

- Qwen 2.5 7B delivers advanced programming and math abilities, improved instruction following, and structured text generation.
- The model supports context lengths of up to 128K tokens, enabling more comprehensive and coherent outputs.
- Novita AI offers the Qwen 2.5 7B model for free to support and contribute to the open-source community.
Qwen 2.5 7B is a powerful open-source language model designed to meet the diverse needs of developers and researchers. With significant improvements across key areas, it stands out as a valuable resource for the community. Below are the main takeaways of this model:
What is Qwen 2.5 7B?

In addition, as a model family, Qwen 2.5 also includes other models, covering different parameter sizes, context windows, and specialized domains (general, code, and math).
Qwen 2.5 Family
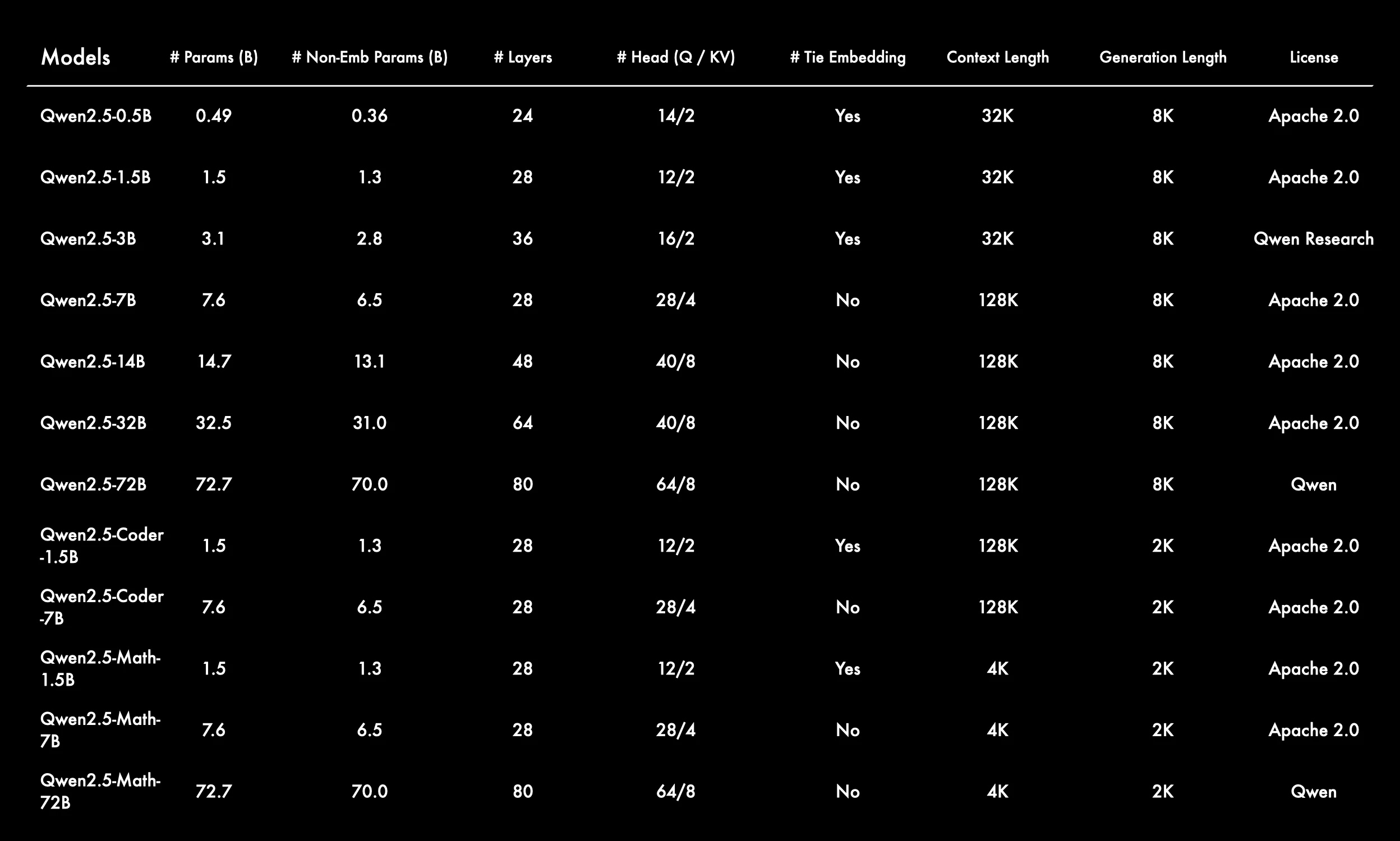
Diverse Model Architectures and Scales
The Qwen2.5 series covers model sizes ranging from 0.5B to 72B parameters, meeting the needs of various scenarios from lightweight to large-scale applications.
The number of layers and attention heads (Q/KV) increases with model size, resulting in greater model complexity.
Context Window and Generation Length
Most base models have a context length of 128K, while smaller models (0.5B, 1.5B, 3B) have 32K, and Math versions have 4K.
The mainstream generation length is 8K, while Coder and Math versions have 2K.
Changes in Tie Embedding
Smaller models (0.5B, 1.5B, 3B) and all Coder/Math-1.5B versions use Tie Embedding, while larger models do not.
This may help improve parameter efficiency and generalization for smaller models.
Rich Model Types
In addition to general-purpose models, there are also Coder (code-specialized) and Math (math-specialized) sub-series, meeting the needs of different vertical domains.
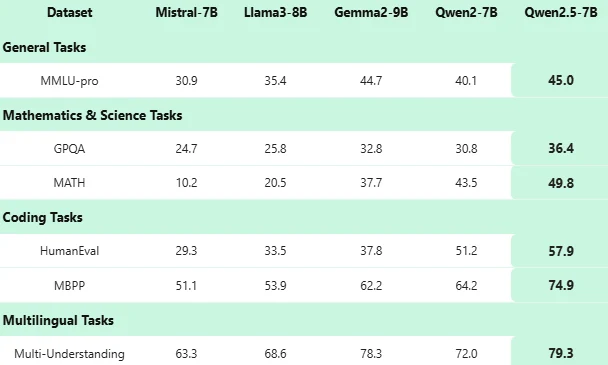
Qwen 2.5 7B Benchmark
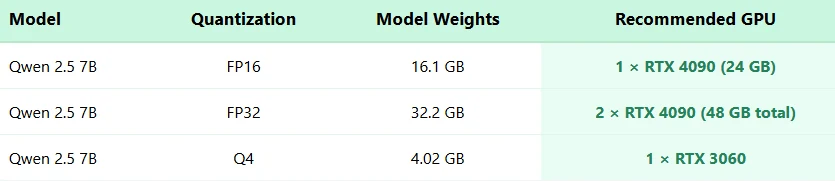
Qwen 2.5 7B Hardware Requiremnets
How to Access Qwen 2.5 7B?
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 3: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 4: Install the API
Install API using the package manager specific to your programming language.

After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-7b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)Qwen 2.5 7B sets a new benchmark in open-source language models, offering outstanding performance across coding, mathematics, and multilingual understanding. Its versatility, scalability, and efficient hardware usage make it a top choice for developers and enterprises seeking state-of-the-art AI capabilities.
Frequently Asked Questions
How does Qwen 2.5 7B compare to similar models?
Qwen 2.5 7B outperforms many peer models in mathematics, coding, and general benchmarks, especially in long-context and structured data tasks.
How can I access Qwen 2.5 7B?
You can deploy Qwen 2.5 7B via the Novita AI platform, which offers easy API integration and scalable GPU cloud solutions.
What are the hardware requirements for Qwen 2.5 7B?
For FP16 precision, a single RTX 4090 (24GB) is recommended. For FP32, two RTX 4090 GPUs are needed. With Q4 quantization, it can run on an RTX 3060.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing an affordable and reliable GPU cloud for building and scaling.



