

قم بإحالة أصدقائك اليوم واحصل على 10 دولارات من أرصدة API LLM لكل منكما — أي ما يصل إلى 500 دولار من المكافآت الإجمالية في انتظارك!
Llama 3.2 1B و Qwen2.5 7B و Qwen 3 (0.6B, 1.7B, 4B) و GLM 4 — كلها متاحة الآن على Novita AI لتعزيز مشاريعك دون إنفاق فلس واحد!
يقدم DeepSeek R1 0528 قدرات ذكاء اصطناعي متطورة بفضل بنيته المختلطة من الخبراء Mixture-of-Experts التي تضم 685 مليار معلمة، ويتفوق في مهام التفكير والبرمجة والمهام متعددة اللغات.
ومع ذلك، فإن متطلباته الأجهزة الكبيرة تجعل النشر المحلي صعبًا. بالنسبة للاحتياجات الصغيرة الحجم، يوفر DeepSeek R1 0528 Qwen 3 8B بديلاً مضغوطًا وفعالًا.
وبدلاً من ذلك، تقضي الحلول السحابية مثل Novita AI على تحديات البنية التحتية، وتوفر وصولاً قابلاً للتطوير وفعالاً من حيث التكلفة إلى نماذج DeepSeek.
كم عدد أنواع DeepSeek R1 0528؟
https://www.youtube.com/watch?v=TidP39n5GfU
DeepSeek R1 0528
حجم النموذج: 685 مليار معلمة
مفتوح المصدر: نعم
الهندسة المعمارية: Mixture of Experts (MoE)
دعم اللغات: متعدد اللغات، يتفوق في الإنجليزية والصينية
الأنماط المدعومة: نص إلى نص
طريقة التدريب: في التحديث الأخير، تم تعزيز عمق التفكير وقدرات الاستدلال للنموذج بشكل كبير باستخدام موارد حسابية متزايدة وتحسينات خوارزمية أثناء مرحلة ما بعد التدريب.
DeepSeek R1 0528 Qwen 3 8B
حجم النموذج: 8.19 مليار معلمة
مفتوح المصدر: نعم
الهندسة المعمارية: Transformer
دعم اللغات: متعدد اللغات، يتفوق في الإنجليزية والصينية
الأنماط المدعومة: نص إلى نص
طريقة التدريب: تم تدريبه بعديًا باستخدام سلسلة التفكير المقطرة من DeepSeek-R1-0528، مما أدى إلى إنتاج DeepSeek-R1-0528-Qwen3-8B.
معيار DeepSeek R1 0528
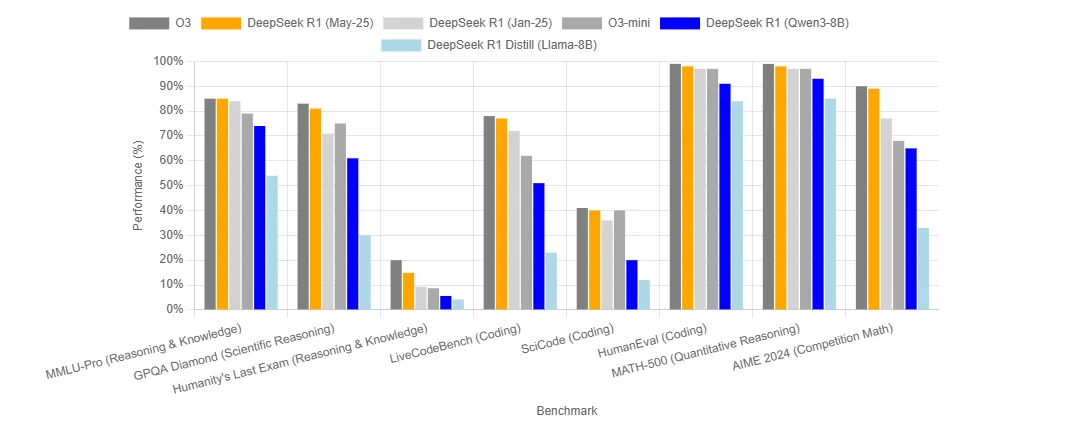
كم تكلفة تشغيل DeepSeek R1 0528؟
فيما يلي نظرة عامة على متطلبات الأجهزة لـ DeepSeek R1 0528 و DeepSeek R1 0528 Qwen 3 8B، مع إبراز تكويناتها واحتياجات النظام:
متطلبات الأجهزة
DeepSeek R1 0528 النسخة الكاملة
- حجم النموذج: ~1900 جيجابايت
- تكوين الأجهزة:
- 24 × NVIDIA H100 GPU (ذاكرة 80 جيجابايت لكل منها)؛ 8 × H200 SXM 141 جيجابايت
- إجمالي ذاكرة GPU: 1920 جيجابايت
- ذاكرة النظام RAM:
- الموصى بها: ≥512 جيجابايت
- الأمثل: 1 تيرابايت (لـ GPU offload و KV cache والمهام المتوازية)
- التخزين:
- NVMe SSD عالي السرعة
- السعة: ≥500 جيجابايت
- CPU:
- معالجات متعددة النوى وعالية التردد (مثل Dual Intel Xeon أو AMD EPYC)
- التبريد والطاقة:
- أنظمة تبريد وطاقة على مستوى المؤسسات
- استهلاك الطاقة النموذجي: عدة كيلوواط
أطلق قالب GPU الخاص بـ DeepSeek-R1-0528 فورًا
DeepSeek R1 0528 Qwen 3 8B
- حجم النموذج: 18.72 جيجابايت
- تكوين الأجهزة:
- 1× NVIDIA RTX 4090 GPU (ذاكرة 24 جيجابايت)
بينما يوفر DeepSeek R1 Qwen 3 8B خيارًا قابلاً للتطبيق للنشر المحلي أو المحصور في الموارد، فإن تكوينات DeepSeek R1 الأكبر تحقق أداءً فائقًا في جميع المعايير، خاصة في المهام الصعبة مثل البرمجة والتفكير.
DeepSeek R1 0528 محليًا: فعال ولكنه صعب
1. قيود الأجهزة والتكلفة
- متطلبات GPU عالية: 24× H100 GPU باهظة الثمن وتتطلب مركز بيانات واسع النطاق. تكلف كل GPU H100 عشرات الآلاف من الدولارات.
- ذاكرة نظام RAM كبيرة: 512 جيجابايت كحد أدنى، ويفضل 1 تيرابايت، وهو أبعد بكثير من الأجهزة الاستهلاكية القياسية.
- احتياجات التخزين: محركات NVMe SSD عالية السرعة ذات سعات كبيرة ضرورية، مما يزيد بشكل كبير من التكلفة.
2. الطاقة والتبريد
- استهلاك الطاقة: يتطلب النظام عدة كيلوواط من الطاقة، وهو ما يتجاوز قدرات الإعداد المنزلي أو المكتبي النموذجي.
- التبريد: هناك حاجة إلى أنظمة تبريد على مستوى المؤسسات (مثل التبريد المائي) لمنع ارتفاع درجة الحرارة، وهو أمر يصعب تحقيقه محليًا.
3. المساحة المادية
- حجم النظام: تتطلب الخوادم المثبتة على رفوف لـ 24 GPU مساحة مادية كبيرة، قد لا تكون متوفرة في المنزل أو المكتب الصغير.
4. الخبرة والبرمجيات
- الصيانة: تتضمن إدارة مثل هذا النظام القوي صيانة مستمرة، والتي قد تكون صعبة بدون فريق تقني مخصص.
- إعداد النظام: يتطلب إعداد التدريب أو الاستدلال الموزع على 24 GPU خبرة في إدارة المجموعات وبرمجيات مثل PyTorch و NCCL أو DeepSpeed.
https://www.youtube.com/watch?v=W8CObaM-gjA
الوصول إلى بديل DeepSeek R1 0528: API مثل Novita AI
- الوصول عبر السحابة
تستفيد Novita AI من البنية التحتية السحابية القوية، مما يلغي الحاجة إلى أجهزة محلية باهظة الثمن. يتيح ذلك للمستخدمين الوصول إلى قدرات الذكاء الاصطناعي المتقدمة من أي جهاز متصل بالإنترنت.
- سهولة الاستخدام
مع Novita AI، لا حاجة إلى تثبيتات معقدة أو إدارة التبعيات. يمكن للمستخدمين الوصول بسلاسة إلى ميزاتها عبر واجهة الويب أو API، وتجنب التحديات التقنية المرتبطة بنشر DeepSeek V3.
- فعالية التكلفة
بدلاً من الاستثمار في وحدات GPU باهظة الثمن وتحمل استهلاك طاقة عالي، تقدم Novita AI نموذج الدفع حسب الاستخدام، مما يجعله خيارًا أكثر بأسعار معقولة لمجموعة واسعة من حالات الاستخدام.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط، مع توفير سحابة GPU موثوقة وبأسعار معقولة للبناء والتوسع.
Llama 3.2 1B و Qwen2.5 7B و Qwen 3 (0.6B, 1.7B, 4B) و GLM 4 — كلها متاحة الآن على Novita AI لتعزيز مشاريعك دون إنفاق فلس واحد!
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
قم بتسجيل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

جرب نسخة تجريبية من DeepSeek R1 0528 الآن!
الخطوة 2: اختر نموذجك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.
الخطوة 3: ابدأ نسختك التجريبية المجانية
ابدأ نسختك التجريبية المجانية لاستكشاف إمكانيات النموذج المحدد.
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنقدم لك مفتاح API جديد. بالدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام واجهة برمجة تطبيقات chat completions لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_H_85jwhkUyBsRipBTIU9n_adbP5B9Qvu0wxGGMN4Vq-BpFVKntQQXOAJF4IpkuDJh2e-NQkoJkcwMhus4t81PQ==",
)
model = "deepseek/deepseek-r1-0528-qwen3-8b"
stream = True # or False
max_tokens = 16000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
نظرًا لمتطلبات الأجهزة العالية لـ DeepSeek R1، نشجع الجميع على استخدام Novita AI، وهي منصة سحابية توفر وصولاً فعالاً من حيث التكلفة وقابلاً للتوسع إلى نماذج الذكاء الاصطناعي المتقدمة دون الحاجة إلى بنية تحتية باهظة الثمن.
الأسئلة المتكررة
ما هي الاختلافات الرئيسية بين DeepSeek R1 0528 و DeepSeek R1 0528 Qwen 3 8B؟
DeepSeek R1 0528: 685 مليار معلمة، بنية Mixture-of-Experts، يتطلب 24× H100 GPU.
DeepSeek R1 0528 Qwen 3 8B: 8.19 مليار معلمة، بنية Transformer، يعمل على GPU واحد RTX 4090.
ما الذي يجعل بنية Mixture-of-Experts (MoE) فريدة؟
تقوم MoE بتنشيط مجموعات فرعية من المعلمات (“خبراء”) ديناميكيًا لمهام محددة، مما يحسن الكفاءة الحسابية للمهام عالية التعقيد، ولكنها تتطلب أجهزة متقدمة.
هل يمكن نشر DeepSeek R1 0528 محليًا؟
النشر المحلي ممكن ولكنه يتطلب أجهزة على مستوى المؤسسات، بما في ذلك 1920 جيجابايت من ذاكرة GPU وعدة كيلوواط من الطاقة. توفر المنصات السحابية مثل Novita AI بديلاً عمليًا.
Novita AI هي المنصة السحابية الشاملة التي تمكّن طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، بدون خادم، ومثيلات GPU — الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، وابدأ مجانًا، وحوّل رؤيتك للذكاء الاصطناعي إلى حقيقة.



