

- Dans quelles conditions les développeurs doivent-ils passer à Kimi-K2-Thinking ?
- Qu'est-ce que Kimi K2 Thinking a révolutionné dans les modèles open source ?
- Quel modèle performe le mieux, Kimi-K2-Thinking ou Sonnet 4 ?
- Comment utiliser Kimi-K2-Thinking dans Trae ?
- Conseils pour utiliser Kimi-K2-Thinking dans Trae
- Pourquoi les développeurs choisissent Novita AI avec Trae
Les développeurs modernes ont souvent du mal à transformer des modèles de raisonnement avancés en systèmes pratiques riches en outils. Même des modèles puissants comme Claude ou GPT nécessitent des configurations complexes pour intégrer efficacement le codage, le débogage et les flux de travail de données. C’est là que Trae devient le véritable catalyseur de Kimi-K2-Thinking.
En combinant l’environnement de développement tout-en-un de Trae avec le raisonnement à long horizon de Kimi-K2-Thinking, les développeurs disposent d’un moyen fluide de créer des flux de travail IA autonomes et multi-outils. Trae fournit l’intégration de modèles, l’orchestration d’outils et le débogage en temps réel au sein d’une interface unifiée, tandis que Kimi-K2-Thinking offre un raisonnement stable sur plus de 200 étapes, avec un contexte de 256 000 tokens et une mise à l’échelle des coûts efficace.
Cet article explique dans quelles conditions les développeurs doivent passer à Kimi-K2-Thinking, comment Trae et Novita AI rendent le déploiement sans effort ensemble, et pourquoi cette stack transforme le raisonnement complexe en un avantage de développement pratique et abordable.
Dans quelles conditions les développeurs doivent-ils passer à Kimi-K2-Thinking ?
Lorsque votre flux de travail nécessite un raisonnement à long terme, une coordination multi-outils et une supervision minimale, Kimi-K2-Thinking devient votre moteur idéal.
Analyse automatisée de données
Outils : Python / SQL / Plotly
Utilisez-le lorsque : Vous avez besoin d’un raisonnement en plusieurs étapes : données → nettoyage → modélisation → visualisation → rapport.
Pourquoi Kimi-K2 : Il garde la trace sur des centaines d’appels d’outils avec une logique stable.
Recherche et revue de littérature
Outils : Recherche web / Analyseurs de citations / Résumeurs
Utilisez-le lorsque : Vous devez lire, comparer et synthétiser de grands volumes de texte.
Pourquoi Kimi-K2 : Il maintient une compréhension de contexte long et une synthèse structurée.
Support client intelligent
Outils : APIs de récupération / Systèmes CRM / Modèles de sentiment
Utilisez-le lorsque : Les conversations s’étendent sur plusieurs tours et sources de données.
Pourquoi Kimi-K2 : Il maintient la mémoire et orchestre les réponses des outils de manière transparente.
Codage assisté par IA
Outils : Interpréteur de code / Débogueur / Compilateur
Utilisez-le lorsque : Vous avez besoin d’une planification, de tests et de correction d’erreurs automatisés.
Pourquoi Kimi-K2 : Il parcourt des boucles de développement complètes de manière autonome.
Automatisation du marketing
Outils : Tableaux de bord d’analyse / APIs de tests A-B / Outils de mots-clés
Utilisez-le lorsque : Les campagnes nécessitent une optimisation basée sur les données au fil du temps.
Pourquoi Kimi-K2 : Il effectue des évaluations répétées et affine les stratégies créatives.
Agents de connaissances d’entreprise
Outils : Bases de données / Moteurs de recherche / Connecteurs Slack
Utilisez-le lorsque : Les équipes ont besoin d’insights unifiés et continuellement mis à jour.
Pourquoi Kimi-K2 : Il coordonne l’utilisation des outils avec une mémoire de raisonnement à long terme.
Testez Kimi K2 Thinking gratuitement dès maintenant !
Qu’est-ce que Kimi K2 Thinking a révolutionné dans les modèles open source ?
L’architecture de Kimi-K2 équilibre échelle, efficacité et stabilité, lui permettant d’effectuer un raisonnement riche en outils sur de longues séquences sans perte de cohérence.
Une nouvelle norme pour le raisonnement à long horizon
Kimi-K2-Thinking introduit une architecture avancée d’agent de raisonnement qui entrelace le raisonnement structuré avec l’utilisation adaptative d’outils. Il peut effectuer 200 à 300 appels d’outils consécutifs sans perdre sa direction ou sa cohérence.
La plupart des modèles ouverts échouaient auparavant après environ 30 à 50 étapes, mais Kimi-K2 maintient sa précision sur des tâches longues nécessitant un raisonnement étape par étape.
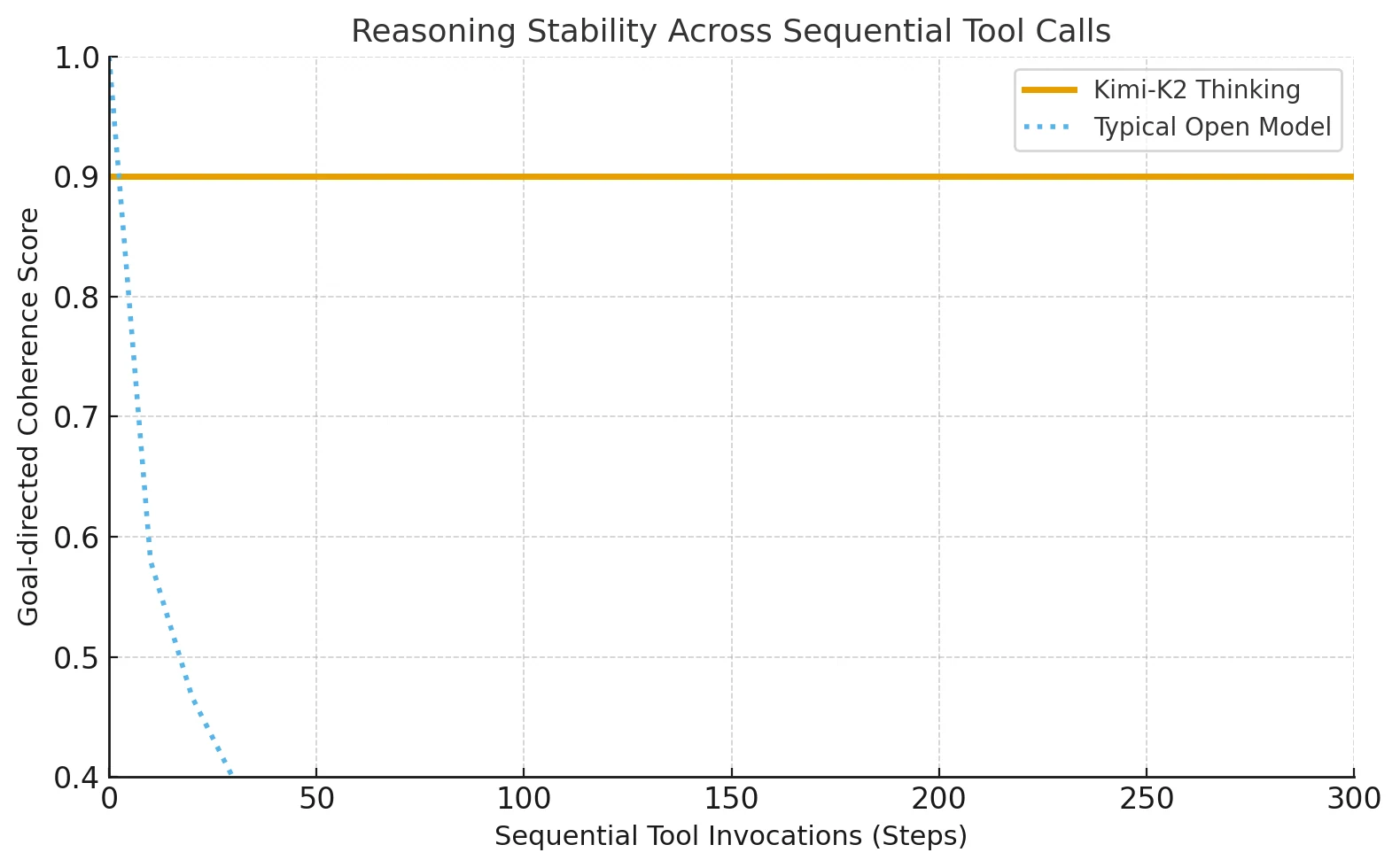
Des systèmes fermés aux agents de raisonnement ouverts
Avant Kimi-K2, seul le Claude d’Anthropic pouvait maintenir un tel raisonnement entrelacé d’outils. Kimi-K2 étend cette méthode aux écosystèmes open source, permettant aux développeurs indépendants d’accéder à des chaînes cognitives longues et stables, autrefois exclusives aux plateformes d’IA fermées.
Architecture système de base
| Composant | Rôle fonctionnel |
|---|---|
| Mélange d’experts (MoE) | Augmente la capacité dynamique tout en maintenant le coût de calcul constant. |
| 1 000 milliards de paramètres / 32 milliards activés | Équilibre l’échelle avec un routage efficace par token. |
| 61 couches totales + 1 backbone dense | Préserve la profondeur tout en garantissant la stabilité du signal. |
| 384 experts, 8 actifs par token | Améliore l’adaptabilité à des contextes de raisonnement variés. |
| Fenêtre de 256 000 tokens | Permet la continuité dans les tâches ultra-longues. |
| Attention latente multi-têtes (MLA) | Améliore la focalisation inter-étapes et réduit la charge mémoire. |
| Activation SwiGLU | Lisse le flux de gradients et stabilise le raisonnement profond. |
Quel modèle performe le mieux, Kimi-K2-Thinking ou Sonnet 4 ?
Comparaison des performances
Kimi-K2-Thinking performe à un niveau proche de GPT-5 et Claude sur les principaux benchmarks de raisonnement et de mathématiques. Il est légèrement en retard sur les tâches MMLU-Pro, Redux, de rédaction longue et de génération de code, mais surpasse les autres modèles lorsque des outils externes sont disponibles ou que les chaînes de raisonnement sont étendues.
Dans des paramètres d’exécution de longue durée (HLE) avec outils, Kimi-K2 atteint 44,9, contre 32,0 pour Claude, démontrant sa force dans le raisonnement soutenu multi-outils.
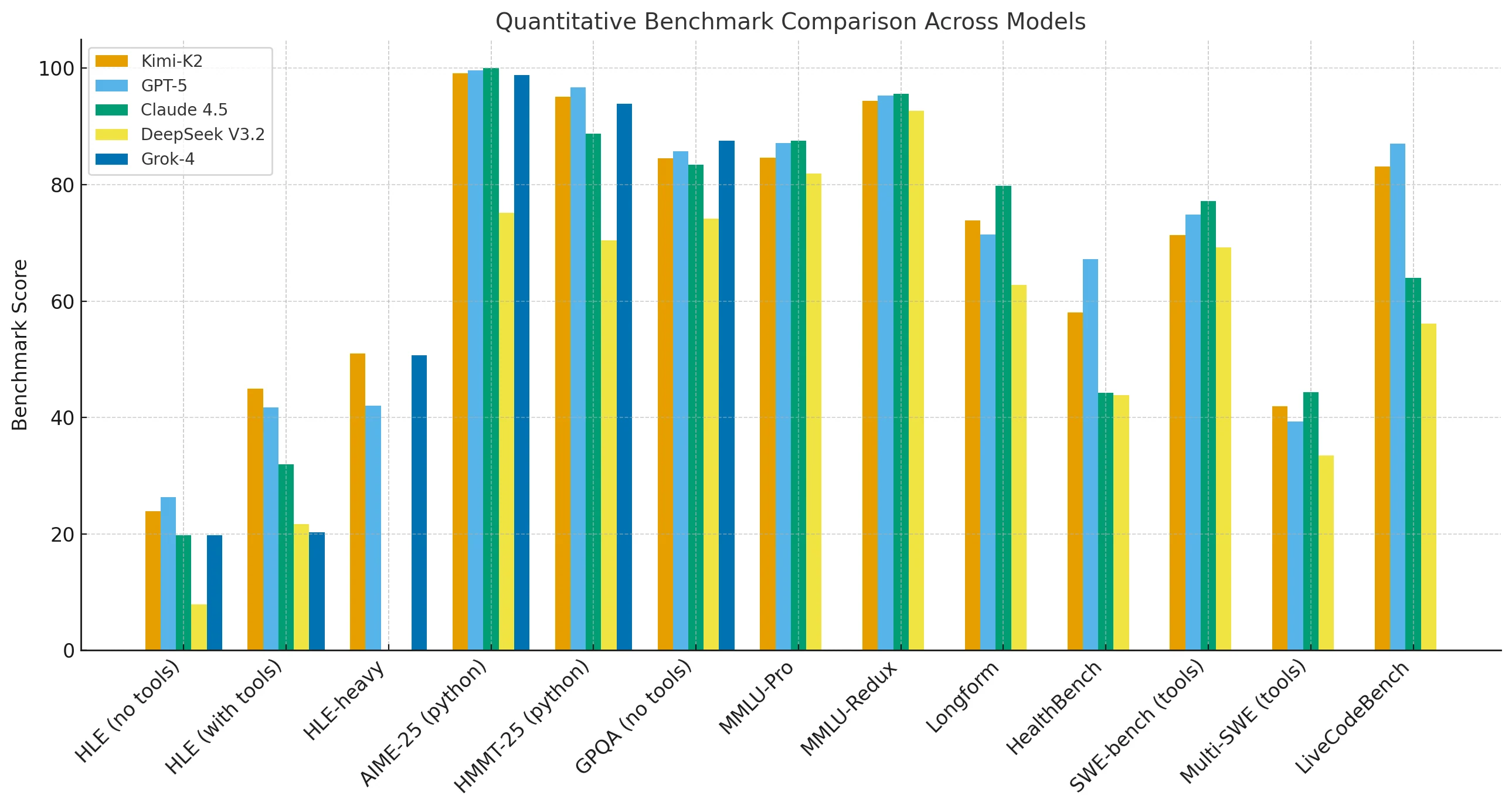
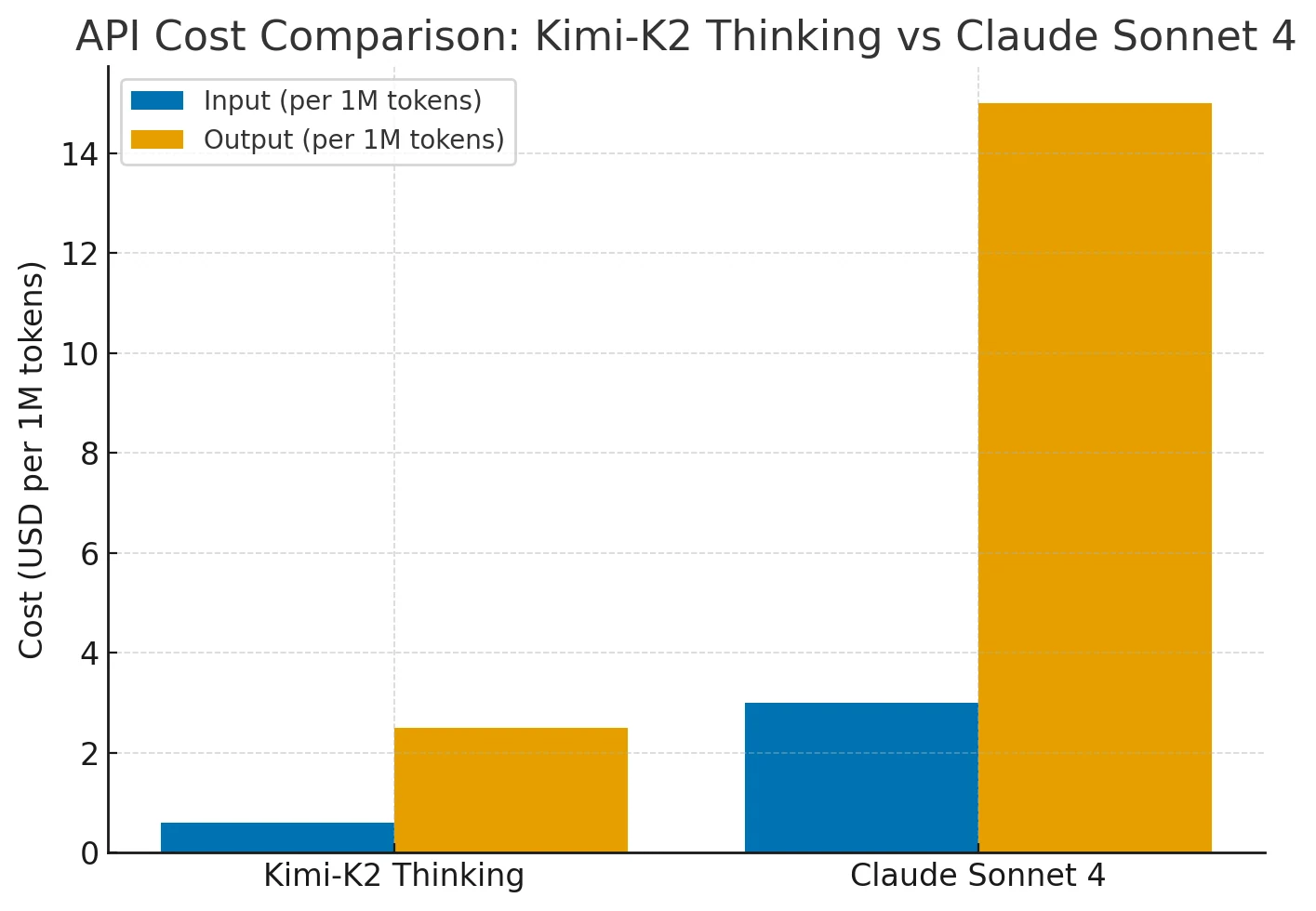
Efficacité des coûts
Kimi-K2 offre des performances comparables à Claude Sonnet 4 à un coût 75 à 80 % inférieur. Sa tarification reste plate pour les contextes longs (jusqu’à 256 000 tokens) et les utilisations fréquentes d’outils, tandis que le coût de Claude augmente fortement avec la longueur du contexte et les actions de l’agent.
Kimi-K2 offre donc des capacités de niveau Claude/GPT avec une efficacité coût/performance supérieure pour les tâches de raisonnement étendues.
Testez Kimi K2 Thinking dès maintenant !
Comment utiliser Kimi-K2-Thinking dans Trae ?
Novita AI propose actuellement l’API Kimi-K2-Thinking à contexte complet la plus abordable.
Novita AI propose des APIs avec un contexte de 262 000 tokens, des coûts de 0,6 $ par entrée et 2,5 $ par sortie, prenant en charge les sorties structurées et l’appel de fonctions, ce qui offre un soutien solide pour maximiser le potentiel d’agent de code de Kimi K2 Thinking.
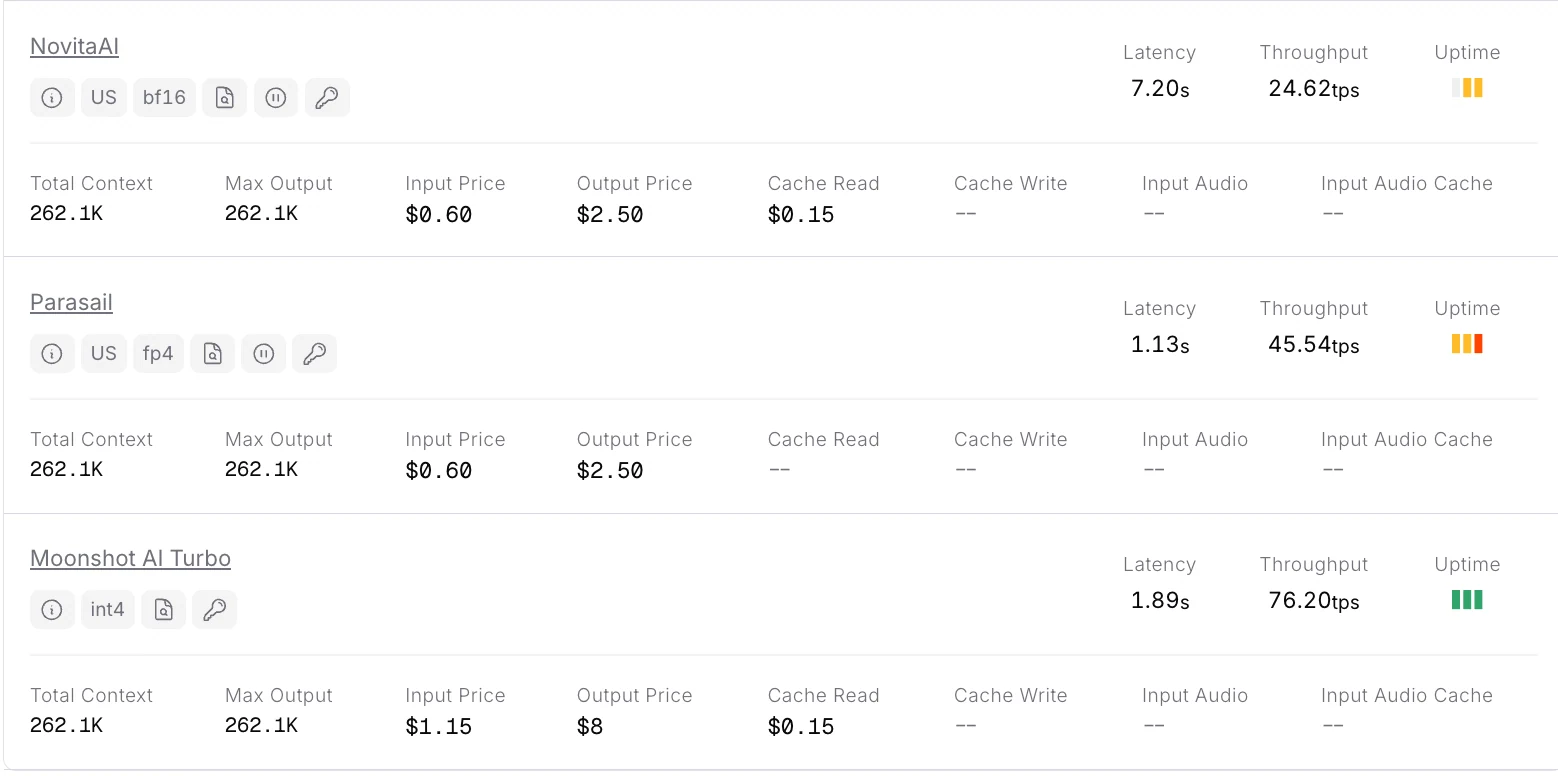
Étape 1 : Obtenir votre clé API
Étape 1 : Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Testez Kimi K2 Thinking dès maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
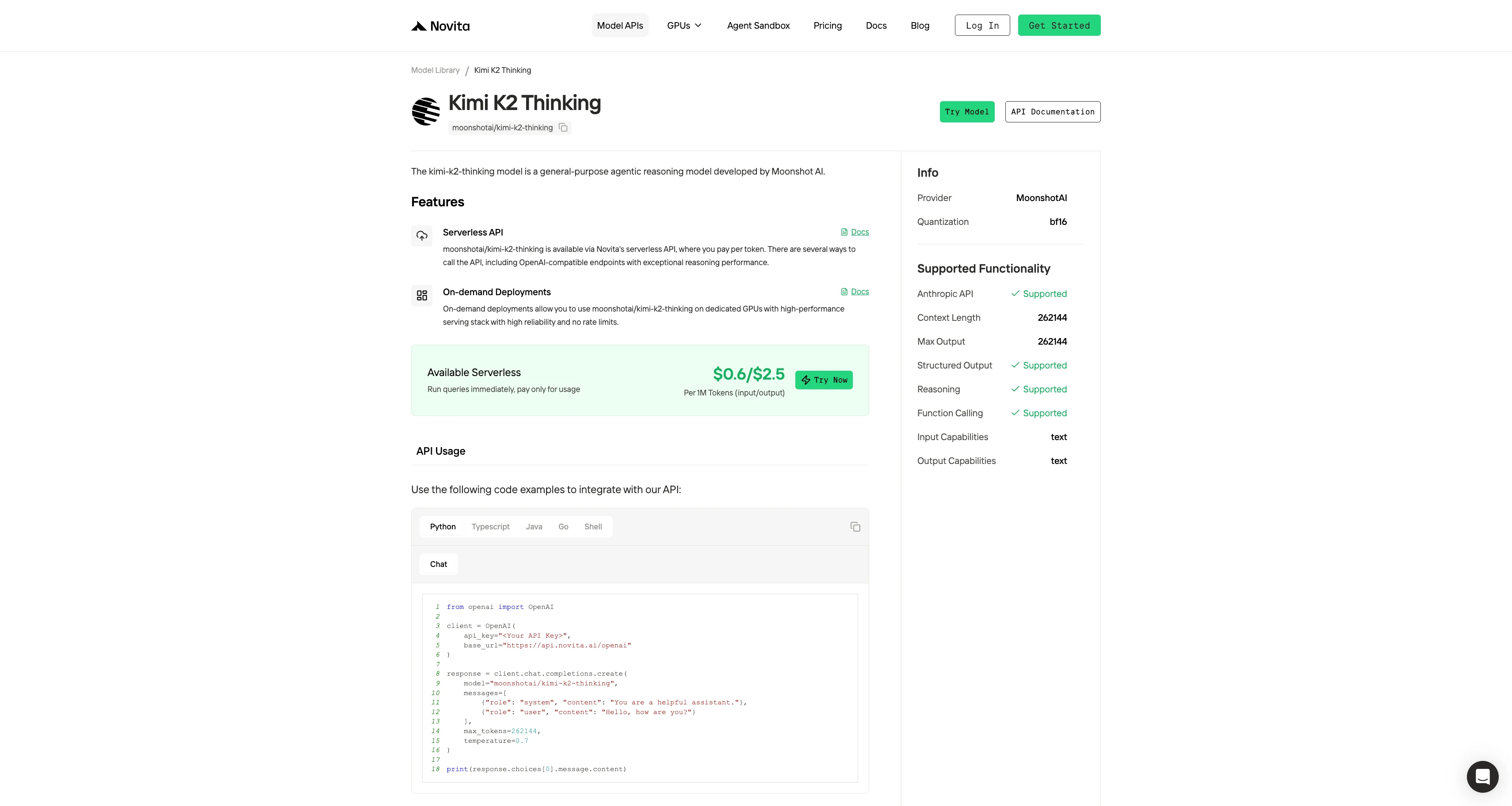
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installer l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM de Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2-thinking",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=262144,
temperature=0.7
)
print(response.choices[0].message.content)
Kimi K2 Thinking avec Trae
Étape 1 : Ouvrir Trae et accéder aux modèles
Lancez l’application Trae. Cliquez sur le bouton Basculer la barre latérale IA dans le coin supérieur droit pour ouvrir la barre latérale IA. Accédez ensuite à Gestion IA et sélectionnez Modèles.

Étape 2 : Ajouter un modèle personnalisé et choisir Novita comme fournisseur
Cliquez sur le bouton Ajouter un modèle pour créer une entrée de modèle personnalisé. Dans la boîte de dialogue d’ajout de modèle, sélectionnez Fournisseur = Novita dans le menu déroulant.


Étape 3 : Sélectionner ou saisir le modèle
Dans le menu déroulant Modèle, choisissez le modèle souhaité (DeepSeek-R1-0528, Kimi K2 thinking, DeepSeek-V3-0324 ou MiniMax-M1-80k). Si le modèle exact n’est pas listé, saisissez simplement l’ID du modèle que vous avez noté depuis la bibliothèque Novita. Assurez-vous de choisir la variante correcte du modèle que vous souhaitez utiliser.
Étape 5 : Saisissez votre clé API
Copiez la clé API Novita AI depuis votre console Novita et collez-la dans le champ Clé API de Trae.
Obtenez votre clé API dès maintenant !
Étape 6 : Enregistrer la configuration
Cliquez sur Ajouter un modèle pour enregistrer. Trae validera la clé API et la sélection du modèle en arrière-plan !
Conseils pour utiliser Kimi-K2-Thinking dans Trae
Voici des conseils pratiques pour utiliser Kimi‑K2‑Thinking dans Trae à destination des développeurs :
1. Définissez clairement l’objectif
Commencez votre prompt par un objectif général clair. Par exemple :
« Votre objectif est d’analyser ce jeu de données et de produire un rapport résumant les insights, puis de générer du code pour visualiser les métriques clés. » Cela joue sur le point fort de K2 : le raisonnement sur de longues chaînes et l’orchestration d’outils.
2. Incluez le rôle système + les contraintes
Utilisez un prompt système comme celui-ci :
« Vous êtes un assistant IA construit avec Kimi-K2-Thinking. Assurez-vous de reformuler toutes les contraintes avant de procéder. » Reformuler les contraintes permet de réduire les erreurs dans le raisonnement en plusieurs étapes. (Skywork)
3. Activez l’environnement d’appel d’outils dans Trae
Lorsque vous utilisez Trae, configurez l’appel de modèle pour inclure les outils disponibles (par exemple, recherche, requête de base de données, exécution de code). K2 peut décider quand et comment appeler les outils.
4. Définissez des paramètres adaptés
- Utilisez une température ≈ 1,0 pour des performances de raisonnement équilibrées.
- Si les tâches sont fortement orientées logique/analyse, gardez la température basse (0,1 à 0,3) pour réduire l’aléatoire.
- Faites attention à la longueur du contexte : bien que K2 prenne en charge jusqu’à 256 000 tokens, des entrées extrêmement longues peuvent ralentir la réponse.
5. Divisez les tâches pour un meilleur contrôle
Au lieu de « résoudre ceci en une étape », utilisez des prompts comme :
« 1) Décrire 3 approches possibles. 2) Évaluer chaque approche. 3) En choisir une et l’exécuter. » Cela aide K2 à maintenir une structure et améliore la qualité des réponses.
6. Validez les sorties et le raisonnement
Demandez au modèle de sortir sa chaîne de raisonnement ou ses hypothèses. Par exemple :
« Listez les hypothèses que vous avez faites et les contraintes que vous avez vérifiées avant de procéder. » Cela est utile pour l’audit dans les projets complexes.
7. Associez le modèle aux types de tâches
Utilisez K2 pour :
- Raisonnement en plusieurs étapes, planification, flux de travail de recherche
- Tâches nécessitant une orchestration d’outils et de longues chaînes
Pour des tâches plus simples ou critiques en termes de latence, un modèle plus léger peut être plus efficace.
8. Surveillez les coûts et la latence
Le raisonnement et l’utilisation d’outils de K2 génèrent plus de tokens et prennent plus de temps que les modèles de base. Prévoyez votre budget en conséquence lors du déploiement via Trae.
Si vous le souhaitez, je peux rédiger un modèle de configuration Trae (YAML/JSON) pour intégrer K2-Thinking avec ces bonnes pratiques.
Pourquoi les développeurs choisissent Novita AI avec Trae
| Dimension clé | Valeur clé | Explication claire |
|---|---|---|
| 💰 Maîtrise des coûts | Gérez l’utilisation de l’API et la facturation de manière indépendante | Vous contrôlez votre clé API et votre budget : pas de markup caché ni de frais intermédiaires. |
| 🚀 Accès aux nouveaux modèles en premier | Accès instantané aux derniers modèles d’IA | DeepSeek, LLaMA et Mistral sont immédiatement disponibles une fois hébergés sur Novita. |
| 📈 Plans évolutifs | Passez facilement du prototype à la production | La tarification à l’usage s’adapte en douceur à la taille de votre projet. |
| 🧩 Environnement de développement tout-en-un | Kit de développement et d’IA intégré | Codez, analysez et collaborez directement dans Trae : pas d’outils externes nécessaires. |
| 🔄 Flux de travail transparent | Interface unifiée et automatisation | Écrivez, déboguez et appelez des fonctions IA dans un environnement cohérent unique. |
Kimi-K2-Thinking redéfinit l’intelligence open source en combinant la stabilité du raisonnement profond avec une orchestration d’outils efficace. Il maintient des centaines d’appels d’outils séquentiels, conserve sa cohérence sur des contextes longs et offre des performances de niveau Claude à une fraction du coût.
Pour tout développeur travaillant sur des flux de travail agentiques, des recherches automatisées ou du codage analytique longue forme, Kimi-K2-Thinking offre une base évolutive, transparente et abordable pour le développement d’IA de nouvelle génération.
Foire aux questions
Quand les développeurs doivent-ils passer à Kimi-K2-Thinking ?
Passez à lui lorsque votre projet implique un raisonnement en plusieurs étapes, une utilisation fréquente d’outils ou des fenêtres de contexte larges : des scénarios où Kimi-K2-Thinking maintient la précision et la logique tandis que les autres modèles dérivent ou surfacturent.
En quoi Kimi-K2-Thinking diffère-t-il de Claude Sonnet 4 ?
Kimi-K2-Thinking maintient 200 à 300 appels d’outils avec un raisonnement stable et coûte environ 75 à 80 % moins cher, tandis que la tarification de Claude Sonnet 4 augmente fortement avec des contextes plus longs et des actions d’agent fréquentes.
Kimi-K2-Thinking peut-il gérer des tâches de développement full-stack ?
Oui. Kimi-K2-Thinking automatise le traitement des données, la génération de code, le débogage et l’amélioration itérative au sein de Trae ou de la configuration d’appel d’outils de Novita AI.
Novita AI est la plateforme cloud tout-en-un qui donne vie à vos ambitions en IA. APIs intégrées, serverless, instances GPU : les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et concrétisez votre vision de l’IA.
Lectures recommandées
Comment accéder à Qwen 3 Coder : Qwen Code ; Claude Code ; Trae
Comment utiliser GLM-4.6 dans Cursor pour augmenter la productivité des petites équipes



