

Recommandez vos amis dès aujourd’hui et vous recevez tous les deux 10 $ de crédits API LLM — soit jusqu’à 500 $ de récompenses qui vous attendent !
Llama 3.2 1B, Qwen2.5 7B, Qwen 3 (0.6B, 1.7B, 4B), GLM 4 — tous disponibles maintenant sur Novita AI pour booster vos projets sans dépenser un centime !
Construisez avec Novita AI dès maintenant !
DeepSeek R1 0528 offre des capacités d’IA de pointe avec son architecture Mixture-of-Experts de 685 milliards de paramètres, excellant dans le raisonnement, le codage et les tâches multilingues.
Cependant, ses importantes exigences matérielles rendent le déploiement local difficile. Pour des besoins à plus petite échelle, DeepSeek R1 0528 Qwen 3 8B propose une alternative compacte et efficace.
En complément, les solutions cloud comme Novita AI éliminent les contraintes d’infrastructure, offrant un accès scalable et économique aux modèles DeepSeek.
Combien de types DeepSeek R1 0528 propose-t-il ?
https://www.youtube.com/watch?v=TidP39n5GfU
DeepSeek R1 0528
Taille du modèle : 685 milliards de paramètres
Open Source : Oui
Architecture : Mixture of Experts (MoE)
Support linguistique : Multilingue, excelle en anglais et en chinois
Modalités prises en charge : Texte vers Texte
Méthode d’entraînement : Dans la dernière mise à jour, la profondeur du raisonnement et les capacités d’inférence du modèle ont été considérablement améliorées grâce à l’utilisation de ressources de calcul accrues et d’optimisations algorithmiques lors du post-entraînement.
DeepSeek R1 0528 Qwen 3 8B
Taille du modèle : 8,19 milliards de paramètres
Open Source : Oui
Architecture : Transformer
Support linguistique : Multilingue, excelle en anglais et en chinois
Modalités prises en charge : Texte vers Texte
Méthode d’entraînement : Post-entraîné avec la chaîne de pensée distillée à partir de DeepSeek-R1-0528, donnant naissance à DeepSeek-R1-0528-Qwen3-8B.
Benchmark de DeepSeek R1 0528
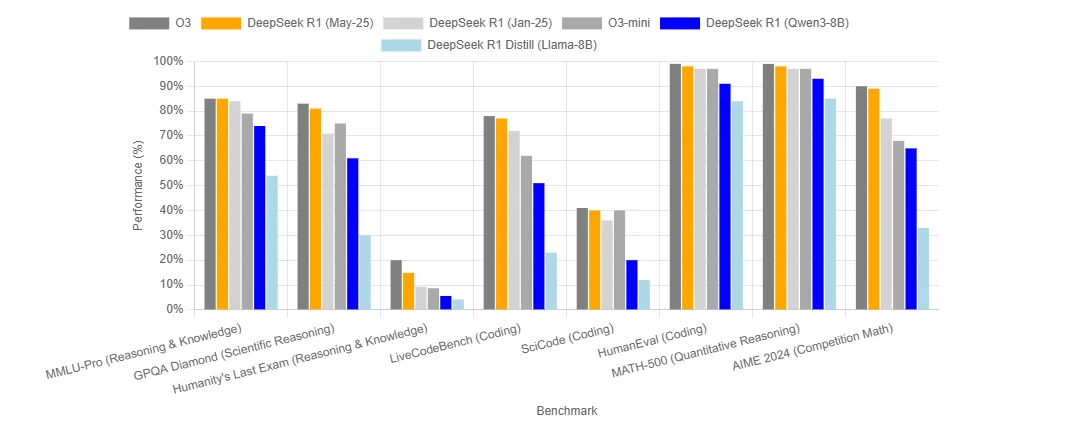
Combien coûte l’exécution de DeepSeek R1 0528 ?
Voici un aperçu des exigences matérielles pour DeepSeek R1 0528 et DeepSeek R1 0528 Qwen 3 8B, présentant leurs configurations respectives et leurs besoins système :
Exigences matérielles
DeepSeek R1 0528 version complète
- Taille du modèle : ~1900 Go
- Configuration matérielle :
- 24 × GPU NVIDIA H100 (80 Go de mémoire chacun) ; 8 × H200 SXM 141 Go
- Mémoire GPU totale : 1920 Go
- RAM système :
- Recommandée : ≥512 Go
- Optimale : 1 To (pour le déchargement GPU, le cache KV, les tâches parallèles)
- Stockage :
- SSD NVMe haute vitesse
- Capacité : ≥500 Go
- CPU :
- Processeurs multiceurs haute fréquence (par ex., Dual Intel Xeon ou AMD EPYC)
- Refroidissement et alimentation :
- Systèmes de refroidissement et d’alimentation de niveau entreprise
- Consommation électrique typique : plusieurs kW
Lancez instantanément le template GPU DeepSeek-R1-0528
DeepSeek R1 0528 Qwen 3 8B
- Taille du modèle : 18,72 Go
- Configuration matérielle :
- 1 × GPU NVIDIA RTX 4090 (24 Go de mémoire)
Alors que DeepSeek R1 Qwen 3 8B constitue une option viable pour les déploiements locaux ou à ressources limitées, les configurations plus grandes de DeepSeek R1 offrent des performances supérieures sur tous les benchmarks, en particulier pour les tâches exigeantes comme le codage et le raisonnement.
DeepSeek R1 0528 en local : efficace mais contraignant
1. Contraintes matérielles et financières
- Exigences GPU élevées : 24 GPU H100 sont prohibitifs et nécessitent un centre de données à grande échelle. Chaque GPU H100 coûte des dizaines de milliers de dollars.
- Grande RAM système : Un minimum de 512 Go de RAM, idéalement 1 To, dépasse largement le matériel grand public standard.
- Besoins en stockage : Des SSD NVMe haute vitesse avec de grandes capacités sont essentiels, ce qui ajoute un coût significatif.
2. Alimentation et refroidissement
- Consommation électrique : Le système nécessite plusieurs kW, ce qui dépasse les capacités d’une installation domestique ou de bureau typique.
- Refroidissement : Des systèmes de refroidissement de niveau entreprise (par ex., refroidissement liquide) sont nécessaires pour éviter la surchauffe, difficile à réaliser localement.
3. Espace physique
- Taille du système : Les serveurs en rack pour 24 GPU nécessitent un espace physique important, probablement indisponible dans un domicile ou un petit bureau.
4. Compétences et logiciels
- Maintenance : Gérer un système aussi puissant implique une maintenance continue, difficile sans une équipe informatique dédiée.
- Configuration système : Mettre en place un apprentissage ou une inférence distribuée sur 24 GPU nécessite une expertise en gestion de cluster et des logiciels comme PyTorch, NCCL ou DeepSpeed.
https://www.youtube.com/watch?v=W8CObaM-gjA
Accéder à une alternative à DeepSeek R1 0528 : une API comme Novita AI
- Accès cloud
Novita AI exploite une infrastructure cloud puissante, éliminant le besoin de matériel local coûteux. Cela permet aux utilisateurs d’accéder à des fonctionnalités d’IA avancées depuis n’importe quel appareil connecté à Internet.
- Facilité d’utilisation
Avec Novita AI, pas besoin d’installations complexes ni de gestion de dépendances. Les utilisateurs peuvent accéder à ses fonctionnalités via une interface web ou une API, évitant les défis techniques associés au déploiement de DeepSeek V3.
- Économique
Au lieu d’investir dans des GPU coûteux et de subir une consommation électrique élevée, Novita AI propose un modèle de paiement à l’utilisation, ce qui en fait une option plus abordable pour de nombreux cas d’usage.
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.
Llama 3.2 1B, Qwen2.5 7B, Qwen 3 (0.6B, 1.7B, 4B), GLM 4 — tous disponibles maintenant sur Novita AI pour booster vos projets sans dépenser un centime !
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Essayez la démo DeepSeek R1 0528 dès maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Commencez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En entrant dans la page Settings, vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_H_85jwhkUyBsRipBTIU9n_adbP5B9Qvu0wxGGMN4Vq-BpFVKntQQXOAJF4IpkuDJh2e-NQkoJkcwMhus4t81PQ==",
)
model = "deepseek/deepseek-r1-0528-qwen3-8b"
stream = True # or False
max_tokens = 16000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
En raison des exigences matérielles élevées de DeepSeek R1, nous encourageons tout le monde à utiliser Novita AI, une plateforme cloud qui offre un accès économique et scalable aux modèles d’IA avancés sans nécessiter d’infrastructure coûteuse.
Foire aux questions
Quelles sont les principales différences entre DeepSeek R1 0528 et DeepSeek R1 0528 Qwen 3 8B ?
DeepSeek R1 0528 : 685B paramètres, architecture Mixture-of-Experts, nécessite 24 GPU H100.
DeepSeek R1 0528 Qwen 3 8B : 8,19B paramètres, architecture Transformer, fonctionne sur un seul GPU RTX 4090.
Qu’est-ce qui rend l’architecture Mixture-of-Experts (MoE) unique ?
MoE active dynamiquement des sous-ensembles de paramètres (« experts ») pour des tâches spécifiques, améliorant l’efficacité computationnelle pour les tâches très complexes, mais exige du matériel avancé.
DeepSeek R1 0528 peut-il être déployé localement ?
Le déploiement local est possible mais nécessite du matériel de niveau entreprise, notamment 1920 Go de mémoire GPU et plusieurs kW d’alimentation. Les plateformes cloud comme Novita AI constituent une alternative pratique.
Novita AI est la plateforme cloud tout-en-un qui donne vie à vos ambitions en IA. API intégrées, serverless, GPU Instance — les outils économiques dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et faites de votre vision IA une réalité.



