

Découvrez l’évolution et les avancées des systèmes de génération augmentée par récupération (RAG). Apprenez comment le RAG améliore les grands modèles de langage (LLM) avec des connaissances externes.
Introduction
La génération augmentée par récupération (RAG) se présente comme une solution prometteuse pour répondre aux défis inhérents au travail avec les grands modèles de langage (LLM), notamment les lacunes de connaissances spécifiques, les problèmes de factualité et les hallucinations. En intégrant des sources de connaissances externes comme des bases de données, le RAG améliore les LLM, les rendant particulièrement précieux dans des environnements riches en connaissances ou des applications spécifiques nécessitant des connaissances à jour. Contrairement à d’autres méthodes, le RAG ne nécessite pas de réentraînement des LLM pour des tâches spécifiques, ce qui constitue un avantage significatif. Sa popularité récente, en particulier dans les agents conversationnels, souligne sa pertinence.
Une enquête récente de Gao et al. (2023) fournit des informations précieuses sur les principales conclusions, les implications pratiques et les approches de pointe du RAG. L’enquête examine divers composants des systèmes RAG, notamment les techniques de récupération, de génération et d’augmentation, en analysant leurs méthodologies d’évaluation, leurs applications et les technologies associées.
Qu’est-ce que le RAG
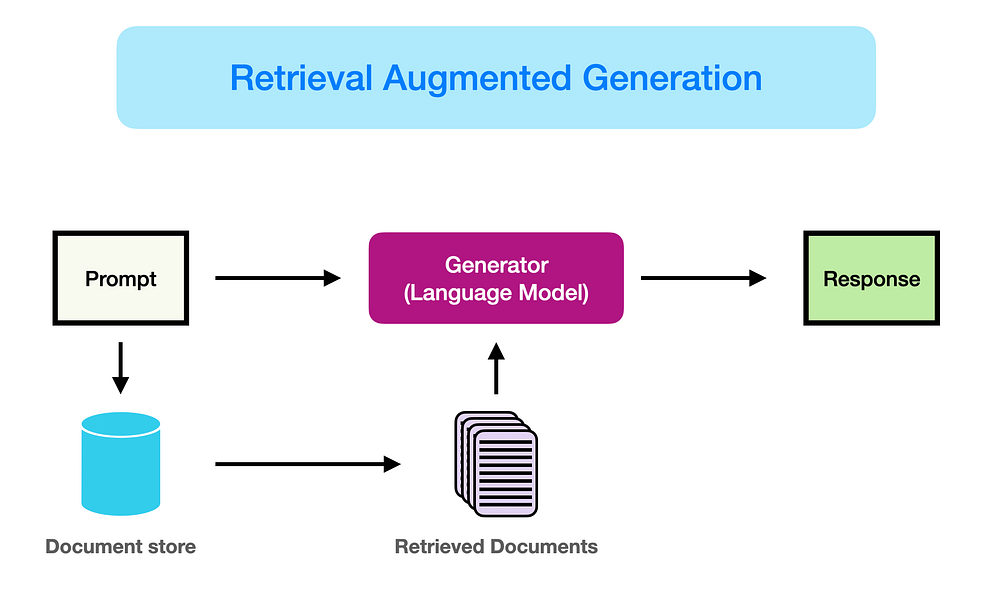
La génération augmentée par récupération (RAG) améliore les performances des grands modèles de langage en incorporant des références provenant de bases de connaissances externes faisant autorité, complétant ainsi les vastes données d’entraînement du modèle. Les grands modèles de langage (LLM) exploitent d’immenses jeux de données et des milliards de paramètres pour générer des réponses à des tâches telles que la réponse aux questions, la traduction linguistique et la complétion de texte. Le RAG étend les capacités des LLM en les adaptant à des domaines spécifiques ou à des bases de connaissances organisationnelles internes, sans nécessiter de réentraînement du modèle. Cette approche offre un moyen économique d’améliorer la sortie des LLM pour garantir sa pertinence, sa précision et son utilité dans divers contextes.
Composants clés du RAG
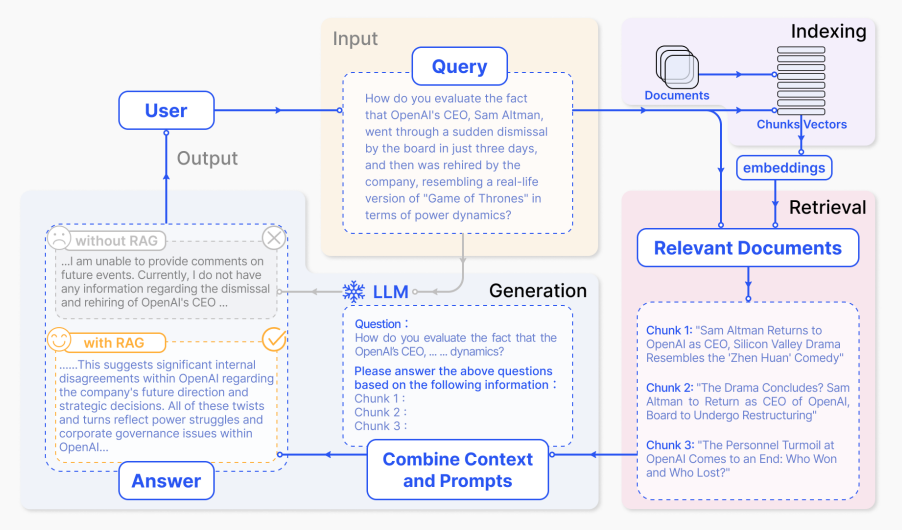
Nous pouvons décomposer le processus en les étapes/composants suivants :
- Entrée : Il s’agit de la question posée au système de LLM. Sans RAG, le LLM répond directement à cette question.
- Indexation : Lorsque le RAG est utilisé, un ensemble de documents connexes est indexé. Cela implique de diviser les documents en morceaux, de créer des embeddings pour ces morceaux, puis de les indexer dans un magasin vectoriel. Lors de l’inférence, la requête est également encodée de la même manière.
- Récupération : Les documents pertinents sont récupérés en comparant la requête aux vecteurs indexés, ce qui donne une sélection de « Documents pertinents ».
- Génération : Les documents récupérés sont fusionnés avec l’invite originale pour fournir un contexte supplémentaire. Ce texte combiné et l’invite sont ensuite introduits dans le modèle pour générer une réponse, produisant ainsi le résultat final pour l’utilisateur.
Dans un exemple donné, se fier uniquement au modèle sans RAG peut ne pas répondre correctement en raison d’un manque de connaissances à jour. À l’inverse, l’utilisation du RAG permet au système d’accéder aux informations nécessaires pour répondre précisément à la question.
Paradigmes du RAG
Ces dernières années, on a assisté à une évolution des systèmes RAG, passant du RAG naïf au RAG avancé et au RAG modulaire. Cette progression visait à surmonter des défis spécifiques liés aux performances, au coût et à l’efficacité.
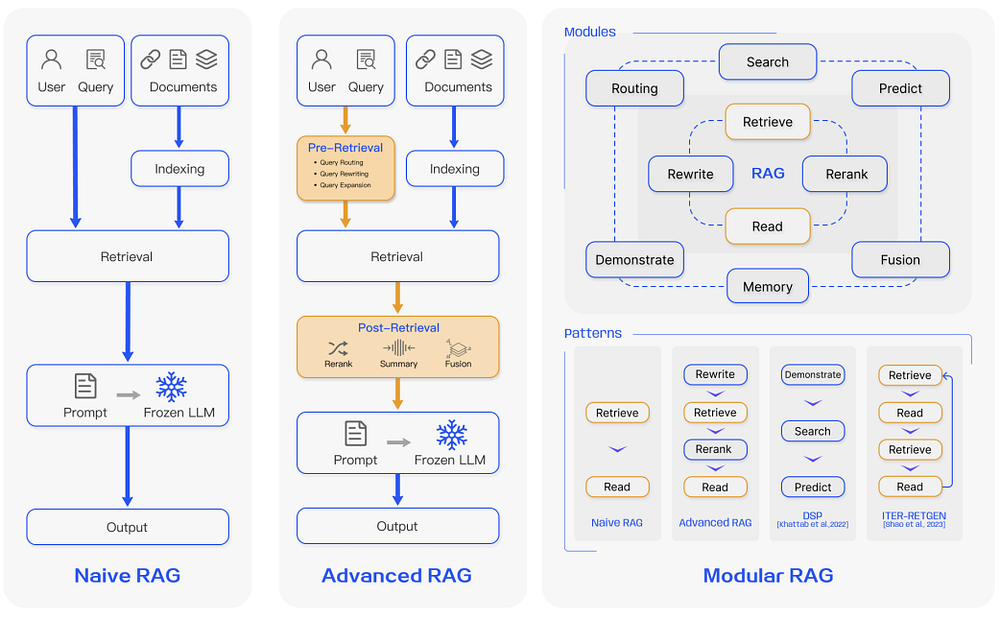
RAG naïf
Le RAG naïf fonctionne à travers le processus conventionnel d’indexation, de récupération et de génération décrit précédemment. En substance, il utilise l’entrée de l’utilisateur pour interroger les documents pertinents, qui sont ensuite amalgamés avec une invite et fournis au modèle pour générer une réponse finale. Si l’application implique des interactions de dialogue à plusieurs tours, l’historique de la conversation peut être intégré dans l’invite.
Cependant, le RAG naïf a ses limites, notamment des problèmes de faible précision (résultant en des morceaux récupérés mal alignés) et de faible rappel (incapacité à récupérer tous les morceaux pertinents). Il existe également un risque que le LLM reçoive des informations obsolètes, une préoccupation majeure que les systèmes RAG visent à résoudre en premier lieu. Cela peut entraîner des problèmes d’hallucination et la génération de réponses médiocres et inexactes.
De plus, lorsque l’augmentation est mise en œuvre, des préoccupations concernant la redondance et la répétition peuvent survenir. La gestion de plusieurs passages récupérés implique des considérations de classement et de conciliation du style et du ton. En outre, un défi majeur consiste à garantir que la tâche de génération ne repose pas excessivement sur les informations augmentées, ce qui pourrait amener le modèle à simplement répéter le contenu récupéré.
RAG avancé
Le RAG avancé offre des solutions aux lacunes observées dans le RAG naïf, notamment en améliorant la qualité de la récupération. Cette amélioration englobe l’optimisation des processus de pré-récupération, de récupération et de post-récupération.
La phase de pré-récupération implique d’affiner l’indexation des données à travers cinq étapes clés : améliorer la granularité des données, optimiser les structures d’index, ajouter des métadonnées, optimiser l’alignement et la récupération mixte. Ces mesures visent à élever la qualité des données indexées.
L’amélioration supplémentaire de la phase de récupération peut être obtenue en optimisant le modèle d’embedding lui-même. Cette optimisation influence directement la qualité des morceaux de contexte. Les stratégies peuvent inclure le fine-tuning des embeddings pour améliorer la pertinence de la récupération ou l’utilisation d’embeddings dynamiques qui capturent mieux les nuances contextuelles (par exemple, le modèle embeddings-ada-02 d’OpenAI).
L’optimisation post-récupération se concentre sur la limitation des limites de fenêtre de contexte et la gestion des informations parasites ou perturbatrices. Le reclassement est une approche courante pour relever ces défis, impliquant des techniques telles que le déplacement du contexte pertinent vers les bords de l’invite ou le recalcul de la similarité sémantique entre la requête et les morceaux de texte pertinents. Les techniques de compression d’invite peuvent également aider à gérer ces problèmes.
RAG modulaire
Le RAG modulaire, comme son nom l’indique, améliore les modules fonctionnels au sein du cadre de génération augmentée par récupération. Il implique l’intégration de modules tels qu’un module de recherche pour la récupération par similarité et l’application de fine-tuning dans le récupérateur. Le RAG naïf et le RAG avancé peuvent tous deux être considérés comme des instances spécifiques du RAG modulaire, comprenant des modules fixes. Cependant, le RAG étendu introduit des modules supplémentaires comme la recherche, la mémoire, la fusion, le routage, la prédiction et l’adaptateur de tâche, chacun répondant à des défis distincts. Ces modules peuvent être reconfigurés pour s’adapter à des contextes de tâche spécifiques, offrant ainsi au RAG modulaire une plus grande diversité et flexibilité. Cette flexibilité permet d’ajouter, remplacer ou ajuster des modules en fonction des exigences de la tâche.
Avec la flexibilité accrue dans la construction de systèmes RAG, diverses techniques d’optimisation ont été proposées pour affiner les pipelines RAG :
- Exploration hybride de recherche : Cette approche combine des techniques de recherche telles que la recherche par mots-clés et la recherche sémantique pour récupérer des informations pertinentes et riches en contexte, particulièrement utiles pour traiter divers types de requêtes et besoins d’information.
- Récupération récursive et moteur de requête : Cela implique un processus de récupération récursif qui commence par de petits morceaux sémantiques et récupère progressivement des morceaux plus grands pour enrichir le contexte, établissant un équilibre entre efficacité et richesse contextuelle.
- StepBack-prompt : Cette technique de sollicitation permet aux LLM d’abstraire des concepts et des principes, guidant le raisonnement vers des réponses mieux fondées. L’adoption de cette technique dans un cadre RAG permet aux LLM de dépasser les instances spécifiques et de raisonner plus largement si nécessaire.
- Sous-requêtes : Différentes stratégies de requête, telles que les requêtes arborescentes ou l’interrogation séquentielle de morceaux, peuvent être employées pour divers scénarios. Par exemple, LlamaIndex propose un moteur de requête par sous-questions, décomposant une requête en plusieurs questions qui utilisent différentes sources de données pertinentes.
- Hypothetical Document Embeddings (HyDE) : HyDE génère une réponse hypothétique à une requête, l’encode, et l’utilise pour récupérer des documents similaires à la réponse hypothétique au lieu d’utiliser directement la requête.
Cadre du RAG
Cette section résume les avancées significatives dans les composants d’un système RAG : Récupération, Génération et Augmentation.
Récupération
La récupération dans un système RAG implique de récupérer un contexte très pertinent à partir d’un récupérateur, ce qui peut être amélioré par divers moyens :
Amélioration des représentations sémantiques :
L’amélioration des stratégies de fragmentation est cruciale pour choisir la stratégie la plus appropriée en fonction du contenu et des exigences de l’application. Différents modèles peuvent exceller avec différentes tailles de blocs, par exemple les sentence transformers pour des phrases uniques et text-embedding-ada-002 pour des blocs contenant 256 ou 512 tokens. L’expérimentation avec différentes stratégies de fragmentation est courante pour optimiser la récupération dans un système RAG, en tenant compte de facteurs tels que la longueur des questions de l’utilisateur, l’application et les limites de tokens.
Le fine-tuning des modèles d’embedding peut être nécessaire pour des domaines spécialisés afin de garantir que les requêtes des utilisateurs soient comprises avec précision. Des modèles d’embedding comme BGE-large-EN développé par BAAI peuvent être affinés pour des connaissances spécifiques ou des tâches en aval afin d’optimiser la pertinence de la récupération.
Alignement des requêtes et des documents :
Les techniques de réécriture de requêtes, telles que Query2Doc, ITER-RETGEN et HyDE, se concentrent sur le raffinement des requêtes qui manquent d’informations sémantiques ou qui contiennent des formulations imprécises.
La transformation des embeddings optimise les embeddings de requêtes pour les aligner sur un espace latent plus étroitement lié à la tâche.
Alignement du récupérateur et du LLM :
Le fine-tuning des récupérateurs utilise les signaux de rétroaction des LLM pour affiner les modèles de récupération. Les exemples incluent l’adaptateur de récupération augmentée (AAR), REPLUG et UPRISE.
L’incorporation d’adaptateurs externes, tels que PRCA, RECOMP et PKG, facilite le processus d’alignement entre les récupérateurs et les LLM.
Génération
Le générateur au sein d’un système RAG joue un rôle central en transformant les informations récupérées en texte cohérent, constituant finalement la sortie finale du modèle. Ce processus implique souvent des données d’entrée diverses, nécessitant des efforts pour affiner l’adaptation du modèle de langage à l’entrée dérivée des requêtes et des documents. Ces améliorations peuvent être obtenues grâce à des processus post-récupération et au fine-tuning :
Post-récupération avec LLM gelé : Cette approche se concentre sur l’amélioration de la qualité des résultats de récupération sans modifier le LLM lui-même. Des opérations telles que la compression d’informations et le reclassement des résultats sont utilisées. La compression d’informations aide à réduire le bruit, à traiter les limitations de longueur de contexte et à améliorer les effets de génération, tandis que le reclassement réordonne les documents pour prioriser les éléments les plus pertinents en haut.
Fine-tuning du LLM pour le RAG : Une optimisation ou un fine-tuning supplémentaire du générateur garantit que le texte généré est à la fois naturel et utilise efficacement les documents récupérés, améliorant ainsi les performances globales du système RAG.
Augmentation
L’augmentation englobe le processus d’intégration transparente du contexte des passages récupérés avec la tâche de génération en cours. Avant d’approfondir le processus d’augmentation, y compris ses étapes et ses données, établissons d’abord une taxonomie des composants fondamentaux du RAG.
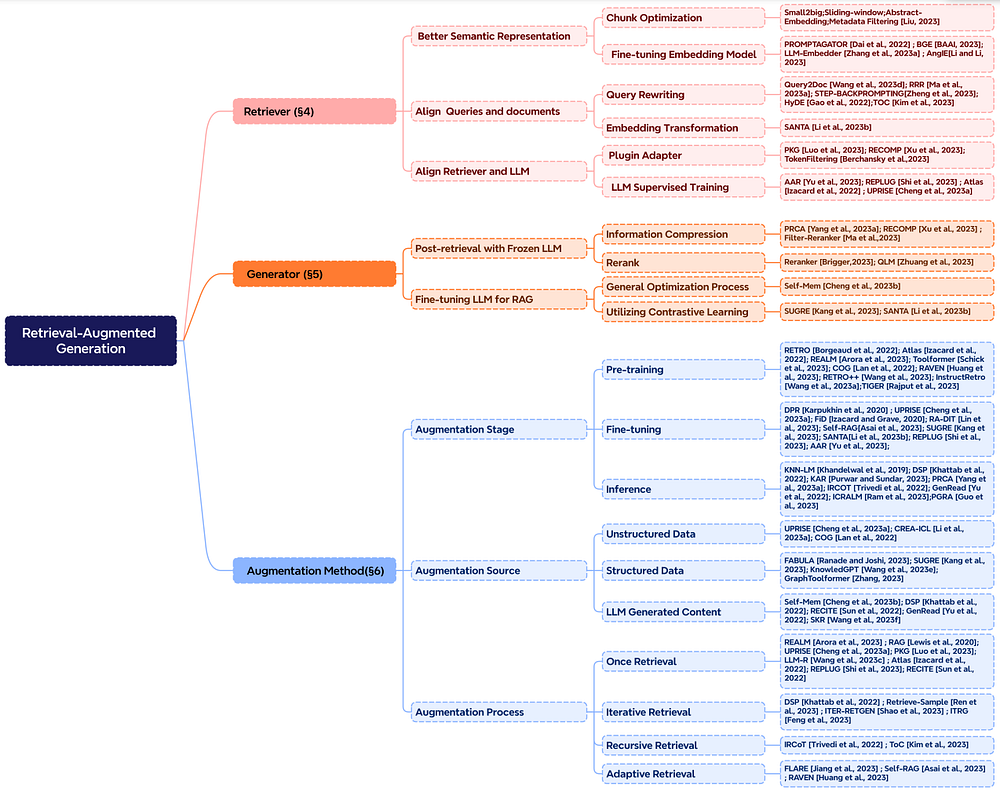
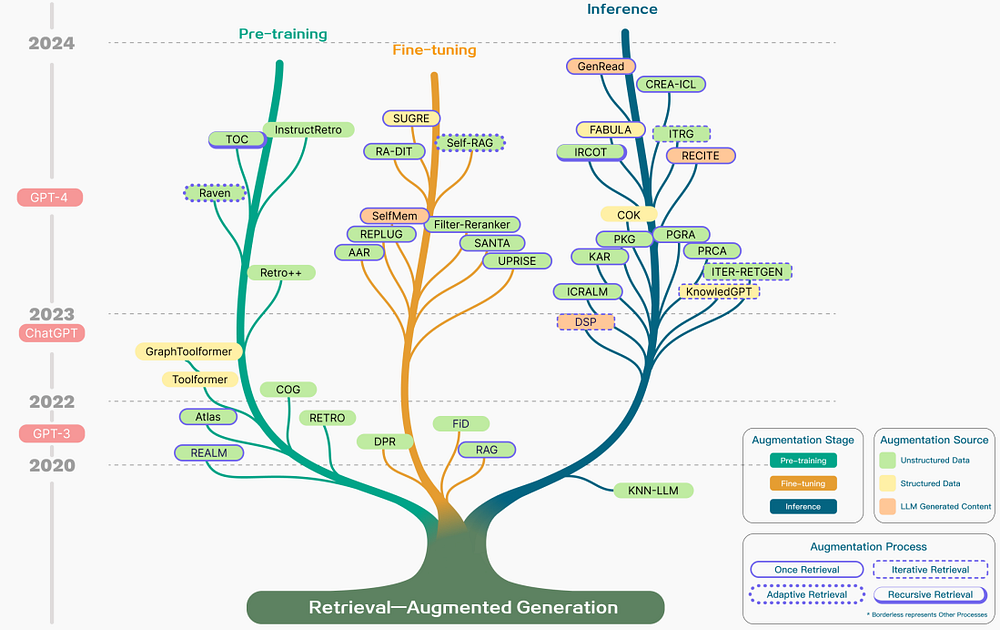
L’augmentation par récupération peut être appliquée à différentes étapes, notamment le pré-entraînement, le fine-tuning et l’inférence.
Étapes d’augmentation : Par exemple, RETRO illustre un système utilisant l’augmentation par récupération pour un pré-entraînement à grande échelle à partir de zéro en incorporant un encodeur supplémentaire basé sur des connaissances externes. Le fine-tuning peut également être intégré au RAG pour améliorer et affiner les systèmes RAG. Pendant l’étape d’inférence, de nombreuses techniques sont employées pour intégrer efficacement le contenu récupéré afin de répondre aux exigences spécifiques des tâches et d’affiner davantage le processus RAG.
Source d’augmentation : L’efficacité d’un modèle RAG dépend fortement de la sélection des sources de données d’augmentation. Ces sources peuvent être catégorisées en données non structurées, structurées et générées par LLM.
Processus d’augmentation : Pour résoudre des problèmes complexes tels que le raisonnement en plusieurs étapes, diverses méthodes ont été proposées :
- Récupération itérative : consiste à effectuer plusieurs cycles de récupération pour enrichir la profondeur et la pertinence des informations. Les approches notables utilisant cette méthode incluent RETRO et GAR-meets-RAG.
- Récupération récursive : construit de manière itérative sur la sortie d’une étape de récupération comme entrée d’une autre, permettant une exploration plus approfondie des informations pertinentes pour des requêtes complexes (par exemple, la recherche académique et l’analyse de cas juridiques). Les approches notables incluent IRCoT et Tree of Clarifications.
- Récupération adaptative : personnalise le processus de récupération en fonction des demandes spécifiques en identifiant les moments et le contenu optimaux pour la récupération. Les approches notables utilisant cette méthode incluent FLARE et Self-RAG.
La figure ci-dessous fournit une représentation complète de la recherche sur le RAG, illustrant divers aspects de l’augmentation, y compris les étapes, les sources et les processus.
Évaluation du RAG
Évaluer les performances des modèles RAG dans divers scénarios d’application est crucial pour comprendre et optimiser leur efficacité. Traditionnellement, l’évaluation des systèmes RAG s’est concentrée sur la mesure de leurs performances dans des tâches en aval à l’aide de métriques spécifiques aux tâches telles que F1 et EM. RaLLe se distingue comme un cadre notable utilisé pour évaluer les grands modèles de langage augmentés par récupération dans des tâches intensives en connaissances.
Les cibles d’évaluation dans le RAG englobent à la fois la récupération et la génération, visant à évaluer la qualité du contexte récupéré et du contenu généré. Les métriques couramment utilisées pour évaluer la qualité de la récupération sont issues de domaines comme les systèmes de recommandation et la récupération d’informations, notamment NDCG et le taux de succès. Parallèlement, l’évaluation de la qualité de la génération implique d’évaluer des aspects tels que la pertinence et la nocivité pour le contenu non étiqueté, ou la précision pour le contenu étiqueté. Les méthodes d’évaluation du RAG peuvent inclure à la fois des approches manuelles et automatiques.
L’évaluation d’un cadre RAG se concentre généralement sur trois scores de qualité principaux et quatre capacités. Les scores de qualité englobent la mesure de la pertinence du contexte (précision et spécificité du contexte récupéré), la fidélité des réponses (fidélité des réponses au contexte récupéré) et la pertinence des réponses (pertinence des réponses par rapport aux questions posées). De plus, quatre capacités aident à évaluer l’adaptabilité et l’efficacité d’un système RAG : la robustesse au bruit, le rejet négatif, l’intégration de l’information et la robustesse contrefactuelle. Voici un résumé des métriques utilisées pour évaluer différentes facettes d’un système RAG :
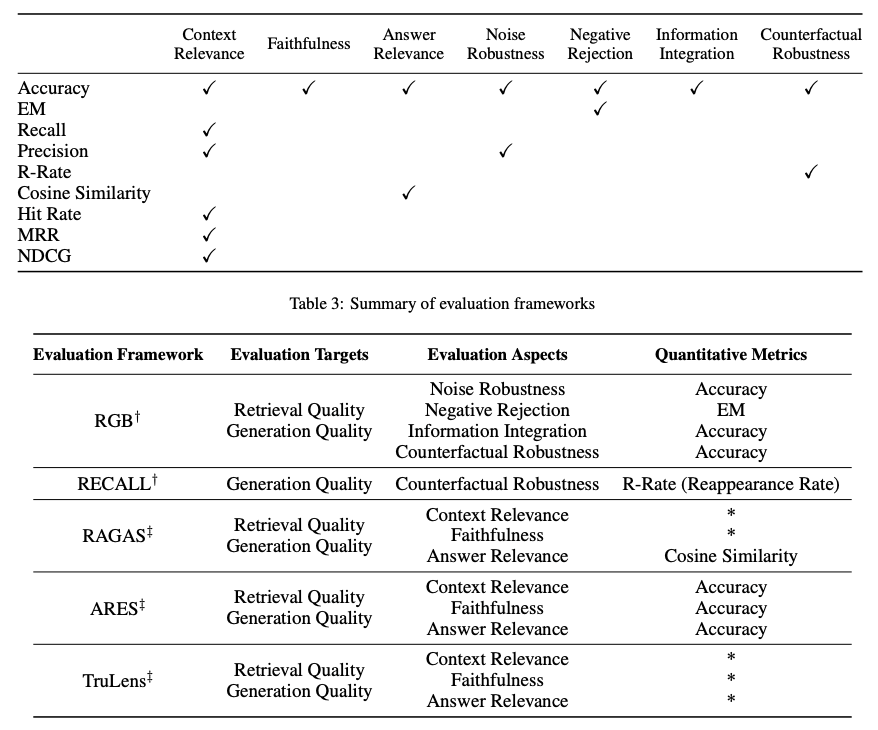
Divers benchmarks, tels que RGB et RECALL, sont employés pour évaluer les modèles RAG. Des outils comme RAGAS, ARES et TruLens ont été créés pour automatiser le processus d’évaluation des systèmes RAG. Certains de ces systèmes utilisent des LLM pour déterminer certains scores de qualité tels que définis ci-dessus.
Défis et avenir du RAG
Dans cet aperçu, nous avons exploré divers aspects de la recherche sur le RAG et différentes stratégies pour améliorer ses composants de récupération, d’augmentation et de génération. Voici plusieurs défis soulignés par Gao et al., 2023, alors que nous continuons à développer et à améliorer les systèmes RAG :
- Longueur du contexte : Avec l’expansion continue de la taille de la fenêtre de contexte des LLM, l’adaptation du RAG pour garantir la capture d’un contexte hautement pertinent et crucial pose des défis.
- Robustesse : La gestion des informations contrefactuelles et adverses est cruciale pour mesurer et améliorer la robustesse des systèmes RAG.
- Approches hybrides : Les recherches en cours visent à mieux comprendre comment optimiser l’utilisation combinée du RAG et des modèles affinés.
- Extension des rôles des LLM : Il y a un intérêt croissant pour l’augmentation du rôle et des capacités des LLM afin d’améliorer encore les systèmes RAG.
- Lois d’échelle : L’étude des lois d’échelle des LLM et leur application aux systèmes RAG reste un domaine nécessitant une meilleure compréhension.
- RAG prêt pour la production : Le développement de systèmes RAG de qualité production nécessite une excellence technique dans divers domaines, notamment les performances, l’efficacité, la sécurité des données et la confidentialité.
- RAG multimodal : Alors que la recherche sur le RAG s’est principalement concentrée sur les tâches textuelles, il y a un intérêt croissant pour l’extension des modalités afin de prendre en charge un plus large éventail de domaines tels que l’image, l’audio, la vidéo et le code.
- Évaluation : La construction d’applications complexes avec le RAG nécessite des métriques nuancées et des outils d’évaluation pour évaluer la pertinence contextuelle, la créativité, la diversité du contenu, la factualité et plus encore. De plus, il existe un besoin d’amélioration de la recherche en interprétabilité et d’outils pour le RAG.
Comment intégrer le RAG avec les grands modèles de langage
La mise en œuvre de la génération augmentée par récupération (RAG) avec les grands modèles de langage (LLM) implique plusieurs étapes, notamment la préparation des jeux de données et l’intégration dans la configuration du LLM. Ce processus permet au LLM d’exploiter les techniques de récupération et de générer des réponses plus précises et contextuellement pertinentes.
Voir comment intégrer votre LLM avec la technique RAG dans notre blog : Tutoriel étape par étape sur l’intégration de la génération augmentée par récupération (RAG) avec les grands modèles de langage

Source : novita.ai
Conclusion
En résumé, l’évolution des systèmes RAG a été rapide, marquée par l’émergence de paradigmes avancés qui offrent une personnalisation et améliorent les performances et l’utilité dans divers domaines. La demande croissante pour les applications RAG a stimulé le développement de méthodes pour améliorer ses différents composants. De la méthodologie hybride à l’auto-récupération, un large éventail de domaines de recherche est actuellement exploré dans les modèles RAG modernes.
novita.ai, la plateforme tout-en-un pour une créativité sans limites qui vous donne accès à plus de 100 API. De la génération d’images au traitement du langage, en passant par l’amélioration audio et la manipulation vidéo, à un coût abordable à l’utilisation, elle vous libère des tracas de la maintenance GPU tout en construisant vos propres produits. Essayez-la gratuitement.
Lecture recommandée
Moteur d’inférence LLM de Novita AI : le plus grand débit et l’inférence la moins chère disponible



