

- Qwen 2.5 7B は高度なプログラミングと数学の能力、改善された指示追従、構造化テキスト生成を提供します。
- このモデルは最大 128K トークンのコンテキスト長をサポートし、より包括的で一貫性のある出力を可能にします。
- Novita AI はオープンソースコミュニティを支援・貢献するために Qwen 2.5 7B モデルを無料で提供 しています。
Qwen 2.5 7B は、開発者や研究者の多様なニーズに応えるために設計された強力なオープンソース言語モデルです。主要な分野での大幅な改善により、コミュニティにとって貴重なリソースとして際立っています。以下はこのモデルの主なポイントです:
Qwen 2.5 7B とは?

さらに、モデルファミリーとして、Qwen 2.5 には他のモデルも含まれており、さまざまなパラメータサイズ、コンテキストウィンドウ、特殊なドメイン(汎用、コード、数学)をカバーしています。
Qwen 2.5 ファミリー
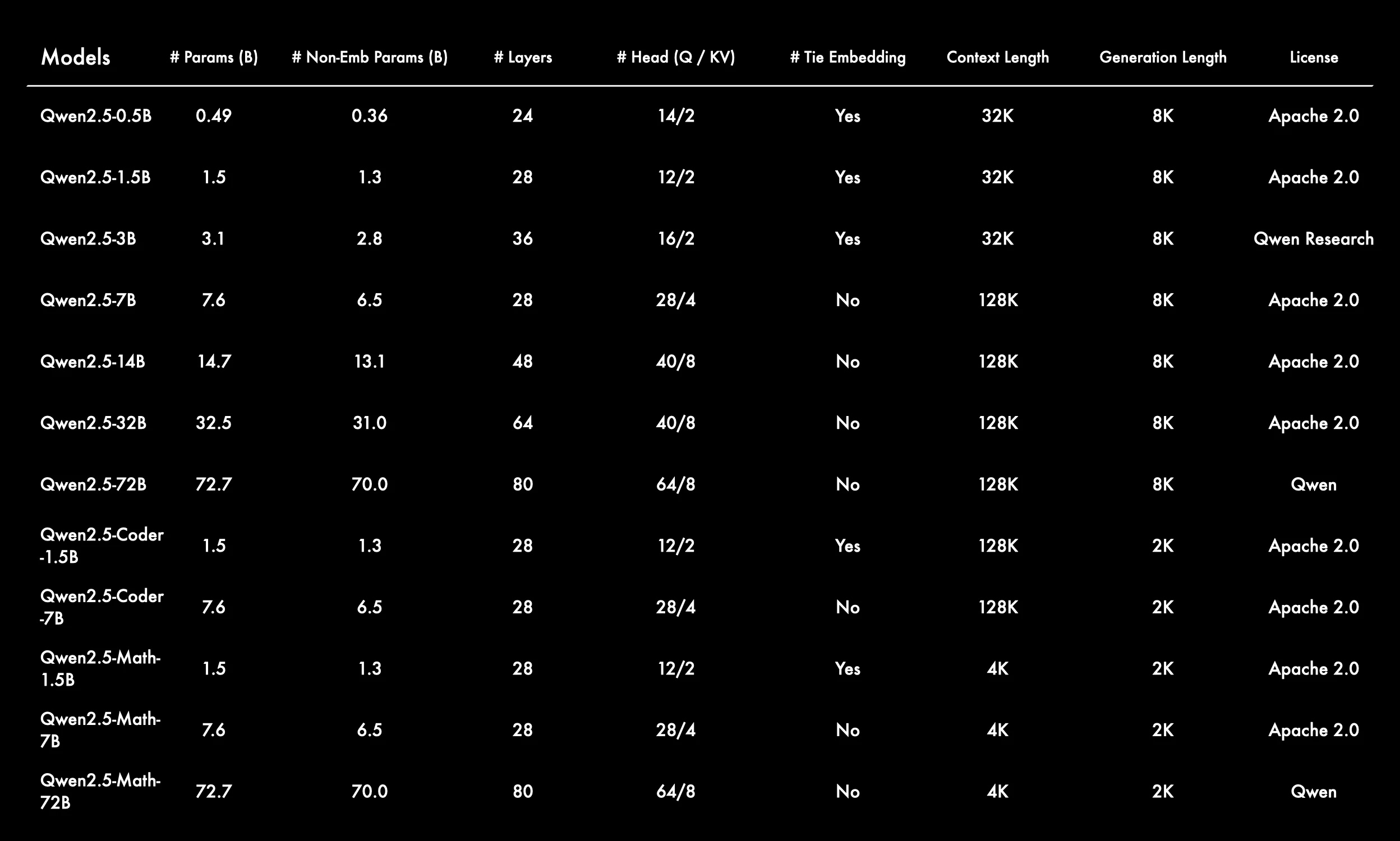
** 多様なモデルアーキテクチャとスケール **
Qwen2.5 シリーズは 0.5B から 72B パラメータまでのモデルサイズをカバーし、軽量から大規模アプリケーションまでのさまざまなシナリオのニーズを満たします。
レイヤー数とアテンションヘッド数 (Q/KV) はモデルサイズの増加に伴い増加し、モデルの複雑さが向上します。
** コンテキストウィンドウと生成長 **
ほとんどのベースモデルは 128K のコンテキスト長を持ち、小型モデル (0.5B, 1.5B, 3B) は 32K、Math バージョンは 4K です。
主流の生成長は 8K で、Coder および Math バージョンは 2K です。
** Tie Embedding の変更 **
小型モデル (0.5B, 1.5B, 3B) およびすべての Coder/Math-1.5B バージョンは Tie Embedding を使用しますが、大型モデルは使用しません。
これにより、小型モデルのパラメータ効率と汎化が向上する可能性があります。
** 豊富なモデルタイプ **
汎用モデルに加えて、Coder (コード特化) および Math (数学特化) サブシリーズもあり、さまざまな垂直ドメインのニーズを満たします。
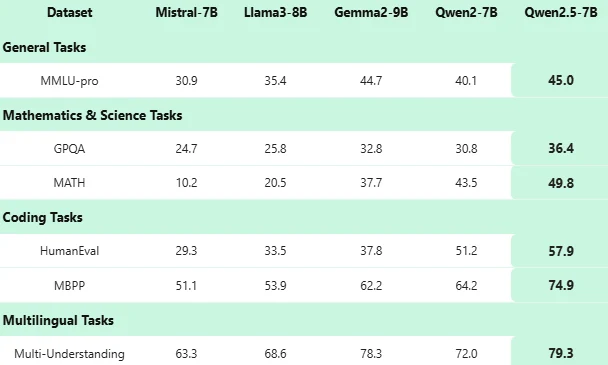
Qwen 2.5 7B ベンチマーク
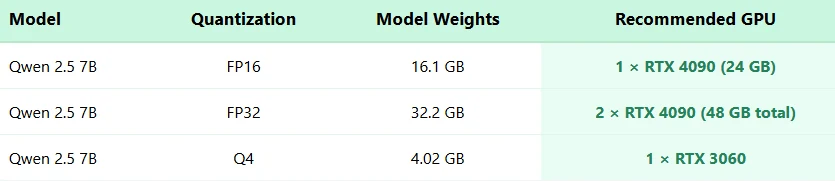
Qwen 2.5 7B ハードウェア要件
Qwen 2.5 7B にアクセスする方法?
** Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームであり、構築とスケーリングのための手頃で信頼性の高い GPU クラウドも提供しています。 **
ステップ 1: ログインしてモデルライブラリにアクセス
アカウントにログインし、** モデルライブラリ ** ボタンをクリックします。

ステップ 2: 無料トライアルを開始
選択したモデルの機能を試すために無料トライアルを開始します。
ステップ 3: API キーを取得
API で認証するために、新しい API キーを提供します。「設定」ページに移動し、画像に示されているように API キーをコピーできます。

ステップ 4: API をインストール
プログラミング言語に固有のパッケージマネージャーを使用して API をインストールします。

インストール後、必要なライブラリを開発環境にインポートします。API キーを使用して API を初期化し、Novita AI LLM との対話を開始します。これは Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-7b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen 2.5 7B は、コード、数学、多言語理解において卓越したパフォーマンスを提供し、オープンソース言語モデルの新たなベンチマークを打ち立てます。その汎用性、スケーラビリティ、効率的なハードウェア使用率により、最先端の AI 機能を求める開発者や企業にとって最良の選択肢となります。
よくある質問
** Qwen 2.5 7B は類似モデルと比較してどうですか? **
Qwen 2.5 7B は、数学、コーディング、一般的なベンチマーク、特に長文脈および構造化データタスクにおいて、多くの同等モデルを上回ります。
** Qwen 2.5 7B にアクセスするには? **
Novita AI プラットフォームを介して Qwen 2.5 7B をデプロイできます。このプラットフォームは簡単な API 統合とスケーラブルな GPU クラウドソリューションを提供します。
** Qwen 2.5 7B のハードウェア要件は? **
FP16 精度には、1 枚の RTX 4090 (24GB) をお勧めします。FP32 には 2 枚の RTX 4090 GPU が必要です。Q4 量子化では、RTX 3060 で実行できます。
Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームであり、構築とスケーリングのための手頃で信頼性の高い GPU クラウドも提供しています。



