

Узнайте, как промптинг с цепочкой рассуждений (Chain-of-Thought, CoT) улучшает большие языковые модели (LLM) в различных областях — от арифметических рассуждений до здравого смысла и символьных рассуждений.
Введение
Большие языковые модели (LLM) изменили ландшафт искусственного интеллекта, предоставив непревзойденные возможности в понимании и генерации естественного языка. Тем не менее, их способность выполнять сложные задачи рассуждения остается предметом активных исследований. Одним из перспективных подходов в этой области является промптинг с цепочкой рассуждений (Chain-of-Thought, CoT). В этой статье мы рассмотрим нюансы CoT-промптинга и его значение для будущего развития LLM.
CoT-промптинг, как описано в недавней статье, представляет собой стратегию, направленную на то, чтобы побудить LLM объяснять свои рассуждения. Это включает предоставление модели набора примеров, в которых путь рассуждений явно расписан в формате few-shot. Ожидается, что LLM будет имитировать аналогичную траекторию рассуждений при ответе на запрос. Этот метод показал заметное повышение эффективности модели для задач, требующих сложных рассуждений.

Основное преимущество CoT-промптинга заключается в его способности повышать производительность LLM в задачах, связанных с арифметическими, здравым смыслом и символьными рассуждениями. Исследования показали существенное улучшение производительности, особенно для моделей, содержащих около 100 миллиардов параметров. Напротив, меньшие модели склонны генерировать нелогичные цепочки рассуждений, что приводит к снижению точности по сравнению с традиционными методами промптинга.
Понимание промптинга с цепочкой рассуждений
По сути, CoT-промптинг заключается в том, чтобы направить LLM на пошаговое мышление. Это предполагает представление модели примера в формате few-shot, в котором описан процесс рассуждений. Затем модели поручается следовать аналогичной цепочке рассуждений при формулировании ответа на запрос. Такой метод особенно эффективен для сложных задач, требующих последовательности шагов рассуждения перед генерацией ответа.
Вот пример CoT-промпта с использованием стратегии few-shot:

Вот как отвечает большая языковая модель (предоставленная novita.ai):

CoT-промптинг может быть расширен и на контекст zero-shot. В этом случае он включает добавление фразы вроде «Давайте подойдем к этому шаг за шагом» к исходному запросу, что может дополнить few-shot-промптинг. Это небольшое дополнение оказалось эффективным для повышения производительности модели в задачах, где в запросе не хватает примеров.
Проблема ручного CoT (Manual-CoT)
Несмотря на выдающиеся достижения Manual-CoT, ручное создание демонстраций представляет собой препятствие. Разные задачи требуют разных демонстраций, и создание эффективных может потребовать значительных усилий. Чтобы преодолеть эту проблему, исследователи предлагают автоматизированный подход к CoT-промптингу, известный как Auto-CoT. Этот метод использует LLM с запросом «Давайте подойдем к этому шаг за шагом» для автоматической генерации цепочек рассуждений для демонстраций.
Роль разнообразия в Auto-CoT
Ключевой вывод исследования подчеркивает важность разнообразия при автоматическом построении демонстраций. Исследователи заметили, что автоматически сгенерированные цепочки рассуждений часто содержат ошибки. Чтобы смягчить влияние этих ошибок, они представляют автоматизированную технику CoT-промптинга под названием Auto-CoT. Auto-CoT выбирает вопросы с различными атрибутами и генерирует цепочки рассуждений для составления демонстраций. За счет использования разнообразия Auto-CoT стремится повысить качество автоматически построенных демонстраций.
Преимущества промптинга с цепочкой рассуждений
Использование промптинга с цепочкой рассуждений (CoT) с большими языковыми моделями (LLM) дает множество преимуществ, способствуя более эффективному и результативному взаимодействию. Вот основные преимущества:
- Повышенная точность: CoT-промптинг направляет модель через последовательность запросов, значительно увеличивая вероятность получения точных и релевантных ответов. Такой структурированный подход помогает уточнить понимание модели, что приводит к более точным результатам.
- Улучшенный контроль: Цепочки обеспечивают структурированную основу для взаимодействия с LLM, предоставляя пользователям больший контроль над выходами модели. Следуя последовательности запросов, пользователи могут направить разговор в нужное русло, сводя к минимуму риск нежелательных или нерелевантных результатов.
- Согласованное сохранение контекста: Адаптивное обучение в рамках цепочек обеспечивает последовательное сохранение контекста на протяжении всего разговора. Такое сохранение контекста способствует более связному и осмысленному взаимодействию, поскольку модель сохраняет память о текущем диалоге.
- Эффективность: CoT-промптинг оптимизирует процесс взаимодействия, экономя время за счет устранения необходимости в многократных вводах. Пользователи могут более эффективно достигать конкретных результатов, особенно когда требуется определенный результат от LLM-запроса.
- Расширенные способности к рассуждению: CoT-промптинг побуждает LLM решать задачи по одному шагу за раз, а не рассматривать всю задачу целиком. Этот подход усиливает способности LLM к рассуждению, способствуя более систематическому и практичному процессу решения проблем.
Типы промптинга с цепочкой рассуждений
В области промптинга с цепочкой рассуждений (CoT) выделяются две эффективные стратегии, обе из которых имеют решающее значение для улучшения взаимодействия с большими языковыми моделями (LLM). Давайте рассмотрим особенности этих методов:
Мультимодальный CoT
Мультимодальный CoT-промптинг вносит динамический элемент в традиционные текстовые взаимодействия, интегрируя различные входные моды, включая изображения, аудио или видео.

Пользователи запускают цепочку, предоставляя мультимодальный запрос, представляя более сложный контекст для интерпретации и обработки LLM. Последующие запросы могут дополнительно включать различные модальности, способствуя более глубокому пониманию ввода пользователя. Включение разнообразных модальностей улучшает контекст, позволяя модели лучше улавливать нюансы намерений пользователя. Мультимодальные вводы могут вызывать более творческие ответы от LLM, расширяя возможности для генерации разнообразного и контекстуально релевантного контента.
Если вы хотите узнать больше о мультимодальных языковых моделях, вы можете ознакомиться с нашим блогом: Large Multimodal Models(LMMs): A Gigantic Leap in AI World
Промптинг от простого к сложному (Least-to-Most Prompting)
Промптинг от простого к сложному — это стратегия, которая начинает цепочку с минималистичного запроса и постепенно увеличивает сложность в последующих запросах. Взаимодействие начинается с базового и широкого запроса, позволяя модели предоставить первоначальный ответ. По мере развития цепочки пользователи могут постепенно вводить больше деталей, спецификаций или тонкостей, направляя модель к более нюансированному и точному результату. Такой инкрементальный подход способствует постепенному улучшению понимания модели, снижая риск неверных интерпретаций в начале взаимодействия.
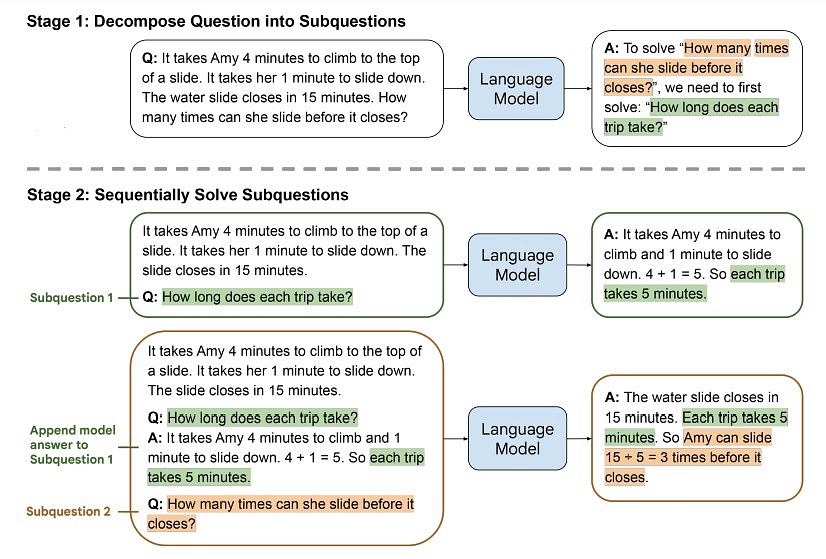
Промптинг от простого к сложному позволяет пользователям регулировать сложность задачи на основе первоначального ответа модели, обеспечивая более персонализированное и прагматичное взаимодействие.
Реализация Auto-CoT
Auto-CoT включает два основных шага:
- Сегментирование вопросов из предоставленного набора данных на восемь кластеров — sentence-BERT используется для кодирования вопросов, после чего кластеры устанавливаются на основе косинусного сходства.
- Выбор репрезентативного вопроса из каждого кластера и создание его цепочки рассуждений с помощью Zero-Shot-CoT вместе с простыми эвристиками — эти эвристики включают отказ от выбора вопросов длиной более 60 токенов или цепочек рассуждений, содержащих более пяти шагов. Эти эвристики разработаны для повышения вероятности того, что автоматически сгенерированный ответ будет точным.

Применение промптинга с цепочкой рассуждений
Промптинг с цепочкой рассуждений (CoT) находит применение в различных областях, подчеркивая свою универсальность в расширении возможностей больших языковых моделей (LLM). Вот несколько заметных приложений вместе с примерами:

Арифметические рассуждения
Языковым моделям хорошо известна сложность решения текстовых математических задач. Интегрируясь с языковой моделью на 540 миллиардов параметров, CoT-промптинг достигает сравнимой или превосходной производительности на таких эталонах, как MultiArith и GSM8K. С CoT модель эффективно решает задачи арифметических рассуждений, особенно хорошо проявляя себя с большими размерами моделей. Это приложение подчеркивает способность CoT улучшать способности решения математических задач.
Рассуждения на основе здравого смысла
Влияние CoT на улучшение способностей языковых моделей к рассуждению в области здравого смысла очевидно в этом приложении. Задачи рассуждения на основе здравого смысла, которые включают понимание физических и человеческих взаимодействий на основе общих знаний, могут быть сложными для систем понимания естественного языка. CoT-промптинг оказывается эффективным в таких задачах, как CommonsenseQA, StrategyQA, понимание дат и понимание спорта. Хотя размер модели обычно влияет на производительность, CoT вносит дополнительные улучшения, особенно заметно помогая в задачах понимания спорта.
Символьные рассуждения
Задачи символьных рассуждений часто создают препятствия для языковых моделей, особенно при стандартных методах промптинга. Однако CoT-промптинг позволяет LLM решать такие задачи, как конкатенация последних букв и подбрасывание монет, с впечатляющими показателями успешности. Он облегчает символьные рассуждения и помогает в обобщении длины, позволяя моделям обрабатывать более длинные входные данные во время вывода. Это приложение подчеркивает значительный потенциал CoT в улучшении способности модели выполнять сложные задачи символьных рассуждений.
Ответы на вопросы (QA)
CoT-промптинг улучшает ответы на вопросы (QA), разбивая сложные вопросы на логические шаги. Эта методология помогает модели понять структуру вопроса и взаимосвязи между его элементами. CoT способствует многошаговым рассуждениям, при которых модель итеративно собирает и интегрирует информацию из различных источников. Этот итеративный процесс приводит к улучшению вывода и более точным ответам. Описывая шаги рассуждения, CoT также смягчает распространенные ошибки и предвзятости в ответах. Применение CoT в QA подчеркивает его эффективность в декомпозиции сложных проблем, тем самым способствуя улучшению рассуждений и понимания в языковых моделях.
Ограничения и будущие направления
Хотя CoT-промптинг многообещающ, он не лишен недостатков. Прежде всего, улучшение производительности наблюдается только у моделей, содержащих около 100 миллиардов параметров. Напротив, меньшие модели часто генерируют иррациональные цепочки рассуждений, что приводит к снижению точности по сравнению с традиционными методами промптинга. Кроме того, выигрыш в эффективности от CoT-промптинга обычно коррелирует с размером модели.
Несмотря на эти ограничения, CoT-промптинг знаменует собой заметный прогресс в повышении способности LLM к рассуждению. Последующие исследования, вероятно, будут сосредоточены на оттачивании этого подхода и изучении путей повышения его эффективности для различных задач и размеров моделей.
Заключение
Промптинг с цепочкой рассуждений (Chain-of-Thought, CoT) представляет собой значительный прорыв в области искусственного интеллекта, особенно в улучшении способностей больших языковых моделей (LLM) к рассуждению. Побуждая эти модели объяснять свой процесс рассуждения, CoT продемонстрировал потенциал для повышения производительности в сложных задачах, требующих арифметических, основанных на здравом смысле и символьных рассуждений. Несмотря на свои ограничения, CoT открывает многообещающие перспективы для будущей эволюции LLM.
По мере того как мы расширяем границы возможностей LLM, такие техники, как CoT-промптинг, окажутся незаменимыми. Поощряя пошаговое мышление и стимулируя объяснение рассуждений, мы не только улучшаем производительность модели на сложных задачах, но и получаем бесценные знания о их внутренних механизмах. Хотя путь к полностью рассуждающим LLM еще долог, такие методологии, как CoT-промптинг, несомненно, ставят нас на правильную траекторию.
novita.ai — единая платформа для безграничного творчества, предоставляющая доступ к 100+ API. От генерации изображений и обработки языка до улучшения аудио и манипуляции видео, недорогая оплата по факту использования, она освобождает вас от обслуживания GPU при построении собственных продуктов. Попробуйте бесплатно.
Рекомендуемое чтение
Novita AI LLM Inference Engine: the largest throughput and cheapest inference available



