

今すぐ友達を紹介すると、あなたと友達の両方に $10 の LLM API クレジット をプレゼント。最大 $500 の報酬があなたを待っています!
Llama 3.2 1B、Qwen2.5 7B、Qwen 3(0.6B、1.7B、4B)、GLM 4 — すべて Novita AI で今すぐご利用いただけます。無料でプロジェクトを加速しましょう!
DeepSeek R1 0528 は、685B パラメータの Mixture-of-Experts アーキテクチャにより最先端の AI 機能を提供し、推論、コーディング、多言語タスクに優れています。
しかし、その高いハードウェア要件により、ローカルでのデプロイは困難です。小規模なニーズには、DeepSeek R1 0528 Qwen 3 8B がコンパクトで効率的な代替手段を提供します。
あるいは、Novita AI のようなクラウドベースのソリューションはインフラストラクチャの課題を排除し、DeepSeek モデルへのスケーラブルでコスト効率の高いアクセスを提供します。
DeepSeek R1 0528 にはいくつの種類がある?
https://www.youtube.com/watch?v=TidP39n5GfU
DeepSeek R1 0528
モデルサイズ: 6850 億パラメータ
オープンソース: はい
アーキテクチャ: Mixture of Experts(MoE)
言語サポート: 多言語、英語と中国語に優れる
対応モダリティ: テキスト→テキスト
トレーニング方法: 最新のアップデートでは、ポストトレーニング時に計算リソースとアルゴリズムの最適化を増やして推論能力を大幅に強化。
DeepSeek R1 0528 Qwen 3 8B
モデルサイズ: 81.9 億パラメータ
オープンソース: はい
アーキテクチャ: Transformer
言語サポート: 多言語、英語と中国語に優れる
対応モダリティ: テキスト→テキスト
トレーニング方法: DeepSeek-R1-0528 から抽出された思考連鎖でポストトレーニングされ、DeepSeek-R1-0528-Qwen3-8B を生成。
DeepSeek R1 0528 ベンチマーク
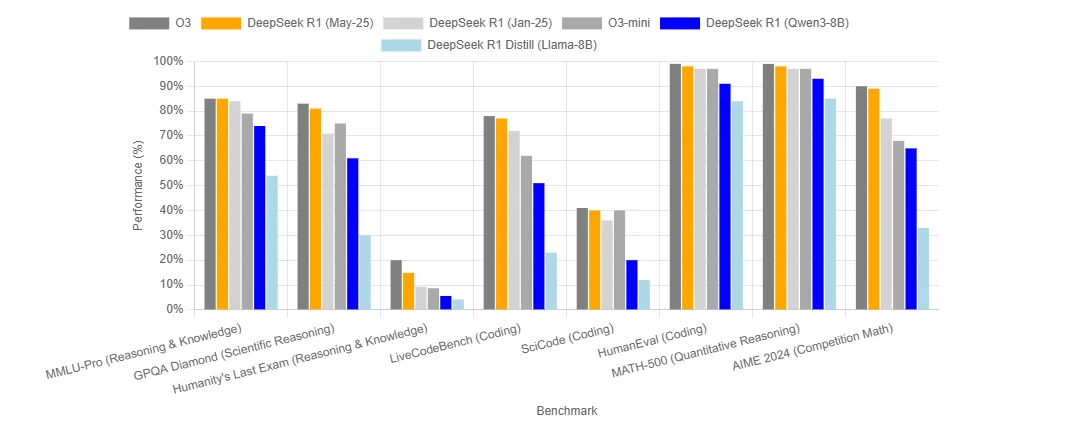
DeepSeek R1 0528 の実行コストは?
以下に、DeepSeek R1 0528 と DeepSeek R1 0528 Qwen 3 8B の ** ハードウェア要件**の概要を示します。各構成とシステム要件を強調しています。
ハードウェア要件
DeepSeek R1 0528 フルバージョン
- モデルサイズ: ~1900GB
- ハードウェア構成:
- 24 × NVIDIA H100 GPU(各 80GB メモリ); 8 x H200 SXM 141GB
- 合計 GPU メモリ: 1920GB
- システム RAM:
- 推奨: ≥512GB
- 最適: 1TB(GPU オフロード、KV キャッシュ、並列タスク用)
- ストレージ:
- 高速 NVMe SSD
- 容量: ≥500GB
- CPU:
- マルチコア、高周波プロセッサ(例:Dual Intel Xeon または AMD EPYC)
- 冷却と電源:
- エンタープライズグレードの冷却および電源システム
- 標準消費電力: 数 kW
DeepSeek-R1-0528 GPU テンプレートをすぐに起動
DeepSeek R1 0528 Qwen 3 8B
- **モデルサイズ **: 18.72GB
- ハードウェア構成:
- 1× NVIDIA RTX 4090 GPU(24GB メモリ)
DeepSeek R1 Qwen 3 8B はローカルまたはリソース制約のある環境での実行可能な選択肢を提供しますが、大規模な DeepSeek R1 構成 は、特にコーディングや推論といった要求の厳しいタスクにおいて、すべてのベンチマークで優れたパフォーマンスを発揮します。
DeepSeek R1 0528 をローカルで実行:効率的だが困難
1. ハードウェアとコストの制約
- 高い GPU 要件: 24× H100 GPU は非常に高額で、大規模データセンターが必要。各 H100 GPU は数万ドル。
- 大容量システム RAM: 最低 512GB RAM、理想的には 1TB 必要で、標準的なコンシューマグレードのハードウェアをはるかに超える。
- ストレージ要件: 高速で大容量の NVMe SSD が必須であり、コストが大幅に増加。
2. 電力と冷却
- 消費電力: システムは数 kW の電力を必要とし、一般的な家庭やオフィスの設備では対応不可。
- 冷却: 過熱を防ぐためにエンタープライズグレードの冷却システム(水冷など)が必要。ローカルでの実現は困難。
3. 物理スペース
- システムサイズ: 24 GPU 用のラックマウントサーバーは、多くの物理スペースを必要とし、家庭や小さなオフィスではまず確保できない。
4. 専門知識とソフトウェア
- メンテナンス: このような強力なシステムの管理には継続的なメンテナンスが必要で、専任の IT チームなしでは困難。
- システム設定: 24 GPU での分散型トレーニングや推論の設定には、クラスタ管理や PyTorch、NCCL、DeepSpeed などのソフトウェアに関する専門知識が必要。
https://www.youtube.com/watch?v=W8CObaM-gjA
DeepSeek R1 0528 の代替案:Novita AI のような API にアクセス
- クラウドベースのアクセス
Novita AI は強力なクラウドインフラストラクチャを活用し、高価なローカルハードウェアを不要にします。これにより、インターネット接続があればどのデバイスからでも高度な AI 機能にアクセスできます。
- 簡単な使い方
Novita AI では、複雑なインストールや依存関係の管理は不要です。Web インターフェースまたは API を介してシームレスに機能にアクセスでき、DeepSeek V3 のデプロイに伴う技術的な課題を回避できます。
- コスト効率
高価な GPU への投資や高い消費電力の代わりに、Novita AI は従量課金制を提供し、多様なユースケースでより手頃なオプションとなっています。
Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームであり、同時に手頃で信頼性の高い GPU クラウドを構築とスケーリングに提供します。
Llama 3.2 1B、Qwen2.5 7B、Qwen 3(0.6B、1.7B、4B)、GLM 4 — すべて Novita AI で今すぐご利用いただけます。無料でプロジェクトを加速しましょう!
ステップ 1: ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ 2: モデルを選択
利用可能なオプションを閲覧し、ニーズに合ったモデルを選択します。
ステップ 3: 無料トライアルを開始
選択したモデルの機能を探索するために、無料トライアルを開始します。
ステップ 4: API キーを取得
API で認証するために、新しい API キーが提供されます。「設定」ページに移動し、画像の指示に従って API キーをコピーします。

ステップ 5: API をインストール
使用するプログラミング言語に応じたパッケージマネージャーを使用して API をインストールします。
インストール後、必要なライブラリを開発環境にインポートします。API キーを使用して API を初期化し、Novita AI LLM と対話を開始します。以下は、Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_H_85jwhkUyBsRipBTIU9n_adbP5B9Qvu0wxGGMN4Vq-BpFVKntQQXOAJF4IpkuDJh2e-NQkoJkcwMhus4t81PQ==",
)
model = "deepseek/deepseek-r1-0528-qwen3-8b"
stream = True # または False
max_tokens = 16000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
DeepSeek R1 の高いハードウェア要件のため、高額なインフラストラクチャを必要とせずにコスト効率が高くスケーラブルなアクセスを提供するクラウドベースのプラットフォーム Novita AI のご利用をお勧めします。
よくある質問
DeepSeek R1 0528 と DeepSeek R1 0528 Qwen 3 8B の主な違いは何ですか?
DeepSeek R1 0528: 685B パラメータ、Mixture-of-Experts アーキテクチャ、24× H100 GPU が必要。
DeepSeek R1 0528 Qwen 3 8B: 8.19B パラメータ、Transformer アーキテクチャ、1 台の RTX 4090 GPU で動作。
Mixture-of-Experts(MoE)アーキテクチャの特徴は何ですか?
MoE はタスクに応じてパラメータのサブセット(「エキスパート」)を動的に活性化し、高複雑タスクの計算効率を向上させますが、高度なハードウェアが必要です。
DeepSeek R1 0528 はローカルにデプロイできますか?
ローカルデプロイは可能ですが、1920GB の GPU メモリや数 kW の電力など、エンタープライズグレードのハードウェアが必要です。Novita AI のようなクラウドプラットフォームが実用的な代替手段を提供します。
Novita AI は、AI の野望を支援するオールインワンのクラウドプラットフォームです。統合 API、サーバーレス、GPU インスタンス — コスト効率の高いツールが揃っています。インフラストラクチャを排除し、無料で始めて、AI ビジョンを現実にしましょう。



