

Points clés
Apprentissage par renforcement (RL) : Utilise un processus RL en deux étapes pour affiner le raisonnement par essais et erreurs, vérifié par des outils comme les interpréteurs de code et les solveurs, garantissant des résultats précis.
Benchmarks compétitifs : Obtient des scores élevés dans les tâches de raisonnement et de codage :
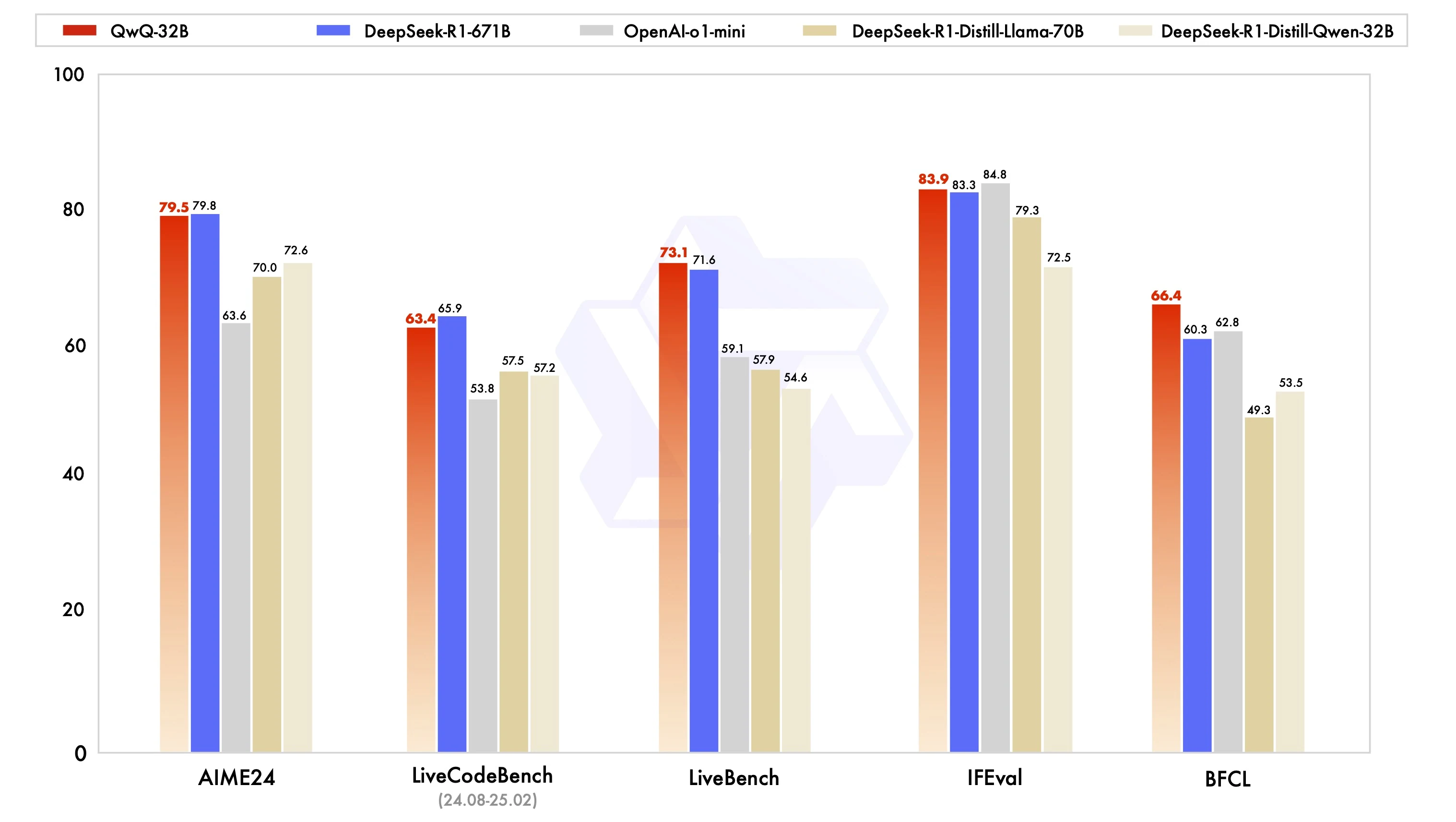
AIME24 : 79,5 (proche de DeepSeek R1 à 79,8).
IFEval : 83,9 (légèrement au-dessus de DeepSeek R1).
BFCL : 66,4 (surpasse DeepSeek R1 à 60,3).
Efficacité matérielle : Nécessite nettement moins de VRAM que DeepSeek R1 ; prend en charge la quantification pour fonctionner sur des configurations matérielles plus petites.
Si vous souhaitez évaluer QwQ 32B pour vos propres cas d’usage — lors de l’inscription, Novita AI offre un crédit de 0,5 $ pour commencer !
QwQ-32B, développé par l’équipe Qwen d’Alibaba, est un modèle de raisonnement de 32,5 milliards de paramètres qui offre des performances comparables à des modèles beaucoup plus grands comme DeepSeek-R1, tout en utilisant nettement moins de paramètres. Son efficacité et ses solides capacités de raisonnement en font un choix idéal pour les chercheurs, développeurs et organisations recherchant des performances élevées sans les exigences lourdes en ressources des grands modèles de langage (LLM) traditionnels.
Qu’est-ce que QwQ-32B ?
Introduction de base
- qwen/qwq-32b
- Open Source : Disponible sous licence Apache 2.0, permettant les contributions et améliorations de la communauté.
- Transformers : QwQ-32B utilise une architecture transformer avec 64 couches, 40 têtes d’attention pour les requêtes et 8 pour les clés-valeurs. Construit sur des transformers avec RoPE (Positional Embeddings rotatifs), QwQ-32B intègre la fonction d’activation SwiGLU, utilise RMSNorm pour la normalisation et inclut un biais dans les calculs QKV de l’attention.
- Paramètres : Un total de 32,5 milliards de paramètres, dont 31,0 milliards de paramètres non liés aux embeddings.
- Support de contexte long : Prend en charge jusqu’à 32 768 tokens.
- Langues prises en charge : Couvre plus de 29 langues pour une accessibilité et une application mondiales.
Méthodes d’entraînement
S’appuyant sur Qwen2.5, QwQ-32B optimise spécifiquement les tâches de raisonnement via le RL, montrant une innovation potentielle en éliminant la dépendance aux méthodes traditionnelles de fine-tuning supervisé (SFT).
De plus, QwQ-32B utilise l’apprentissage par renforcement (RL) pour affiner ses capacités de raisonnement, en s’appuyant sur les essais et erreurs pour adapter son approche en utilisant des outils et des retours d’environnement. En employant un mécanisme de « récompenses basées sur les résultats », le modèle génère des résultats de manière indépendante, qui sont ensuite vérifiés pour leur exactitude, garantissant des performances fiables dans les tâches structurées. Cette rupture avec le SFT souligne son accent sur l’efficacité et l’adaptabilité, marquant un changement vers une optimisation plus directe pilotée par le RL.
Benchmark
De Qwen
QwQ-32B dépasse son poids : Il égale ou dépasse les performances de modèles plus grands, tels que DeepSeek-R1-671B, dans plusieurs benchmarks, malgré un nombre de paramètres inférieur. Le modèle démontre de solides compétences générales en raisonnement, codage et inférence, mais pas de contenu créatif, ce qui le rend polyvalent pour diverses tâches.
Configuration matérielle requise
Pour exécuter QwQ-32B efficacement, considérez les exigences matérielles suivantes :
- VRAM :
- Nécessite une VRAM substantielle.
- Pour une précision 16 bits, 80 Go de VRAM sont nécessaires.
- Pour une précision 8 bits, 40 Go de VRAM suffisent.
- Pour une précision 4 bits, seulement 20 Go de VRAM sont requis.
- GPU :
- Compatible avec les GPU RTX 3090/4090, surtout en utilisant la quantification.
- Les GPU haut de gamme comme NVIDIA A100 et H100 sont également adaptés.
Comparé à DeepSeek R1, QwQ-32B réduit considérablement les besoins matériels, le rendant plus accessible pour divers systèmes tout en maintenant des performances solides.
Applications
- Éducation :
- Fournit un tutorat personnalisé en mathématiques et programmation, adapté aux apprenants de différents niveaux.
- Explique des concepts complexes en termes simples, en faisant un outil précieux pour les étudiants et les éducateurs.
- Aide à résoudre des devoirs et à générer des exercices pratiques pour un apprentissage efficace.
- Développement logiciel :
- Soutient les développeurs en générant des extraits de code de haute qualité pour divers langages de programmation.
- Aide au débogage en identifiant les erreurs et en suggérant des correctifs appropriés.
- Propose des recommandations pour optimiser l’efficacité du code et respecter les meilleures pratiques.
- Recherche :
- Aide les chercheurs à effectuer des analyses de données, y compris des calculs statistiques et des visualisations.
- Aide aux revues de littérature, en résumant des articles académiques et en extrayant des informations clés.
- Génère des brouillons initiaux pour les documents de recherche, faisant gagner un temps précieux aux chercheurs.
- Résolution de problèmes :
- Aide à décomposer des problèmes complexes en composants plus petits et gérables.
- Suggère des solutions potentielles, y compris des instructions étape par étape pour des défis multidimensionnels.
- Fournit un raisonnement logique et des explications pour soutenir les processus de prise de décision.
En excellant dans ces domaines, QwQ-32B sert d’assistant polyvalent pour les tâches éducatives, professionnelles et de recherche.
QWQ 32B vs Qwen 2.5 72B vs DeepSeek R1
| Caractéristique | QwQ-32B | Qwen 2.5 72B | DeepSeek-R1 671B |
|---|---|---|---|
| Paramètres | 32,5B | 72B | 671B |
| Base d’architecture | Qwen 2.5 | Architecture native | DeepSeek-R1-Zero |
| Méthode d’entraînement | Apprentissage par renforcement (pas de SFT) | Non spécifiquement indiqué | RL + Fine-tuning supervisé |
| Fenêtre de contexte | 32 768 tokens | 8 000 tokens | 32 768 tokens |
| Langues prises en charge | Plus de 29 langues | Plus de 29 langues | Principalement chinois et anglais |
| Capacité mathématique | 79,5 (AIME 2024) | 83,1 (benchmark MATH) | 97,3 (MATH-500), 79,8 (AIME 2024) |
| Capacité de codage | 63,4 (Live Code Bench) | 59,1 (HumanEval) | 49,2 (SWE-bench Verified), 65,9 (Live Code Bench) |
| Configuration matérielle requise | 4 bits : 20 Go VRAM/8 bits : 40 Go VRAM/16 bits : 80 Go VRAM, de préférence avec plusieurs A100 ou H100 | environ 41,6 Go à 77,1 Go de VRAM | 8xGPU H100 |
| Licence open source | Apache 2.0 | Non spécifiquement indiqué | Licence MIT |
| Principaux avantages | Respectueux du matériel/Raisonnement puissant/Comparable à des modèles plus grands | Temps de réponse rapide/Rentable/Bon support multilingue | Raisonnement mathématique exceptionnel/Sorties auto-vérifiées/Processus de raisonnement clair |
| Caractéristiques de sortie | Raisonnement logique solide, contenu créatif plus faible | Capacités générales | Logique claire, bien structurée |
Comment accéder à QWQ 32B ?
1. Utiliser des plateformes en ligne pour accéder à QWQ 32B (ex. Novita AI)
Vous pouvez trouver la page LLM Playground de Novita AI pour un essai gratuit ! C’est la page de test que nous fournissons spécifiquement pour les développeurs ! Sélectionnez le modèle souhaité dans la liste. Ici, vous pouvez choisir le modèle QWQ 32B.
Essayez la démo QWQ 32B maintenant !
2.Accéder aux API QWQ 32B gratuites (ex. Novita AI)
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API, tout en fournissant également un cloud GPU abordable et fiable pour construire et passer à l’échelle.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier avec l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring to: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwq-32b"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
Lors de l’inscription, Novita AI offre un crédit de 0,5 $ pour commencer !
Si les crédits gratuits sont épuisés, vous pouvez payer pour continuer à l’utiliser.
Conclusion
QwQ-32B représente une avancée significative dans les modèles de raisonnement IA, offrant des performances exceptionnelles en mathématiques, codage et résolution de problèmes en plusieurs étapes, tout en conservant une taille relativement compacte. Avec sa disponibilité open source et sa conception efficace, il constitue un outil puissant pour les chercheurs, développeurs et ingénieurs cherchant à exploiter l’IA pour des tâches complexes et structurées.
Qu’est-ce qui rend QwQ-32B unique ?
QwQ-32B se distingue par son utilisation de l’apprentissage par renforcement sans fine-tuning supervisé, atteignant des performances exceptionnelles dans les tâches de raisonnement, notamment en mathématiques et en codage.
Quels sont les besoins matériels ?
Pour des performances optimales, QwQ-32B nécessite des ressources de calcul importantes. La version quantifiée en 4 bits nécessite environ 20 Go de VRAM.
Quelle est la différence entre QwQ-32B et Qwen2.5 ?
QwQ-32B s’appuie sur Qwen2.5, en ajoutant une optimisation par apprentissage par renforcement spécifiquement pour les tâches de raisonnement, sans utiliser les approches traditionnelles de fine-tuning supervisé.
Novita AI est la plateforme cloud tout-en-un qui dynamise vos ambitions IA. API intégrées, serverless, instances GPU — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et faites de votre vision IA une réalité.



