

Key Hightlights
GLM-4.5 : A foundation model unifies reasoning, coding, and intelligent agent capabilities to meet the complex demands of intelligent agent applications.
Kimi K2 : General-purpose model with enterprise-grade reliability, optimized for production-ready code generation and cost-effective development workflows.
Novita AI not only provides stable API services but also offers extremely cost-effective pricing. For example, GLM-4.5 costs $0.6 per 1M input tokens and $2.2 per 1M output tokens, while Kimi K2 costs $0.57 per 1M input tokens and $2.3 per 1M output tokens.
Basic Introduction of Model
GLM-4.5
GLM-4.5 is a foundation model designed for intelligent agents with 355 billion total parameters and 32 billion active parameters. The model unifies reasoning, coding, and intelligent agent capabilities to meet the complex demands of intelligent agent applications. GLM-4.5 is a hybrid reasoning model that provides two modes: thinking mode for complex reasoning and tool usage, and non-thinking mode for immediate responses.
Key Features and Architecture
- Parameters: 355 billion total parameters with 32 billion active parameters.
- Hybrid Reasoning: Two operational modes - thinking mode for complex reasoning and tool usage, and non-thinking mode for immediate responses.
- Model Versions: Available in base models, hybrid reasoning models, and FP8 versions.
- Context Window: 128K tokens.
- Licensing: MIT open-source license for commercial use and secondary development.
- Capabilities: Unified reasoning, coding, and intelligent agent functionalities for complex applications.
Kimi K2
Kimi K2 is a breakthrough large-scale language model developed by Moonshot AI, released in July 2025. It features an innovative Mixture-of-Experts (MoE) architecture with 1 trillion total parameters and 32 billion parameters activated per forward pass, enabling efficient scaling and high performance. Kimi K2 is meticulously optimized for agentic intelligence, meaning it can autonomously plan, reason, use tools, and synthesize code with multi-step problem-solving capabilities.
Key Features and Architecture
- Architecture: MoE with 384 experts, selecting 8 per token during inference to balance efficiency and capability.
- Parameters: 1 trillion total, 32 billion active at a time.
- Context Window: 128K tokens.
- Training: Trained on 15.5 trillion tokens using Moonshot’s proprietary MuonClip optimizer to maintain training stability.
- Languages: Primarily optimized for Chinese and English.
- Disk Space: Full model requires approximately 1.09 TB.
Benchmark Comparison of GLM-4.5 and Kimi K2
1. Intelligence Benchmarks
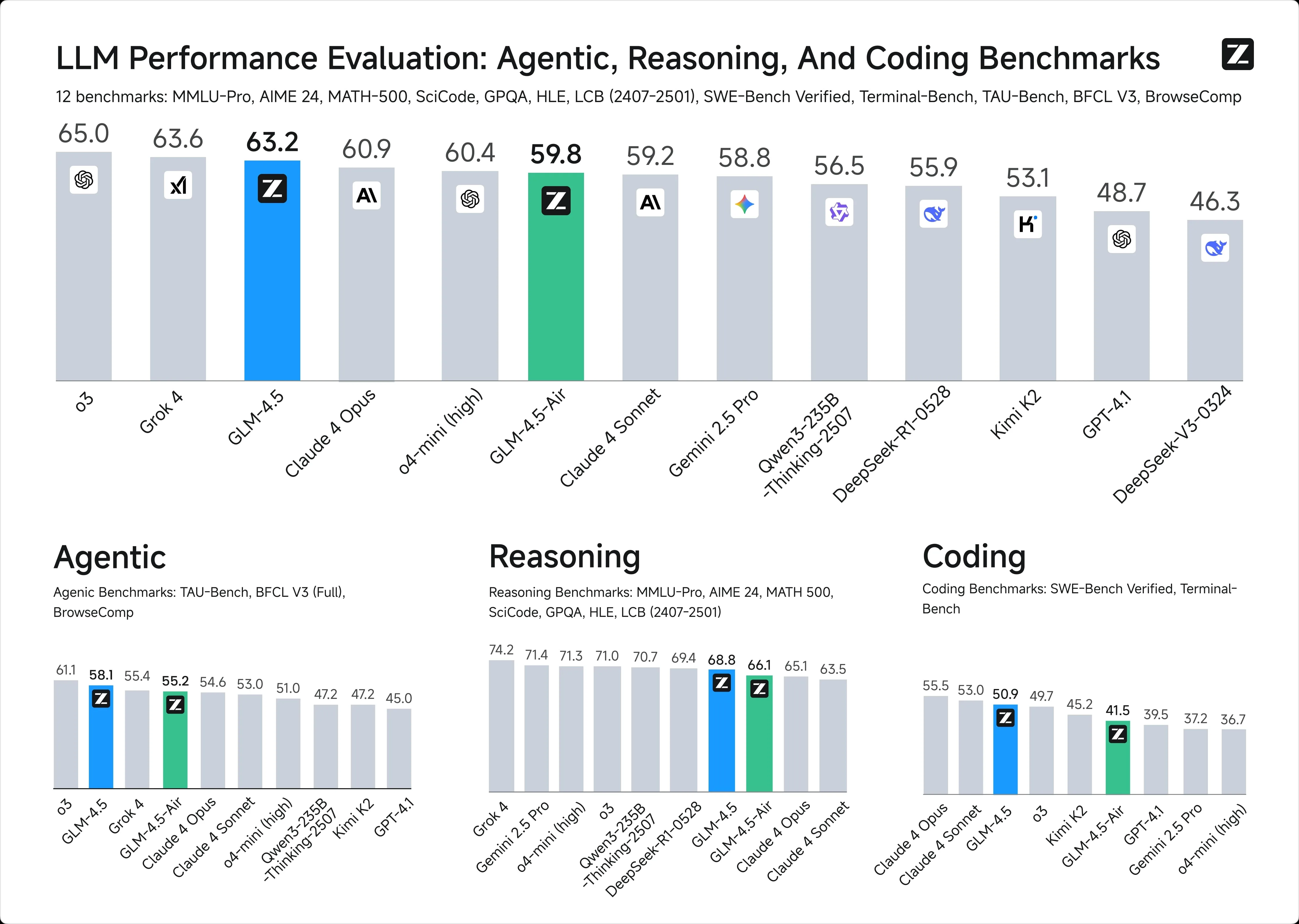
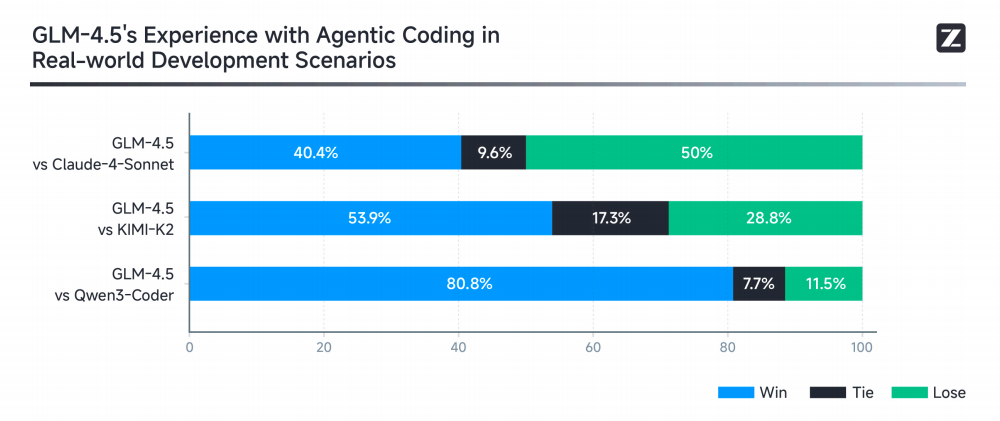
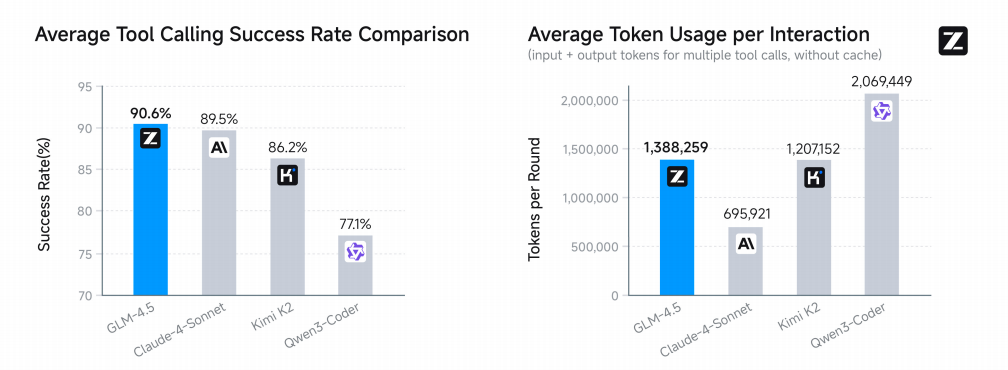
2. API Pricing:
GLM-4.5: $0.6 / $2.2 in/out per 1M Tokens
Kimi K2: $0.57 / $2.3 in/out per 1M Tokens
Applied Skills Test of GLM-4.5 and Kimi K2
1. Coding Challenge
Prompt:
Implement a function to merge overlapping intervals and return the result sorted by start time.
Input: List of intervals as tuples [(start, end), …]
Output: List of merged intervals
Constraint: Handle edge cases and optimize for readability
Example:
intervals = [(1,3), (2,6), (8,10), (15,18)]
Expected output: [(1,6), (8,10), (15,18)]
intervals = [(1,4), (4,5)]
Expected output: [(1,5)]Scoring Criteria (10 points):
- Algorithm Correctness (4 points): Correctly merges overlapping intervals, handles edge cases (empty list, single interval, touching intervals)
- Code Efficiency (3 points): Optimal approach (sort first, then merge in one pass), clean logic
- Code Quality (2 points): Readable variable names, proper structure, handles input validation
- Edge Case Handling (1 point): Explicitly handles corner cases like empty input, single interval, etc.
GLM-4.5
Kimi K2
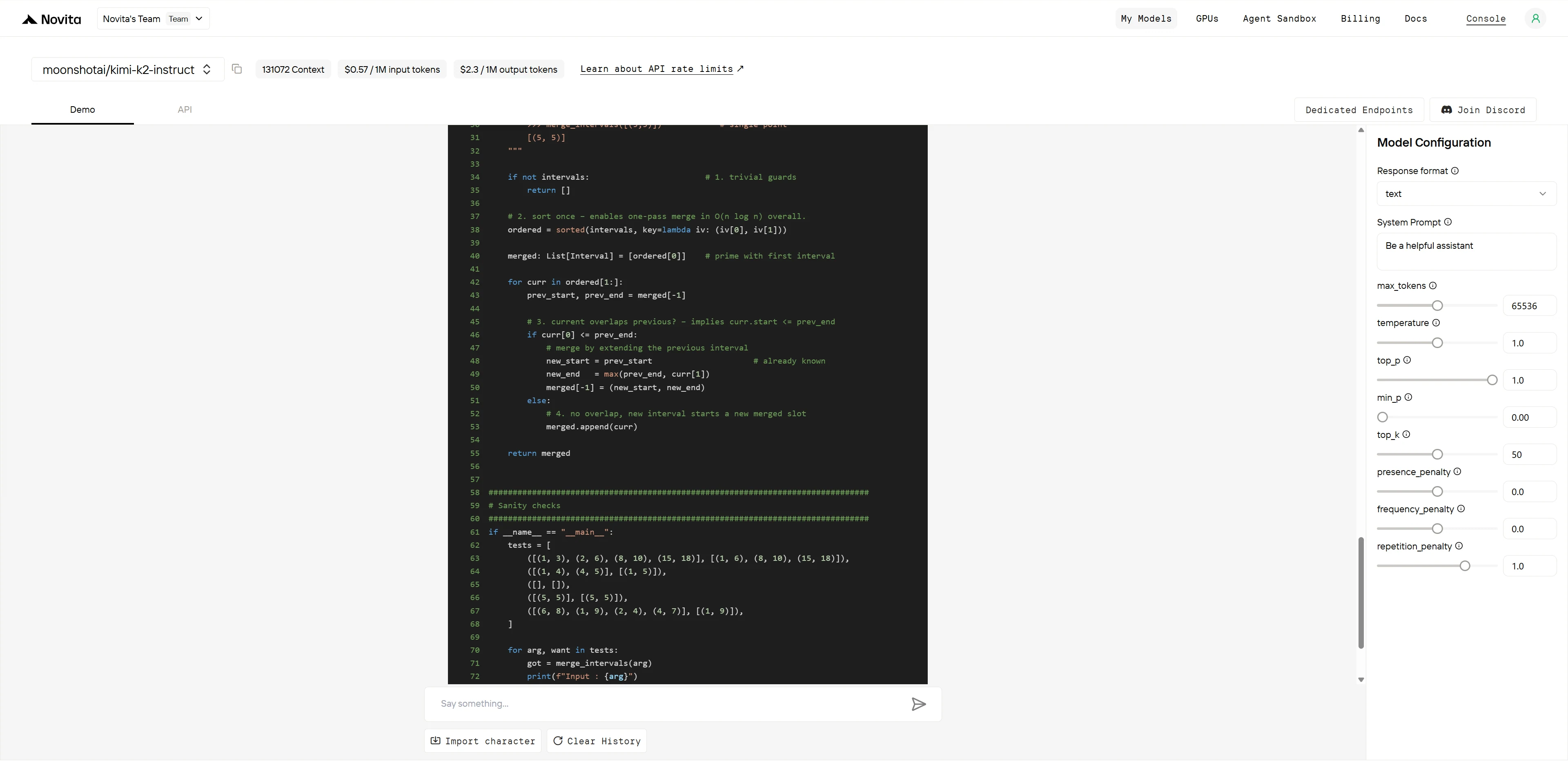
Performance Comparison Table
| Aspect | Kimi K2 | GLM-4.5 |
|---|---|---|
| Algorithm Correctness | 4/4 | 4/4 |
| Code Efficiency | 3/3 | 3/3 |
| Code Quality | 2/2 | 1/2 |
| Edge Case Handling | 1/1 | 0.5/1 |
| Total Score | 10/10 | 8.5/10 |
Overall Assessment
Kimi K2 excels as a production-ready solution, featuring comprehensive type annotations, detailed documentation, complete test suites, and professional code organization. It represents the approach of an experienced software engineer who prioritizes maintainability, reliability, and industry best practices. The code is immediately deployable and follows enterprise-level standards.
GLM-4.5 shines as an educational tool, providing exceptionally clear algorithmic explanations, step-by-step reasoning, and accurate complexity analysis. While the core implementation is correct and concise, it prioritizes conceptual understanding over engineering polish. This approach resembles that of a skilled computer science instructor focused on teaching algorithmic thinking.
Kimi K2 optimizes for engineering excellence and production readiness, while GLM-4.5 optimizes for conceptual clarity and pedagogical value. Both approaches have merit depending on the context - whether you need robust, maintainable code for a production system or clear, educational content for learning algorithms.
2. Handle Ambiguous Queries Challenge
Prompt:
Analyze this ambiguous request and provide your interpretation strategy:
"I need to process the data from last quarter's performance metrics to generate insights for the upcoming board meeting. The numbers should reflect our competitive position and growth trajectory."
Tasks:
1. Identify 3 key ambiguities in this request
2. Propose clarifying questions for each ambiguity
3. Make reasonable assumptions and explain your reasoning
4. Outline a structured approach to handle such vague requirementsScoring Criteria (10 points):
- Ambiguity Identification (3 points): Correctly identifies unclear aspects (data source, metrics definition, output format, etc.)
- Clarifying Questions Quality (3 points): Questions are specific, actionable, and address the core uncertainties
- Assumption Reasoning (2 points): Logical assumptions with clear justification
- Systematic Approach (2 points): Demonstrates a structured methodology for handling ambiguous requests
GLM-4.5
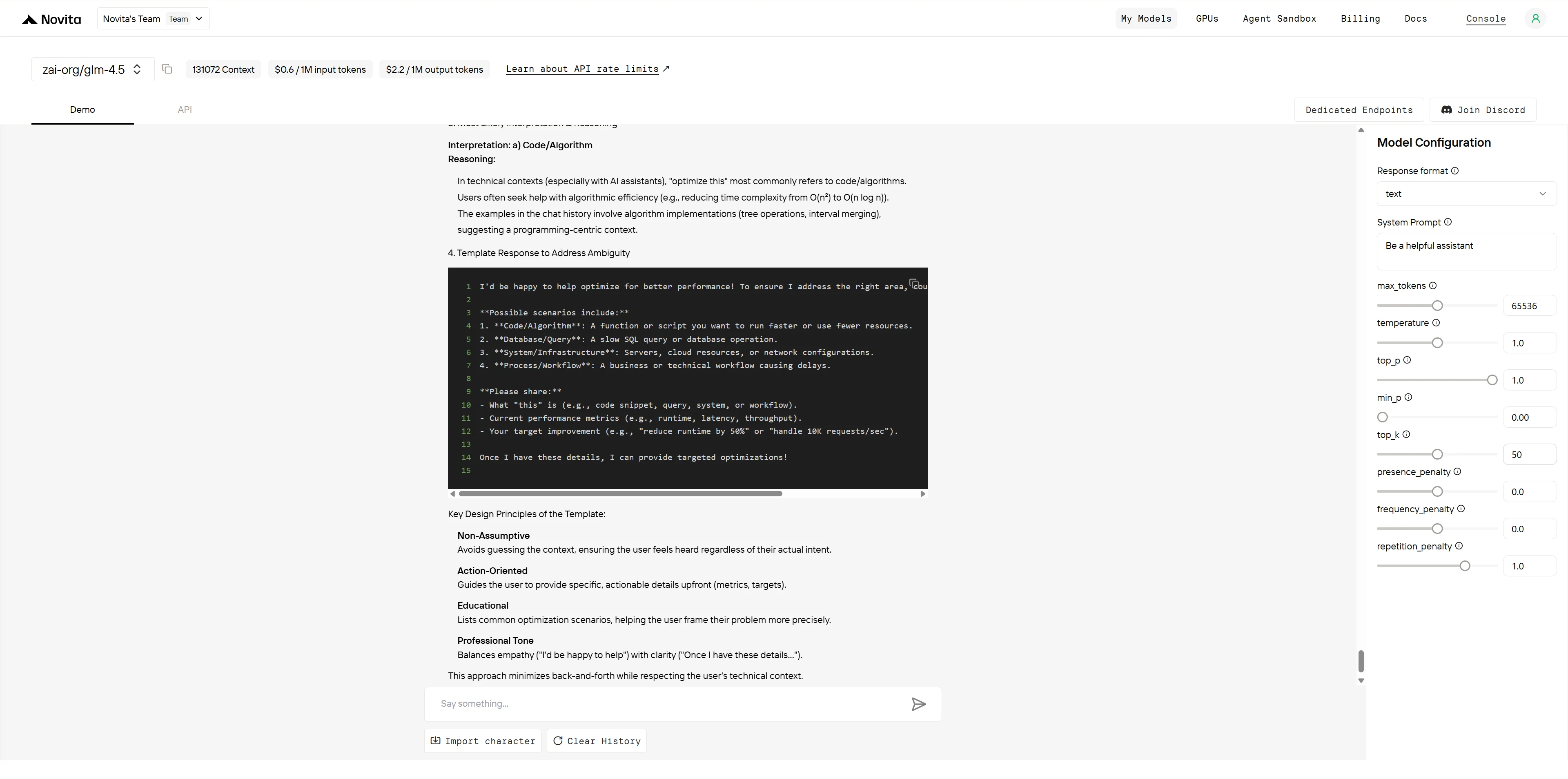
Kimi K2
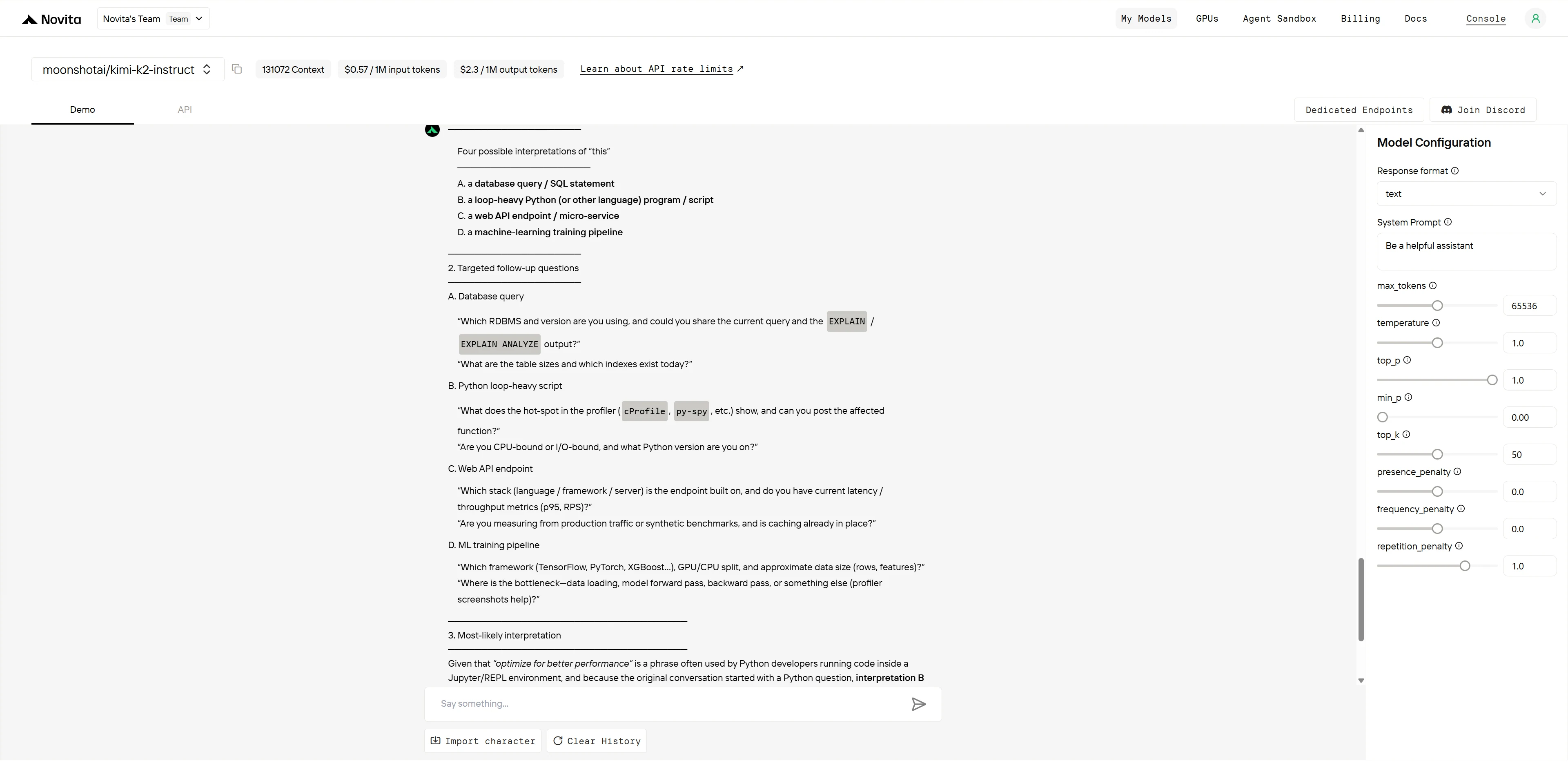
Performance Comparison Table
| Aspect | Kimi K2 | GLM-4.5 |
|---|---|---|
| Ambiguity Identification | 3/3 | 3/3 |
| Clarifying Questions Quality | 3/3 | 2/3 |
| Assumption Reasoning | 2/2 | 2/2 |
| Systematic Approach | 2/2 | 2/2 |
| Total Score | 10/10 | 9/10 |
Overall Assessment
The minimal scoring difference (10 vs 9) reflects that both models handle ambiguous communication exceptionally well. Kimi K2’s edge comes from the technical precision and immediate actionability of its questions, which would likely lead to faster problem resolution in real-world technical scenarios. GLM-4.5’s approach, while slightly less technically specific, provides excellent educational value and comprehensive coverage that would be highly valuable in training or consultation contexts.
Strengths & Weaknesses
GLM-4.5
Strengths
- Hybrid Reasoning Architecture: Unique thinking/non-thinking modes optimize for both complex reasoning and rapid responses
- Agent-Native Design: Purpose-built for intelligent agent applications with native tool usage capabilities
- Educational Excellence: Superior structured explanations and knowledge transfer abilities
- Lightweight Deployment: 32B active parameters enable resource-efficient deployment
- Comprehensive Coverage: Systematic analysis covering all scenarios and possibilities
Weaknesses
- Limited Technical Depth: Less specialized domain expertise compared to production-focused models
- Generic Problem-Solving: Questions and solutions tend to be broader rather than laser-focused
- Production Readiness Gap: Lacks enterprise-level code quality and deployment maturity
Kimi K2
Strengths
- MoE Efficiency: 1T parameters with 32B active - superior computational efficiency at scale
- Production Engineering: Enterprise-grade code quality with comprehensive testing and documentation
- Technical Expertise: Deep domain knowledge with highly specific, actionable diagnostics
- Bilingual Optimization: Specialized Chinese-English performance with cultural context understanding
- Training Stability: Advanced MuonClip optimizer ensures robust and reliable outputs
Weaknesses
- High Resource Requirements: 1.09TB disk space demands significant hardware infrastructure
How to Access GLM-4.5 and Kimi K2 on Novita AI
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.
Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.
Step 5: Install the API
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Both GLM-4.5 and Kimi K2 represent distinct approaches to large language model design, each excelling in complementary domains.
GLM-4.5’s hybrid reasoning architecture and agent-native capabilities make it exceptionally well-suited for educational applications and intelligent agent development, providing comprehensive explanations and systematic problem-solving approaches. Conversely, Kimi K2’s MoE architecture and production-grade engineering deliver superior technical depth and operational reliability, making it ideal for enterprise environments requiring precise, actionable solutions. While GLM-4.5’s educational strengths and deployment flexibility favor research and learning scenarios, Kimi K2’s engineering maturity and specialized expertise position it as the preferred choice for production systems and technical problem-solving where accuracy and efficiency are paramount.
You can also use Kimi K2 in Claude Code for enhanced agentic coding capabilities with significant cost savings . Learn how to set up Kimi K2 with Claude Code.
Frequently Asked Questions
What is Kimi K2?
Kimi K2 is a general-purpose AI model developed by Moonshot AI that offers reliable code generation, strong domain expertise, and cost-effective pricing at $0.57-2.30 per 1M tokens.
What is GLM short for?
GLM stands for “General Language Model,” representing a family of large language models developed by Zhipu AI that emphasizes general-purpose natural language understanding and generation capabilities.
How to fit a GLM model?
GLM models can be deployed through official APIson platforms like Novita AI, with specific setup instructions varying by model version and hardware requirements.
About Novita AI
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



