ausgelegt ist, Leistung und Wirtschaftlichkeit für ein breites Anwendungsspektrum, einschließlich Inhaltserstellung, Support-Bots und alltägliche Entwicklungsaufgaben, auszugleichen. Claude 4 Sonnet verbessert die Fähigkeiten seines Vorgängers Sonnet 3.7 erheblich und zeichnet sich durch verbesserte Präzision und Kontrollierbarkeit sowohl bei Codierungs- als auch bei Denkaufgaben aus.
Hauptmerkmale und Architektur
- Architektur: Dichtes Transformer-Modell (nicht MoE) mit groß angelegter dichter Parametrisierung.
- Trainingsschwerpunkt: Betont Sicherheit, Ausrichtung und Steuerbarkeit neben allgemeinem Verstehen und Generieren natürlicher Sprache.
- Fähigkeiten: Stark in Konversations-KI, mehrstufigem Denken, Zusammenfassung, Code-Assistenz und ethischem Bewusstsein.
- Sprachen: Hauptsächlich für Englisch optimiert, mit starken mehrsprachigen Fähigkeiten.
- Kontextlänge: 200k Token.
Benchmark-Vergleich von Qwen3-Coder-480B-A35B-Instruct und Claude 4 Sonnet
1. Benchmarks für angewandte Intelligenz

2. Kontextfenster:
Qwen3-Coder-480B-A35B-Instruct: 262k Token
Claude 4 Sonnet: 200k Token
3. API-Preise:
Qwen3-Coder-480B-A35B-Instruct: $0,95 / $5 in/out pro 1M Token
Claude 4 Sonnet: $3 / $15 in/out pro 1M Token
Entdecke jetzt Qwen3-Coder-480B-A35B-Instruct!
Angewandte Fähigkeitstests von Qwen3-Coder-480B-A35B-Instruct und Claude 4 Sonnet
1. Codierungsaufgabe: Robuste Intervall-Mengen-Klasse
Beschreibung
Implementiere eine Klasse namens IntervalSet, die die folgenden Operationen unterstützt:
add(interval: List[int])
Füge ein Intervall[start, end]zur Menge hinzu. Automatisches Zusammenführen aller überlappenden oder benachbarten Intervalle.remove(interval: List[int])
Entferne alle Teile von Intervallen in der Menge, die mit[start, end]überlappen. Dies kann einige Intervalle in zwei disjunkte Intervalle aufteilen.contains(point: int) -> bool
GibTruezurück, wennpointin einem aktuellen Intervall der Menge liegt, sonstFalse.to_list() -> List[List[int]]
Gib die aktuellen Intervalle in aufsteigender Reihenfolge als Liste von[start, end]-Paaren zurück.
Zusätzliche Anforderungen
- Alle Operationen müssen im schlimmsten Fall O(log n) oder besser sein (n = Anzahl der Intervalle).
- Ungültige Eingaben müssen robust behandelt werden: Jedes Intervall, bei dem
end < startist, sollte ignoriert werden. - Der Code sollte 40 Zeilen nicht überschreiten (ohne unwesentliche Leerzeichen/Kommentare; kann bei Bedarf geringfügig erweitert werden, aber konzentriere dich auf prägnante Kernlogik).
Bewertungskriterien
- Korrektheit des Algorithmus (40%):
Behandelt alle Fälle korrekt (Zusammenführen, Aufteilen, Abfragen, ungültige Eingaben). - Datenstrukturwahl & Komplexität (30%):
Verwendet einen effizienten Ansatz (z. B. balancierter BST, Bisect, SortedList oder ähnlich), um O(log n)-Operationen zu gewährleisten. - Codequalität (20%):
Klare, lesbare Implementierung; gute Variablenbenennung; robuste Behandlung von Randfällen. - Vollständigkeit der Implementierung (10%):
Alle Methoden verhalten sich wie angegeben; keine fehlende Hilfslogik.
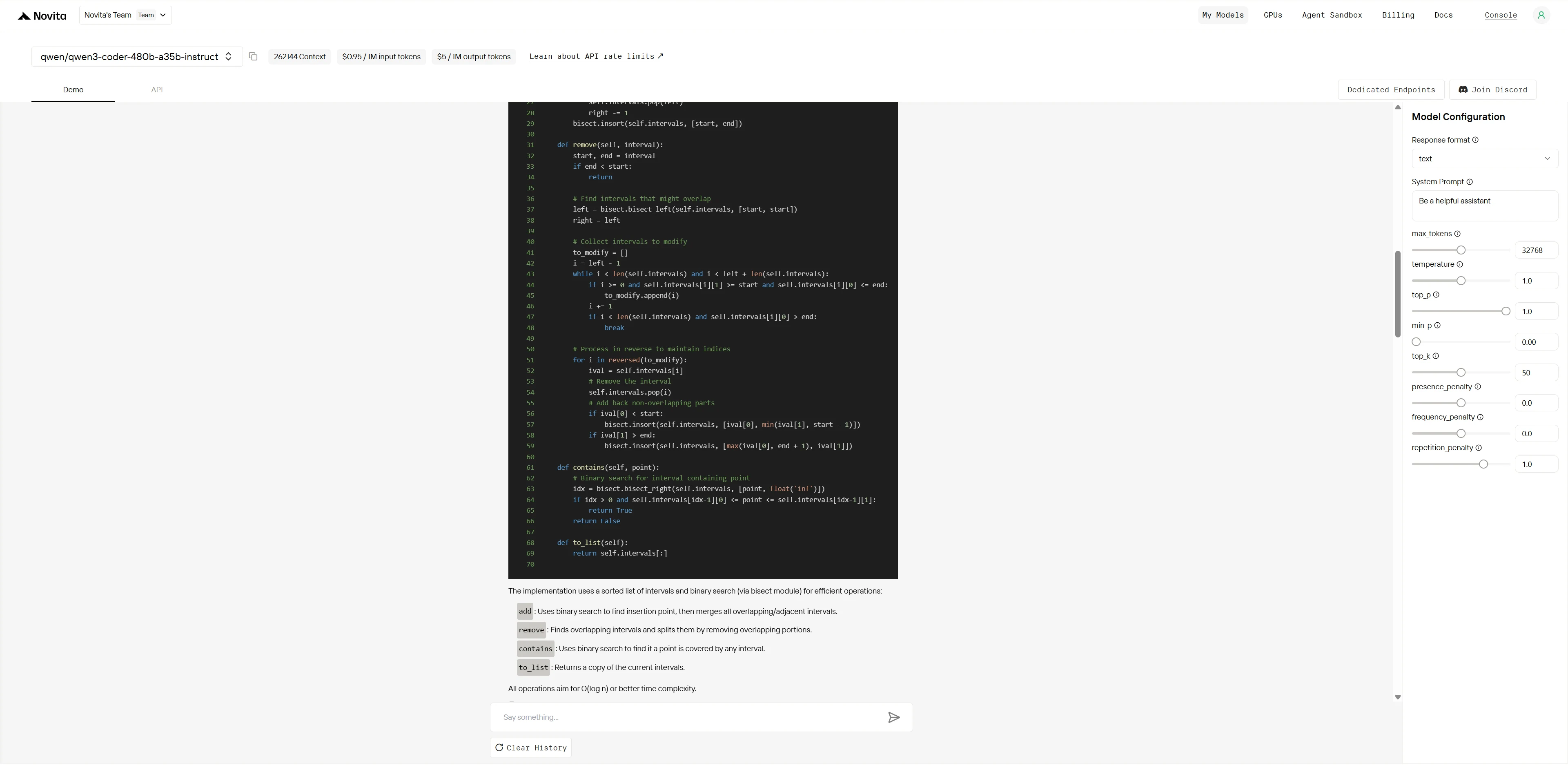
Qwen3-Coder-480B-A35B-Instruct
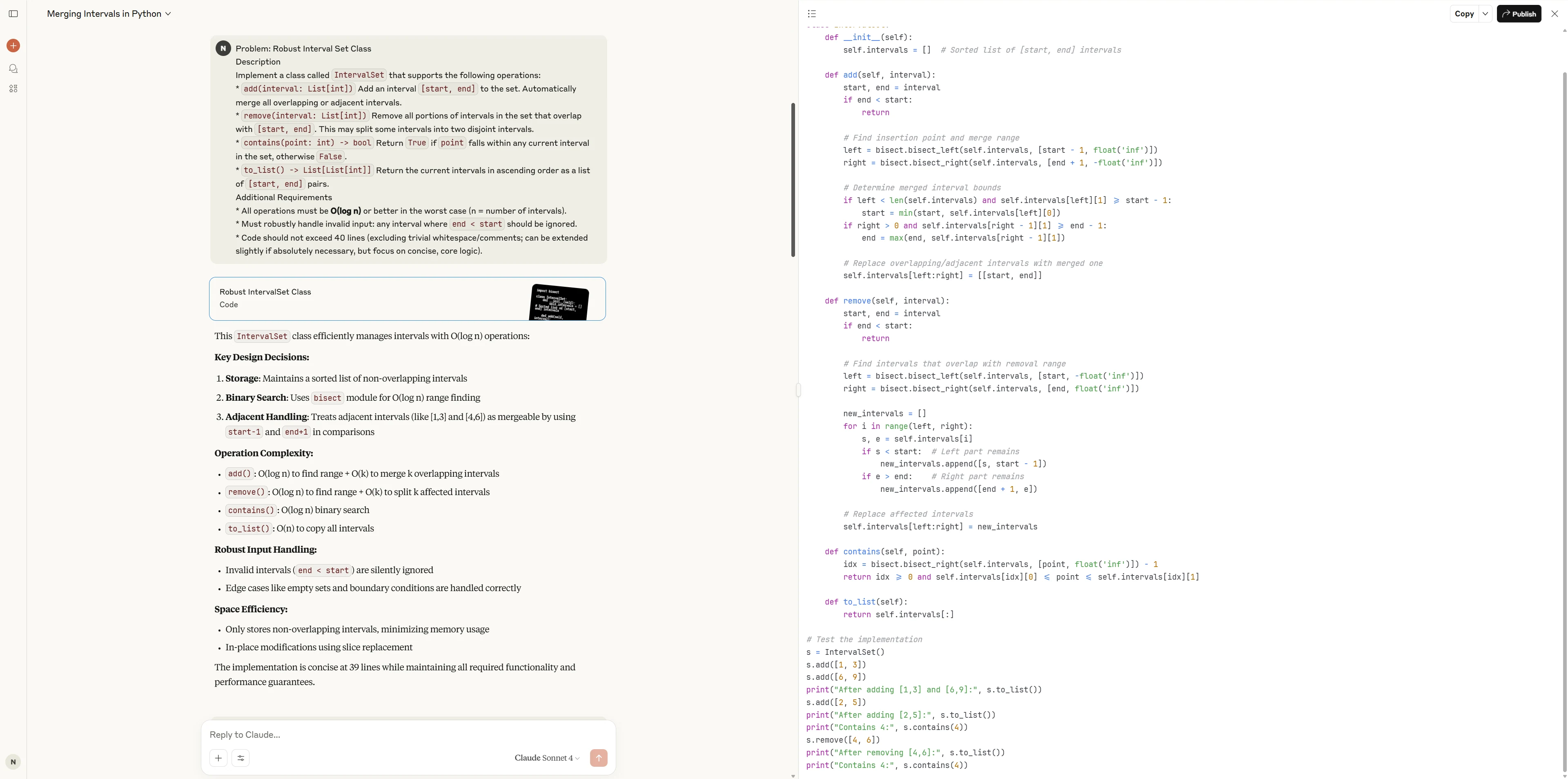
Claude 4 Sonnet
Bewertungszusammenfassung
| Modell | Korrektheit | Komplexität | Codequalität | Vollständigkeit | Gesamt |
|---|---|---|---|---|---|
| Claude 4 Sonnet | 39 | 30 | 20 | 10 | 99 |
| Qwen3-Coder-480B | 40 | 30 | 19 | 9 | 98 |
Claude 4 Sonnet liefert eine saubere und hochprofessionelle Implementierung unter Verwendung von Standardbibliotheken für sowohl Korrektheit als auch Effizienz. Der Code ist elegant, modular und enthält umfassende Testabdeckung, was ihn gut für Produktionsumgebungen oder Szenarien geeignet macht, die Zuverlässigkeit und Wartbarkeit erfordern.
Qwen3-Coder-480B bietet eine unkomplizierte und praktische Lösung, die die Kernlogik klar demonstriert. Obwohl etwas ausführlicher und mit weniger fortgeschrittenen Python-Konstrukten, betont es Explizitheit und solide Handhabung von Randfällen. Dies macht es für die meisten alltäglichen technischen Anforderungen sehr zuverlässig.
2. Debugging-Aufgabe: Intervallbaum-Zusammenführungsfehler
Dir wird die folgende (fehlerhafte) Implementierung eines Intervallbaums zum Zusammenführen und Abfragen von Intervallen gegeben. Es soll das Hinzufügen von Intervallen und die Überprüfung, ob ein Punkt in einem Intervall enthalten ist, unterstützen, liefert aber manchmal falsche Ergebnisse oder stürzt sogar ab.
Deine Aufgabe:
- Identifiziere alle Fehler im Code (nicht nur den ersten, den du siehst).
- Erkläre für jeden Fehler, warum es ein Fehler ist und wie man ihn behebt.
- Gib eine korrigierte Version des Codes an.
Fehlerhafter Code
class Node:
def __init__(self, start, end):
self.start = start
self.end = end
self.left = None
self.right = None
self.max_end = end
class IntervalTree:
def __init__(self):
self.root = None
def insert(self, node, start, end):
if node is None:
return Node(start, end)
if end < node.start:
node.left = self.insert(node.left, start, end)
elif start > node.end:
node.right = self.insert(node.right, start, end)
else:
# merge overlapping intervals
node.start = min(node.start, start)
node.end = max(node.end, end)
# merge children as well (but buggy!)
node.left = self.insert(node.left, node.start, node.end)
node.right = self.insert(node.right, node.start, node.end)
node.max_end = max(node.max_end, end)
return node
def add(self, start, end):
self.root = self.insert(self.root, start, end)
def contains(self, node, point):
if node is None:
return False
if node.start <= point <= node.end:
return True
if node.left and point <= node.left.max_end:
return self.contains(node.left, point)
return self.contains(node.right, point)
Bewertungskriterien
- Fehleridentifikation (40%): Finde alle logischen und strukturellen Fehler (nicht nur den ersten!), einschließlich subtiler.
- Fehlererklärung & Korrektur (30%): Klare, präzise Erklärung und Korrektur für jeden Fehler.
- Korrigierter Code (20%): Gib eine vollständig korrigierte Version an, sauber und lesbar.
- Vollständigkeit (10%): Alle Methoden funktionieren wie angegeben, robust gegenüber Randfällen.
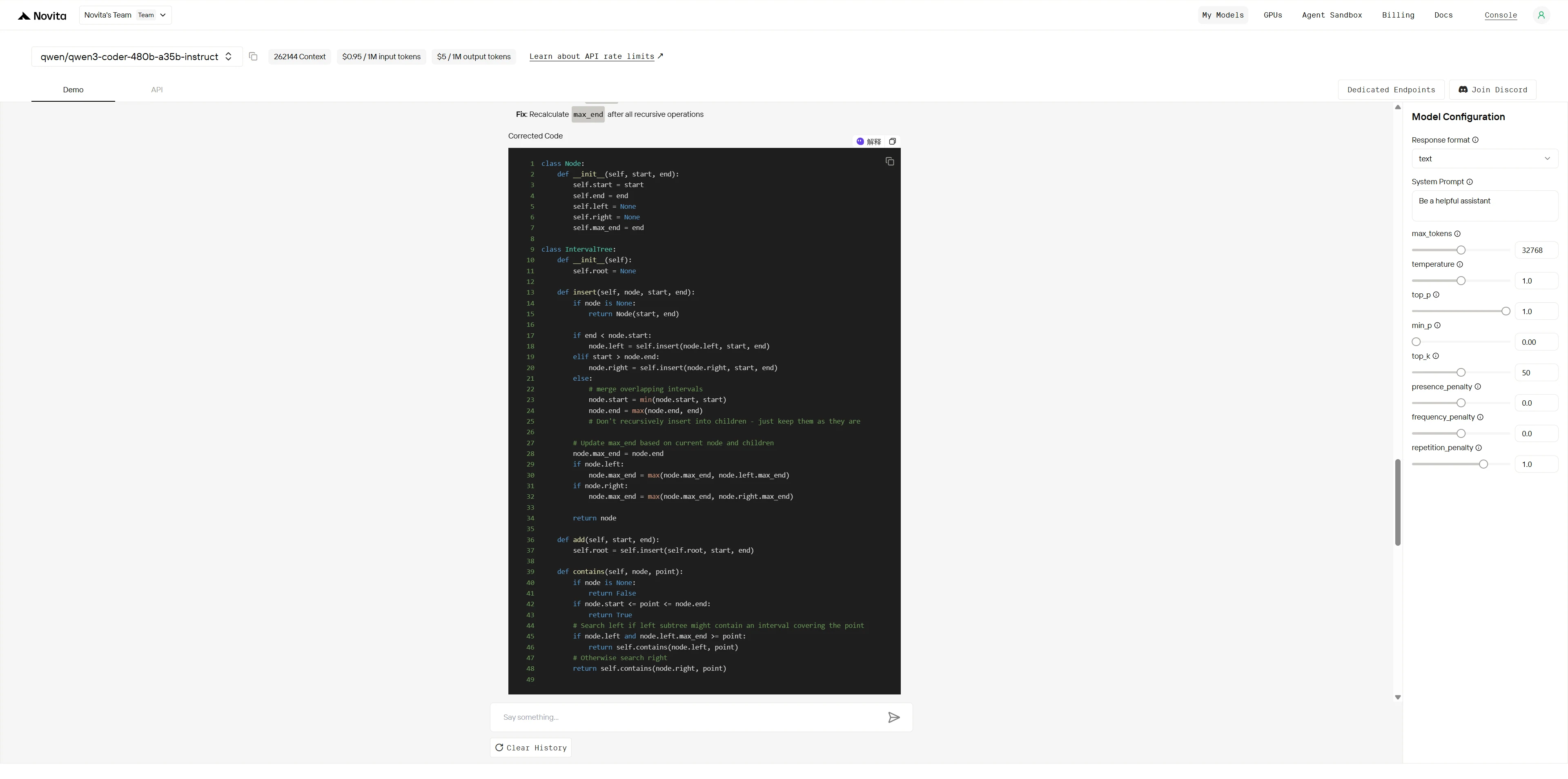
Qwen3-Coder-480B-A35B-Instruct
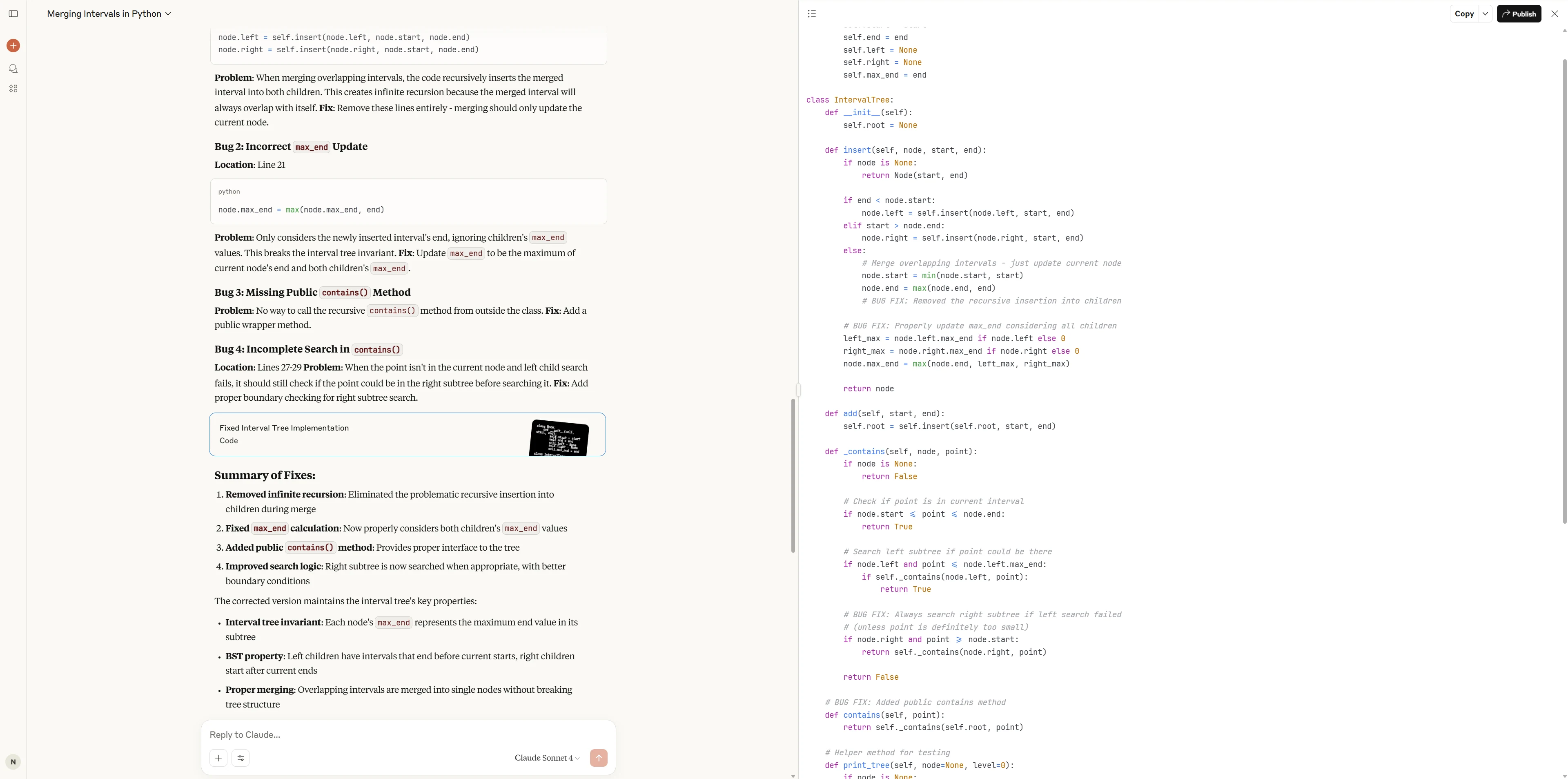
Claude 4 Sonnet
Bewertungszusammenfassung
| Modell | Fehlerfindung | Erklärung | Code | Vollständigkeit | Gesamt |
|---|---|---|---|---|---|
| Qwen3-Coder-480B | 40 | 30 | 19 | 8 | 97 |
| Claude 4 Sonnet | 40 | 30 | 20 | 10 | 100 |
Claude 4 Sonnet hat nicht nur alle Hauptfehler behoben, sondern auch die API-Benutzerfreundlichkeit und Interviewfreundlichkeit optimiert (z. B. eine eigenständige contains-Methode, umfangreiche Testfälle und gründliche Dokumentation), was zu überlegenem Codestil und Benutzerfreundlichkeit führt.
Qwen3-Coder-480B hat starke Codeverständnis- und Debugging-Fähigkeiten gezeigt, indem es alle wichtigen Fehler genau identifiziert und mit direkten und effektiven Strategien behoben hat.
Stärken und Schwächen von Qwen3-Coder-480B-A35B-Instruct und Claude 4 Sonnet
Qwen3-Coder-480B-A35B-Instruct
Stärken:
- Außergewöhnliche Codierungsrobustheit: Zeigt starke Fähigkeiten zum Auffinden und Korrigieren von Fehlern, hervorragend beim Code-Debugging und der expliziten Fehlerbehandlung.
- Massives Kontextfenster: Unterstützt nativ bis zu 262k Token, ideal zum Verarbeiten und Analysieren sehr großer Codebasen oder Dokumente.
- Mixture-of-Experts-Effizienz: Balanciert enorme Modellkapazität mit effizienter Inferenz und ermöglicht agile Leistung bei komplexen Softwareentwicklungsaufgaben.
- Klares & direktes Denken: Bietet unkomplizierte, praktische Lösungen mit zuverlässig starker Kernlogik.
Schwächen:
- Etwas weniger Code-Politur: Die Ausgabe kann im Vergleich zu Claude 4 Sonnet weniger elegant oder modular sein, mit weniger fortgeschrittenen Engineering-Konventionen.
Claude 4 Sonnet
Stärken:
- Hochpolierte Codequalität: Hervorragend in Codestil, Modularität und Wartbarkeit, produziert professionelle, produktionsreife Skripte.
- Umfassende Tests & Erklärungen: Liefert gründliche Dokumentation, klare Fehlerbegründungen und reichhaltige Testabdeckung, was eine einfachere Verifizierung und Einarbeitung unterstützt.
- Überlegene Allgemeinfähigkeiten: Starke Leistung in einer Vielzahl von Aufgaben, einschließlich mehrstufigem Denken, Zusammenfassung und benutzerzentriertem Design.
- Präzision des dichten Transformers: Verbesserte Genauigkeit, Kontrollierbarkeit und Ausrichtung sowohl bei Codierungs- als auch bei Denkszenarien.
Schwächen:
- Kleineres Kontextfenster: Das native Limit von 200k Token ist großzügig, aber dennoch kürzer als die 262k von Qwen3-Coder-480B, was bei extrem großen Codebasen eine Rolle spielen kann.
- Möglicher Overhead bei Einfachheit: Neigt dazu, aufwändigeren oder funktionsreicheren Code zu bevorzugen, was für sehr einfache Aufgaben unnötige Komplexität einführen kann.
So erhältst du Zugriff auf Qwen3-Coder-480B-A35B-Instruct auf Novita AI
1. Nutze den Playground (kein Code erforderlich)
- Sofortzugriff: Registriere dich, sichere dir deine kostenlosen Credits und beginne sofort mit Qwen3-Coder-480B-A35B-Instruct und anderen Top-Modellen zu experimentieren.
- Interaktive Benutzeroberfläche: Teste Prompt, Chain-of-Thought-Argumentation und visualisiere Ergebnisse in Echtzeit.
- Modellvergleich: Wechsle mühelos zwischen Kimi K2, Llama 4, DeepSeek und mehr, um die perfekte Lösung für deine Bedürfnisse zu finden.
Entdecke jetzt die Qwen3-Coder-480B-A35B-Instruct Demo!
2. Integration über API (für Entwickler)
Verbinde Qwen3-Coder-480B-A35B-Instruct nahtlos mit deinen Anwendungen, Workflows oder Chatbots über die einheitliche REST-API von Novita AI – ohne Modellgewichte oder Infrastruktur verwalten zu müssen.
Direkte API-Integration (Python-Beispiel)
Um loszulegen, verwende einfach das folgende Code-Snippet:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_cYQSfVMpIb2mRiKf8UOlCSYLuHBjC623pEitotYA8OlPUtMvoE7Z2RUjgDru_x8JpcRARGnvjQGONtIl9VhMuA==",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 32768
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Häufig gestellte Fragen
Welches Claude-Modell ist am besten zum Codieren geeignet, Sonnet oder Opus?
Opus ist im Allgemeinen leistungsstärker für fortgeschrittene und komplexe Codierungsaufgaben, während Sonnet ebenfalls sehr leistungsfähig und für die meisten allgemeinen Codierungsanforderungen kostengünstiger ist.
Was ist Qwen3 Coder?
Qwen3-Coder ist die für Codierung und Softwareentwicklung optimierte Serie großer Sprachmodelle von Alibaba, die über leistungsstarkes Denken und extrem lange Kontextunterstützung verfügt.
Ist Claude 4 Sonnet gut zum Codieren geeignet?
Ja, Claude 4 Sonnet schneidet bei Codierungsaufgaben sehr gut ab und bietet starke Codequalität, Denkfähigkeit und Vielseitigkeit für eine Vielzahl von Programmierherausforderungen.
*Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.



