

Wichtige Highlights
Reinforcement Learning (RL): Nutzt einen zweistufigen RL-Prozess, um die Argumentation durch Versuch und Irrtum zu verfeinern, verifiziert durch Werkzeuge wie Code-Interpreter und Löser, um genaue Ergebnisse zu gewährleisten.
Wettbewerbsfähige Benchmarks: Erzielt starke Werte bei Reasoning- und Coding-Aufgaben:
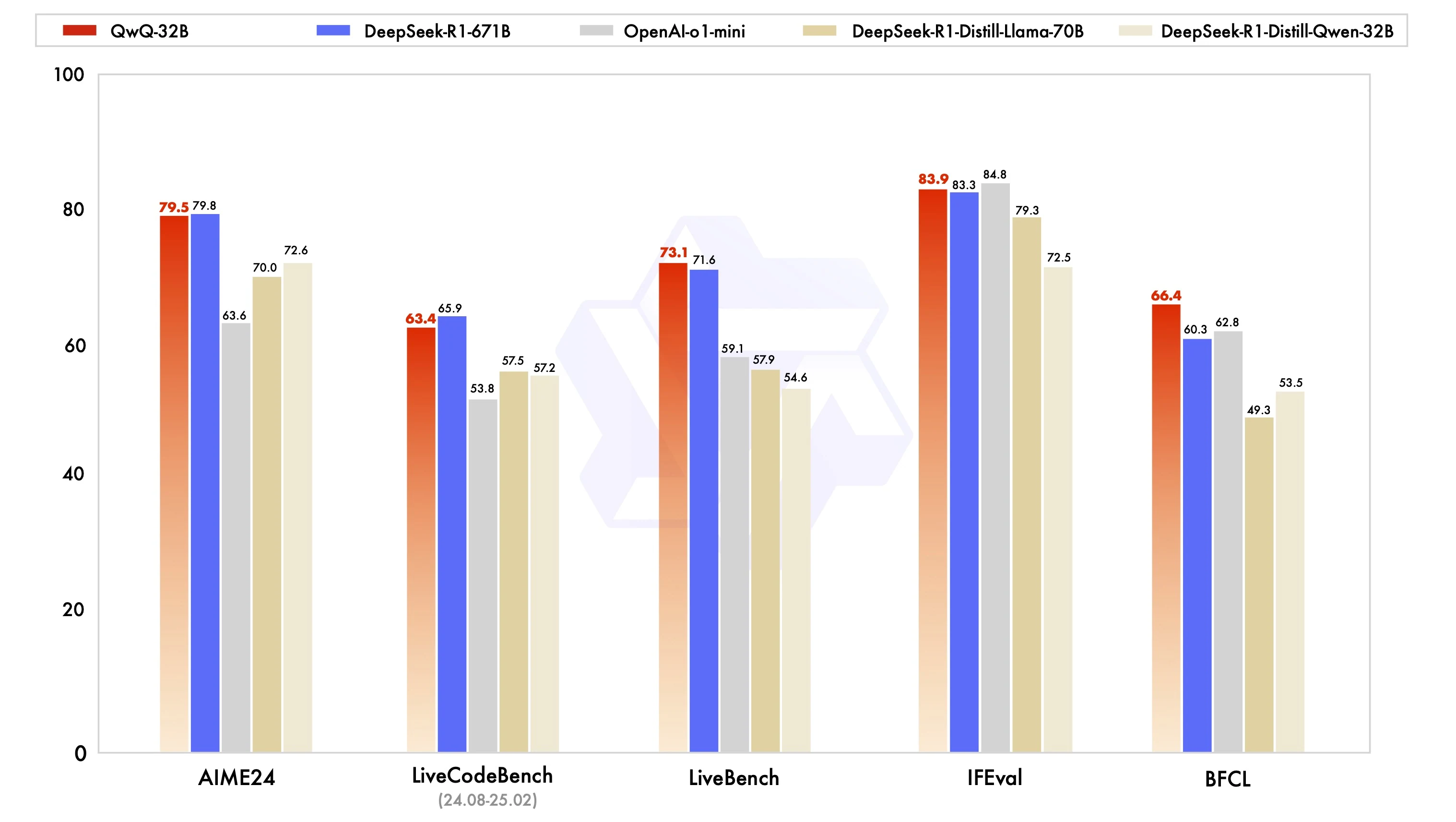
AIME24: 79,5 (nahe an DeepSeek R1 mit 79,8).
IFEval: 83,9 (leicht über DeepSeek R1).
BFCL: 66,4 (übertrifft DeepSeek R1 mit 60,3).
Hardware-Effizienz: Benötigt deutlich weniger VRAM als DeepSeek R1; unterstützt Quantisierung, um auf kleinerer Hardware zu laufen.
Wenn Sie QWQ 32B für Ihre eigenen Anwendungsfälle testen möchten – Bei der Registrierung gibt Novita AI Ihnen ein Guthaben von 0,5 $, um loszulegen!
QwQ-32B, entwickelt von Alibabas Qwen-Team, ist ein Reasoning-Modell mit 32,5 Milliarden Parametern, das eine mit deutlich größeren Modellen wie DeepSeek-R1 vergleichbare Leistung erbringt – bei deutlich weniger Parametern. Seine Effizienz und starken Reasoning-Fähigkeiten machen es zur idealen Wahl für Forscher, Entwickler und Organisationen, die hohe Leistung ohne den hohen Ressourcenbedarf traditioneller großer Sprachmodelle (LLMs) benötigen.
Was ist QwQ-32B?
Grundlegende Einführung
- qwen/qwq-32b
- Open Source: Verfügbar unter der Apache 2.0-Lizenz, die Community-Beiträge und Verbesserungen ermöglicht.
- Transformers: QwQ-32B verwendet eine Transformer-Architektur mit 64 Schichten, 40 Aufmerksamkeitsköpfen für Queries und 8 für Key-Values. Es basiert auf Transformers mit RoPE (Rotary Positional Embeddings), integriert die SwiGLU-Aktivierungsfunktion, verwendet RMSNorm zur Normalisierung und enthält einen Bias in den Attention-QKV-Berechnungen.
- Parameter: Insgesamt 32,5 Milliarden Parameter, davon 31,0 Milliarden Nicht-Embedding-Parameter.
- Langer Kontext: Unterstützt bis zu 32.768 Token.
- Unterstützte Sprachen: Deckt über 29 Sprachen ab, für globale Zugänglichkeit und Anwendung.
Trainingsmethoden
Aufbauend auf Qwen2.5 optimiert QwQ-32B Reasoning-Aufgaben gezielt durch RL. Dies zeigt ein innovatives Potenzial, indem es die Abhängigkeit von traditionellen überwachten Feinabstimmungsmethoden (SFT) eliminiert.
Darüber hinaus nutzt QwQ-32B Reinforcement Learning (RL), um seine Reasoning-Fähigkeiten zu verfeinern, indem es auf Versuch und Irrtum setzt, um seinen Ansatz mithilfe von Werkzeugen und Umgebungsfeedback anzupassen. Durch einen Mechanismus mit „ergebnisbasierten Belohnungen“ generiert das Modell Ergebnisse eigenständig, die dann auf Richtigkeit überprüft werden – die Zuverlässigkeit bei strukturierten Aufgaben ist gewährleistet. Diese Abkehr von SFT unterstreicht den Fokus auf Effizienz und Anpassungsfähigkeit und markiert eine Verschiebung hin zu einer direkteren RL-gesteuerten Optimierung.
Benchmark
Von Qwen
QwQ-32B schlägt über seinem Gewicht: Es erreicht oder übertrifft die Leistung größerer Modelle wie DeepSeek-R1-671B in mehreren Benchmarks, trotz weniger Parametern. Das Modell zeigt starke allgemeine Reasoning-, Programmier- und Inferenzfähigkeiten, jedoch keine kreativen Inhalte, was es vielseitig für verschiedene Aufgaben macht.
Hardware-Anforderungen
Für einen effizienten Betrieb von QwQ-32B sollten Sie folgende Hardware-Anforderungen beachten:
- VRAM:
- Erfordert erheblichen VRAM.
- Für 16-Bit-Genauigkeit werden 80 GB VRAM benötigt.
- Für 8-Bit-Genauigkeit reichen 40 GB VRAM aus.
- Für 4-Bit-Genauigkeit sind nur 20 GB VRAM erforderlich.
- GPUs:
- Kompatibel mit RTX 3090/4090 GPUs, besonders bei Verwendung von Quantisierung.
- High-End-GPUs wie NVIDIA A100 und H100 sind ebenfalls geeignet.
Im Vergleich zu DeepSeek R1 reduziert QwQ-32B die Hardware-Anforderungen erheblich, was es für verschiedene Systeme zugänglicher macht, während die Leistung stark bleibt.
Anwendungen
- Bildung:
- Bietet personalisierte Nachhilfe in Mathematik und Programmierung für Lernende unterschiedlicher Niveaus.
- Erklärt komplexe Konzepte in einfachen Worten – ein wertvolles Werkzeug für Schüler und Lehrer gleichermaßen.
- Hilft bei Hausaufgaben und erstellt Übungsaufgaben für effektives Lernen.
- Softwareentwicklung:
- Unterstützt Entwickler durch Generierung hochwertiger Code-Snippets in verschiedenen Programmiersprachen.
- Hilft beim Debuggen durch Identifizierung von Fehlern und Vorschlag geeigneter Korrekturen.
- Bietet Empfehlungen zur Optimierung der Code-Effizienz und Einhaltung von Best Practices.
- Forschung:
- Unterstützt Forscher bei der Datenanalyse, einschließlich statistischer Berechnungen und Visualisierung.
- Hilft bei Literaturrecherchen, Zusammenfassungen akademischer Arbeiten und Extraktion wichtiger Erkenntnisse.
- Erstellt erste Entwürfe für Forschungsdokumente, was wertvolle Zeit spart.
- Problemlösung:
- Hilft, komplexe Probleme in kleinere, handhabbare Teile zu zerlegen.
- Schlägt potenzielle Lösungen vor, einschließlich Schritt-für-Schritt-Anleitungen für vielschichtige Herausforderungen.
- Bietet logisches Denken und Erklärungen zur Unterstützung von Entscheidungsprozessen.
Durch seine Stärke in diesen Bereichen dient QwQ-32B als vielseitiger Assistent für Bildungs-, Berufs- und Forschungsaufgaben.
QWQ 32B vs Qwen 2.5 72B vs DeepSeek R1
| Feature | QwQ-32B | Qwen 2.5 72B | DeepSeek-R1 671B |
|---|---|---|---|
| Parameter | 32,5B | 72B | 671B |
| Architektur-Basis | Qwen 2.5 | Native Architektur | DeepSeek-R1-Zero |
| Trainingsmethode | Reinforcement Learning (kein SFT) | Nicht näher spezifiziert | RL + Supervised Fine-tuning |
| Kontextfenster | 32.768 Token | 8.000 Token | 32.768 Token |
| Sprachunterstützung | 29+ Sprachen | 29+ Sprachen | Hauptsächlich Chinesisch und Englisch |
| Mathematische Fähigkeit | 79,5 (AIME 2024) | 83,1 (MATH Benchmark) | 97,3 (MATH-500), 79,8 (AIME 2024) |
| Programmierfähigkeit | 63,4 (Live Code Bench) | 59,1 (HumanEval) | 49,2 (SWE-bench Verified), 65,9 (Live Code Bench) |
| Hardware-Anforderungen | 4-Bit: 20 GB VRAM/8-Bit: 40 GB VRAM/16-Bit: 80 GB VRAM, vorzugsweise mit mehreren A100 oder H100 | etwa 41,6 GB bis 77,1 GB VRAM | 8xH100 GPUs |
| Open-Source-Lizenz | Apache 2.0 | Nicht näher spezifiziert | MIT-Lizenz |
| Hauptvorteile | Hardwarefreundlich/Starkes Reasoning/Vergleichbar mit größeren Modellen | Schnelle Antwortzeiten/Kostengünstig/Gute Mehrsprachigkeit | Außergewöhnliches mathematisches Reasoning/Selbstprüfung der Ausgaben/Klarer Reasoning-Prozess |
| Ausgabeeigenschaften | Starkes logisches Denken, schwächere kreative Inhalte | Allgemeine Fähigkeiten | Klare Logik, gut strukturiert |
Wie erhalte ich Zugang zu QWQ 32B?
1. Nutzung von Online-Plattformen (z. B. Novita AI)
Sie finden die LLM-Playground-Seite von Novita AI für einen kostenlosen Test! Dies ist die speziell für Entwickler bereitgestellte Testseite. Wählen Sie das gewünschte Modell aus der Liste. Hier können Sie das Modell QWQ 32B auswählen.
QwQ 32B jetzt kostenlos testen!
2.Kostenlose QWQ 32B-APIs nutzen (z. B. Novita AI)
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern einen einfachen Weg bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für Aufbau und Skalierung bereitstellt.
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Loggen Sie sich in Ihr Konto ein und klicken Sie auf die Schaltfläche Model Library.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihren kostenlosen Test
Beginnen Sie Ihren kostenlosen Test, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Ihren API-Schlüssel abrufen
Zur Authentifizierung mit der API erhalten Sie einen neuen API-Schlüssel. Rufen Sie die Seite „Settings“ auf und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Die API installieren
Installieren Sie die API mit dem Paketmanager Ihrer Programmiersprache.

Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Holen Sie sich den Novita AI API-Schlüssel: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<IHR Novita AI API-Schlüssel>",
)
model = "qwen/qwq-32b"
stream = True # oder False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Verhalten Sie sich wie ein hilfreicher Assistent.",
},
{
"role": "user",
"content": "Hallo!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
Bei der Registrierung gibt Novita AI ein Guthaben von 0,5 $, um loszulegen!
Wenn das kostenlose Guthaben aufgebraucht ist, können Sie bezahlen, um die Nutzung fortzusetzen.
Fazit
QwQ-32B stellt einen bedeutenden Fortschritt in KI-Reasoning-Modellen dar. Es liefert außergewöhnliche Leistungen in Mathematik, Programmierung und mehrstufiger Problemlösung – bei gleichzeitig kompakter Größe. Durch seine Open-Source-Verfügbarkeit und effizientes Design ist es ein leistungsstarkes Werkzeug für Forscher, Entwickler und Ingenieure, die KI für komplexe und strukturierte Aufgaben nutzen möchten.
Was macht QwQ-32B einzigartig?
QwQ-32B zeichnet sich durch den Einsatz von Reinforcement Learning ohne überwachte Feinabstimmung aus und erreicht eine außergewöhnliche Leistung bei Reasoning-Aufgaben, insbesondere in Mathematik und Programmierung.
Welche Hardwareanforderungen gibt es?
Für optimale Leistung benötigt QwQ-32B erhebliche Rechenressourcen. Die quantisierte 4-Bit-Version benötigt etwa 20 GB VRAM.
Was ist der Unterschied zwischen QwQ-32B und Qwen2.5?
QwQ-32B baut auf Qwen2.5 auf und fügt eine Reinforcement-Learning-Optimierung speziell für Reasoning-Aufgaben hinzu, ohne traditionelle überwachte Feinabstimmungsansätze zu verwenden.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen fördert. Integrierte APIs, serverlos, GPU-Instanzen – die kostengünstigen Werkzeuge, die Sie brauchen. Infrastruktur wegdenken, kostenlos starten und Ihre KI-Vision verwirklichen.



