

- ¿Bajo qué condiciones deberían los desarrolladores cambiarse a Kimi-K2-Thinking?
- ¿Qué revolucionó Kimi K2 Thinking en los modelos de código abierto?
- ¿Qué modelo rinde mejor, Kimi-K2-Thinking o Sonnet 4?
- ¿Cómo usar Kimi-K2-Thinking en Trae?
- Consejos para usar Kimi-K2-Thinking en Trae
- Por qué los desarrolladores eligen Novita AI con Trae
Los desarrolladores modernos a menudo tienen dificultades para convertir modelos de razonamiento avanzados en sistemas prácticos y ricos en herramientas. Incluso modelos potentes como Claude o GPT requieren configuraciones complejas para integrar de manera eficiente la programación, la depuración y los flujos de trabajo de datos. Aquí es donde Trae se convierte en el verdadero habilitador de Kimi-K2-Thinking.
Al combinar el entorno de desarrollo integral de Trae con el razonamiento de largo alcance de Kimi-K2-Thinking, los desarrolladores obtienen una forma fluida de construir flujos de trabajo de IA autónomos y multitool. Trae proporciona integración de modelos, orquestación de herramientas y depuración en tiempo real dentro de una única interfaz unificada, mientras que Kimi-K2-Thinking ofrece un razonamiento estable de más de 200 pasos con un contexto de 256 mil tokens y una escalabilidad de costos eficiente.
Este artículo explica bajo qué condiciones los desarrolladores deberían cambiarse a Kimi-K2-Thinking, cómo Trae y Novita AI juntos hacen que la implementación sea sencilla, y por qué esta combinación convierte el razonamiento complejo en una ventaja de desarrollo práctica y asequible.
¿Bajo qué condiciones deberían los desarrolladores cambiarse a Kimi-K2-Thinking?
Cuando tu flujo de trabajo requiere razonamiento a largo plazo, coordinación de múltiples herramientas y supervisión mínima, Kimi-K2-Thinking se convierte en tu motor ideal.
Análisis de datos automatizado
Herramientas: Python / SQL / Plotly
Úsalo cuando: Necesites razonamiento de varios pasos: datos → limpiar → modelar → visualizar → informar.
Por qué Kimi-K2: Mantiene el seguimiento a través de cientos de llamadas a herramientas con lógica estable.
Investigación y revisión bibliográfica
Herramientas: Búsqueda web / Analizadores de citas / Resumidores
Úsalo cuando: Debas leer, comparar y sintetizar grandes volúmenes de texto.
Por qué Kimi-K2: Sostiene la comprensión de contexto largo y la síntesis estructurada.
Atención al cliente inteligente
Herramientas: APIs de recuperación / Sistemas CRM / Modelos de sentimiento
Úsalo cuando: Las conversaciones abarcan múltiples turnos y fuentes de datos.
Por qué Kimi-K2: Mantiene la memoria y orquesta las respuestas de las herramientas sin problemas.
Codificación asistida por IA
Herramientas: Intérprete de código / Depurador / Compilador
Úsalo cuando: Necesites planificación, pruebas y corrección de errores automatizadas.
Por qué Kimi-K2: Itera a través de ciclos de desarrollo completos de forma autónoma.
Automatización de marketing
Herramientas: Paneles de análisis / APIs de pruebas A-B / Herramientas de palabras clave
Úsalo cuando: Las campañas requieran optimización basada en datos a lo largo del tiempo.
Por qué Kimi-K2: Ejecuta evaluaciones repetidas y refina estrategias creativas.
Agentes de conocimiento empresarial
Herramientas: Bases de datos / Motores de búsqueda / Conectores de Slack
Úsalo cuando: Los equipos necesiten información unificada y actualizada continuamente.
Por qué Kimi-K2: Coordina el uso de herramientas con memoria de razonamiento a largo plazo.
¡Prueba Kimi K2 Thinking gratis ahora!
¿Qué revolucionó Kimi K2 Thinking en los modelos de código abierto?
La arquitectura de Kimi-K2 equilibra escala, eficiencia y estabilidad, permitiéndole realizar razonamiento rico en herramientas sobre secuencias largas sin pérdida de coherencia.
Un nuevo estándar para el razonamiento de horizonte largo
Kimi-K2-Thinking introduce una arquitectura de agente pensante avanzada que entrelaza el razonamiento estructurado con el uso adaptativo de herramientas. Puede completar entre 200 y 300 llamadas consecutivas a herramientas sin perder la dirección ni la coherencia.
La mayoría de los modelos abiertos anteriores se rompían después de unos 30 a 50 pasos, pero Kimi-K2 mantiene la precisión a través de tareas largas que requieren un razonamiento paso a paso.
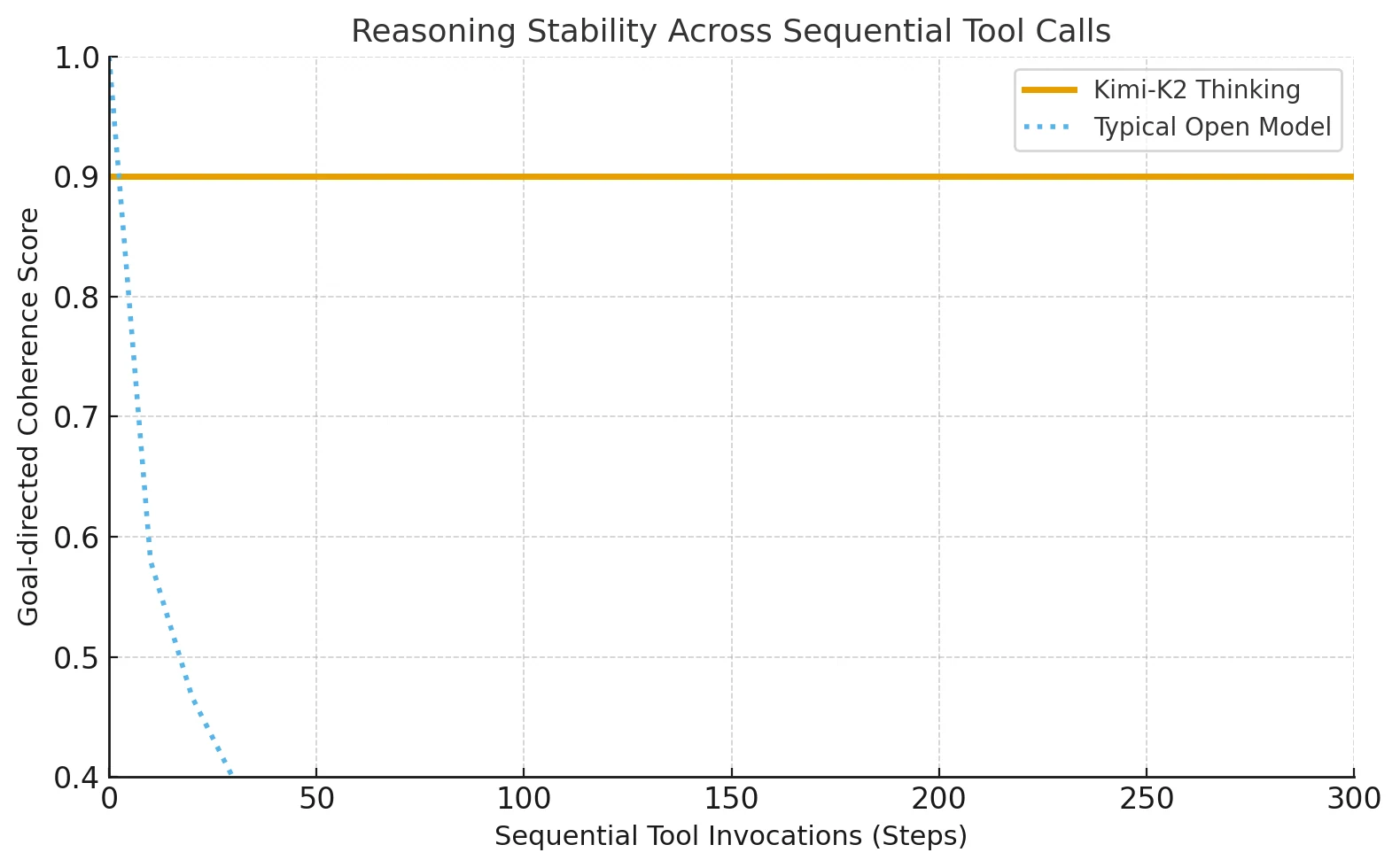
De sistemas cerrados a agentes pensantes abiertos
Antes de Kimi-K2, solo Claude de Anthropic podía mantener un razonamiento de herramientas intercalado de este tipo. Kimi-K2 extiende este método a los ecosistemas de código abierto, permitiendo a los desarrolladores independientes acceder a cadenas cognitivas estables y de formato largo que antes eran exclusivas de las plataformas de IA cerradas.
Arquitectura central del sistema
| Componente | Función |
|---|---|
| Mezcla de expertos (MoE) | Aumenta la capacidad dinámica mientras mantiene constante el costo computacional. |
| 1T parámetros / 32B activados | Equilibra la escala con un enrutamiento eficiente por token. |
| 61 capas totales + 1 backbone denso | Preserva la profundidad mientras asegura la estabilidad de la señal. |
| 384 expertos, 8 activos por token | Mejora la adaptabilidad a diversos contextos de razonamiento. |
| Ventana de 256K tokens | Permite la continuidad en tareas ultralargas. |
| Atención latente multibloque (MLA) | Mejora el enfoque entre pasos y reduce la tensión de la memoria. |
| Activación SwiGLU | Suaviza el flujo del gradiente y estabiliza el razonamiento profundo. |
¿Qué modelo rinde mejor, Kimi-K2-Thinking o Sonnet 4?
Comparación de rendimiento
Kimi-K2-Thinking se acerca a GPT-5 y Claude en los principales benchmarks de razonamiento y matemáticas. Está ligeramente por detrás en MMLU-Pro, Redux, redacción de textos largos y tareas de generación de código, pero supera a otros cuando hay herramientas externas disponibles o cuando se extienden las cadenas de razonamiento.
En entornos de ejecución de alta longitud (HLE) con herramientas, Kimi-K2 alcanza 44,9, en comparación con los 32,0 de Claude, demostrando su fortaleza en el razonamiento sostenido con múltiples herramientas.
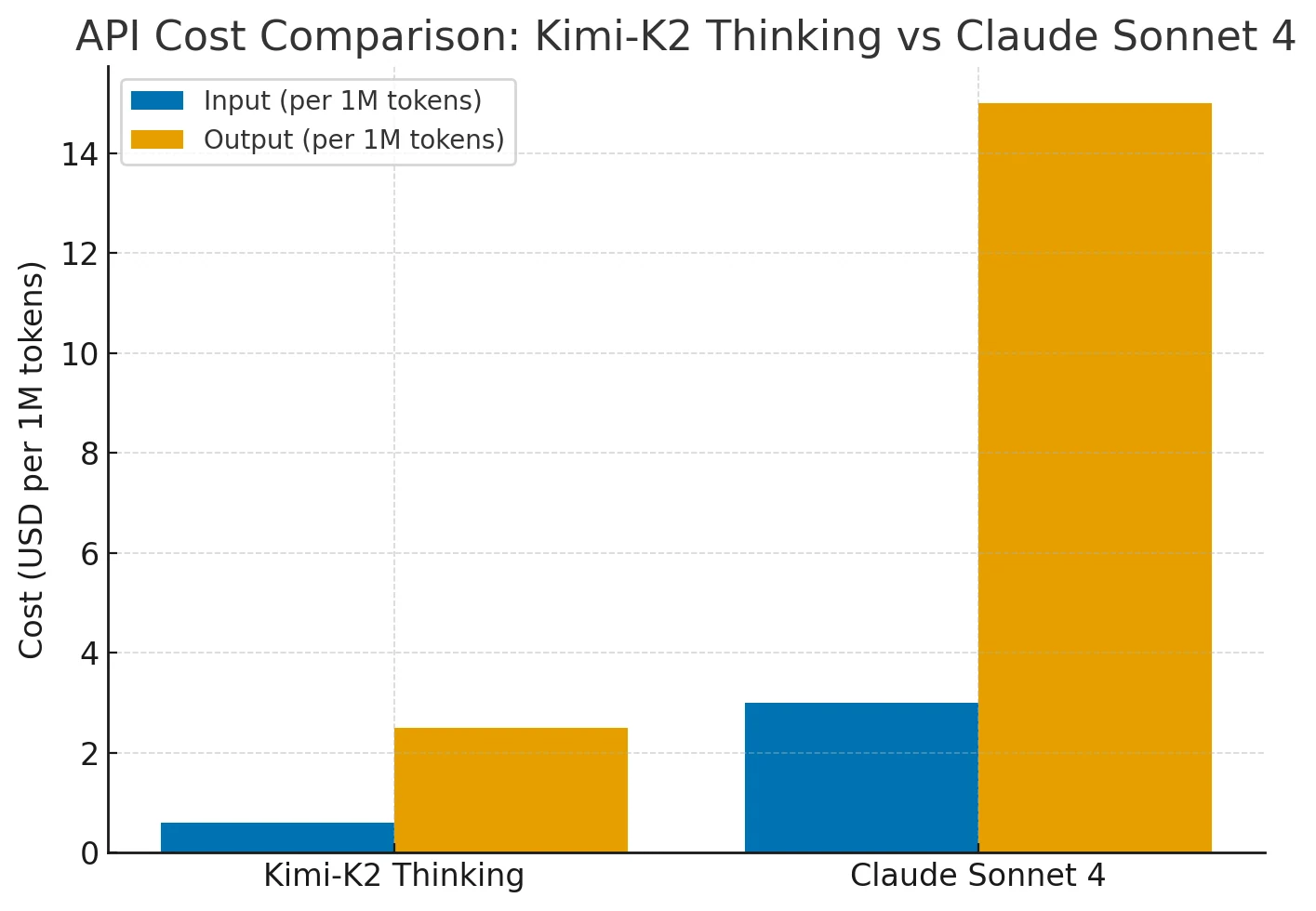
Eficiencia de costos
Kimi-K2 ofrece un rendimiento comparable al de Claude Sonnet 4 con un costo entre un 75 y un 80 % menor. Su precio se mantiene constante en contextos largos (hasta 256 mil tokens) y con uso frecuente de herramientas, mientras que el costo de Claude aumenta drásticamente con la longitud del contexto y las acciones del agente.
Por lo tanto, Kimi-K2 ofrece capacidades de nivel Claude/GPT con una eficiencia costo-rendimiento superior para tareas de razonamiento extendido.
¡Prueba Kimi K2 Thinking ahora!
¿Cómo usar Kimi-K2-Thinking en Trae?
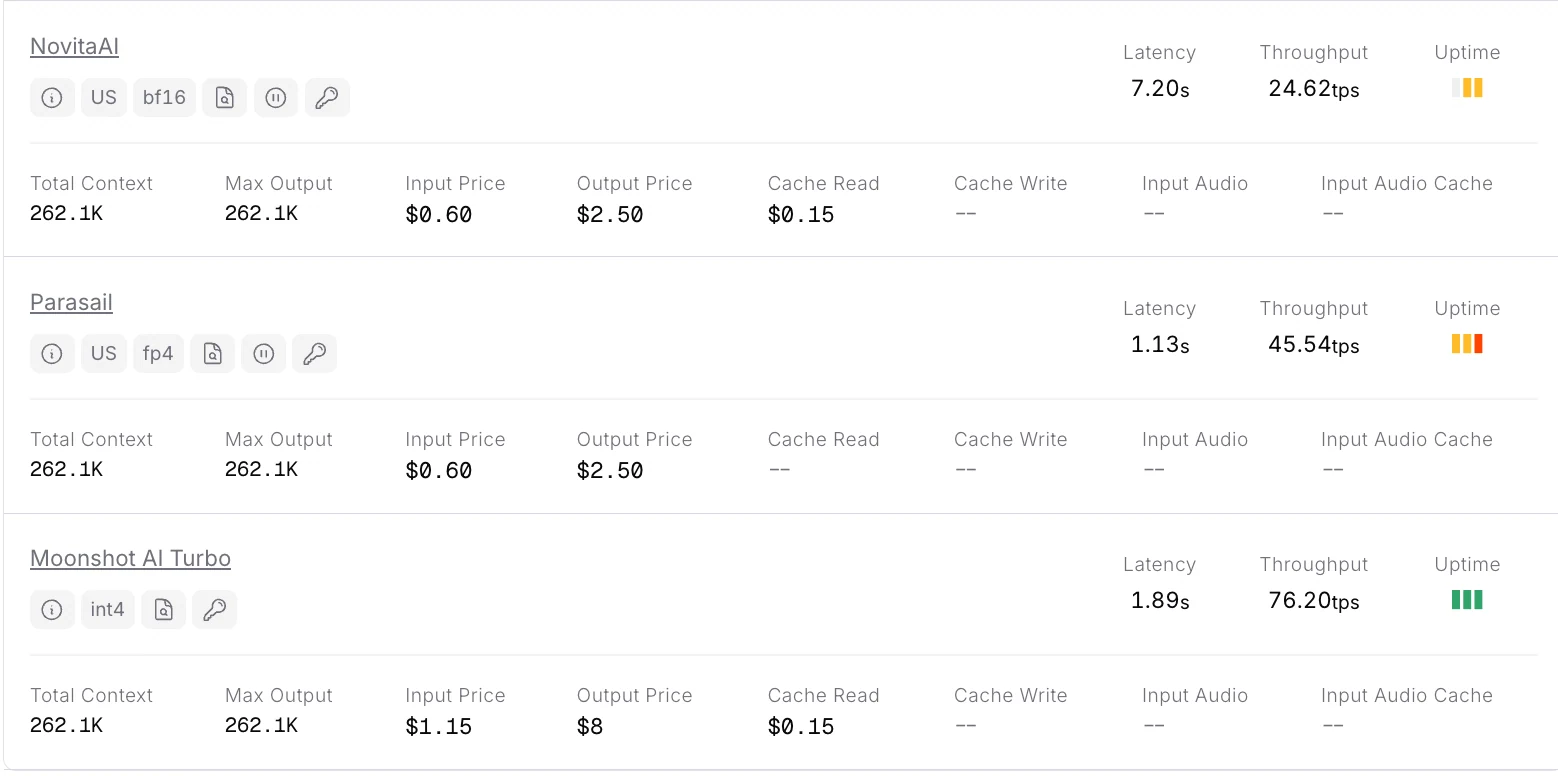
Novita AI actualmente ofrece la API Kimi-K2-Thinking con contexto completo más asequible.
Novita AI proporciona APIs con 262K de contexto y costos de $0.6/entrada y $2.5/salida, que admiten salida estructurada y llamadas a funciones, lo que brinda un gran soporte para maximizar el potencial del agente de código de Kimi K2 Thinking.
Lo primero: Obtén la clave API
Paso 1: Inicia sesión en tu cuenta y haz clic en el botón Model Library.

¡Prueba Kimi K2 Thinking ahora!
Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
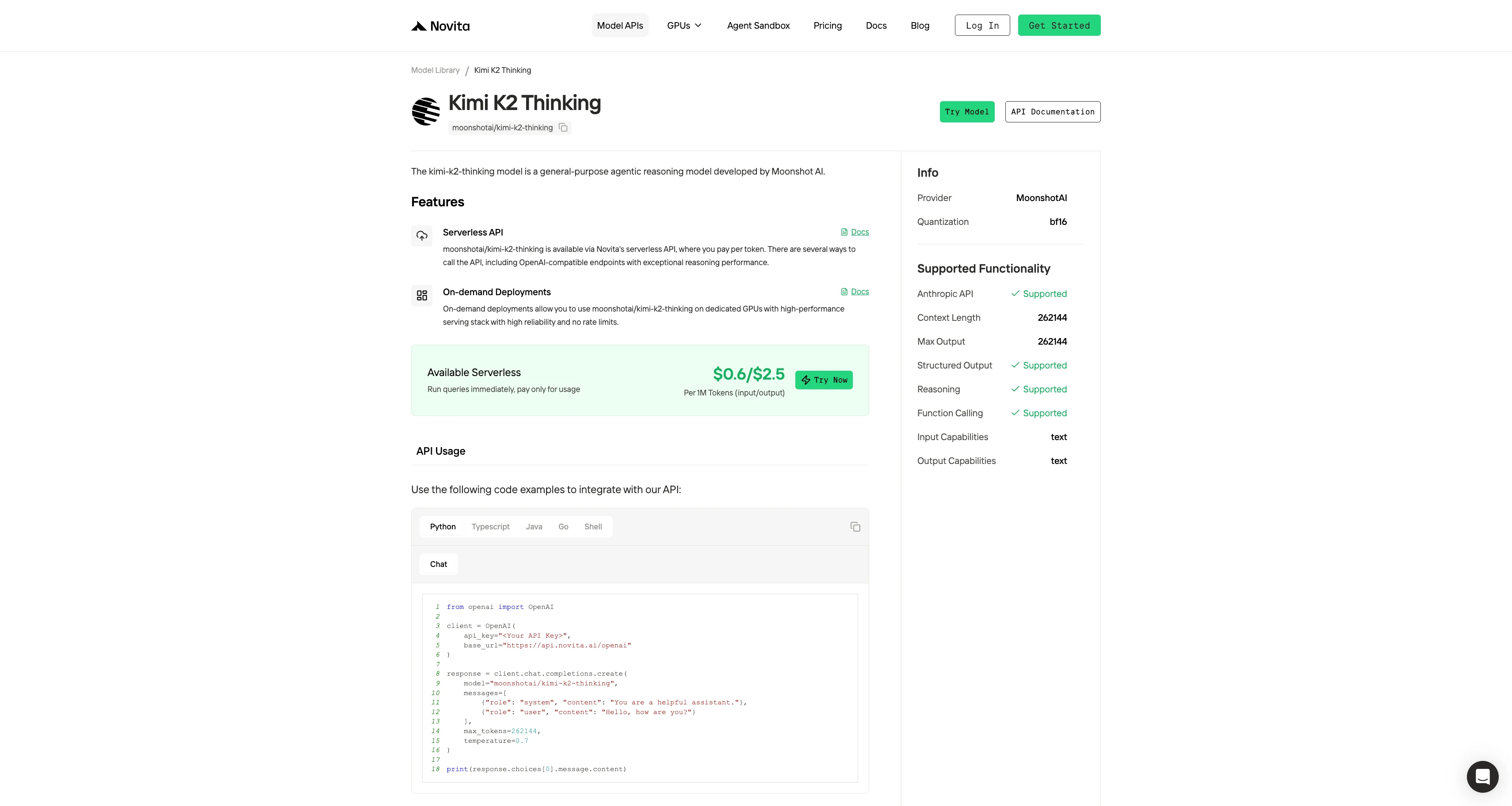
Paso 4: Obtén tu clave API
Para autenticarte en la API, te proporcionaremos una nueva clave API. Al ingresar a la página “Settings”, puedes copiar la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el administrador de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo del uso de la API de finalización de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Tu clave API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2-thinking",
messages=[
{"role": "system", "content": "Eres un asistente útil."},
{"role": "user", "content": "Hola, ¿cómo estás?"}
],
max_tokens=262144,
temperature=0.7
)
print(response.choices[0].message.content)
Kimi K2 Thinking con Trae
Paso 1: Abre Trae y accede a los modelos
Inicia la aplicación Trae. Haz clic en el botón “Toggle AI Side Bar” en la esquina superior derecha para abrir la barra lateral de IA. Luego, ve a “AI Management” y selecciona “Models”.

Paso 2: Añade un modelo personalizado y elige Novita como proveedor
Haz clic en el botón Add Model para crear una entrada de modelo personalizada. En el cuadro de diálogo de añadir modelo, selecciona Provider = Novita en el menú desplegable.


Paso 3: Selecciona o introduce el modelo
En el menú desplegable “Model”, elige el modelo deseado (DeepSeek-R1-0528, Kimi K2 thinking, DeepSeek-V3-0324 o MiniMax-M1-80k). Si el modelo exacto no aparece listado, simplemente escribe el ID del modelo que anotaste de la biblioteca de Novita. Asegúrate de elegir la variante correcta del modelo que deseas usar.
Paso 5: Introduce tu clave API
Copia la clave API de Novita AI desde tu consola de Novita y pégala en el campo “API Key” en Trae.
Paso 6: Guarda la configuración
Haz clic en Add Model para guardar. Trae validará la clave API y la selección del modelo en segundo plano.
Consejos para usar Kimi-K2-Thinking en Trae
Aquí tienes consejos prácticos para usar Kimi‑K2‑Thinking en Trae para desarrolladores:
1. Define el objetivo claramente
Comienza tu mensaje con un objetivo de alto nivel claro. Por ejemplo:
“Tu objetivo es analizar este conjunto de datos y producir un informe que resuma los hallazgos, luego generar código para visualizar las métricas clave.”
Esto aprovecha la fortaleza de K2 en el razonamiento de cadena larga y la orquestación de herramientas.
2. Incluye el rol del sistema y las restricciones
Usa un mensaje de sistema como:
“Eres un asistente de IA construido con Kimi-K2-Thinking. Asegúrate de reafirmar todas las restricciones antes de proceder.”
Reafirmar las restricciones ayuda a reducir errores en el razonamiento de múltiples pasos. (Skywork)
3. Habilita el entorno de llamadas a funciones en Trae
Al usar Trae, configura la llamada al modelo para incluir las herramientas disponibles (por ejemplo, búsqueda, consulta a base de datos, ejecución de código). K2 puede decidir cuándo y cómo llamar a las herramientas.
4. Establece parámetros apropiados
- Usa temperature ≈ 1.0 para un rendimiento de razonamiento equilibrado.
- Si las tareas son lógicas o de análisis intensivo, mantén la temperatura más baja (0.1-0.3) para reducir la aleatoriedad.
- Ten cuidado con la longitud del contexto: aunque K2 soporta hasta 256k tokens, entradas extremadamente largas pueden ralentizar la respuesta.
5. Divide las tareas para un mejor control
En lugar de “resuelve esto en un solo paso”, usa mensajes como:
“1) Describe 3 enfoques posibles. 2) Evalúa cada enfoque. 3) Elige uno y ejecútalo.”
Esto ayuda a K2 a mantener la estructura y mejora la calidad de las respuestas.
6. Valida las salidas y el razonamiento
Pide al modelo que genere su cadena de razonamiento o suposiciones. Por ejemplo:
“Enumera las suposiciones que hiciste y las restricciones que verificaste antes de proceder.”
Esto es útil para auditar en proyectos complejos.
7. Empareja el modelo con los tipos de tarea
Usa K2 para:
- Razonamiento de múltiples pasos, planificación, flujos de trabajo de investigación
- Tareas que requieren orquestación de herramientas y cadenas largas
Para tareas más simples o críticas en latencia, un modelo más ligero puede ser más eficiente.
8. Monitorea el costo y la latencia
El razonamiento y el uso de herramientas de K2 generan más tokens y toman más tiempo que los modelos básicos. Presupuesta en consecuencia cuando se implemente a través de Trae.
Si lo deseas, puedo redactar una plantilla de configuración de Trae (YAML/JSON) para integrar K2-Thinking con estas mejores prácticas.
Por qué los desarrolladores eligen Novita AI con Trae
| Dimensión clave | Valor clave | Explicación clara |
|---|---|---|
| 💰 Controla los costos | Administra el uso de la API y la facturación de forma independiente | Controlas tu clave API y tu presupuesto: sin márgenes ocultos ni tarifas de intermediarios. |
| 🚀 Accede primero a los nuevos modelos | Acceso instantáneo a los modelos de IA más recientes | DeepSeek, LLaMA y Mistral están disponibles inmediatamente una vez alojados en Novita. |
| 📈 Planes escalables | Crece fácilmente desde prototipo hasta producción | Precios de pago por uso que se escalan suavemente con el tamaño de tu proyecto. |
| 🧩 Entorno de desarrollo integral | Conjunto integrado de herramientas de desarrollo e IA | Codifica, analiza y colabora directamente dentro de Trae, sin necesidad de herramientas externas. |
| 🔄 Flujo de trabajo fluido | Interfaz unificada y automatización | Escribe, depura y llama a funciones de IA todo en un entorno consistente. |
Kimi-K2-Thinking redefine la inteligencia de código abierto al combinar una profunda estabilidad de razonamiento con una orquestación eficiente de herramientas. Sostiene cientos de llamadas secuenciales a herramientas, mantiene la coherencia en contextos largos y ofrece un rendimiento de nivel Claude a una fracción del costo.
Para cualquier desarrollador que maneje flujos de trabajo agentivos, investigación automatizada o codificación analítica de formato largo, Kimi-K2-Thinking proporciona una base escalable, transparente y asequible para el desarrollo de IA de próxima generación.
Preguntas frecuentes
¿Cuándo deberían los desarrolladores cambiarse a Kimi-K2-Thinking?
Cámbiate cuando tu proyecto implique razonamiento de múltiples pasos, uso frecuente de herramientas o ventanas de contexto grandes, escenarios donde Kimi-K2-Thinking mantiene la precisión y la lógica mientras otros modelos se desvían o cobran de más.
¿En qué se diferencia Kimi-K2-Thinking de Claude Sonnet 4?
Kimi-K2-Thinking sostiene de 200 a 300 llamadas a herramientas con razonamiento estable y cuesta aproximadamente entre un 75 y un 80 % menos, mientras que el precio de Claude Sonnet 4 aumenta drásticamente con contextos más largos y acciones de agente frecuentes.
¿Puede Kimi-K2-Thinking manejar tareas de desarrollo full-stack?
Sí. Kimi-K2-Thinking automatiza el procesamiento de datos, la generación de código, la depuración y la mejora iterativa dentro de la configuración de llamadas a herramientas de Trae o Novita AI.
Novita AI es la plataforma en la nube integral que impulsa tus ambiciones de IA. APIs integradas, sin servidor, instancias GPU: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.
Lecturas recomendadas
Cómo acceder a Qwen 3 Coder: Qwen Code; Claude Code; Trae
Cómo usar GLM-4.6 en Cursor para aumentar la productividad de equipos pequeños



