

- Qwen 2.5 7B offre des capacités avancées en programmation et en mathématiques, un meilleur suivi des instructions et une génération de texte structurée.
- Le modèle prend en charge des longueurs de contexte allant jusqu’à 128K tokens, permettant des sorties plus complètes et cohérentes.
- Novita AI propose le modèle Qwen 2.5 7B gratuitement pour soutenir et contribuer à la communauté open-source.
Qwen 2.5 7B est un puissant modèle de langage open-source conçu pour répondre aux divers besoins des développeurs et des chercheurs. Avec des améliorations significatives dans les domaines clés, il se distingue comme une ressource précieuse pour la communauté. Voici les principaux points à retenir sur ce modèle :
Qu’est-ce que Qwen 2.5 7B ?

De plus, en tant que famille de modèles, Qwen 2.5 comprend également d’autres modèles, couvrant différentes tailles de paramètres, fenêtres de contexte et domaines spécialisés (général, code et mathématiques).
La famille Qwen 2.5
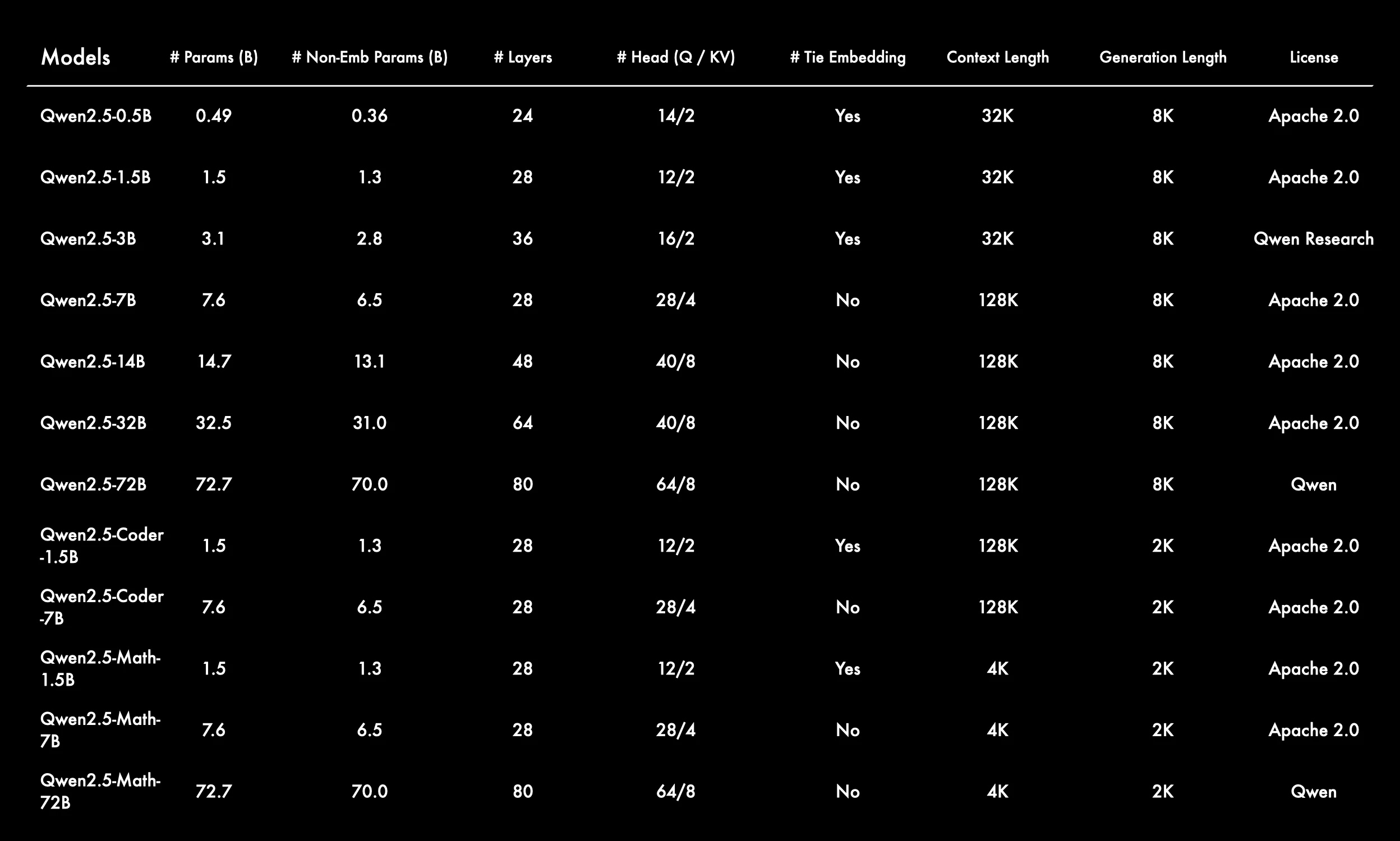
Architectures et échelles de modèles diversifiées
La série Qwen2.5 couvre des tailles de modèles allant de 0,5B à 72B paramètres, répondant aux besoins de divers scénarios, des applications légères aux applications à grande échelle.
Le nombre de couches et de têtes d’attention (Q/KV) augmente avec la taille du modèle, ce qui accroît la complexité du modèle.
Fenêtre de contexte et longueur de génération
La plupart des modèles de base ont une longueur de contexte de 128K, tandis que les modèles plus petits (0,5B, 1,5B, 3B) en ont 32K, et les versions Math en ont 4K.
La longueur de génération courante est de 8K, tandis que les versions Coder et Math ont 2K.
Changements dans le Tie Embedding
Les modèles plus petits (0,5B, 1,5B, 3B) et toutes les versions Coder/Math-1.5B utilisent Tie Embedding, contrairement aux modèles plus grands.
Cela peut améliorer l’efficacité des paramètres et la généralisation pour les modèles plus petits.
Types de modèles riches
En plus des modèles à usage général, il existe également des sous-séries Coder (spécialisées dans le code) et Math (spécialisées dans les mathématiques), répondant aux besoins de différents domaines verticaux.
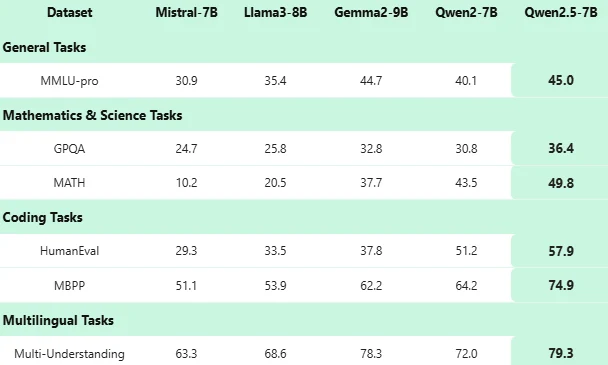
Benchmark de Qwen 2.5 7B
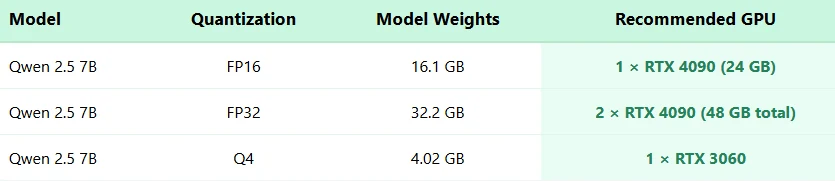
Configuration matérielle requise pour Qwen 2.5 7B
Comment accéder à Qwen 2.5 7B ?
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez Qwen 2.5 7B maintenant !
Étape 2 : Commencez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 3 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué dans l’image.

Étape 4 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<VOTRE_CLÉ_API_Novita_AI>",
)
model = "qwen/qwen2.5-7b-instruct"
stream = True # ou False
max_tokens = 2048
system_content = """Soyez un assistant utile"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen 2.5 7B établit une nouvelle référence parmi les modèles de langage open-source, offrant des performances exceptionnelles en codage, mathématiques et compréhension multilingue. Sa polyvalence, son évolutivité et son utilisation efficace du matériel en font un choix de premier ordre pour les développeurs et les entreprises à la recherche de capacités d’IA de pointe.
Foire aux questions
Comment Qwen 2.5 7B se compare-t-il à des modèles similaires ?
Qwen 2.5 7B surpasse de nombreux modèles comparables en mathématiques, en codage et dans les benchmarks généraux, en particulier dans les tâches à long contexte et avec des données structurées.
Comment puis-je accéder à Qwen 2.5 7B ?
Vous pouvez déployer Qwen 2.5 7B via la plateforme Novita AI, qui offre une intégration API facile et des solutions GPU cloud évolutives.
Quels sont les besoins matériels pour Qwen 2.5 7B ?
Pour une précision FP16, un seul RTX 4090 (24 Go) est recommandé. Pour FP32, deux RTX 4090 sont nécessaires. Avec la quantification Q4, il peut fonctionner sur un RTX 3060.
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.



