

Découvrez comment le prompt en chaîne de pensée (CoT) améliore les modèles de langage à grande échelle (LLM) dans divers domaines, du raisonnement arithmétique au bon sens et au raisonnement symbolique dans notre blog.
Introduction
Les modèles de langage à grande échelle (LLM) ont transformé le paysage de l’intelligence artificielle, offrant des capacités inégalées tant pour la compréhension que pour la génération du langage naturel. Néanmoins, leur maîtrise dans l’exécution de tâches de raisonnement complexes a été un point central de nombreuses recherches. Une approche prometteuse dans ce domaine est le prompt en chaîne de pensée (CoT). Cet article explore les nuances du prompt CoT et ses implications pour la trajectoire future des LLM.
Le prompt CoT, tel que décrit dans un récent article, est une stratégie conçue pour inciter les LLM à expliciter leurs processus de raisonnement. Cela implique de fournir au modèle un ensemble d’exemples où le chemin de raisonnement est explicitement détaillé de manière few-shot. On attend du LLM qu’il imite une trajectoire de raisonnement similaire lorsqu’il répond à l’invite. Cette méthodologie a démontré une amélioration notable de l’efficacité du modèle pour les tâches nécessitant un raisonnement complexe.

Un avantage majeur du prompt CoT réside dans sa capacité à renforcer les performances des LLM dans des tâches impliquant le raisonnement arithmétique, le bon sens et le raisonnement symbolique. La recherche a indiqué des améliorations substantielles des performances, en particulier avec des modèles d’environ 100 milliards de paramètres. À l’inverse, les modèles plus petits ont montré des tendances à générer des chaînes de pensée illogiques, ce qui a entraîné une précision moindre par rapport aux techniques de prompt conventionnelles.
Comprendre le prompt en chaîne de pensée
Essentiellement, le prompt CoT consiste à diriger le LLM pour qu’il pense étape par étape. Cela implique de présenter au modèle un exemple few-shot détaillant le processus de raisonnement. Le modèle est ensuite chargé de suivre une chaîne de pensée comparable lorsqu’il formule sa réponse à l’invite. Une telle méthode s’avère particulièrement efficace pour les tâches complexes exigeant une séquence d’étapes de raisonnement avant de générer une réponse.
Voici un exemple de prompt CoT utilisant une stratégie few-shot :

Voici comment le modèle de langage à grande échelle (fourni par novita.ai) répond :

Le prompt CoT peut également s’étendre à un contexte zero-shot. Dans ce scénario, il s’agit d’ajouter une phrase telle que « Approchons cela étape par étape » à l’invite initiale, ce qui peut compléter le prompt few-shot. Cette inclusion mineure s’est avérée efficace pour améliorer l’efficacité du modèle dans des tâches où l’invite manque d’exemples suffisants.
Le défi du CoT manuel
Malgré les réussites remarquables du CoT manuel, la création manuelle de démonstrations présente des obstacles. Différentes tâches exigent des démonstrations distinctes, et élaborer des démonstrations efficaces peut nécessiter un effort considérable. Pour surmonter ce défi, les chercheurs préconisent une approche de prompt CoT automatisé appelée Auto-CoT. Cette méthode exploite les LLM avec l’invite « Approchons cela étape par étape » pour générer automatiquement des chaînes de raisonnement pour les démonstrations.
Le rôle de la diversité dans Auto-CoT
Un résultat clé de l’étude souligne l’importance de la diversité dans la construction automatisée de démonstrations. Les chercheurs ont observé que les chaînes de raisonnement générées automatiquement contiennent souvent des erreurs. Pour atténuer l’impact de ces erreurs, ils introduisent une technique de prompt CoT automatisé nommée Auto-CoT. Auto-CoT sélectionne des questions aux attributs divers et génère des chaînes de raisonnement pour formuler des démonstrations. En exploitant la diversité, Auto-CoT cherche à améliorer la qualité des démonstrations construites automatiquement.
Avantages du prompt en chaîne de pensée
L’utilisation du prompt en chaîne de pensée (CoT) avec les modèles de langage à grande échelle (LLM) offre de nombreux avantages, favorisant des interactions plus efficaces et efficientes. Voici les principaux bénéfices :
- Précision renforcée : Le prompt CoT guide le modèle à travers une séquence d’invites, augmentant notablement la probabilité d’obtenir des réponses précises et pertinentes. Cette approche structurée affine la compréhension du modèle, ce qui donne des sorties plus exactes.
- Contrôle amélioré : Les chaînes fournissent un cadre structuré pour interagir avec les LLM, donnant aux utilisateurs un plus grand contrôle sur les sorties du modèle. En suivant une séquence d’invites, les utilisateurs peuvent orienter la conversation dans la direction souhaitée, minimisant le risque de résultats non intentionnels ou non pertinents.
- Rétention cohérente du contexte : L’apprentissage adaptatif dans les chaînes assure une préservation cohérente du contexte tout au long de la conversation. Cette rétention de contexte favorise des interactions plus cohérentes et significatives, car le modèle garde une mémoire du dialogue en cours.
- Efficacité : Le prompt CoT rationalise le processus d’interaction, faisant gagner du temps en éliminant la nécessité de multiples entrées. Les utilisateurs peuvent obtenir des résultats spécifiques plus efficacement, en particulier lorsqu’ils visent un résultat précis à partir d’une invite LLM.
- Capacités de raisonnement améliorées : Le prompt CoT encourage les LLM à se concentrer sur la résolution de problèmes une étape à la fois plutôt que de considérer l’ensemble du défi simultanément. Cette approche augmente les capacités de raisonnement des LLM, facilitant un processus de résolution de problèmes plus systématique et pratique.
Types de prompt en chaîne de pensée
Dans le domaine du prompt en chaîne de pensée (CoT), deux stratégies efficaces ont émergé, toutes deux cruciales pour améliorer les interactions avec les modèles de langage à grande échelle (LLM). Explorons maintenant les subtilités de ces méthodes :
CoT multimodal
Le prompt CoT multimodal injecte un élément dynamique dans les interactions textuelles classiques en intégrant divers modes d’entrée, notamment les images, l’audio ou la vidéo.

Les utilisateurs démarrent la chaîne en fournissant une invite multimodale, présentant un contexte plus complexe pour que le LLM interprète et réponde. Les invites de suivi peuvent intégrer davantage de modalités, facilitant une compréhension plus profonde de l’entrée utilisateur. L’inclusion de diverses modalités enrichit le contexte, permettant au modèle de mieux saisir les subtilités de l’intention de l’utilisateur. Les entrées multimodales peuvent susciter des réponses plus imaginatives de la part du LLM, élargissant le champ de génération de contenu varié et contextuellement pertinent.
Si vous souhaitez en savoir plus sur les modèles de langage multimodaux, vous pouvez consulter notre blog : Large Multimodal Models(LMMs): A Gigantic Leap in AI World
Prompt du moins au plus
Le prompt du moins au plus est une stratégie qui commence la chaîne avec une invite minimaliste et augmente progressivement la complexité dans les invites suivantes. L’interaction commence par une invite basique et large, permettant au modèle de fournir une réponse initiale. Au fur et à mesure que la chaîne se déroule, les utilisateurs peuvent progressivement introduire plus de détails, de spécifications ou de subtilités, orientant le modèle vers une sortie plus nuancée et précise. Cette approche incrémentale facilite une amélioration progressive de la compréhension du modèle, atténuant le risque d’interprétations erronées au début de l’interaction.
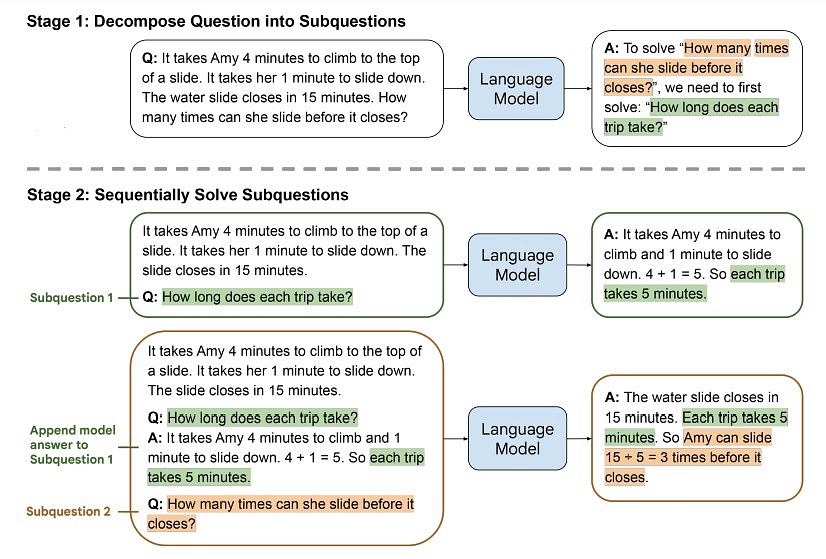
Le prompt du moins au plus permet aux utilisateurs d’ajuster la complexité de la tâche en fonction de la réponse initiale du modèle, garantissant une interaction plus personnalisée et pragmatique.
Implémentation d’Auto-CoT
Auto-CoT comporte deux étapes principales :
- Segmenter les questions d’un ensemble de données fourni en huit clusters — sentence-BERT est utilisé pour encoder les questions, après quoi les clusters sont établis en fonction de la similarité cosinus.
- Choisir une question représentative dans chaque cluster et élaborer sa chaîne de raisonnement en utilisant Zero-Shot-CoT avec des heuristiques simples — ces heuristiques consistent à éviter de sélectionner des questions dépassant 60 tokens ou des chaînes de raisonnement comprenant plus de cinq étapes. Ces heuristiques sont conçues pour augmenter la probabilité que la réponse générée automatiquement soit correcte.

Applications du prompt en chaîne de pensée
Le prompt en chaîne de pensée (CoT) trouve des applications dans divers domaines, soulignant sa polyvalence pour améliorer les capacités des modèles de langage à grande échelle (LLM). Voici plusieurs applications notables accompagnées d’exemples :

Raisonnement arithmétique
La difficulté à résoudre des problèmes de mathématiques avec des mots est bien connue pour les modèles de langage. En s’intégrant à un modèle de langage de 540 milliards de paramètres, le prompt CoT atteint des performances comparables ou supérieures sur des benchmarks comme MultiArith et GSM8K. Avec le CoT, le modèle traite efficacement les tâches de raisonnement arithmétique, excellant particulièrement avec des tailles de modèle plus grandes. Cette application souligne la capacité du CoT à améliorer les capacités de résolution de problèmes mathématiques.
Raisonnement de bon sens
L’impact du CoT sur l’amélioration des capacités de raisonnement des modèles de langage dans le domaine du bon sens est évident dans cette application. Les tâches de raisonnement de bon sens, qui impliquent la compréhension des interactions physiques et humaines basée sur des connaissances générales, peuvent être difficiles pour les systèmes de compréhension du langage naturel. Le prompt CoT s’avère efficace dans des tâches telles que CommonsenseQA, StrategyQA, la compréhension des dates et la compréhension sportive. Bien que la taille du modèle influence généralement les performances, le CoT apporte des améliorations supplémentaires, bénéficiant notamment aux tâches de compréhension sportive.
Raisonnement symbolique
Les tâches de raisonnement symbolique présentent souvent des obstacles pour les modèles de langage, en particulier avec les méthodes de prompt standard. Cependant, le prompt CoT permet aux LLM de s’attaquer à des tâches comme la concaténation de la dernière lettre et les lancers de pièces avec des taux de résolution impressionnants. Il facilite le raisonnement symbolique et aide à la généralisation de longueur, permettant aux modèles de traiter des entrées plus longues lors de l’inférence. Cette application met en évidence le potentiel significatif du CoT pour améliorer la capacité d’un modèle à exécuter des tâches de raisonnement symbolique complexes.
Réponse aux questions (QA)
Le prompt CoT améliore la réponse aux questions (QA) en décomposant les questions complexes en étapes logiques. Cette méthodologie aide le modèle à comprendre la structure de la question et les interconnexions entre ses éléments. Le CoT favorise un raisonnement multi-sauts, où le modèle rassemble et intègre itérativement des informations provenant de diverses sources. Ce processus itératif conduit à une meilleure inference et à des réponses plus précises. En détaillant les étapes de raisonnement, le CoT atténue également les erreurs et biais courants dans les réponses. L’application du CoT dans la QA souligne son efficacité à déconstruire des problèmes complexes, favorisant ainsi un meilleur raisonnement et une meilleure compréhension dans les modèles de langage.
Limites et orientations futures
Bien que le prompt CoT soit prometteur, il ne manque pas d’inconvénients. Principalement, il n’améliore les performances qu’avec des modèles d’environ 100 milliards de paramètres. À l’inverse, les modèles plus petits génèrent souvent des chaînes de pensée irrationnelles, ce qui entraîne une précision moindre par rapport aux méthodes de prompt conventionnelles. De plus, les gains d’efficacité du prompt CoT sont généralement corrélés à la taille du modèle.
Malgré ces limitations, le prompt CoT marque une avancée notable dans l’augmentation de l’aptitude au raisonnement des LLM. Les recherches futures se concentreront probablement sur l’affinement de cette approche et l’exploration de voies pour renforcer son efficacité dans diverses tâches et dimensions de modèles.
Conclusion
Le prompt en chaîne de pensée (CoT) constitue une avancée significative dans le domaine de l’intelligence artificielle, en particulier pour augmenter les capacités de raisonnement des modèles de langage à grande échelle (LLM). En incitant ces modèles à expliciter leur processus de raisonnement, le CoT a démontré son potentiel pour améliorer les performances dans des tâches complexes nécessitant un raisonnement arithmétique, de bon sens et symbolique. Malgré ses limites, le CoT laisse entrevoir des perspectives prometteuses pour l’évolution future des LLM.
Alors que nous repoussons les limites des capacités des LLM, des techniques comme le prompt CoT s’avéreront indispensables. En favorisant une approche de pensée étape par étape et en encourageant l’explicitation du raisonnement, nous améliorons non seulement les performances du modèle sur des tâches complexes, mais nous obtenons également des informations précieuses sur leurs mécanismes internes. Bien que la route vers des LLM pleinement raisonnants soit encore longue, des méthodologies comme le prompt CoT nous mettent sans aucun doute sur la bonne voie.
novita.ai, la plateforme tout-en-un pour une créativité sans limites qui vous donne accès à plus de 100 API. De la génération d’images au traitement du langage, en passant par l’amélioration audio et la manipulation vidéo, avec un paiement à l’utilisation avantageux, elle vous libère des tracas de la maintenance GPU tout en construisant vos propres produits. Essayez-le gratuitement.
Lectures recommandées
Moteur d’inférence LLM Novita AI : le plus grand débit et l’inférence la moins chère disponible



