

- Unter welchen Bedingungen sollten Entwicklerinnen zu Kimi-K2-Thinking wechseln?
- Was hat Kimi K2 Thinking in Open-Source-Modellen revolutioniert?
- Welches Modell schneidet besser ab: Kimi-K2-Thinking oder Sonnet 4?
- Wie verwendet man Kimi-K2-Thinking in Trae?
- Tipps für die Verwendung von Kimi-K2-Thinking in Trae
- Warum Entwicklerinnen Novita AI mit Trae wählen
Moderne Entwickler*innen haben oft Schwierigkeiten, fortschrittliche Reasoning-Modelle in praktische, toolreiche Systeme zu integrieren. Selbst leistungsstarke Modelle wie Claude oder GPT erfordern komplexe Einrichtungen, um Coding, Debugging und Daten-Workflows effizient zu verbinden. Genau hier wird Trae zum echten Enabler für Kimi-K2-Thinking.
Durch die Kombination von Traes All-in-One-Entwicklungsumgebung mit Kimi-K2-Thinkings langfristigem Reasoning erhalten Entwickler*innen eine nahtlose Möglichkeit, autonome, multi-tool KI-Workflows zu erstellen. Trae bietet Modellintegration, Tool-Orchestrierung und Echtzeit-Debugging in einer einzigen einheitlichen Oberfläche, während Kimi-K2-Thinking stabiles, über 200 Schritte umfassendes Reasoning mit 256K-Token-Kontext und effizienter Kostenskalierung liefert.
Dieser Artikel erklärt, unter welchen Bedingungen Entwickler*innen zu Kimi-K2-Thinking wechseln sollten, wie Trae und Novita AI gemeinsam die Bereitstellung mühelos machen und warum dieser Stack komplexe Reasoning in einen praktischen, erschwinglichen Entwicklungsvorteil verwandelt.
Unter welchen Bedingungen sollten Entwickler*innen zu Kimi-K2-Thinking wechseln?
Wenn Ihr Workflow langfristige Reasoning, Multi-Tool-Koordination und minimale Überwachung erfordert – ist Kimi-K2-Thinking Ihre ideale Engine.
Automatisierte Datenanalyse
Tools: Python / SQL / Plotly
Verwenden Sie es, wenn: Sie mehrstufiges Reasoning benötigen – Daten → Bereinigung → Modellierung → Visualisierung → Bericht.
Warum Kimi-K2: Behält die Logik über Hunderte von Tool-Aufrufen hinweg stabil im Blick.
Recherche & Literaturübersicht
Tools: Websuche / Zitier-Parser / Zusammenfassungstools
Verwenden Sie es, wenn: Sie große Mengen an Text lesen, vergleichen und zusammenfassen müssen.
Warum Kimi-K2: Bietet nachhaltiges Langkontext-Verständnis und strukturierte Zusammenfassung.
Intelligenter Kundensupport
Tools: Retrieval-APIs / CRM-Systeme / Sentiment-Modelle
Verwenden Sie es, wenn: Gespräche sich über mehrere Runden und Datenquellen erstrecken.
Warum Kimi-K2: Behält den Kontext bei und orchestriert Tool-Antworten nahtlos.
KI-gestütztes Coding
Tools: Code-Interpreter / Debugger / Compiler
Verwenden Sie es, wenn: Sie automatisierte Planung, Tests und Fehlerbehebung benötigen.
Warum Kimi-K2: Iteriert autonom durch vollständige Entwicklungszyklen.
Marketing-Automatisierung
Tools: Analyse-Dashboards / A/B-Test-APIs / Keyword-Tools
Verwenden Sie es, wenn: Kampagnen eine datengestützte Optimierung über einen längeren Zeitraum erfordern.
Warum Kimi-K2: Führt wiederholte Auswertungen durch und verfeinert kreative Strategien.
Enterprise-Wissensagenten
Tools: Datenbanken / Suchmaschinen / Slack-Konnektoren
Verwenden Sie es, wenn: Teams einheitliche, kontinuierlich aktualisierte Einblicke benötigen.
Warum Kimi-K2: Koordiniert die Tool-Nutzung mit langfristigem Reasoning-Gedächtnis.
Testen Sie Kimi K2 Thinking jetzt kostenlos!
Was hat Kimi K2 Thinking in Open-Source-Modellen revolutioniert?
Die Architektur von Kimi-K2 balanciert Skalierbarkeit, Effizienz und Stabilität und ermöglicht es ihm, toolreiches Reasoning über lange Sequenzen hinweg ohne Kohärenzverlust durchzuführen.
Ein neuer Standard für langfristiges Reasoning
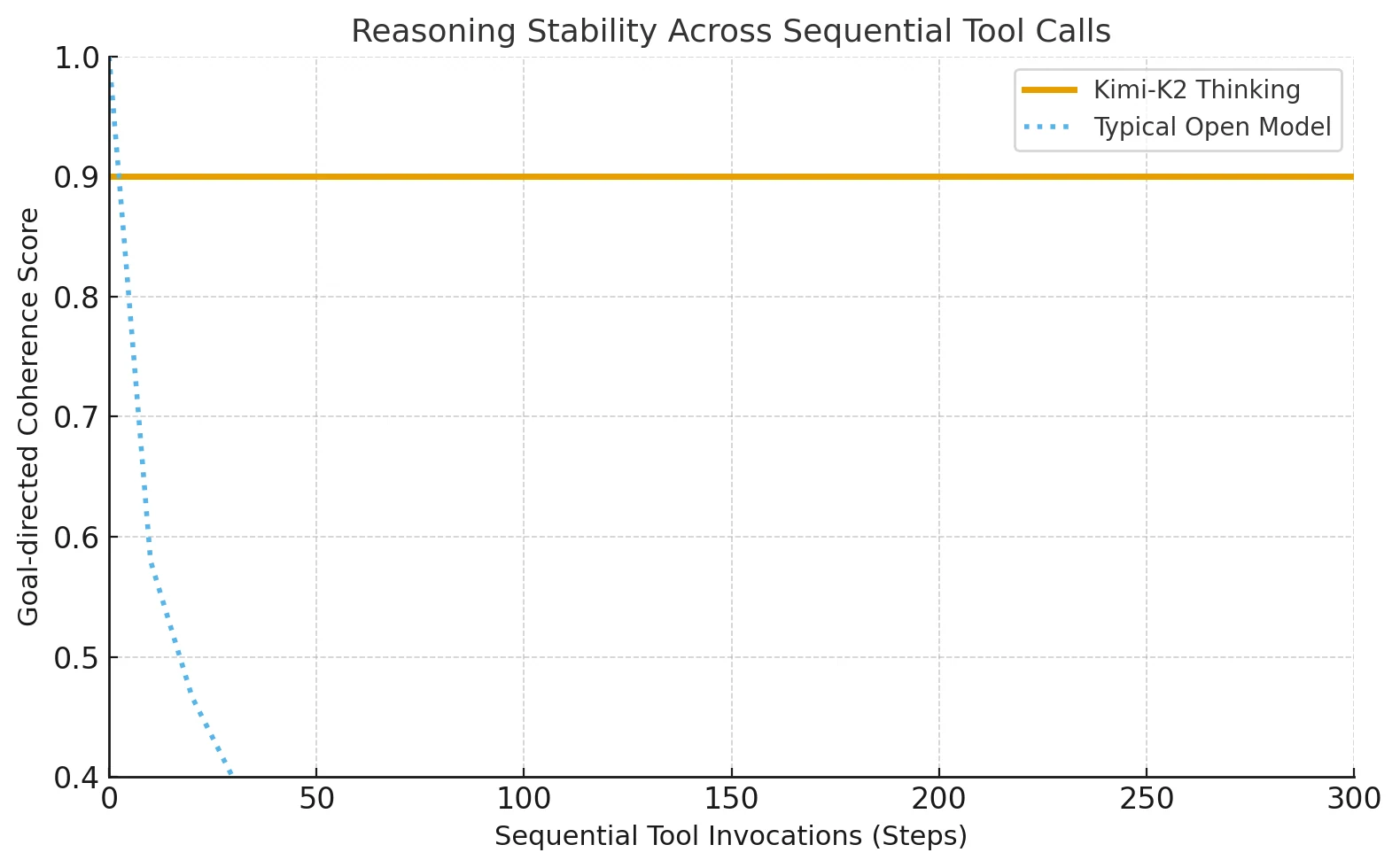
Kimi-K2-Thinking führt eine fortschrittliche Thinking-Agent-Architektur ein, die strukturiertes Reasoning mit adaptiver Tool-Nutzung verzahnt. Es kann 200–300 aufeinanderfolgende Tool-Aufrufe durchführen, ohne die Richtung oder Kohärenz zu verlieren.
Die meisten Open-Source-Modelle brachen zuvor nach etwa 30–50 Schritten ab, aber Kimi-K2 hält die Genauigkeit auch bei langen Aufgaben aufrecht, die schrittweises Reasoning erfordern.
Von geschlossenen Systemen zu offenen Thinking-Agenten
Vor Kimi-K2 konnte nur Anthropics Claude eine solche verzahnte Tool-Reasoning aufrechterhalten. Kimi-K2 erweitert diese Methode auf Open-Source-Ökosysteme und ermöglicht es unabhängigen Entwickler*innen, auf stabile, langfristige kognitive Ketten zuzugreifen, die zuvor exklusiv für geschlossene KI-Plattformen reserviert waren.
Kernsystemarchitektur
| Komponente | Funktionale Rolle |
|---|---|
| Mixture-of-Experts (MoE) | Erhöht die dynamische Kapazität bei gleichbleibenden Rechenkosten. |
| 1T Parameter / 32B aktiviert | Balanciert Skalierbarkeit mit effizientem Token-weiser Routing. |
| 61 Gesamtschichten + 1 dichter Backbone | Bewahrt die Tiefe bei gleichzeitiger Gewährleistung der Signalstabilität. |
| 384 Experten, 8 aktiv pro Token | Verbessert die Anpassungsfähigkeit an unterschiedliche Reasoning-Kontexte. |
| 256K Token-Fenster | Ermöglicht Kontinuität bei extrem langen Aufgaben. |
| Multi-Head Latent Attention (MLA) | Verbessert die fokussierte Aufmerksamkeit über Schritte hinweg und reduziert den Speicherbedarf. |
| SwiGLU-Aktivierung | Glättet den Gradientenfluss und stabilisiert tiefes Reasoning. |
Welches Modell schneidet besser ab: Kimi-K2-Thinking oder Sonnet 4?
Leistungsvergleich
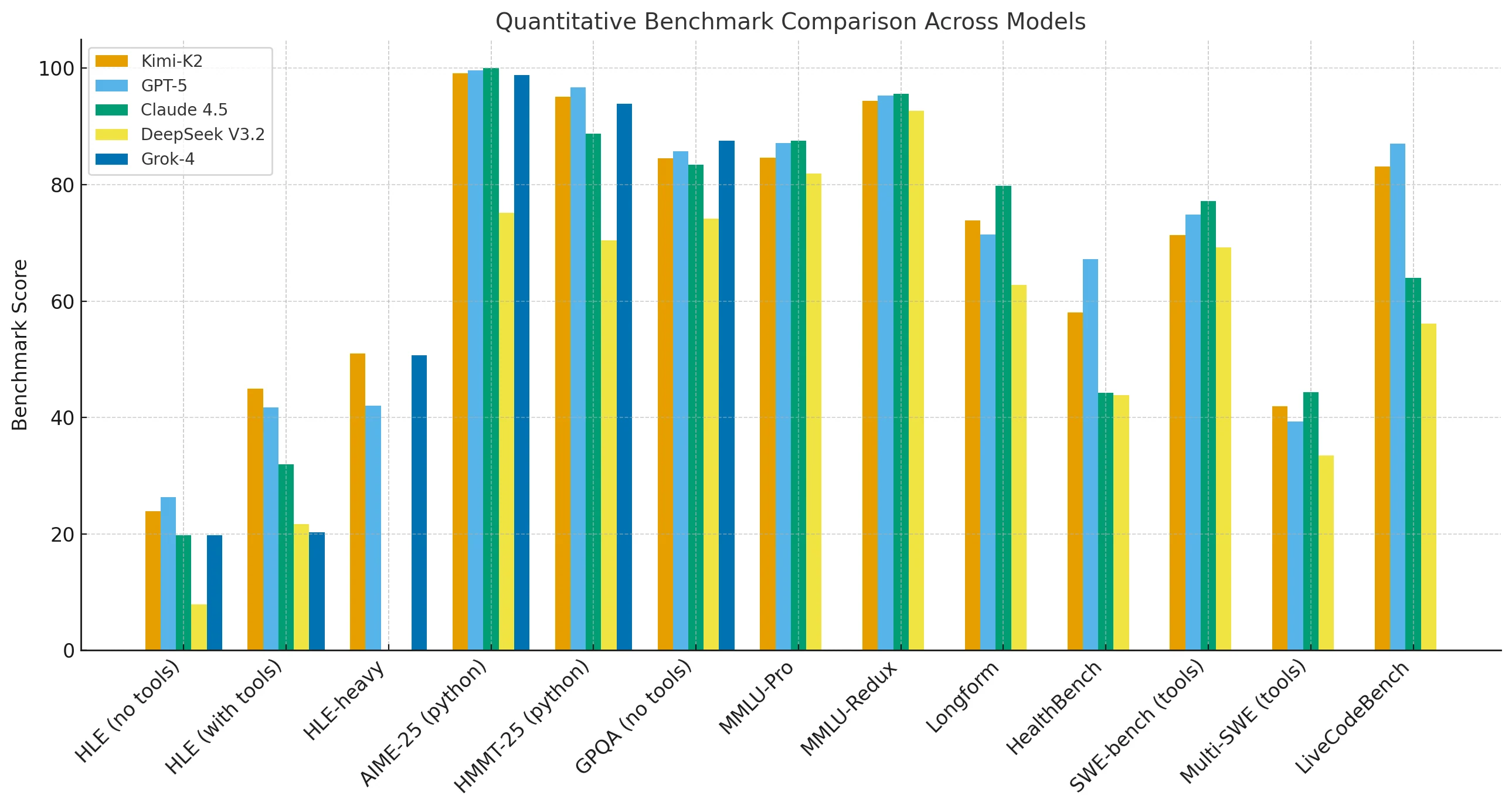
Kimi-K2-Thinking schneidet bei wichtigen Reasoning- und Mathematik-Benchmarks vergleichbar mit GPT-5 und Claude ab. Es hinkt bei MMLU-Pro, Redux, langformatiertem Schreiben und Codegenerierungsaufgaben leicht hinterher, übertrifft die Konkurrenz jedoch, wenn externe Tools verfügbar sind oder Reasoning-Ketten verlängert werden.
In Einstellungen mit hoher Ausführungsdauer (HLE) und Tool-Nutzung erreicht Kimi-K2 44,9, verglichen mit Claudes 32,0, was seine Stärke bei nachhaltigem, Multi-Tool-Reasoning unterstreicht.
Kosteneffizienz
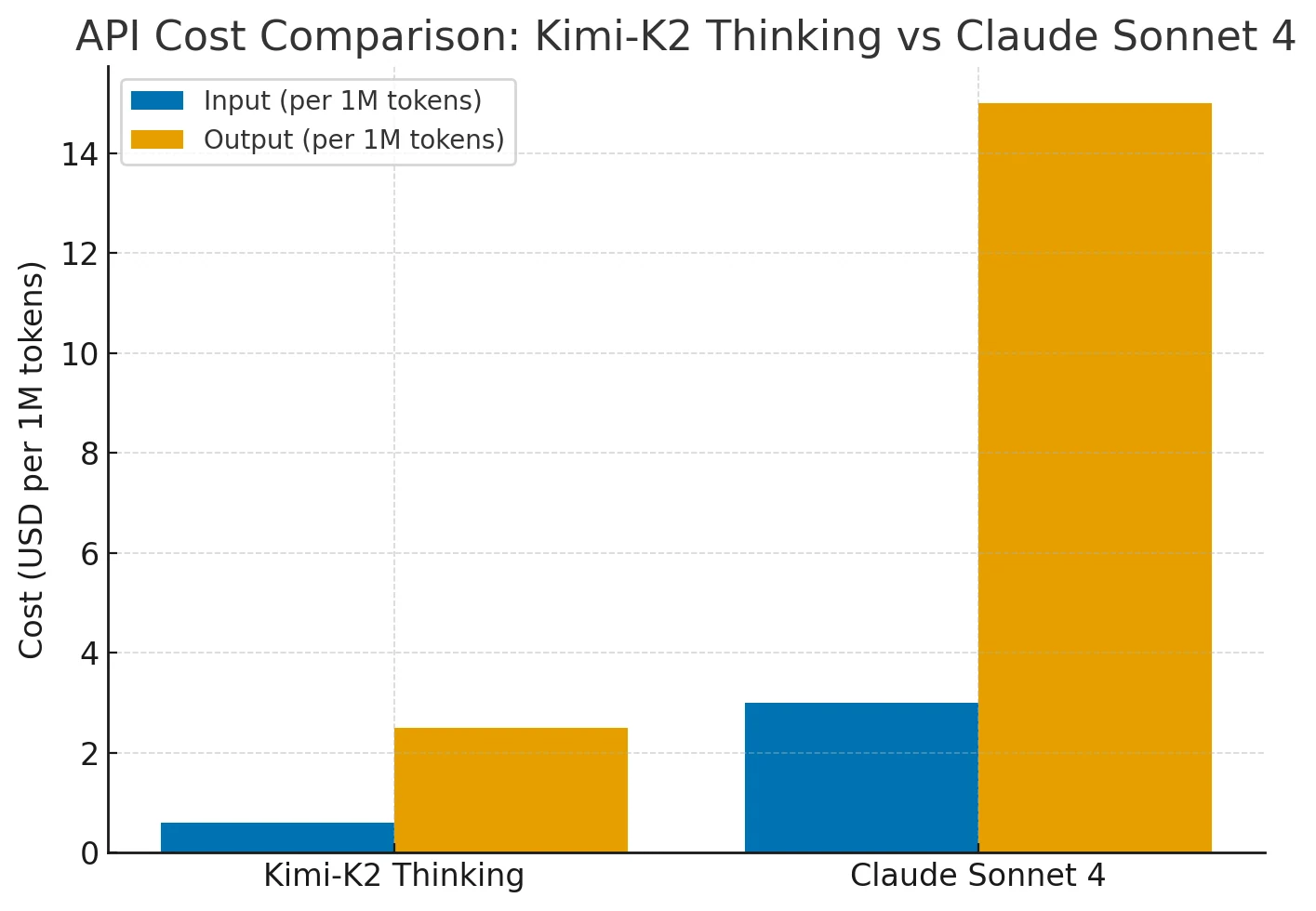
Kimi-K2 bietet eine mit Claude Sonnet 4 vergleichbare Leistung zu 75–80 % niedrigeren Kosten. Seine Preisgestaltung bleibt über lange Kontexte (bis zu 256 K Token) und häufige Tool-Nutzung hinweg konstant, während Claudes Kosten mit der Kontextlänge und Agentenaktionen stark ansteigen.
Kimi-K2 liefert daher Claude/GPT-Niveau an Fähigkeiten mit überlegener Kosten-Leistungs-Effizienz für erweiterte Reasoning-Aufgaben.
Testen Sie Kimi K2 Thinking jetzt!
Wie verwendet man Kimi-K2-Thinking in Trae?
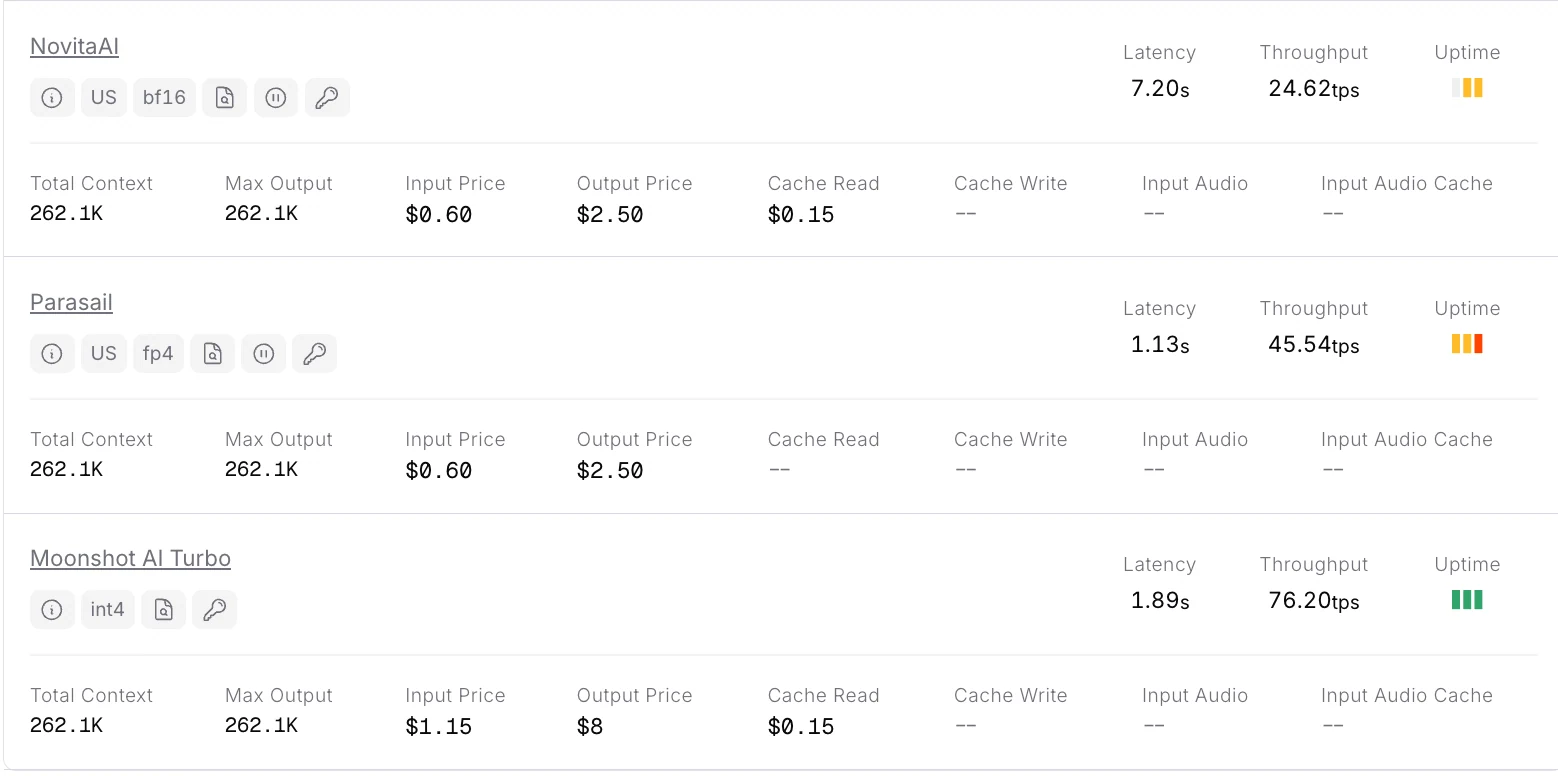
Novita AI bietet derzeit die günstigste Full-Context-Kimi-K2-Thinking-API an.
Novita AI bietet APIs mit 262K Kontext und Kosten von 0,6 $/Eingabe und 2,5 $/Ausgabe, die strukturierte Ausgabe und Funktionsaufrufe unterstützen. Dies bietet starke Unterstützung, um das Potenzial von Kimi K2 Thinking als Code-Agent maximal auszuschöpfen.
Schritt 1: API-Schlüssel erhalten
Schritt 1: Melden Sie sich bei Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Testen Sie Kimi K2 Thinking jetzt!
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells zu erkunden.
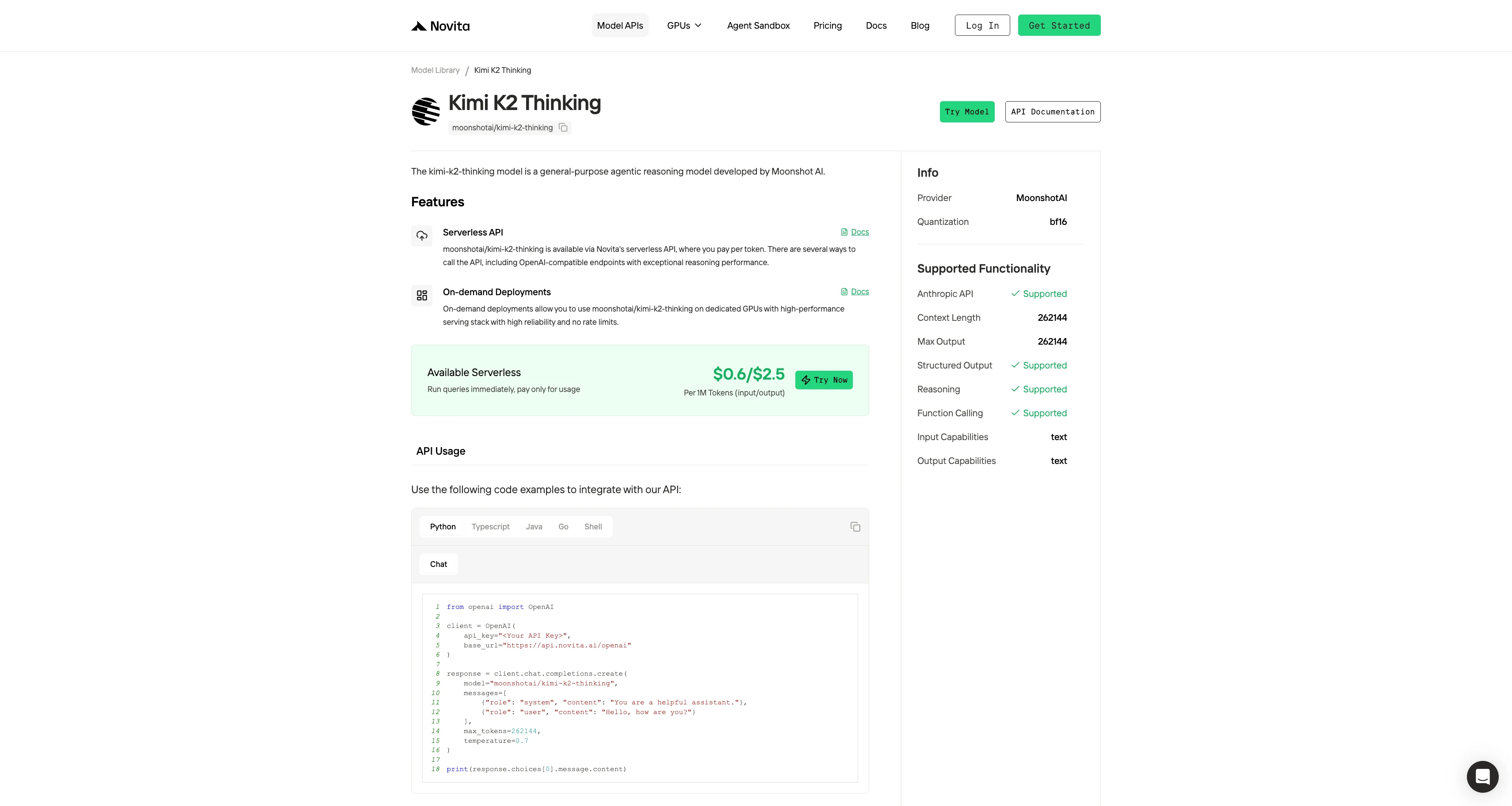
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Um sich bei der API zu authentifizieren, stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Gehen Sie auf die Seite „Einstellungen“, dort können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager. Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Nutzer*innen.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2-thinking",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=262144,
temperature=0.7
)
print(response.choices[0].message.content)
Kimi K2 Thinking mit Trae
Schritt 1: Trae öffnen und auf Modelle zugreifen
Starten Sie die Trae-App. Klicken Sie oben rechts auf die Schaltfläche „KI-Seitenleiste umschalten“, um die KI-Seitenleiste zu öffnen. Gehen Sie dann zu KI-Verwaltung und wählen Sie Modelle.

Schritt 2: Eigenes Modell hinzufügen und Novita als Anbieter auswählen
Klicken Sie auf die Schaltfläche Modell hinzufügen, um einen benutzerdefinierten Modelleintrag zu erstellen. Wählen Sie im Dialog zum Hinzufügen von Modellen aus dem Dropdown-Menü Anbieter = Novita aus.


Schritt 3: Modell auswählen oder eingeben
Wählen Sie aus dem Modell-Dropdown das gewünschte Modell aus (DeepSeek-R1-0528, Kimi K2 thinking, DeepSeek-V3-0324 oder MiniMax-M1-80k). Wenn das genaue Modell nicht aufgeführt ist, geben Sie einfach die Modell-ID ein, die Sie aus der Novita-Bibliothek entnommen haben. Stellen Sie sicher, dass Sie die richtige Variante des gewünschten Modells auswählen.
Schritt 5: Geben Sie Ihren API-Schlüssel ein
Kopieren Sie den Novita AI API-Schlüssel aus Ihrer Novita-Konsole und fügen Sie ihn in das Feld „API-Schlüssel“ in Trae ein.
Holen Sie sich jetzt den API-Schlüssel!
Schritt 6: Konfiguration speichern
Klicken Sie auf Modell hinzufügen, um die Einstellungen zu speichern. Trae validiert den API-Schlüssel und die Modellauswahl im Hintergrund!
Tipps für die Verwendung von Kimi-K2-Thinking in Trae
Hier sind praktische Tipps für Entwickler*innen zur Nutzung von Kimi‑K2‑Thinking in Trae:
1. Ziel klar definieren Beginnen Sie Ihre Eingabeaufforderung mit einem klaren übergeordneten Ziel. Beispiel:
„Dein Ziel ist es, diesen Datensatz zu analysieren und einen Bericht mit Zusammenfassung der Erkenntnisse zu erstellen, sowie Code zur Visualisierung der wichtigsten Metriken zu generieren.“
Dies spielt die Stärke von K2 im Bereich langkettiger Reasoning und Tool-Orchestrierung voll aus.
2. System-Rolle + Einschränkungen hinzufügen Verwenden Sie eine System-Eingabeaufforderung wie:
„Du bist ein KI-Assistent, der mit Kimi-K2-Thinking erstellt wurde. Stelle sicher, dass du alle Einschränkungen vor der Ausführung wiederholst.“
Das Wiederholen von Einschränkungen hilft, Fehler bei mehrstufigem Reasoning zu reduzieren. (Skywork)
3. Tool-Aufruf-Umgebung in Trae aktivieren Wenn Sie Trae verwenden, konfigurieren Sie den Modellaufruf so, dass verfügbare Tools (z. B. Suche, Datenbankabfrage, Codeausführung) enthalten sind. K2 kann entscheiden, wann und wie es Tools aufruft.
4. Passende Parameter festlegen
- Verwenden Sie Temperatur ≈ 1,0 für ausgewogene Reasoning-Leistung.
- Wenn Aufgaben logik-/analyseintensiv sind, halten Sie die Temperatur niedriger (0,1–0,3), um Zufälligkeit zu reduzieren.
- Achten Sie auf die Kontextlänge: Obwohl K2 bis zu 256k Token unterstützt, können extrem lange Eingaben die Antwortgeschwindigkeit verlangsamen.
5. Aufgaben für bessere Kontrolle aufteilen Anstatt „Löse dies in einem Schritt“ zu verwenden, nutzen Sie Eingabeaufforderungen wie:
„1) Nenne 3 mögliche Ansätze. 2) Bewerte jeden Ansatz. 3) Wähle einen aus und führe ihn aus.“
Dies hilft K2, die Struktur beizubehalten und verbessert die Antwortqualität.
6. Ausgaben und Reasoning validieren Bitten Sie das Modell, seine Reasoning-Kette oder Annahmen auszugeben. Beispiel:
„Nenne die Annahmen, die du gemacht hast, und die Einschränkungen, die du vor der Ausführung überprüft hast.“
Dies ist nützlich für Audits in komplexen Projekten.
7. Modell an Aufgabentypen anpassen Verwenden Sie K2 für:
- Mehrstufiges Reasoning, Planung, Recherche-Workflows
- Aufgaben, die Tool-Orchestrierung und lange Ketten erfordern Für einfachere oder latenzkritische Aufgaben ist ein leichteres Modell möglicherweise effizienter.
8. Kosten und Latenz überwachen Das Reasoning und die Tool-Nutzung von K2 erzeugen mehr Token und dauern länger als bei Basis-Modellen. Planen Sie das Budget entsprechend, wenn Sie es über Trae bereitstellen.
Wenn Sie möchten, kann ich eine Trae-Konfigurationsvorlage (YAML/JSON) für die Integration von K2-Thinking mit diesen Best Practices entwerfen.
Warum Entwickler*innen Novita AI mit Trae wählen
| Kernbereich | Schlüsselwert | Klare Erklärung |
|---|---|---|
| 💰 Kosten kontrollieren | API-Nutzung und Abrechnung unabhängig verwalten | Sie kontrollieren Ihren API-Schlüssel und Ihr Budget – ohne versteckte Aufschläge oder Zwischenhändlergebühren. |
| 🚀 Zuerst auf neue Modelle zugreifen | Sofortiger Zugriff auf die neuesten KI-Modelle | DeepSeek, LLaMA und Mistral sind sofort verfügbar, sobald sie auf Novita gehostet werden. |
| 📈 Skalierbare Tarife | Einfaches Wachstum von Prototyp bis Produktion | Die nutzungsbasierte Preisgestaltung skaliert reibungslos mit der Größe Ihres Projekts. |
| 🧩 All-in-One-Entwicklungsumgebung | Integrierte Entwicklungs- und KI-Toolbox | Codieren, analysieren und zusammenarbeiten Sie direkt in Trae – keine externen Tools erforderlich. |
| 🔄 Nahtloser Workflow | Einheitliche Oberfläche und Automatisierung | Schreiben, debuggen und rufen Sie KI-Funktionen alles in einer konsistenten Umgebung auf. |
Kimi-K2-Thinking definiert Open-Source-Intelligenz neu, indem es tiefe Reasoning-Stabilität mit effizienter Tool-Orchestrierung kombiniert. Es hält Hunderte von aufeinanderfolgenden Tool-Aufrufen aufrecht, bewahrt die Kohärenz über lange Kontexte hinweg und liefert Claude-Niveau an Leistung zu einem Bruchteil der Kosten.
Für alle Entwickler*innen, die mit agentischen Workflows, automatisierter Recherche oder langformatiertem analytischem Coding arbeiten, bietet Kimi-K2-Thinking eine skalierbare, transparente und erschwingliche Grundlage für die KI-Entwicklung der nächsten Generation.
Häufig gestellte Fragen
Wann sollten Entwickler*innen zu Kimi-K2-Thinking wechseln? Wechseln Sie, wenn Ihr Projekt mehrstufiges Reasoning, häufige Tool-Nutzung oder große Kontextfenster umfasst – Szenarien, in denen Kimi-K2-Thinking Genauigkeit und Logik beibehält, während andere Modelle abweichen oder überteuerte Kosten verursachen.
Wie unterscheidet sich Kimi-K2-Thinking von Claude Sonnet 4? Kimi-K2-Thinking hält 200–300 Tool-Aufrufe mit stabilem Reasoning durch und kostet etwa 75–80 % weniger, während die Preisgestaltung von Claude Sonnet 4 mit längeren Kontexten und häufigen Agentenaktionen stark ansteigt.
Kann Kimi-K2-Thinking Full-Stack-Entwicklungsaufgaben bewältigen? Ja. Kimi-K2-Thinking automatisiert Datenverarbeitung, Codegenerierung, Debugging und iterative Verbesserung in Trae oder Novita AIs Tool-Aufruf-Einrichtung.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen ermöglicht. Integrierte APIs, Serverless, GPU-Instanzen – die kostengünstigen Tools, die Sie brauchen. Eliminieren Sie Infrastrukturaufwand, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.
Empfohlene Lektüre
So greifen Sie auf Qwen 3 Coder zu: Qwen Code; Claude Code; Trae
So verwenden Sie GLM-4.6 in Cursor, um die Produktivität für kleine Teams zu steigern



