

Puntos clave
Aprendizaje por refuerzo (RL): Utiliza un proceso de RL en dos etapas para refinar el razonamiento mediante prueba y error, verificado por herramientas como intérpretes de código y solucionadores, asegurando resultados precisos.
Puntos de referencia competitivos: Obtiene puntuaciones altas en tareas de razonamiento y codificación:
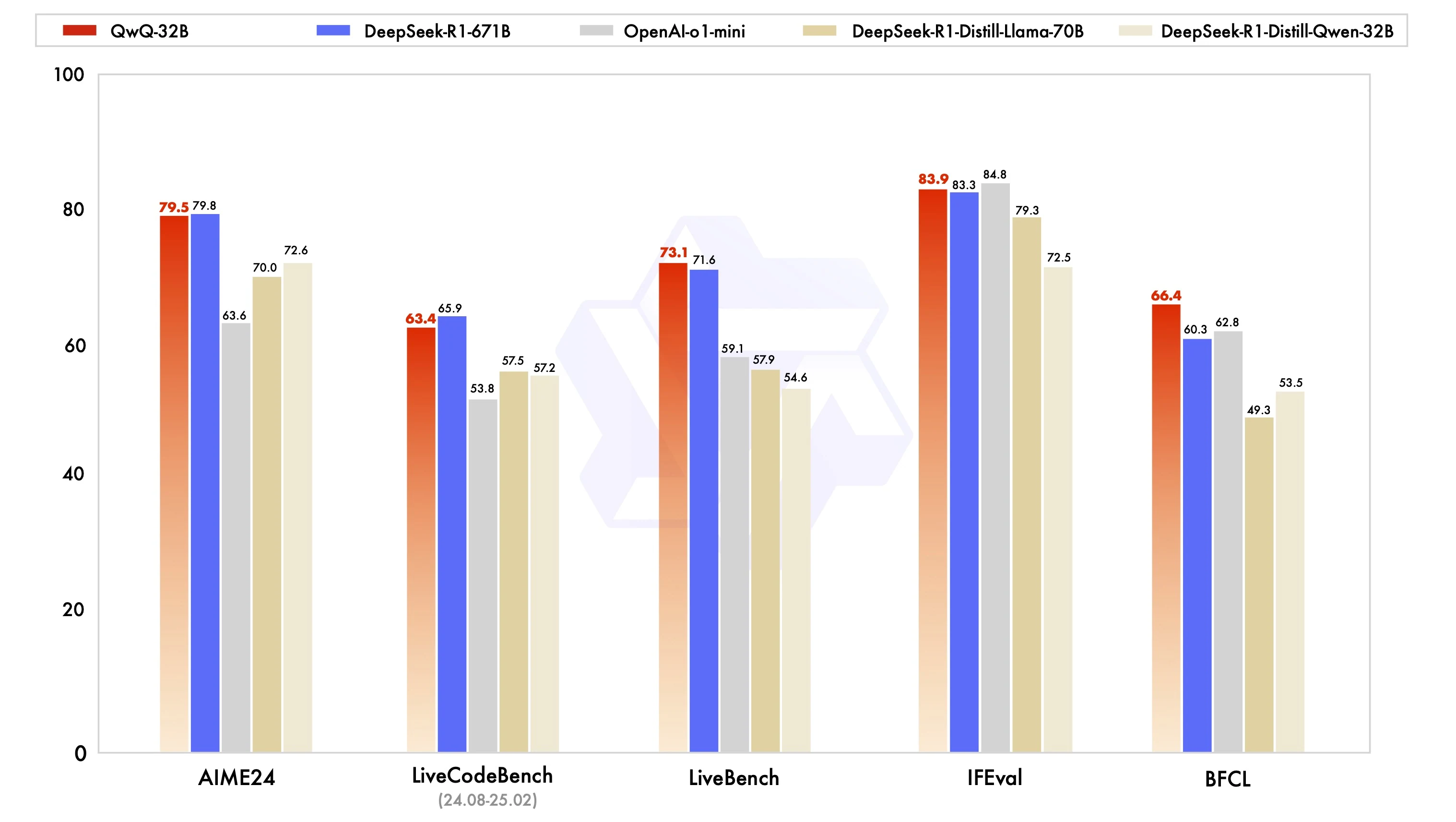
AIME24: 79.5 (cerca del 79.8 de DeepSeek R1).
IFEval: 83.9 (ligeramente por encima de DeepSeek R1).
BFCL: 66.4 (superando el 60.3 de DeepSeek R1).
Eficiencia de hardware: Requiere significativamente menos VRAM que DeepSeek R1; admite cuantización para ejecutarse en configuraciones de hardware más pequeñas.
Si estás buscando evaluar el QWQ 32B en tus propios casos de uso — Al registrarte, Novita AI proporciona un crédito de $0.5 para empezar!
QwQ-32B, desarrollado por el equipo Qwen de Alibaba, es un modelo de razonamiento de 32.5 mil millones de parámetros que ofrece un rendimiento comparable a modelos mucho más grandes como DeepSeek-R1, mientras utiliza significativamente menos parámetros. Su eficiencia y sólidas capacidades de razonamiento lo convierten en una opción ideal para investigadores, desarrolladores y organizaciones que buscan alto rendimiento sin los exigentes requisitos de recursos de los modelos de lenguaje grandes (LLMs) tradicionales.
¿Qué es QwQ-32B?
Introducción básica
- qwen/qwq-32b
- Código abierto: Disponible bajo la licencia Apache 2.0, lo que permite contribuciones y mejoras de la comunidad.
- Transformers: QwQ-32B utiliza una arquitectura transformer con 64 capas, 40 cabezas de atención para consultas y 8 para clave-valor. Construido sobre transformers con RoPE (Embeddings Posicionales Rotatorios), QwQ-32B integra la función de activación SwiGLU, emplea RMSNorm para la normalización e incluye sesgo en los cálculos de QKV de atención.
- Parámetros: Un total de 32.5 mil millones de parámetros, con 31.0 mil millones de parámetros no incrustados.
- Soporte de contexto largo: Admite hasta 32,768 tokens.
- Idiomas compatibles: Cubre más de 29 idiomas para accesibilidad y aplicación global.
Métodos de entrenamiento
Basándose en Qwen2.5, QwQ-32B optimiza específicamente las tareas de razonamiento mediante RL, mostrando una innovación potencial al eliminar la dependencia de los métodos tradicionales de ajuste fino supervisado (SFT).
Además, QwQ-32B utiliza aprendizaje por refuerzo (RL) para refinar sus habilidades de razonamiento, basándose en prueba y error para adaptar su enfoque utilizando herramientas y retroalimentación del entorno. Al emplear un mecanismo de “recompensas basadas en resultados”, el modelo genera resultados de forma independiente, que luego se verifican para determinar su precisión, garantizando un rendimiento confiable en tareas estructuradas. Esta desviación del SFT destaca su enfoque en la eficiencia y la adaptabilidad, marcando un cambio hacia una optimización más directa impulsada por RL.
Puntos de referencia
De Qwen
QwQ-32B supera su peso: Iguala o supera el rendimiento de modelos más grandes, como DeepSeek-R1-671B, en varios puntos de referencia, a pesar de tener menos parámetros. El modelo demuestra un sólido razonamiento general, habilidades de codificación e inferencia, pero no contenido creativo, lo que lo hace versátil en diversas tareas.
Requisitos de hardware
Para ejecutar QwQ-32B de manera eficiente, considera los siguientes requisitos de hardware:
- VRAM:
- Requiere una VRAM sustancial.
- Para precisión de 16 bits, se necesitan 80 GB de VRAM.
- Para precisión de 8 bits, 40 GB de VRAM son suficientes.
- Para precisión de 4 bits, solo se requieren 20 GB de VRAM.
- GPUs:
- Compatible con GPUs RTX 3090/4090, especialmente al usar cuantización.
- GPUs de gama alta como NVIDIA A100 y H100 también son adecuadas.
En comparación con DeepSeek R1, QwQ-32B reduce significativamente los requisitos de hardware, lo que lo hace más accesible para diversos sistemas mientras mantiene un rendimiento sólido.
Aplicaciones
- Educación:
- Proporciona tutoría personalizada en matemáticas y programación, adaptándose a estudiantes de diferentes niveles de habilidad.
- Explica conceptos complejos en términos simples, lo que lo convierte en una herramienta valiosa tanto para estudiantes como para educadores.
- Ayuda a resolver problemas de tareas y generar ejercicios de práctica para un aprendizaje efectivo.
- Desarrollo de software:
- Apoya a los desarrolladores generando fragmentos de código de alta calidad para varios lenguajes de programación.
- Ayuda en la depuración identificando errores y sugiriendo correcciones adecuadas.
- Ofrece recomendaciones para optimizar la eficiencia del código y adherirse a las mejores prácticas.
- Investigación:
- Ayuda a los investigadores a realizar análisis de datos, incluyendo cálculos estadísticos y visualización.
- Ayuda con revisiones de literatura, resumiendo artículos académicos y extrayendo ideas clave.
- Genera borradores iniciales para documentos de investigación, ahorrando tiempo valioso a los investigadores.
- Resolución de problemas:
- Ayuda a descomponer problemas complejos en componentes más pequeños y manejables.
- Sugiere soluciones potenciales, incluyendo guías paso a paso para desafíos multifacéticos.
- Proporciona razonamiento lógico y explicaciones para apoyar los procesos de toma de decisiones.
Al sobresalir en estas áreas, QwQ-32B sirve como un asistente versátil para tareas educativas, profesionales y relacionadas con la investigación.
QWQ 32B vs Qwen 2.5 72B vs DeepSeek R1
| Característica | QwQ-32B | Qwen 2.5 72B | DeepSeek-R1 671B |
|---|---|---|---|
| Parámetros | 32.5B | 72B | 671B |
| Base de arquitectura | Qwen 2.5 | Arquitectura nativa | DeepSeek-R1-Zero |
| Método de entrenamiento | Aprendizaje por refuerzo (sin SFT) | No especificado explícitamente | RL + Ajuste fino supervisado |
| Ventana de contexto | 32,768 tokens | 8,000 tokens | 32,768 tokens |
| Soporte de idiomas | 29+ idiomas | 29+ idiomas | Principalmente chino e inglés |
| Habilidad matemática | 79.5 (AIME 2024) | 83.1 (punto de referencia MATH) | 97.3 (MATH-500), 79.8 (AIME 2024) |
| Habilidad de codificación | 63.4 (Live Code Bench) | 59.1 (HumanEval) | 49.2 (SWE-bench Verified), 65.9 (Live Code Bench) |
| Requisitos de hardware | 4 bits: 20 GB VRAM / 8 bits: 40 GB VRAM / 16 bits: 80 GB VRAM, preferiblemente con múltiples A100 o H100 | aproximadamente 41.6 GB a 77.1 GB de VRAM | 8 GPUs H100 |
| Licencia de código abierto | Apache 2.0 | No especificada explícitamente | Licencia MIT |
| Ventajas clave | Amigable con el hardware / Razonamiento sólido / Comparable a modelos más grandes | Respuesta rápida / Rentable / Buen soporte multilingüe | Razonamiento matemático excepcional / Salidas autoverificadas / Proceso de razonamiento claro |
| Características de salida | Fuerte razonamiento lógico, contenido creativo más débil | Capacidades generales | Lógica clara, bien estructurada |
Cómo acceder a QWQ 32B
1. Usar plataformas en línea para acceder a QWQ 32B (ej. Novita AI)
Puedes encontrar la página de LLM Playground de Novita AI para una prueba gratuita. ¡Esta es la página de prueba que proporcionamos específicamente para desarrolladores! Selecciona el modelo que desees de la lista. Aquí puedes elegir el modelo QWQ 32B.
2.****Acceder a las APIs gratuitas de QWQ 32B **** (ej. Novita AI)
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma fácil de implementar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona la nube de GPU asequible y confiable para construir y escalar.
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Comienza tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Entrando en la página de “Settings”, puedes copiar la clave de API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el administrador de paquetes específico de tu lenguaje de programación.

Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring to: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwq-32b"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
Al registrarte, Novita AI proporciona un crédito de $0.5 para empezar.
Si se agotan los créditos gratuitos, puedes pagar para continuar usándolo.
Conclusión
QwQ-32B representa un avance significativo en los modelos de razonamiento de IA, ofreciendo un rendimiento excepcional en matemáticas, codificación y resolución de problemas de múltiples pasos, todo mientras mantiene un tamaño relativamente compacto. Con su disponibilidad de código abierto y diseño eficiente, sirve como una herramienta poderosa para investigadores, desarrolladores e ingenieros que buscan aprovechar la IA para tareas complejas y estructuradas.
¿Qué hace único a QwQ-32B?
QwQ-32B se destaca por su uso de aprendizaje por refuerzo sin ajuste fino supervisado, logrando un rendimiento excepcional en tareas de razonamiento, particularmente en matemáticas y codificación.
¿Cuáles son los requisitos de hardware?
Para un rendimiento óptimo, QwQ-32B requiere recursos computacionales significativos. La versión cuantizada de 4 bits necesita aproximadamente 20 GB de VRAM.
¿Cuál es la diferencia entre QwQ-32B y Qwen2.5?
QwQ-32B se basa en Qwen2.5, añadiendo optimización de aprendizaje por refuerzo específicamente para tareas de razonamiento, sin usar enfoques tradicionales de ajuste fino supervisado.
Novita AI es la plataforma en la nube todo en uno que impulsa tus ambiciones de IA. APIs integradas, serverless, Instancia de GPU — las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



