

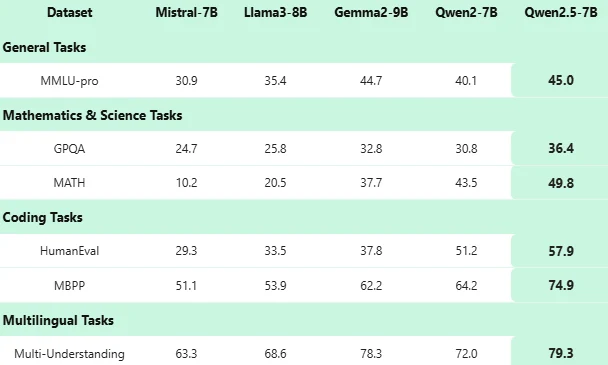
- Qwen 2.5 7B bietet erweiterte Programmier- und Mathematikfähigkeiten, verbesserte Befolgung von Anweisungen und strukturierte Textgenerierung.
- Das Modell unterstützt Kontextlängen von bis zu 128K Tokens, was umfassendere und kohärentere Ausgaben ermöglicht.
- Novita AI bietet das Qwen 2.5 7B-Modell kostenlos an , um die Open-Source-Community zu unterstützen und zu fördern.
Qwen 2.5 7B ist ein leistungsstarkes Open-Source-Sprachmodell, das entwickelt wurde, um die vielfältigen Anforderungen von Entwicklern und Forschern zu erfüllen. Mit erheblichen Verbesserungen in Schlüsselbereichen hebt es sich als wertvolle Ressource für die Community hervor. Nachfolgend sind die wichtigsten Punkte dieses Modells zusammengefasst:
Was ist Qwen 2.5 7B?

Darüber hinaus umfasst Qwen 2.5 als Modellfamilie auch andere Modelle, die verschiedene Parameteranzahlen, Kontextfenster und spezialisierte Domänen (Allgemein, Code und Mathematik) abdecken.
Qwen 2.5 Familie
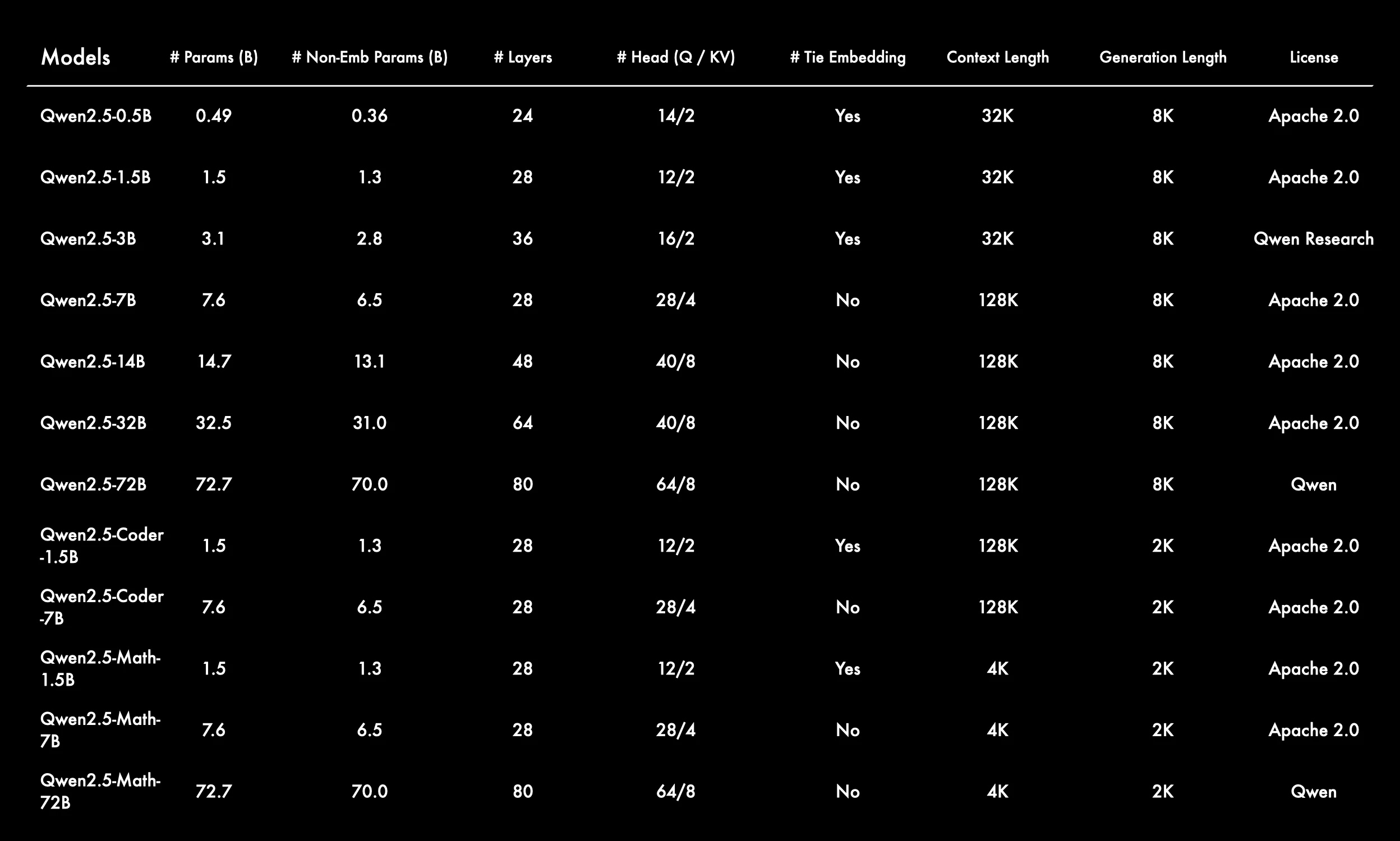
Verschiedene Modellarchitekturen und -größen
Die Qwen2.5-Serie deckt Modellgrößen von 0,5B bis 72B Parametern ab und erfüllt die Anforderungen verschiedener Szenarien von leichtgewichtig bis groß angelegt.
Die Anzahl der Schichten und Aufmerksamkeitsköpfe (Q/KV) steigt mit der Modellgröße, was zu einer höheren Modellkomplexität führt.
Kontextfenster und Generierungslänge
Die meisten Basismodelle haben eine Kontextlänge von 128K, während kleinere Modelle (0,5B, 1,5B, 3B) 32K und Mathematik-Versionen 4K haben.
Die gängige Generierungslänge beträgt 8K, während Coder- und Mathematik-Versionen 2K haben.
Änderungen bei Tie Embedding
Kleinere Modelle (0,5B, 1,5B, 3B) und alle Coder/Math-1.5B-Versionen verwenden Tie Embedding, größere Modelle dagegen nicht.
Dies kann dazu beitragen, die Parametereffizienz und Generalisierung bei kleineren Modellen zu verbessern.
Reichhaltige Modelltypen
Neben den allgemeinen Modellen gibt es auch Coder- (codespezialisiert) und Math- (mathematikspezialisiert) Unterserien, die die Anforderungen verschiedener vertikaler Domänen erfüllen.
Qwen 2.5 7B Benchmark
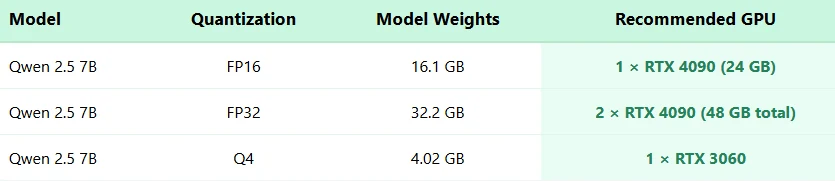
Qwen 2.5 7B Hardware-Anforderungen
Wie erhalte ich Zugang zu Qwen 2.5 7B?
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für den Aufbau und die Skalierung bereitstellt.
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche „Model Library“.

Schritt 2: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 3: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Gehen Sie auf die Seite „Settings“, um den API-Schlüssel wie im Bild gezeigt zu kopieren.

Schritt 4: Installieren Sie die API
Installieren Sie die API mit dem Paketmanager Ihrer Programmiersprache.

Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit der Interaktion mit Novita AI LLM zu beginnen. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-7b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen 2.5 7B setzt einen neuen Maßstab bei Open-Source-Sprachmodellen und bietet herausragende Leistung in den Bereichen Codierung, Mathematik und mehrsprachiges Verständnis. Seine Vielseitigkeit, Skalierbarkeit und effiziente Hardwarenutzung machen es zur ersten Wahl für Entwickler und Unternehmen, die modernste KI-Fähigkeiten suchen.
Häufig gestellte Fragen
Wie schneidet Qwen 2.5 7B im Vergleich zu ähnlichen Modellen ab?
Qwen 2.5 7B übertrifft viele vergleichbare Modelle in Mathematik, Codierung und allgemeinen Benchmarks, insbesondere bei Aufgaben mit langem Kontext und strukturierten Daten.
Wie kann ich auf Qwen 2.5 7B zugreifen?
Sie können Qwen 2.5 7B über die Novita AI-Plattform bereitstellen, die eine einfache API-Integration und skalierbare GPU-Cloud-Lösungen bietet.
Welche Hardwareanforderungen gibt es für Qwen 2.5 7B?
Für FP16-Genauigkeit wird eine einzelne RTX 4090 (24 GB) empfohlen. Für FP32 werden zwei RTX 4090 GPUs benötigt. Mit Q4-Quantisierung kann es auf einer RTX 3060 ausgeführt werden.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für den Aufbau und die Skalierung bereitstellt.



