

- Em Quais Condições os Desenvolvedores Devem Migrar para o Kimi-K2-Thinking?
- O Que o Kimi K2 Thinking Revolucionou nos Modelos Open-Source?
- Qual Modelo Tem Melhor Desempenho, Kimi-K2-Thinking ou Sonnet 4?
- Como Usar o Kimi-K2-Thinking no Trae?
- Dicas para Usar o Kimi-K2-Thinking no Trae
- Por Que os Desenvolvedores Escolhem a Novita AI com o Trae
Desenvolvedores modernos frequentemente lutam para transformar modelos de raciocínio avançados em sistemas práticos e ricos em ferramentas. Mesmo modelos poderosos como Claude ou GPT exigem configurações complexas para integrar codificação, depuração e fluxos de trabalho de dados de forma eficiente. É aqui que o Trae se torna o verdadeiro habilitador do Kimi-K2-Thinking.
Ao combinar o ambiente de desenvolvimento tudo-em-um do Trae com o raciocínio de longo horizonte do Kimi-K2-Thinking, os desenvolvedores ganham uma forma integrada de construir fluxos de trabalho de IA autônomos e com múltiplas ferramentas. O Trae fornece integração de modelos, orquestração de ferramentas e depuração em tempo real em uma única interface unificada, enquanto o Kimi-K2-Thinking oferece raciocínio estável de mais de 200 passos com contexto de 256K tokens e escalonamento de custos eficiente.
Este artigo explica em quais condições os desenvolvedores devem migrar para o Kimi-K2-Thinking, como o Trae e a Novita AI juntos tornam a implantação sem esforço, e por que essa pilha transforma o raciocínio complexo em uma vantagem de desenvolvimento prática e acessível.
Em Quais Condições os Desenvolvedores Devem Migrar para o Kimi-K2-Thinking?
Quando seu fluxo de trabalho requer raciocínio de longo prazo, coordenação de múltiplas ferramentas e supervisão mínima — o Kimi-K2-Thinking se torna o motor ideal.
Análise de Dados Automatizada
Ferramentas: Python / SQL / Plotly
Use quando: Você precisa de raciocínio em múltiplas etapas — dados → limpeza → modelagem → visualização → relatório.
Por que Kimi-K2: Mantém o rastreamento em centenas de chamadas de ferramentas com lógica estável.
Pesquisa e Revisão de Literatura
Ferramentas: Busca na web / Parsers de citações / Sumarizadores
Use quando: Você precisa ler, comparar e sintetizar grandes volumes de texto.
Por que Kimi-K2: Mantém a compreensão de longo contexto e a sumarização estruturada.
Suporte ao Cliente Inteligente
Ferramentas: APIs de recuperação / Sistemas de CRM / Modelos de sentimento
Use quando: As conversas abrangem múltiplas turnos e fontes de dados.
Por que Kimi-K2: Mantém a memória e orquestra as respostas das ferramentas de forma integrada.
Codificação Assistida por IA
Ferramentas: Interpretador de código / Depurador / Compilador
Use quando: Você precisa de planejamento automatizado, testes e correção de erros.
Por que Kimi-K2: Itera por ciclos de desenvolvimento completos de forma autônoma.
Automação de Marketing
Ferramentas: Painéis de análise / APIs de teste A-B / Ferramentas de palavras-chave
Use quando: As campanhas requerem otimização baseada em dados ao longo do tempo.
Por que Kimi-K2: Realiza avaliações repetidas e refina estratégias criativas.
Agentes de Conhecimento Empresarial
Ferramentas: Bancos de dados / Motores de busca / Conectores do Slack
Use quando: As equipes precisam de insights unificados e continuamente atualizados.
Por que Kimi-K2: Coordena o uso de ferramentas com memória de raciocínio de longo prazo.
Teste o Kimi K2 Thinking gratuitamente agora!
O Que o Kimi K2 Thinking Revolucionou nos Modelos Open-Source?
A arquitetura do Kimi-K2 equilibra escala, eficiência e estabilidade, permitindo que ele realize raciocínio rico em ferramentas em sequências longas sem perda de coerência.
Um Novo Padrão para Raciocínio de Longo Horizonte
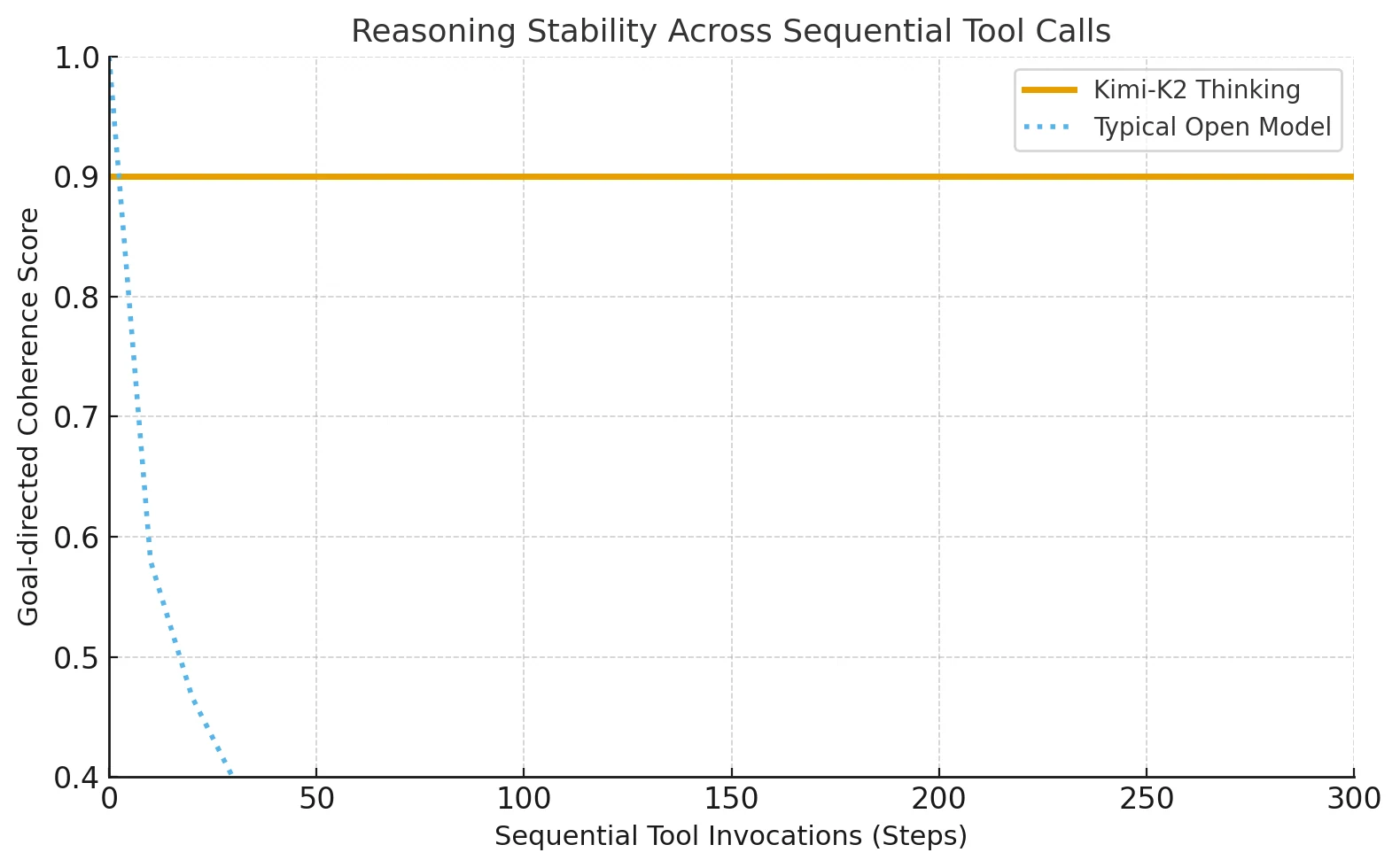
O Kimi-K2-Thinking introduz uma arquitetura avançada de agente de raciocínio que intercala raciocínio estruturado com uso adaptativo de ferramentas. Ele pode concluir 200 a 300 chamadas de ferramentas consecutivas sem perder a direção ou a coerência.
A maioria dos modelos open-source anteriormente falhava após cerca de 30 a 50 passos, mas o Kimi-K2 mantém a precisão em tarefas longas que exigem raciocínio passo a passo.
De Sistemas Fechados para Agentes de Raciocínio Abertos
Antes do Kimi-K2, apenas o Claude da Anthropic conseguia manter esse raciocínio intercalado com ferramentas. O Kimi-K2 estende esse método para ecossistemas open-source, permitindo que desenvolvedores independentes acessem cadeias cognitivas longas e estáveis que antes eram exclusivas de plataformas de IA fechadas.
Arquitetura Central do Sistema
| Componente | Função |
|---|---|
| Mixture-of-Experts (MoE) | Aumenta a capacidade dinâmica mantendo o custo de computação constante. |
| 1T de parâmetros / 32B ativados | Equilibra escala com roteamento eficiente por token. |
| 61 camadas totais + 1 backbone denso | Preserva a profundidade enquanto garante a estabilidade do sinal. |
| 384 especialistas, 8 ativos por token | Aumenta a adaptabilidade a diferentes contextos de raciocínio. |
| Janela de 256K tokens | Permite continuidade em tarefas ultra longas. |
| Multi-Head Latent Attention (MLA) | Melhora o foco entre passos e reduz a carga de memória. |
| Ativação SwiGLU | Suaviza o fluxo de gradiente e estabiliza o raciocínio profundo. |
Qual Modelo Tem Melhor Desempenho, Kimi-K2-Thinking ou Sonnet 4?
Comparação de Desempenho
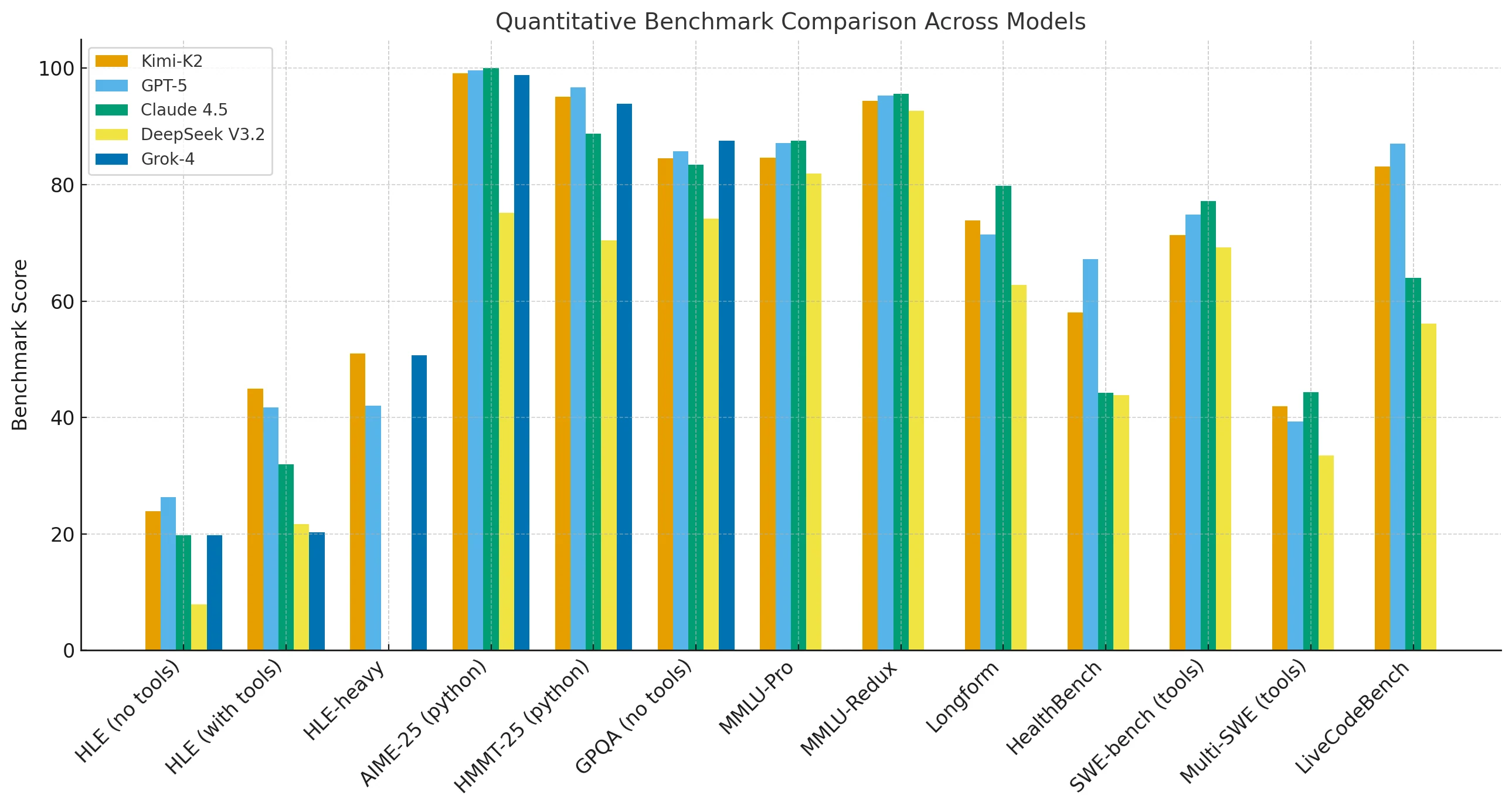
O Kimi-K2-Thinking tem desempenho próximo ao GPT-5 e ao Claude nos principais benchmarks de raciocínio e matemática. Ele fica ligeiramente atrás em tarefas de MMLU-Pro, Redux, redação longa e geração de código, mas supera esses modelos quando ferramentas externas estão disponíveis ou quando as cadeias de raciocínio são estendidas.
Em configurações de execução de alta duração (HLE, na sigla em inglês) com ferramentas, o Kimi-K2 atinge 44,9, comparado aos 32,0 do Claude, demonstrando sua força em raciocínio sustentado e com múltiplas ferramentas.
Eficiência de Custo
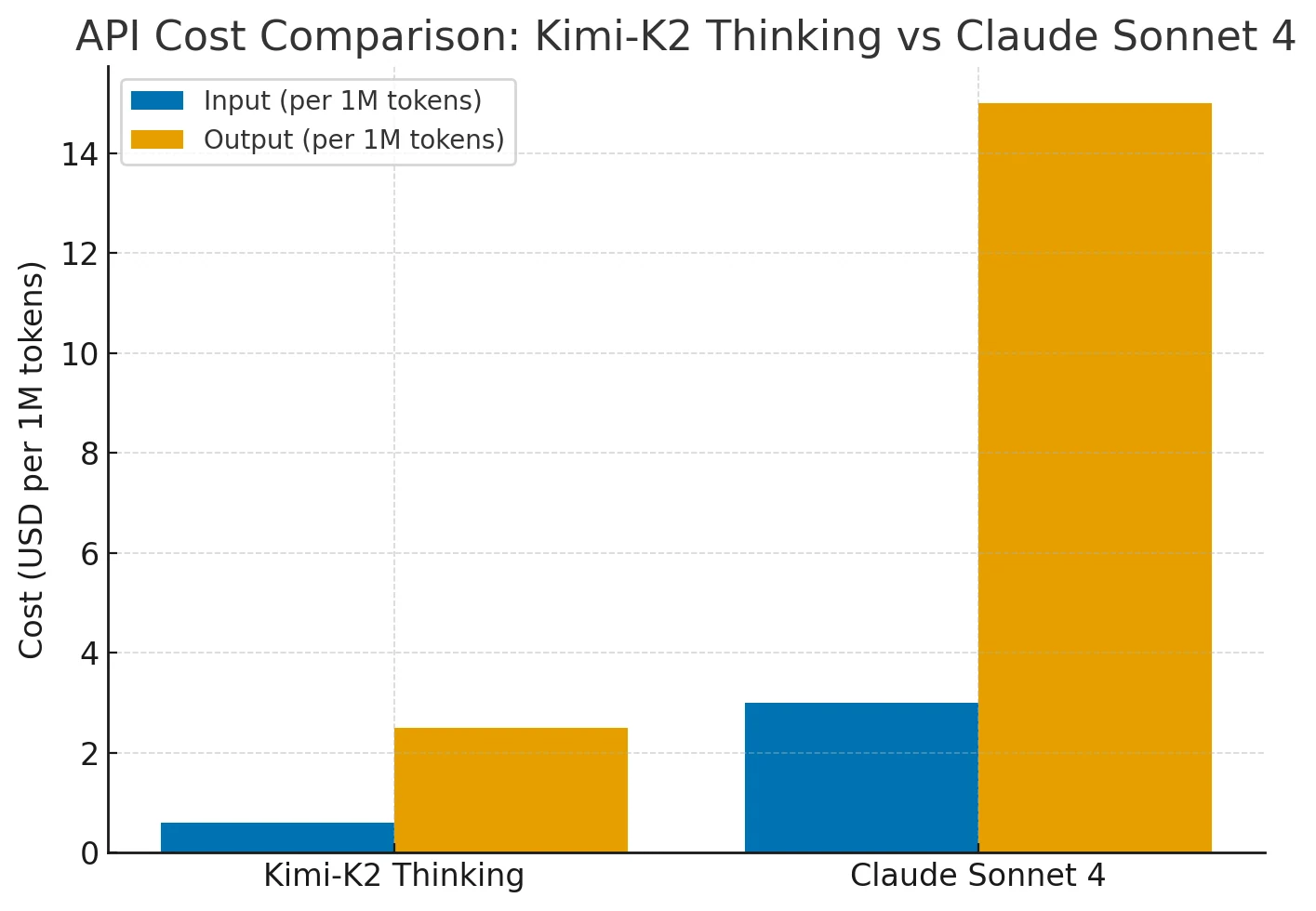
O Kimi-K2 oferece desempenho comparável ao Claude Sonnet 4 com 75 a 80 % de custo menor. Seu preço se mantém estável em contextos longos (de até 256 K tokens) e uso frequente de ferramentas, enquanto o custo do Claude aumenta acentuadamente com o comprimento do contexto e as ações do agente.
Portanto, o Kimi-K2 oferece capacidade de nível Claude/GPT com eficiência de custo-benefício superior para tarefas de raciocínio estendidas.
Teste o Kimi K2 Thinking agora!
Como Usar o Kimi-K2-Thinking no Trae?
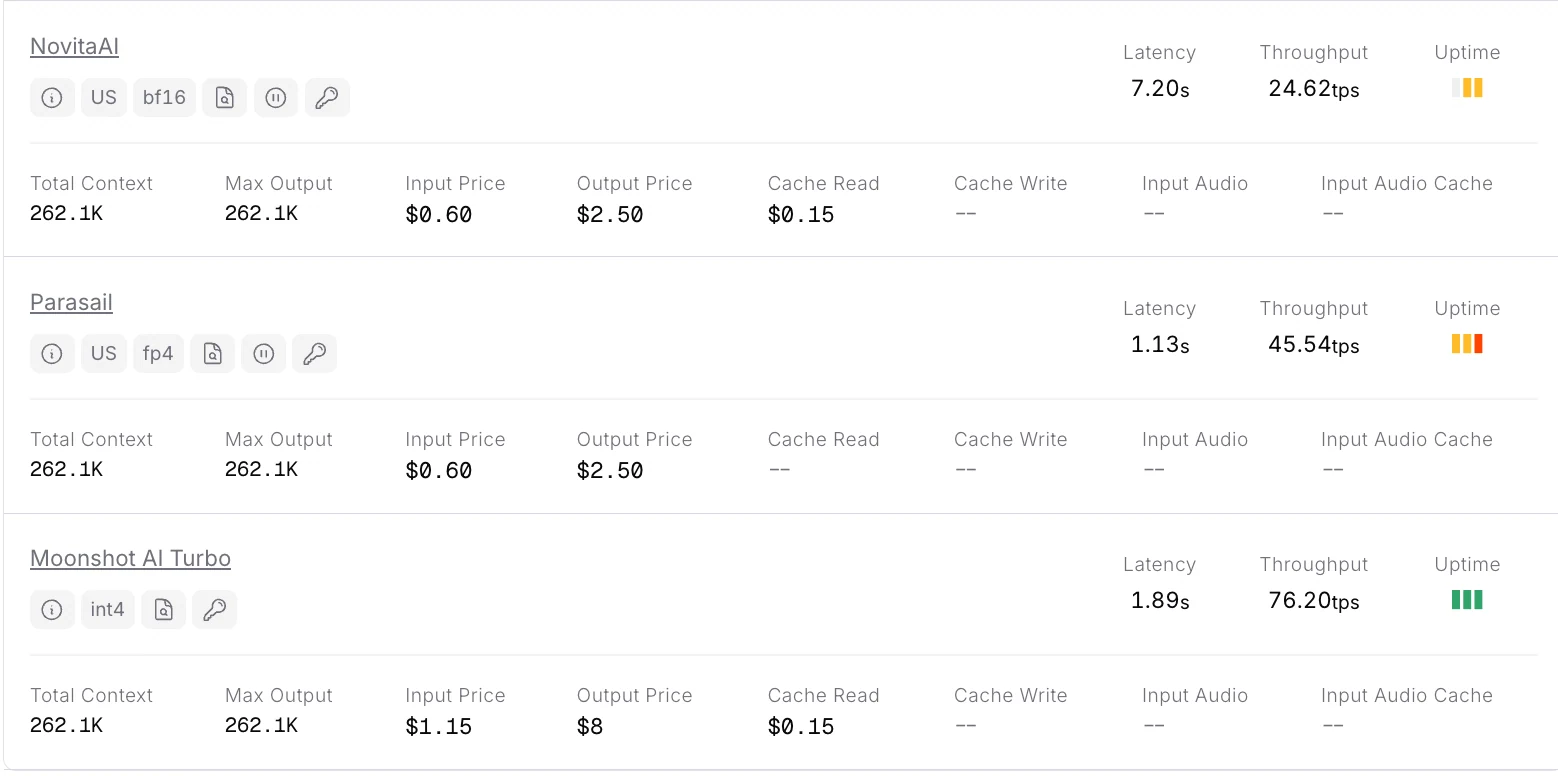
A Novita AI atualmente oferece a API de Kimi-K2-Thinking de contexto completo mais acessível.
A Novita AI fornece APIs com contexto de 262K, e custos de $0,6/entrada e $2,5/saída, com suporte a saída estruturada e chamada de funções, o que oferece um forte suporte para maximizar o potencial do agente de código do Kimi K2 Thinking.
Primeiro: Obtenha a Chave de API
Passo 1: Faça login na sua conta e clique no botão da Biblioteca de Modelos.

Teste o Kimi K2 Thinking agora!
Passo 2: Escolha Seu Modelo Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Passo 3: Inicie Seu Teste Gratuito Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
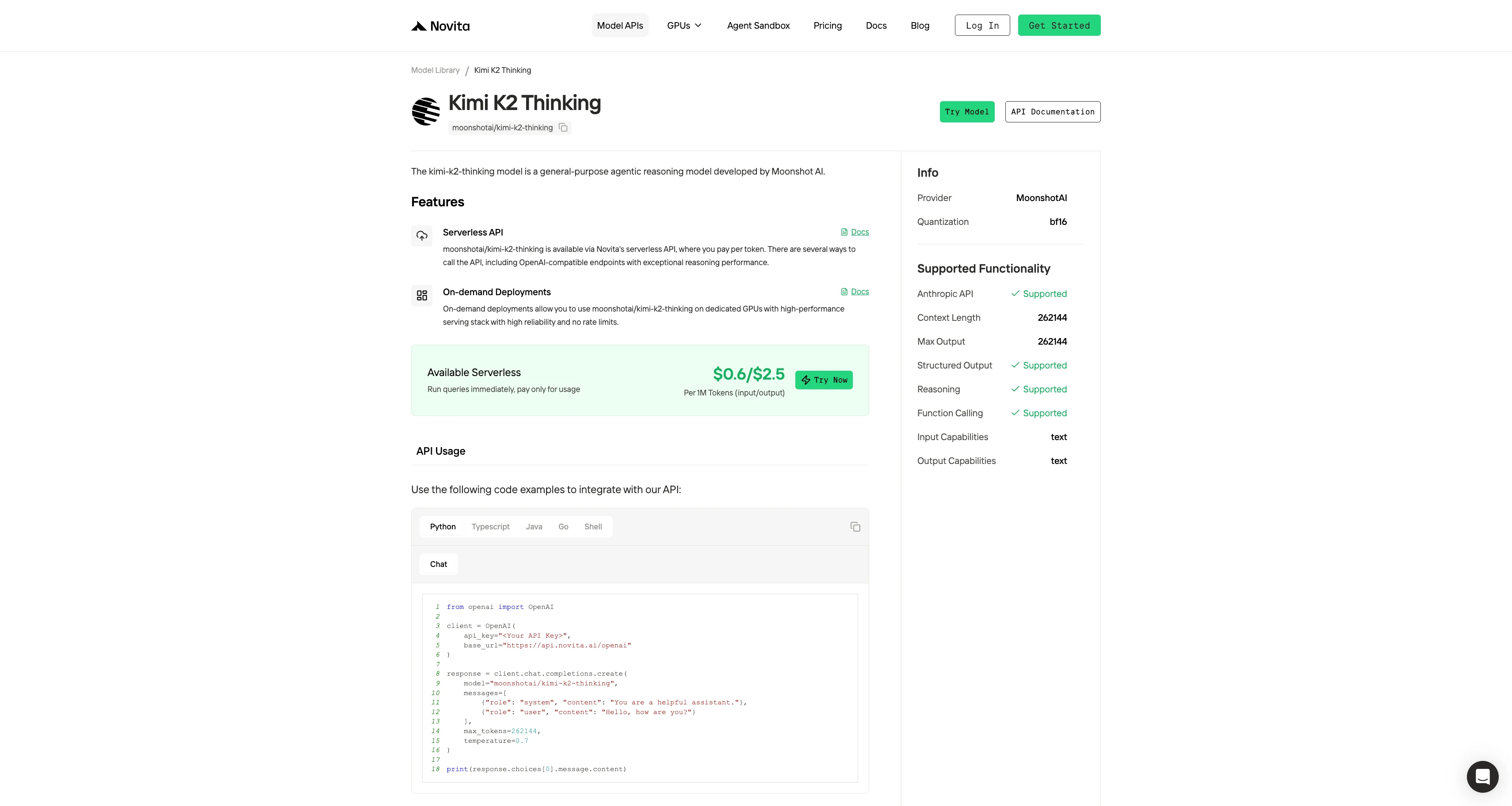
Passo 4: Obtenha Sua Chave de API Para autenticar com a API, forneceremos uma nova chave de API para você. Acessando a página de “Configurações“, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusão de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2-thinking",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=262144,
temperature=0.7
)
print(response.choices[0].message.content)
Kimi K2 Thinking com o Trae
Passo 1: Abra o Trae e Acesse os Modelos
Inicie o aplicativo Trae. Clique na Barra Lateral de IA no canto superior direito para abrir a Barra Lateral de IA. Em seguida, vá para Gerenciamento de IA e selecione Modelos.

Passo 2: Adicione um Modelo Personalizado e Escolha a Novita como Provedor
Clique no botão Adicionar Modelo para criar uma entrada de modelo personalizada. Na caixa de diálogo de adição de modelo, selecione Provedor = Novita no menu suspenso.


Passo 3: Selecione ou Insira o Modelo
No menu suspenso de Modelos, escolha o modelo desejado (DeepSeek-R1-0528, Kimi K2 thinking, DeepSeek-V3-0324 ou MiniMax-M1-80k). Se o modelo exato não estiver listado, basta digitar o ID do modelo que você anotou na biblioteca da Novita. Certifique-se de escolher a variante correta do modelo que deseja usar.
Passo 5: Insira Sua Chave de API
Copie a chave de API da Novita AI do seu console da Novita e cole-a no campo de Chave de API no Trae.
Passo 6: Salve a Configuração
Clique em Adicionar Modelo para salvar. O Trae validará a chave de API e a seleção do modelo em segundo plano!
Dicas para Usar o Kimi-K2-Thinking no Trae
Aqui estão dicas práticas para usar o Kimi‑K2‑Thinking no Trae para desenvolvedores:
1. Defina o objetivo claramente Comece seu prompt com um objetivo de alto nível claro. Por exemplo:
“Seu objetivo é analisar este conjunto de dados e produzir um relatório resumindo os insights, depois gerar código para visualizar as métricas principais.”
Isso explora a força do K2 em raciocínio de longa cadeia e orquestração de ferramentas.
2. Inclua a função de sistema + restrições Use um prompt de sistema como:
“Você é um assistente de IA construído com o Kimi-K2-Thinking. Certifique-se de repetir todas as restrições antes de prosseguir.”
Repetir as restrições ajuda a reduzir erros no raciocínio em múltiplas etapas. (Skywork)
3. Habilite o ambiente de chamada de ferramentas no Trae Ao usar o Trae, configure a chamada do modelo para incluir as ferramentas disponíveis (por exemplo, busca, consulta a banco de dados, execução de código). O K2 pode decidir quando e como chamar as ferramentas.
4. Defina parâmetros apropriados
- Use temperatura ≈ 1,0 para um desempenho de raciocínio equilibrado.
- Se as tarefas forem pesadas em lógica/análise, mantenha a temperatura mais baixa (0,1 a 0,3) para reduzir a aleatoriedade.
- Tenha cuidado com o comprimento do contexto: embora o K2 suporte até 256k tokens, entradas extremamente longas podem deixar a resposta mais lenta.
5. Divida as tarefas para um melhor controle Em vez de “resolva isso em uma etapa“, use prompts como:
“1) Liste 3 abordagens possíveis. 2) Avalie cada abordagem. 3) Escolha uma e execute.”
Isso ajuda o K2 a manter a estrutura e melhora a qualidade da resposta.
6. Valide as saídas e o raciocínio Peça ao modelo para exibir sua cadeia de raciocínio ou suposições. Por exemplo:
“Liste as suposições que você fez e as restrições que verificou antes de prosseguir.”
Isso é útil para auditoria em projetos complexos.
7. Adeque o modelo aos tipos de tarefa Use o K2 para:
- Raciocínio em múltiplas etapas, planejamento, fluxos de trabalho de pesquisa
- Tarefas que exigem orquestração de ferramentas e cadeias longas
Para tarefas mais simples ou críticas em termos de latência, um modelo mais leve pode ser mais eficiente.
8. Monitore custo e latência O raciocínio e o uso de ferramentas do K2 geram mais tokens e demoram mais do que os modelos básicos. Planeje o orçamento de acordo quando implantado via Trae.
Se você quiser, posso elaborar um modelo de configuração do Trae (YAML/JSON) para integrar o K2-Thinking com essas melhores práticas.
Por Que os Desenvolvedores Escolhem a Novita AI com o Trae
| Dimensão Principal | Valor Chave | Explicação Clara |
|---|---|---|
| 💰 Controle de Custos | Gerencie o uso da API e o faturamento de forma independente | Você controla sua chave de API e orçamento — sem margens ocultas ou taxas de intermediários. |
| 🚀 Acesso a Novos Modelos Primeiro | Acesso instantâneo aos modelos de IA mais recentes | DeepSeek, LLaMA e Mistral estão disponíveis imediatamente após serem hospedados na Novita. |
| 📈 Planos Escaláveis | Cresça do protótipo para a produção facilmente | O preço pagamento por uso escala suavemente com o tamanho do seu projeto. |
| 🧩 Ambiente de Desenvolvimento Tudo-em-Um | Kit de ferramentas de desenvolvimento e IA integrado | Codifique, analise e colabore diretamente no Trae — nenhuma ferramenta externa necessária. |
| 🔄 Fluxo de Trabalho Integrado | Interface unificada e automação | Escreva, depure e chame funções de IA tudo em um ambiente consistente. |
O Kimi-K2-Thinking redefine a inteligência open-source combinando a estabilidade do raciocínio profundo com a orquestração eficiente de ferramentas. Ele sustenta centenas de chamadas de ferramentas sequenciais, mantém a coerência em contextos longos e oferece desempenho de nível Claude a uma fração do custo. Para qualquer desenvolvedor que lida com fluxos de trabalho agentivos, pesquisa automatizada ou codificação analítica longa, o Kimi-K2-Thinking fornece uma base escalável, transparente e acessível para o desenvolvimento de IA de próxima geração.
Perguntas Frequentes
Quando os desenvolvedores devem migrar para o Kimi-K2-Thinking? Migre quando seu projeto envolver raciocínio em múltiplas etapas, uso frequente de ferramentas ou janelas de contexto grandes — cenários em que o Kimi-K2-Thinking mantém a precisão e a lógica enquanto outros modelos se desviam ou cobram valores excessivos.
Como o Kimi-K2-Thinking é diferente do Claude Sonnet 4? O Kimi-K2-Thinking sustenta 200 a 300 chamadas de ferramentas com raciocínio estável e custa aproximadamente 75 a 80 % menos, enquanto o preço do Claude Sonnet 4 aumenta acentuadamente com contextos mais longos e ações frequentes de agentes.
O Kimi-K2-Thinking consegue lidar com tarefas de desenvolvimento full-stack? Sim. O Kimi-K2-Thinking automatiza o processamento de dados, geração de código, depuração e melhoria iterativa dentro do Trae ou da configuração de chamada de ferramentas da Novita AI.
A Novita AI é a plataforma de nuvem tudo-em-um que capacita suas ambições de IA. APIs integradas, serverless, Instâncias de GPU — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece gratuitamente e torne sua visão de IA realidade.
Leituras Recomendadas
Como Acessar o Qwen 3 Coder: Qwen Code; Claude Code; Trae
Como Usar o GLM-4.6 no Cursor para Aumentar a Produtividade de Pequenas Equipes



