

Empfehlen Sie noch heute Ihre Freunde weiter und beide erhalten $10 in LLM-API-Guthaben – das sind bis zu $500 an Gesamtbelohnungen, die auf Sie warten!
Llama 3.2 1B, Qwen2.5 7B, Qwen 3 (0.6B, 1.7B, 4B), GLM 4 – alle jetzt bei Novita AI verfügbar, um Ihre Projekte zu beschleunigen, ohne einen Cent auszugeben!
DeepSeek R1 0528 bietet hochmoderne KI-Fähigkeiten mit seiner 685 Milliarden Parameter umfassenden Mixture-of-Experts-Architektur und zeichnet sich beim Denken, Programmieren und bei mehrsprachigen Aufgaben aus.
Allerdings machen die erheblichen Hardwareanforderungen eine lokale Bereitstellung schwierig. Für kleinere Anforderungen bietet DeepSeek R1 0528 Qwen 3 8B eine kompakte und effiziente Alternative.
Alternativ beseitigen cloudbasierte Lösungen wie Novita AI Infrastrukturherausforderungen und bieten skalierbaren und kosteneffizienten Zugang zu DeepSeek-Modellen.
Wie viele Typen hat DeepSeek R1 0528?
https://www.youtube.com/watch?v=TidP39n5GfU
DeepSeek R1 0528
Modellgröße: 685 Milliarden Parameter
Open Source: Ja
Architektur: Mixture of Experts (MoE)
Sprachunterstützung: Mehrsprachig, exzellent in Englisch und Chinesisch
Unterstützte Modalitäten: Text-zu-Text
Trainingsmethode: Im neuesten Update wurden die Denktiefe und Inferenzfähigkeiten des Modells durch den Einsatz erhöhter Rechenressourcen und algorithmischer Optimierungen während des Post-Trainings deutlich verbessert.
DeepSeek R1 0528 Qwen 3 8B
Modellgröße: 8,19 Milliarden Parameter
Open Source: Ja
Architektur: Transformer
Sprachunterstützung: Mehrsprachig, exzellent in Englisch und Chinesisch
Unterstützte Modalitäten: Text-zu-Text
Trainingsmethode: Post-Training mit der Gedankenkette, die von DeepSeek-R1-0528 destilliert wurde, ergibt DeepSeek-R1-0528-Qwen3-8B.
DeepSeek R1 0528 Benchmark
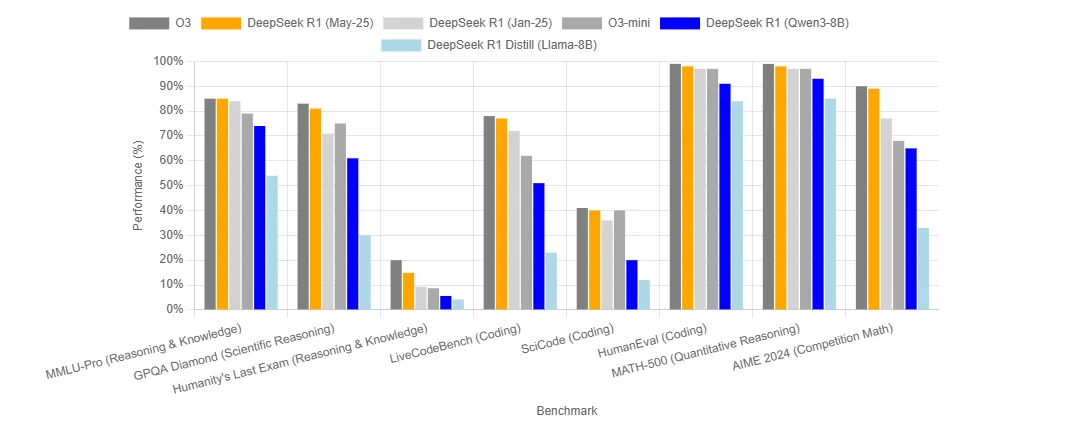
Wie viel kostet es, DeepSeek R1 0528 auszuführen?
Hier eine Übersicht über die Hardwareanforderungen für DeepSeek R1 0528 und DeepSeek R1 0528 Qwen 3 8B, die jeweiligen Konfigurationen und Systemanforderungen:
Hardwareanforderungen
DeepSeek R1 0528 Vollversion
- Modellgröße: ~1900 GB
- Hardwarekonfiguration:
- 24 × NVIDIA H100 GPUs (je 80 GB Speicher); 8 × H200 SXM 141 GB
- Gesamter GPU-Speicher: 1920 GB
- System-RAM:
- Empfohlen: ≥512 GB
- Optimal: 1 TB (für GPU-Offloading, KV-Cache, parallele Aufgaben)
- Speicher:
- Hochgeschwindigkeits-NVMe-SSD
- Kapazität: ≥500 GB
- CPU:
- Mehrkern-Prozessoren mit hoher Taktfrequenz (z. B. Dual Intel Xeon oder AMD EPYC)
- Kühlung & Strom:
- Enterprise-Kühlung und Stromversorgung
- Typische Leistungsaufnahme: mehrere kW
Starten Sie die DeepSeek-R1-0528 GPU-Vorlage sofort
DeepSeek R1 0528 Qwen 3 8B
- Modellgröße: 18,72 GB
- Hardwarekonfiguration:
- 1× NVIDIA RTX 4090 GPU (24 GB Speicher)
Während DeepSeek R1 Qwen 3 8B eine praktikable Option für lokale oder ressourcenbeschränkte Bereitstellungen darstellt, liefern die größeren DeepSeek R1-Konfigurationen in allen Benchmarks eine überlegene Leistung, insbesondere bei anspruchsvollen Aufgaben wie Programmieren und logischem Denken.
DeepSeek R1 0528 lokal: Effizient, aber herausfordernd
1. Hardware- und Kostenbeschränkungen
- Hohe GPU-Anforderungen: 24× H100 GPUs sind unerschwinglich teuer und erfordern ein groß angelegtes Rechenzentrum. Jede H100 GPU kostet Zehntausende Dollar.
- Großer System-RAM: Mindestens 512 GB RAM, idealerweise 1 TB, liegen weit über der Standard-Consumer-Hardware.
- Speicheranforderungen: Hochgeschwindigkeits-NVMe-SSDs mit großen Kapazitäten sind notwendig und verursachen erhebliche Kosten.
2. Stromversorgung und Kühlung
- Leistungsaufnahme: Das System benötigt mehrere kW Strom, was die Kapazitäten einer typischen Heim- oder Büroumgebung übersteigt.
- Kühlung: Enterprise-Kühlsysteme (z. B. Wasserkühlung) sind erforderlich, um Überhitzung zu vermeiden, was lokal schwer zu realisieren ist.
3. Physischer Platz
- Größe des Systems: Rack-montierte Server für 24 GPUs benötigen erheblichen physischen Platz, der in einem Heim- oder kleinen Büro wahrscheinlich nicht verfügbar ist.
4. Fachwissen und Software
- Wartung: Die Verwaltung eines so leistungsstarken Systems erfordert kontinuierliche Wartung, die ohne ein dediziertes IT-Team schwierig sein kann.
- Systemeinrichtung: Die Einrichtung von verteiltem Training oder Inferenz auf 24 GPUs erfordert Fachwissen in Cluster-Management und Software wie PyTorch, NCCL oder DeepSpeed.
https://www.youtube.com/watch?v=W8CObaM-gjA
Zugang zu DeepSeek R1 0528 Alternative: API wie Novita AI
- Cloud-basierter Zugang
Novita AI nutzt eine leistungsstarke Cloud-Infrastruktur und macht teure lokale Hardware überflüssig. So können Benutzer von jedem Gerät mit Internetverbindung auf fortschrittliche KI-Funktionen zugreifen.
- Einfach zu bedienen
Mit Novita AI sind keine komplexen Installationen oder Abhängigkeitsverwaltung erforderlich. Benutzer können nahtlos über eine Weboberfläche oder API darauf zugreifen und vermeiden so die technischen Herausforderungen, die mit der Bereitstellung von DeepSeek V3 verbunden sind.
- Kosteneffizient
Anstatt in teure GPUs und hohen Stromverbrauch zu investieren, bietet Novita AI ein Pay-as-you-go-Modell, das es zu einer erschwinglicheren Option für eine Vielzahl von Anwendungsfällen macht.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Bauen und Skalieren bietet.
Llama 3.2 1B, Qwen2.5 7B, Qwen 3 (0.6B, 1.7B, 4B), GLM 4 – alle jetzt bei Novita AI verfügbar, um Ihre Projekte zu beschleunigen, ohne einen Cent auszugeben!
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Probieren Sie jetzt die DeepSeek R1 0528 Demo aus!
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Gehen Sie auf die Seite „Einstellungen“ und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_H_85jwhkUyBsRipBTIU9n_adbP5B9Qvu0wxGGMN4Vq-BpFVKntQQXOAJF4IpkuDJh2e-NQkoJkcwMhus4t81PQ==",
)
model = "deepseek/deepseek-r1-0528-qwen3-8b"
stream = True # or False
max_tokens = 16000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Aufgrund der hohen Hardwareanforderungen von DeepSeek R1 empfehlen wir allen, Novita AI zu nutzen, eine cloudbasierte Plattform, die kostengünstigen und skalierbaren Zugang zu fortschrittlichen KI-Modellen bietet, ohne dass eine teure Infrastruktur erforderlich ist.
Häufig gestellte Fragen
Was sind die Hauptunterschiede zwischen DeepSeek R1 0528 und DeepSeek R1 0528 Qwen 3 8B?
DeepSeek R1 0528: 685B Parameter, Mixture-of-Experts-Architektur, benötigt 24× H100 GPUs.
DeepSeek R1 0528 Qwen 3 8B: 8,19B Parameter, Transformer-Architektur, läuft auf einer einzigen RTX 4090 GPU.
Was macht die Mixture-of-Experts (MoE)-Architektur einzigartig?
MoE aktiviert dynamisch Teilmengen von Parametern („Experten“) für bestimmte Aufgaben, verbessert die Recheneffizienz bei Aufgaben hoher Komplexität, erfordert aber fortgeschrittene Hardware.
Kann DeepSeek R1 0528 lokal bereitgestellt werden?
Eine lokale Bereitstellung ist möglich, erfordert aber Hardware auf Unternehmensniveau, einschließlich 1920 GB GPU-Speicher und mehreren kW Strom. Cloud-Plattformen wie Novita AI bieten eine praktische Alternative.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen unterstützt. Integrierte APIs, serverloser Betrieb, GPU-Instanz – die kosteneffizienten Tools, die Sie brauchen. Verzichten Sie auf Infrastruktur, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.



