

検索拡張生成(RAG)システムの進化と進歩を探ります。RAGが外部知識で大規模言語モデル(LLM)をどのように強化するかを学びます。
はじめに
検索拡張生成(RAG)は、大規模言語モデル(LLM)に固有の課題(ドメイン知識の不足、事実性の問題、ハルシネーションなど)に対処する有望なソリューションとして登場しました。データベースなどの外部知識ソースを統合することで、RAGはLLMを強化し、特に最新の知識を必要とする知識豊富な環境やドメイン固有のアプリケーションで価値を発揮します。他の手法とは異なり、RAGは特定のタスクのためにLLMを再トレーニングする必要がなく、これが大きな利点です。最近、特に会話エージェントでの人気が高まっており、その重要性が際立っています。
Gaoら(2023)による最近の調査は、RAGの主要な発見、実用的な意味、最先端のアプローチに関する貴重な洞察を提供しています。この調査では、検索、生成、拡張技術を含むRAGシステムのさまざまなコンポーネントを掘り下げ、評価方法論、アプリケーション、関連技術を検討しています。
RAGとは
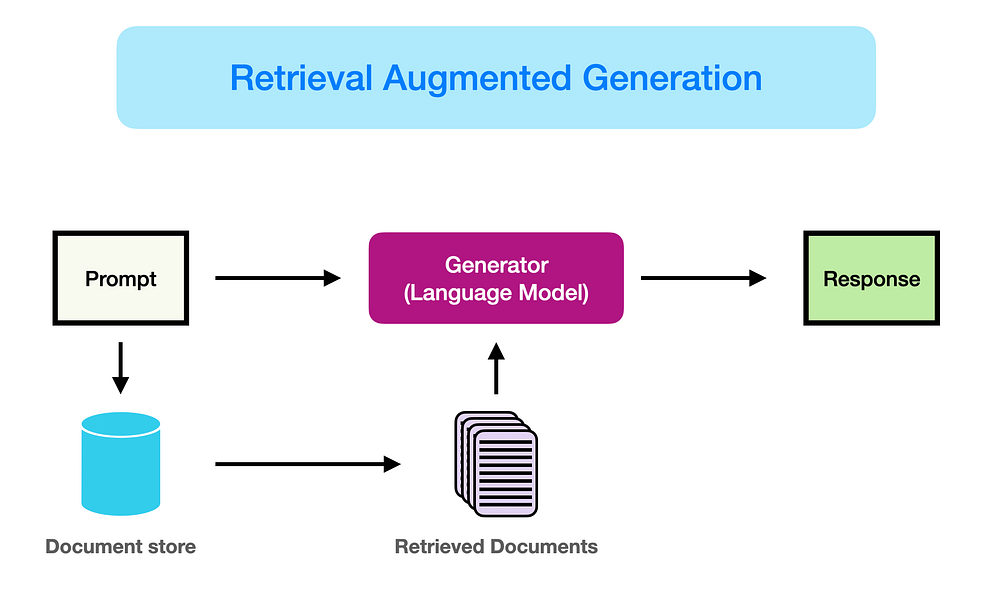
検索拡張生成(RAG)は、信頼できる外部知識ベースからの参照を組み込むことで、大規模言語モデルの性能を向上させます。大規模言語モデル(LLM)は、膨大なデータセットと数十億のパラメータを活用して、質問応答、言語翻訳、テキスト補完などのタスクに対して応答を生成します。RAGは、モデルの再トレーニングを必要とせずに、特定のドメインや内部組織の知識ベースにLLMを適応させることで、その能力を拡張します。このアプローチは、LLMの出力を多様なコンテキストで関連性、正確性、有用性を確保するためのコスト効率の高い手段を提供します。
RAGの主要コンポーネント
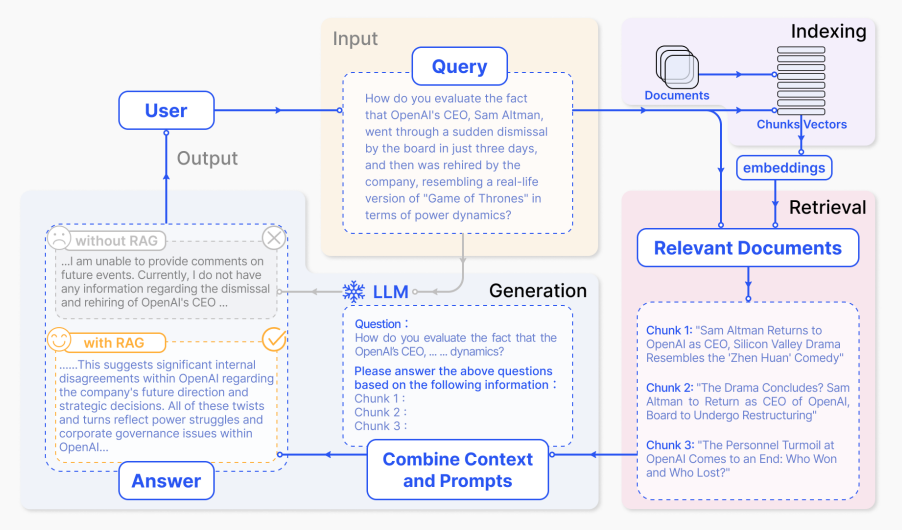
プロセスは以下のステップ/コンポーネントに分解できます。
- 入力: LLMシステムに提示される質問を指します。RAGがない場合、LLMはこの質問に直接応答します。
- インデックス作成: RAGを使用する場合、関連するドキュメントのセットがインデックス作成されます。これには、ドキュメントのチャンク化、チャンクの埋め込み作成、ベクトルストアへのインデックス作成が含まれます。推論時には、クエリも同様に埋め込まれます。
- 検索: クエリをインデックス化されたベクトルと比較することで関連ドキュメントが取得され、「関連ドキュメント」の選択結果が得られます。
- 生成: 取得されたドキュメントは元のプロンプトとマージされ、追加のコンテキストを提供します。この結合されたテキストとプロンプトがモデルに入力され、応答生成が行われ、ユーザーに提供される最終出力が生成されます。
特定の例では、モデルだけに依存する場合、最新の知識が不足しているために適切に応答できないことがあります。一方、RAGを利用することで、システムは質問に正確に答えるために必要な情報にアクセスできるようになります。
RAGのパラダイム
近年、RAGシステムはNaive RAGからAdvanced RAG、Modular RAGへと進化してきました。この進歩は、性能、コスト、効率に関連する特定の課題を克服することを目的としています。
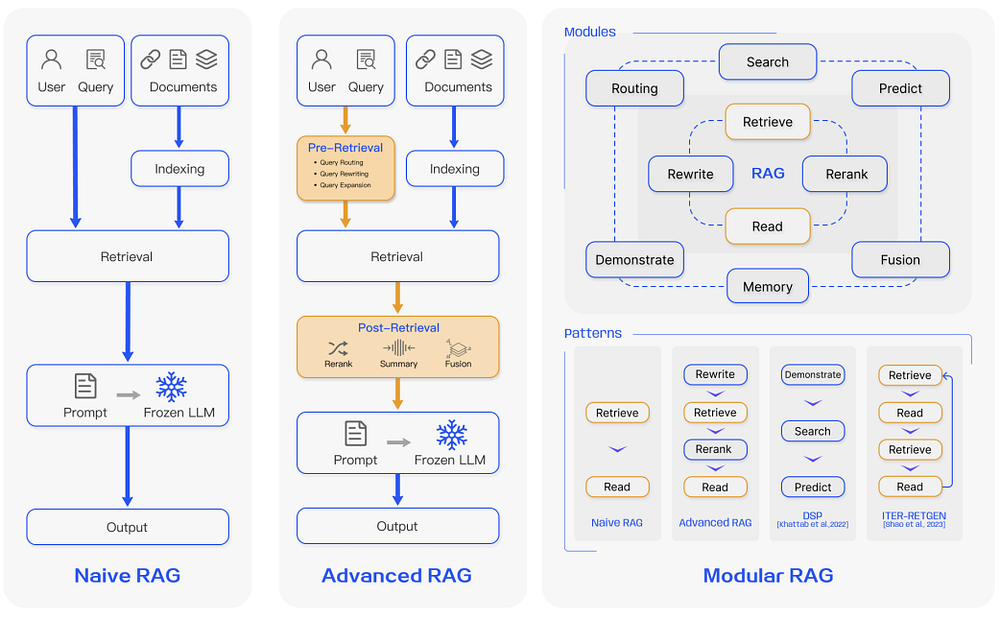
Naive RAG
Naive RAGは、前述のインデックス作成、検索、生成の従来のプロセスを通じて動作します。基本的には、ユーザー入力を使用して関連ドキュメントをクエリし、それらをプロンプトと結合してモデルに提供し、最終応答を生成します。アプリケーションがマルチターンの対話インタラクションを含む場合、会話履歴をプロンプトに統合できます。
しかし、Naive RAGには限界があります。低精度(取得されたチャンクのミスアライメント)や低再現率(関連するすべてのチャンクの取得失敗)の問題が含まれます。また、LLMに古い情報が供給されるリスクもあり、これはRAGシステムが最初に対処しようとした主要な懸念事項です。これにより、ハルシネーションの問題や、質の低く不正確な応答の生成につながる可能性があります。
さらに、拡張が実装されると、冗長性や繰り返しに関する懸念が生じる可能性があります。複数の取得されたパッセージを処理するには、スタイルやトーンのランキングと調整の考慮が必要です。さらに重要な課題は、生成タスクが拡張情報に過度に依存し、モデルが取得したコンテンツを単に繰り返すだけになるのを防ぐことです。
Advanced RAG
Advanced RAGは、Naive RAGで観察された欠点に対する解決策を提供し、特に検索の品質を向上させます。この改善には、検索前、検索中、検索後のプロセス全体の最適化が含まれます。
検索前フェーズでは、データのインデックス作成を5つの主要な段階で改善します。データの粒度の向上、インデックス構造の最適化、メタデータの追加、アラインメントの最適化、混合検索です。これらの対策は、インデックス化されたデータの品質を高めることを目的としています。
検索段階でのさらなる強化は、埋め込みモデル自体の最適化によって達成できます。この最適化は、コンテキストチャンクの品質に直接影響を与えます。戦略には、検索の関連性を向上させるための埋め込みのファインチューニングや、コンテキストのニュアンスをより適切に捉える動的埋め込み(例:OpenAIのembeddings-ada-02モデル)の使用が含まれます。
検索後の最適化は、コンテキストウィンドウの制限を回避し、ノイズや気を散らす情報を管理することに焦点を当てます。再ランキングはこれらの課題に対処する一般的なアプローチであり、関連コンテキストをプロンプトの端に移動したり、クエリと関連テキストチャンク間の意味的類似性を再計算するなどの手法が含まれます。プロンプト圧縮技術もこれらの問題の管理に役立つ可能性があります。
Modular RAG
Modular RAGは、その名前が示すように、検索拡張生成フレームワーク内の機能モジュールを強化します。類似性検索用の検索モジュールの統合や、検索器へのファインチューニングの適用などが含まれます。Naive RAGとAdvanced RAGはどちらも、固定モジュールで構成されたModular RAGの特定のインスタンスと見なすことができます。ただし、拡張RAGでは、検索、メモリ、融合、ルーティング、予測、タスクアダプターなどの追加モジュールが導入され、それぞれ異なる課題に対処します。これらのモジュールは、特定のタスクコンテキストに適応するように再構成でき、Modular RAGに多様性と柔軟性を提供します。この柔軟性により、タスク要件に基づいてモジュールを追加、置換、調整できます。
RAGシステムの構築における柔軟性の向上に伴い、RAGパイプラインを洗練するためのさまざまな最適化技術が提案されています。
- ハイブリッド検索の探索: キーワードベースの検索と意味検索などの検索技術を組み合わせ、関連性が高くコンテキスト豊富な情報を取得します。特に多様なクエリタイプや情報ニーズに対処するのに有益です。
- 再帰的検索とクエリエンジン: 小さな意味チャンクから始め、徐々に大きなチャンクを取得してコンテキストを豊かにする再帰的検索プロセスです。効率とコンテキストの豊かさのバランスを取ります。
- StepBackプロンプト: このプロンプト技術により、LLMは概念や原則を抽象化し、より根拠のある応答へと推論を導くことができます。RAGフレームワーク内でこの技術を採用することで、LLMは特定のインスタンスを超えて、必要に応じてより広く推論できるようになります。
- サブクエリ: ツリークエリやチャンクの逐次クエリなど、さまざまなクエリ戦略をシナリオに応じて使用できます。たとえば、LlamaIndexはサブ質問クエリエンジンを提供し、クエリを複数の質問に分解し、それぞれ異なる関連データソースを利用します。
- 仮説ドキュメント埋め込み(HyDE): HyDEはクエリに対する仮想的な回答を生成し、それを埋め込んで、クエリの代わりにその仮想的な回答に類似したドキュメントを取得するために利用します。
RAGのフレームワーク
このセクションでは、RAGシステムを構成するコンポーネント(検索、生成、拡張)における重要な進歩をまとめます。
検索
RAGシステム内の検索では、検索器から関連性の高いコンテキストを取得します。これはさまざまな方法で強化できます。
意味表現の強化:
チャンキング戦略の改善は、コンテンツとアプリケーション要件に基づいて最適なチャンキング戦略を選択するために重要です。異なるモデルは異なるブロックサイズで優れた性能を発揮する場合があります(例:単文にはsentence-transformers、256または512トークンを含むブロックにはtext-embedding-ada-002)。RAGシステムでの検索を最適化するために、ユーザーの質問の長さ、アプリケーション、トークン制限などの要素を考慮して、さまざまなチャンキング戦略を試すことが一般的です。
特殊なドメインでは、ユーザークエリを正確に理解するために埋め込みモデルのファインチューニングが必要になる場合があります。BAAIが開発したBGE-large-ENなどの埋め込みモデルは、ドメイン知識や特定のダウンストリームタスクにファインチューニングして、検索の関連性を最適化できます。
クエリとドキュメントのアラインメント:
Query2Doc、ITER-RETGEN、HyDEなどのクエリ書き換え手法は、意味情報が不足している、または不正確な表現を含むクエリを洗練することに焦点を当てています。
埋め込み変換は、タスクにより密接に関連する潜在空間にクエリ埋め込みを整列させるために最適化します。
検索器とLLMのアラインメント:
検索器のファインチューニングは、LLMからのフィードバック信号を利用して検索モデルを洗練します。例としては、拡張適応型検索器(AAR)、REPLUG、UPRISEなどがあります。
PRCA、RECOMP、PKGなどの外部アダプターを組み込むことで、検索器とLLM間のアラインメントプロセスを支援します。
生成
RAGシステム内の生成器は、取得された情報を一貫したテキストに変換し、モデルの最終出力を形成する上で極めて重要な役割を果たします。このプロセスには多くの場合、多様な入力データが含まれ、クエリとドキュメントから得られた入力への言語モデルの適応を洗練するための努力が必要です。これらの洗練は、検索後のプロセスとファインチューニングを通じて達成できます。
凍結LLMを用いた検索後処理: このアプローチは、LLM自体を変更せずに検索結果の品質を向上させることに焦点を当てています。情報圧縮や結果の再ランキングなどの操作が利用されます。情報圧縮はノイズの低減、コンテキスト長の制限への対処、生成効果の向上に役立ち、再ランキングは最も関連性の高いアイテムを優先するためにドキュメントを再順序付けます。
RAGのためのLLMのファインチューニング: 生成器をさらに最適化またはファインチューニングすることで、生成されたテキストが自然であり、取得されたドキュメントを効果的に活用できるようにし、RAGシステム全体のパフォーマンスを向上させます。
拡張
拡張には、取得されたパッセージからのコンテキストを進行中の生成タスクにシームレスに統合するプロセスが含まれます。拡張プロセス(その段階とデータを含む)をさらに詳しく調べる前に、RAGのコアコンポーネントの分類を確立しましょう。
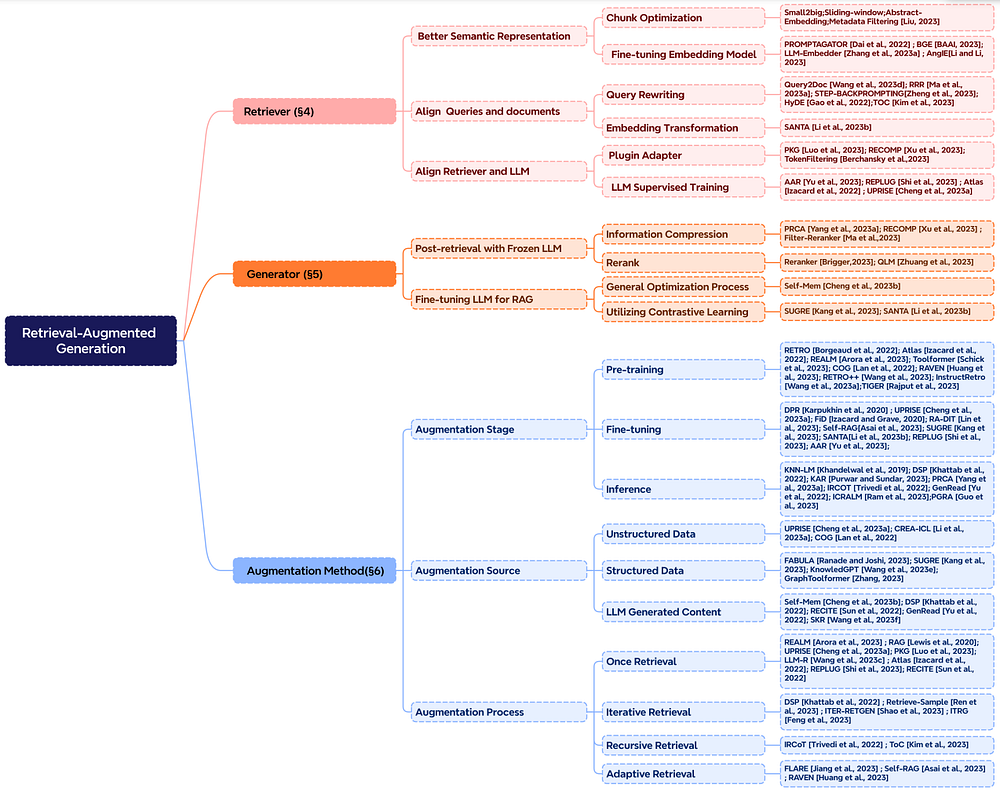
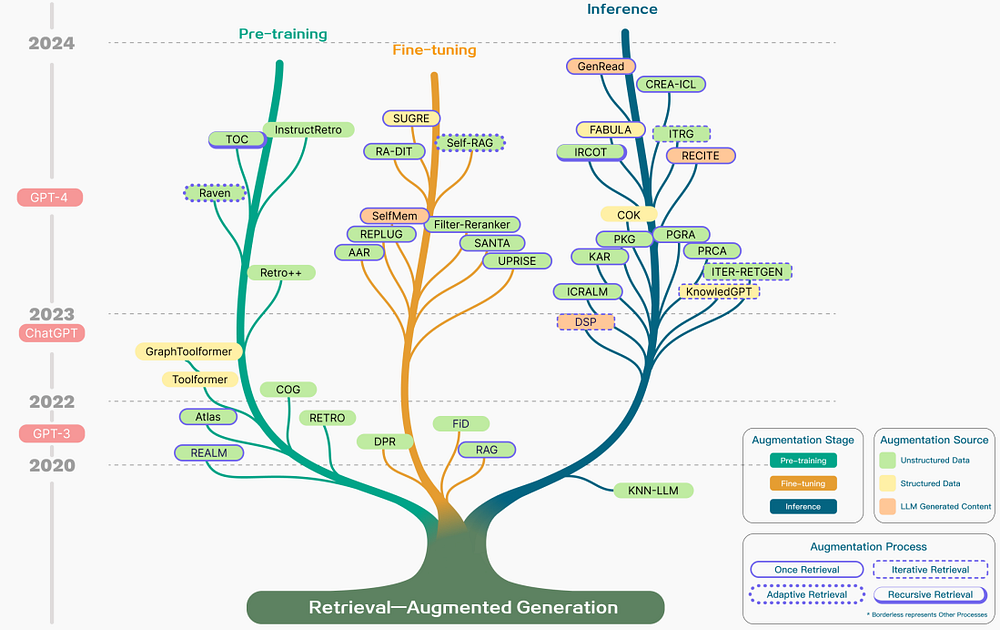
検索拡張は、事前トレーニング、ファインチューニング、推論など、さまざまな段階で適用できます。
拡張段階: たとえば、RETROは、外部知識に基づく追加のエンコーダを組み込むことで、スクラッチからの大規模事前トレーニングに検索拡張を採用するシステムの例です。ファインチューニングはRAGと統合して、RAGシステムを強化および洗練することもできます。推論段階では、特定のタスク要件を満たし、RAGプロセスをさらに洗練するために、取得されたコンテンツを効果的に統合するための多数の手法が使用されます。
拡張ソース: RAGモデルの有効性は、拡張データソースの選択に大きく依存します。これらのソースは、非構造化データ、構造化データ、LLM生成データに分類できます。
拡張プロセス: マルチステップ推論などの複雑な問題に対処するために、さまざまな方法が提案されています。
- 反復検索: 複数の検索サイクルを実行して、情報の深さと関連性を豊かにします。この方法を活用する注目すべきアプローチには、RETROやGAR-meets-RAGがあります。
- 再帰的検索: ある検索ステップの出力を次のステップの入力として繰り返し構築し、複雑なクエリ(例:学術研究や法的ケース分析)の関連情報をより深く探索できるようにします。注目すべきアプローチには、IRCoTやTree of Clarificationsがあります。
- 適応的検索: 最適な検索タイミングとコンテンツを特定することで、特定の要求に検索プロセスをカスタマイズします。この方法を活用する注目すべきアプローチには、FLAREやSelf-RAGがあります。
以下の図は、RAG研究の包括的な表現を示しており、段階、ソース、プロセスなどのさまざまな拡張の側面を示しています。
RAGの評価
さまざまなアプリケーションシナリオにおけるRAGモデルのパフォーマンスを評価することは、その有効性を理解し最適化するために重要です。従来、RAGシステムの評価は、F1やEMなどのタスク固有のメトリクスを使用したダウンストリームタスクでのパフォーマンス測定に焦点が当てられてきました。RaLLeは、知識集約型タスクにおける検索拡張大規模言語モデルの評価に利用される注目すべきフレームワークです。
RAGの評価対象には、検索と生成の両方が含まれ、取得されたコンテキストと生成されたコンテンツの両方の品質を評価することを目的としています。検索品質の評価に一般的に使用されるメトリクスは、レコメンデーションシステムや情報検索などのドメインから借用されており、NDCGやHit Rateが含まれます。一方、生成品質の評価には、ラベルなしコンテンツの関連性や有害性、ラベル付きコンテンツの正確性などの側面の評価が含まれます。RAG評価方法には、手動評価と自動評価の両方が含まれます。
RAGフレームワークの評価は、通常、3つの主要な品質スコアと4つの能力に焦点を当てます。品質スコアには、コンテキスト関連性(取得されたコンテキストの精度と特異性)、回答の忠実性(取得されたコンテキストに対する回答の忠実性)、回答の関連性(提示された質問に対する回答の関連性)の測定が含まれます。さらに、4つの能力は、RAGシステムの適応性と効率性を評価するのに役立ちます。ノイズ堅牢性、ネガティブ拒否、情報統合、反事実堅牢性です。以下は、RAGシステムのさまざまな側面を評価するために使用されるメトリクスの要約です。
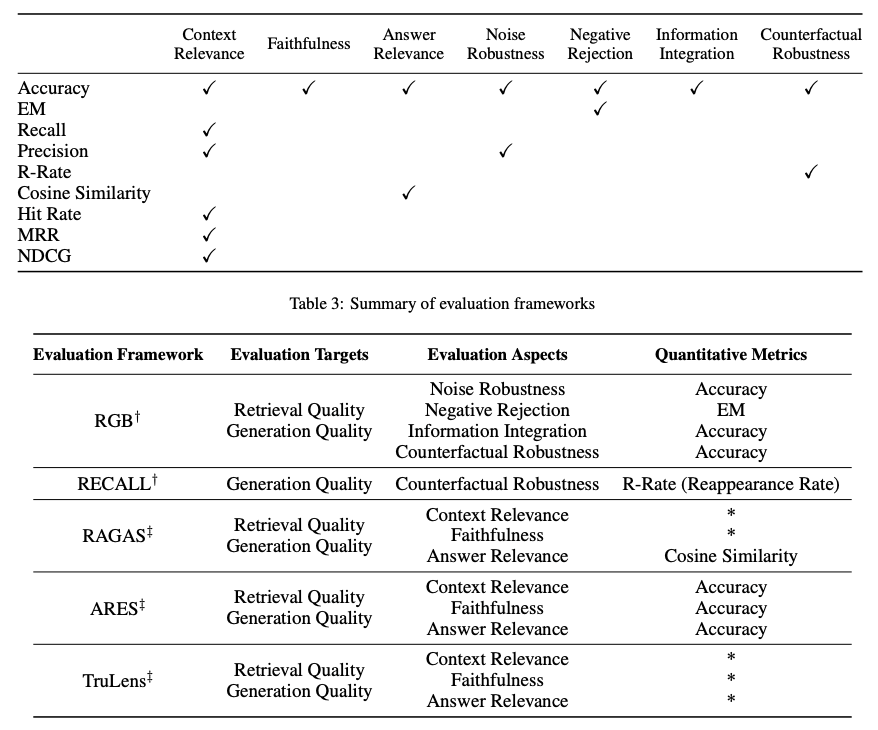
RGBやRECALLなどのさまざまなベンチマークがRAGモデルの評価に使用されます。RAGAS、ARES、TruLensなどのツールは、RAGシステムの評価プロセスを自動化するために作成されました。これらのシステムの中には、上記で定義された特定の品質スコアを決定するためにLLMを利用するものもあります。
RAGの課題と未来
この概要では、RAGのさまざまな研究側面と、その検索、拡張、生成コンポーネントを強化するためのさまざまな戦略を探ってきました。Gaoら(2023)が強調したいくつかの課題を以下に示します。RAGシステムを開発および改善し続けるにあたり、これらに取り組む必要があります。
- コンテキスト長: LLMがコンテキストウィンドウサイズを拡大し続ける中で、RAGを適応させて高度に関連性が高く重要なコンテキストを確実にキャプチャするのは課題です。
- 堅牢性: 反事実情報や敵対的情報への対処は、RAGシステムの堅牢性を測定および向上させるために重要です。
- ハイブリッドアプローチ: RAGとファインチューニングされたモデルの両方の使用を最適化する方法をよりよく理解するための研究が進行中です。
- LLMの役割の拡大: RAGシステムをさらに強化するために、LLMの役割と機能を拡大することへの関心が高まっています。
- スケーリング則: LLMのスケーリング則とそのRAGシステムへの適用を調査することは、依然としてさらなる理解が必要な領域です。
- プロダクション対応RAG: 本番品質のRAGシステムを開発するには、パフォーマンス、効率、データセキュリティ、プライバシーなど、さまざまな領域でのエンジニアリングの卓越性が必要です。
- マルチモーダルRAG: RAG研究は主にテキストベースのタスクに焦点を当ててきましたが、画像、音声、ビデオ、コードなど、より幅広いドメインをサポートするためにモダリティを拡張することへの関心が高まっています。
- 評価: RAGを使用した複雑なアプリケーションを構築するには、コンテキストの関連性、創造性、コンテンツの多様性、事実性などを評価するためのニュアンスのあるメトリクスと評価ツールが必要です。さらに、RAGのための改善された解釈可能性の研究とツールが必要です。
RAGを大規模言語モデルと統合する方法
大規模言語モデル(LLM)で検索拡張生成(RAG)を実装するには、データセットの準備とLLM環境への統合を含むいくつかのステップがあります。このプロセスにより、LLMは検索技術を活用し、より正確でコンテキストに関連した回答を生成できるようになります。
RAGテクニックをLLMと統合する方法については、当社のブログをご覧ください: ステップバイステップチュートリアル:検索拡張生成(RAG)を大規模言語モデルと統合する

出典:novita.ai
結論
要約すると、RAGシステムの進化は急速であり、カスタマイズを提供し、さまざまなドメインでのパフォーマンスと有用性を向上させる高度なパラダイムの出現によって特徴づけられます。RAGアプリケーションへの需要の高まりにより、そのさまざまなコンポーネントを改善するための方法の開発が促進されています。ハイブリッド手法から自己検索まで、現代のRAGモデルでは幅広い研究領域が現在探求されています。
novita.ai は、100以上のAPIにアクセスできる無限の創造性のためのワンストッププラットフォームです。画像生成や言語処理からオーディオ拡張やビデオ操作まで、従量課金制で手頃な価格を実現。GPUメンテナンスの手間から解放され、自社製品を構築できます。無料でお試しください。
おすすめの記事



