

Erfahren Sie, wie Chain-of-Thought (CoT) Prompting große Sprachmodelle (LLMs) in verschiedenen Bereichen verbessert – von arithmetischem Denken über gesunden Menschenverstand bis hin zu symbolischem Denken – in unserem Blog.
Einführung
Große Sprachmodelle (Large Language Models, LLMs) haben die Landschaft der künstlichen Intelligenz verändert und bieten beispiellose Fähigkeiten sowohl beim Verstehen als auch beim Generieren natürlicher Sprache. Dennoch war ihre Fähigkeit, komplexe Denkaufgaben auszuführen, ein Schwerpunkt umfangreicher Untersuchungen. Ein vielversprechender Ansatz in diesem Bereich ist das Chain-of-Thought (CoT) Prompting. Dieser Artikel befasst sich mit den Nuancen des CoT-Promptings und seinen Auswirkungen auf die zukünftige Entwicklung von LLMs.
CoT-Prompting, wie es in einem kürzlich erschienenen Artikel beschrieben wird, ist eine Strategie, die darauf abzielt, LLMs dazu zu bringen, ihre Denkprozesse zu erläutern. Dazu wird dem Modell eine Reihe von Beispielen bereitgestellt, in denen der Denkweg explizit in einer Few-Shot-Manier dargestellt wird. Es wird erwartet, dass das LLM einen ähnlichen Denkweg nachahmt, wenn es auf den Prompt antwortet. Diese Methodik hat eine bemerkenswerte Verbesserung der Wirksamkeit des Modells bei Aufgaben, die komplexes Denken erfordern, gezeigt.

Ein Hauptvorteil des CoT-Promptings liegt in seiner Fähigkeit, die Leistung von LLMs bei Aufgaben zu steigern, die arithmetisches, alltägliches und symbolisches Denken erfordern. Die Forschung hat insbesondere bei Modellen mit etwa 100 Milliarden Parametern erhebliche Leistungssteigerungen gezeigt. Kleinere Modelle hingegen neigten dazu, unlogische Gedankenketten zu generieren, was zu einer geringeren Genauigkeit im Vergleich zu herkömmlichen Prompting-Techniken führte.
Chain-of-Thought Prompting verstehen
Im Kern geht es beim CoT-Prompting darum, das LLM zu schrittweisem Denken anzuleiten. Dazu wird dem Modell ein Few-Shot-Beispiel präsentiert, das den Denkprozess beschreibt. Das Modell wird dann aufgefordert, einer vergleichbaren Gedankenkette zu folgen, wenn es seine Antwort auf den Prompt formuliert. Eine solche Methode erweist sich als besonders wirksam für komplexe Aufgaben, die vor der Generierung einer Antwort eine Reihe von Denkschritten erfordern.
Hier ist ein Beispiel für einen CoT-Prompt mit einer Few-Shot-Strategie:

So antwortet das große Sprachmodell (bereitgestellt von novita.ai):

CoT-Prompting kann auch auf einen Zero-Shot-Kontext ausgeweitet werden. In diesem Szenario wird dem anfänglichen Prompt ein Satz wie „Gehen wir das Schritt für Schritt an“ hinzugefügt, was das Few-Shot-Prompting ergänzen kann. Diese kleine Ergänzung hat sich als wirksam erwiesen, um die Effektivität des Modells bei Aufgaben zu verbessern, bei denen der Prompt nicht genügend Beispiele bietet, aus denen er schöpfen kann.
Die Herausforderung von Manual-CoT
Trotz der bemerkenswerten Erfolge von Manual-CoT stellt die manuelle Erstellung von Demonstrationen ein Hindernis dar. Verschiedene Aufgaben erfordern unterschiedliche Demonstrationen, und die Erstellung effektiver Beispiele kann einen erheblichen Aufwand bedeuten. Um diese Herausforderung zu bewältigen, befürworten Forscher einen automatisierten CoT-Prompting-Ansatz namens Auto-CoT. Diese Methode nutzt LLMs mit dem Prompt „Gehen wir das Schritt für Schritt an“, um automatisch Reasoning-Ketten für Demonstrationen zu generieren.
Die Rolle der Diversität in Auto-CoT
Eine zentrale Erkenntnis aus der Studie unterstreicht die Bedeutung der Diversität bei der automatisierten Erstellung von Demonstrationen. Die Forscher beobachteten, dass automatisch generierte Reasoning-Ketten häufig Fehler enthalten. Um die Auswirkungen dieser Fehler zu mildern, führen sie eine automatisierte CoT-Prompting-Technik namens Auto-CoT ein. Auto-CoT wählt Fragen mit unterschiedlichen Attributen aus und generiert Reasoning-Ketten, um Demonstrationen zu formulieren. Durch die Nutzung von Diversität soll Auto-CoT die Qualität automatisch erstellter Demonstrationen verbessern.
Vorteile des Chain-of-Thought Promptings
Die Verwendung von Chain-of-Thought (CoT) Prompting mit großen Sprachmodellen (LLMs) bietet zahlreiche Vorteile und fördert effektivere und effizientere Interaktionen. Hier sind die wichtigsten Vorteile:
- Verbesserte Präzision: CoT-Prompting führt das Modell durch eine Abfolge von Prompts und erhöht die Wahrscheinlichkeit, genaue und relevante Antworten zu erhalten, deutlich. Dieser strukturierte Ansatz hilft, das Verständnis des Modells zu verfeinern, was zu präziseren Ausgaben führt.
- Verbesserte Kontrolle: Ketten bieten einen strukturierten Rahmen für die Interaktion mit LLMs und geben Benutzern mehr Kontrolle über die Ausgaben des Modells. Durch das Befolgen einer Sequenz von Prompts können Benutzer das Gespräch in die gewünschte Richtung lenken und das Risiko unbeabsichtigter oder irrelevanter Ergebnisse minimieren.
- Konsistente Kontexterhaltung: Adaptives Lernen innerhalb der Ketten stellt sicher, dass der Kontext während des gesamten Gesprächs konsistent erhalten bleibt. Diese Kontexterhaltung fördert kohärentere und sinnvollere Interaktionen, da das Modell eine Erinnerung an den laufenden Dialog bewahrt.
- Effizienz: CoT-Prompting optimiert den Interaktionsprozess und spart Zeit, da mehrere Eingaben überflüssig werden. Benutzer können bestimmte Ergebnisse effizienter erzielen, insbesondere wenn sie ein bestimmtes Ergebnis von einem LLM-Prompt anstreben.
- Verbesserte Reasoning-Fähigkeiten: CoT-Prompting ermutigt LLMs, sich darauf zu konzentrieren, Probleme Schritt für Schritt zu lösen, anstatt die gesamte Herausforderung gleichzeitig zu betrachten. Dieser Ansatz verbessert die Reasoning-Fähigkeiten von LLMs und erleichtert einen systematischeren und praktischeren Problemlösungsprozess.
Arten von Chain-of-Thought Prompting
Im Bereich des Chain-of-Thought (CoT) Promptings haben sich zwei effektive Strategien herausgebildet, die beide für die Verbesserung der Interaktion mit großen Sprachmodellen (LLMs) entscheidend sind. Lassen Sie uns nun die Feinheiten dieser Methoden erkunden:
Multimodales CoT
Multimodales CoT-Prompting bringt ein dynamisches Element in herkömmliche textbasierte Interaktionen, indem es verschiedene Eingabemodi wie Bilder, Audio oder Video integriert.

Benutzer starten die Kette, indem sie einen multimodalen Prompt bereitstellen, der einen komplexeren Kontext für das LLM schafft, den es interpretieren und adressieren kann. Folge-Prompts können weitere Modalitäten einbeziehen, was ein tieferes Verständnis der Benutzereingabe ermöglicht. Die Einbeziehung verschiedener Modalitäten verbessert den Kontext und befähigt das Modell, die Nuancen der Benutzerabsicht besser zu erfassen. Multimodale Eingaben können kreativere Antworten des LLM hervorrufen und den Spielraum für die Generierung vielfältiger und kontextuell relevanter Inhalte erweitern.
Wenn Sie mehr über multimodale Sprachmodelle erfahren möchten, lesen Sie unseren Blog: Large Multimodal Models (LMMs): Ein gigantischer Sprung in der KI-Welt
Least-to-Most Prompting
Least-to-Most Prompting ist eine Strategie, die die Kette mit einem minimalistischen Prompt beginnt und die Komplexität in nachfolgenden Prompts schrittweise erhöht. Die Interaktion beginnt mit einem einfachen und breiten Prompt, der es dem Modell ermöglicht, eine erste Antwort zu geben. Im Verlauf der Kette können Benutzer nach und nach mehr Details, Spezifikationen oder Feinheiten einführen und das Modell so zu einer differenzierteren und präziseren Ausgabe führen. Dieser inkrementelle Ansatz ermöglicht eine schrittweise Verbesserung des Modellverständnisses und verringert das Risiko von Fehlinterpretationen zu Beginn der Interaktion.
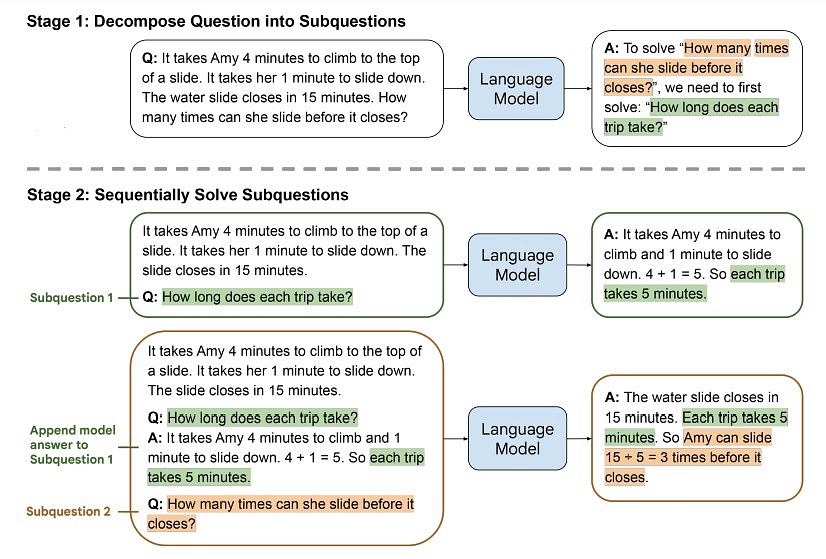
Least-to-Most Prompting ermöglicht es Benutzern, die Komplexität der Aufgabe basierend auf der ersten Antwort des Modells anzupassen, was eine persönlichere und pragmatischere Interaktion gewährleistet.
Auto-CoT-Implementierung
Auto-CoT umfasst zwei Hauptschritte:
- Aufteilen von Fragen aus einem bereitgestellten Datensatz in acht Cluster – Sentence-BERT wird verwendet, um die Fragen zu codieren, wonach Cluster auf der Grundlage der Kosinusähnlichkeit gebildet werden.
- Auswählen einer repräsentativen Frage aus jedem Cluster und Erstellen ihrer Reasoning-Kette unter Verwendung von Zero-Shot-CoT zusammen mit einfachen Heuristiken – diese Heuristiken beinhalten, keine Fragen auszuwählen, die 60 Token überschreiten, oder Reasoning-Ketten, die mehr als fünf Schritte umfassen. Diese Heuristiken sollen die Wahrscheinlichkeit erhöhen, dass die automatisch generierte Antwort korrekt ist.

Anwendungen des Chain-of-Thought Promptings
Chain-of-Thought (CoT) Prompting findet Anwendung in verschiedenen Bereichen, was seine Vielseitigkeit bei der Erweiterung der Fähigkeiten großer Sprachmodelle (LLMs) unterstreicht. Hier sind mehrere bemerkenswerte Anwendungen zusammen mit Beispielen:

Arithmetisches Denken
Die Schwierigkeit, mathematische Textaufgaben für Sprachmodelle zu lösen, ist bekannt. Durch die Integration mit einem 540-Milliarden-Parameter-Sprachmodell erreicht CoT-Prompting eine vergleichbare oder überlegene Leistung bei Benchmarks wie MultiArith und GSM8K. Mit CoT bewältigt das Modell effektiv arithmetische Denkaufgaben, insbesondere bei größeren Modellgrößen. Diese Anwendung unterstreicht die Fähigkeit von CoT, die mathematischen Problemlösungsfähigkeiten zu verbessern.
Denken mit gesundem Menschenverstand
Die Auswirkung von CoT auf die Verbesserung der Reasoning-Fähigkeiten von Sprachmodellen im Bereich des gesunden Menschenverstands zeigt sich in dieser Anwendung. Aufgaben zum Denken mit gesundem Menschenverstand, die das Erfassen physikalischer und menschlicher Interaktionen auf der Grundlage von Allgemeinwissen beinhalten, können für Systeme zum Verständnis natürlicher Sprache eine Herausforderung darstellen. CoT-Prompting erweist sich als wirksam bei Aufgaben wie CommonsenseQA, StrategyQA, Datumsverständnis und Sportverständnis. Während die Modellgröße typischerweise die Leistung beeinflusst, führt CoT zusätzliche Verbesserungen ein, die insbesondere Aufgaben zum Sportverständnis zugutekommen.
Symbolisches Denken
Symbolische Denkaufgaben stellen Sprachmodelle oft vor Hürden, insbesondere mit Standard-Prompting-Methoden. CoT-Prompting befähigt LLMs jedoch, Aufgaben wie die Verkettung des letzten Buchstabens und Münzwürfe mit beeindruckenden Lösungsraten zu bewältigen. Es erleichtert symbolisches Denken und hilft bei der Längengeneralisierung, sodass Modelle längere Eingaben während der Inferenz verarbeiten können. Diese Anwendung hebt das bedeutende Potenzial von CoT hervor, die Fähigkeit eines Modells zur Ausführung komplexer symbolischer Denkaufgaben zu verbessern.
Fragebeantwortung (QA)
CoT-Prompting verbessert die Fragebeantwortung (Question Answering, QA), indem komplexe Fragen in logische Schritte zerlegt werden. Diese Methodik hilft dem Modell, die Struktur der Frage und die Zusammenhänge zwischen ihren Elementen zu verstehen. CoT fördert Multi-Hop-Reasoning, bei dem das Modell iterativ Informationen aus verschiedenen Quellen sammelt und integriert. Dieser iterative Prozess führt zu verbesserten Schlussfolgerungen und genaueren Antworten. Durch die Darstellung von Denkschritten mildert CoT auch häufige Fehler und Verzerrungen in Antworten. Die Anwendung von CoT in der QA unterstreicht seine Wirksamkeit bei der Dekonstruktion komplexer Probleme und fördert so ein besseres Denken und Verständnis in Sprachmodellen.
Einschränkungen und zukünftige Richtungen
Obwohl CoT-Prompting vielversprechend ist, ist es nicht frei von Nachteilen. In erster Linie zeigt es Leistungssteigerungen nur bei Modellen mit etwa 100 Milliarden Parametern. Kleinere Modelle generieren dagegen oft irrationale Gedankenketten, was im Vergleich zu herkömmlichen Prompting-Methoden zu einer geringeren Genauigkeit führt. Darüber hinaus korrelieren die Wirksamkeitsgewinne durch CoT-Prompting typischerweise mit der Größe des Modells.
Trotz dieser Einschränkungen stellt CoT-Prompting einen bemerkenswerten Fortschritt bei der Steigerung der Reasoning-Fähigkeit von LLMs dar. Nachfolgende Forschungsbemühungen werden sich wahrscheinlich auf die Verfeinerung dieses Ansatzes konzentrieren und Wege erkunden, seine Wirksamkeit bei verschiedenen Aufgaben und Modellgrößen zu steigern.
Schlussfolgerung
Chain-of-Thought (CoT) Prompting ist ein bedeutender Durchbruch im Bereich der künstlichen Intelligenz, insbesondere bei der Verbesserung der Reasoning-Fähigkeiten großer Sprachmodelle (LLMs). Indem diese Modelle aufgefordert werden, ihren Denkprozess zu erläutern, hat CoT Potenzial gezeigt, die Leistung bei komplexen Aufgaben zu verbessern, die arithmetisches, alltägliches und symbolisches Denken erfordern. Trotz seiner Einschränkungen verheißt CoT vielversprechende Perspektiven für die zukünftige Entwicklung von LLMs.
Während wir die Grenzen der LLM-Fähigkeiten erweitern, werden Techniken wie CoT-Prompting unverzichtbar sein. Indem wir einen schrittweisen Denkansatz fördern und die Erläuterung von Denkprozessen ermutigen, verbessern wir nicht nur die Modellleistung bei komplexen Aufgaben, sondern gewinnen auch wertvolle Einblicke in ihre inneren Mechanismen. Obwohl der Weg zu vollständig denkenden LLMs noch lang ist, setzen Methoden wie CoT-Prompting uns zweifellos auf die richtige Spur.
novita.ai – die Komplettlösung für unbegrenzte Kreativität, die Ihnen Zugang zu über 100 APIs bietet. Von Bildgenerierung und Sprachverarbeitung bis hin zur Audioverbesserung und Videobearbeitung – günstig, nutzungsabhängig bezahlt, befreit es Sie von GPU-Wartungsproblemen, während Sie Ihre eigenen Produkte entwickeln. Testen Sie es kostenlos.
Empfohlene Lektüre
Novita AI LLM Inference Engine: der größte Durchsatz und die günstigste Inferenz verfügbar



